自然语言处理-第四期-Word2Vec神经网络及反向传递
Posted 好奇宝宝与机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理-第四期-Word2Vec神经网络及反向传递相关的知识,希望对你有一定的参考价值。
背景
上期提到来Bag of word,本期将开始介绍Word2Vec,Word2Vec 的skip Gram模型需要用到神经网络的模型。所以该篇将初步介绍神经网络。我的头条号第一篇文章就是通俗介绍神经网络,https://www.toutiao.com/i6566982498163622403/
本文将覆盖神经网络基础构成和最重要的反向传递
神经网络
今天将从结构上解释下神经网络。
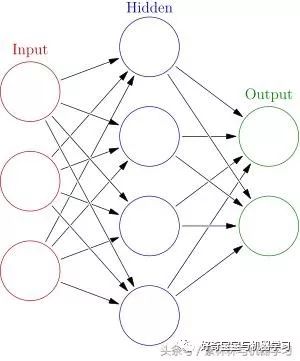
从上面这个图,大家可以看出一个神经网络包括了几部分: 1. 层 2. 点 3. 线
层-神经网络层
神经网络分为:输入层、隐藏层和输出层。
输入层.是用来输入我们的训练数据的,输入层的结构当然是与我们的原始数据强相关;
输出层.是用来记录我们输出的结果的,输出层的结构是与我们预测的结果相关;
隐藏层.是用来处理和记忆我们处理的过程的。
上面神经网络层的解释,感觉是废话,但是结合下面的神经元及数据流向的解释 会变得更清晰
点-神经元
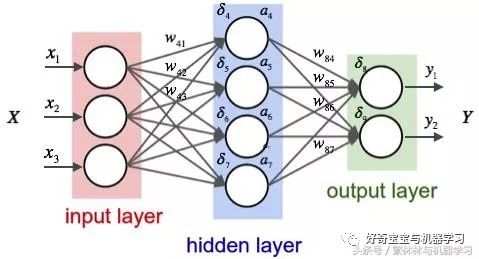
每个神经元就是一个计算处理的单元,其包括两部分1. 基础的线性方程 2. Acivation Function 激励函数
从上面这个图可以看出: 隐藏层第一个神经元对于输入值X1的处理如下:
W * 输入值 + b = 输出值
y = Activation( 输出值)
其中第二步的激励函数是取决于模型的设置。这个激励函数的一个重要意义就是改变神经网络的线性倾向。
线-神经网络数据流转
总结下
还是这个图哈,其中线 表现的数据流转。从上图可以看出,第一层和第二层所有的神经元相互关联。
这样构建出的一个神经网络是什么呢? 粗略的说,就是一个巨大的公式F(X). 这个F(X) 里面 既包含了基础的线性方程,也包含了激励函数。
如果我们只看一个神经元那么该公式可以表达为 y=F(W * X + b) .
神经网络有意思的地方就是,它有点像俄罗斯套娃,打开一个里面还有一个。
可以简单的将神经网络比喻成一个大的套娃,因为这个神经网络的输入值X,可能就是上一个神经元的Y。所以神经网络的公式可以变成:
y= F (b+ W*(F(b+ W * ( F (b+ W* (..........
当然实际情况比这复杂很多,因为涉及矩阵运算。但是我们可以从概念上这么简单理解。如果能这样理解,就能很容易理解反向传递。
Backpropogation (反向传递)
反向传递是神经网络非常重要的概念。如果大家理解了套娃的概念,理解起来就会变得很简单。
假设我们的神经网络特别简单,只有一个神经元,那么神经网络计算的结果如下:
y_神经网络预测 = F( W* X + b)
大家都知道神经网络需要训练,训练目的很简单就是要神经网络算出来的结果和实际结果相近,那么他们之前的差距就是:
loss(差距) = y_实际 - y_神经网络预测
loss(差距) = y_实际 - F(W* X + b)
由于X,y 是训练样本,即其不是变量。 那么以上公式的变量就是该神经元的参数 W ,b
那么,我们可以将公式画成类似下面的图。
那么,gradient descent(梯度下降) 就是在曲线上取切线,然后走一小步。 当取切线为0的时候,基本上就到达了local minimum(本地最小值)
对于多层的神经网络与单层的并没有本质的区别。 就和俄罗斯套娃,做了一层微积分可以,可以再做一层。 最终的结果都是 loss function 取决于每个神经元的参数。
总结下,反向传递就是在计算出初始的差异值后,取微积分,,然后调整参数的过程。backpropogation最终改变的是神经元的参数W,B
再通俗的理解下,我们一直听说神经网络学习,学的结果是什么呢? 就是一点点的调整每个神经元里面的参数。
神经网络训练
我们从数据流向来理解下神经网络的训练过程:
正向:不论输入值是什么,神经网络会根据当前参数计算出一个结果。 并且计算出与实际结果的差异值;
逆向:通过对差异方程 做微积分,找到loss function 上的切线,并走一小步,调整神经元参数;
循环上述两个过程,最终训练的出的就是神经元参数。
下期预告
本期主要给大家介绍了神经网络,感觉纯文本讲不太清楚。 不过大家只要知道,神经网络是一个巨大的F(X),然后通过切线(类似于下山)的过程学习足够了。下一期将进入到Word2Vec部分。
原创码字,感兴趣的朋友请关注下~
以上是关于自然语言处理-第四期-Word2Vec神经网络及反向传递的主要内容,如果未能解决你的问题,请参考以下文章