论文 | 自然语言处理顶会ACL 2018该关注什么?蚂蚁金服专家告诉你!
Posted 支付宝技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文 | 自然语言处理顶会ACL 2018该关注什么?蚂蚁金服专家告诉你!相关的知识,希望对你有一定的参考价值。
小蚂蚁说:
一年一度的ACL大会今年7月15日至20日在澳大利亚墨尔本召开。作为自然语言处理的顶级会议,虽然远在澳洲召开,也吸引了1500位从全球各地赶来的专业人员参会。蚂蚁金服派出了数位技术专家代表公司前去参会,本文是几位专家参会回来后写出的走心分享,并对此次会议的各类优秀论文做出了独家解读。

前言
今年的 ACL 共收到 1544 份提交论文,其中 1018 份长论文接收了 258 篇,526份短论文接收了 126 篇,总体接受率为 24.9%。
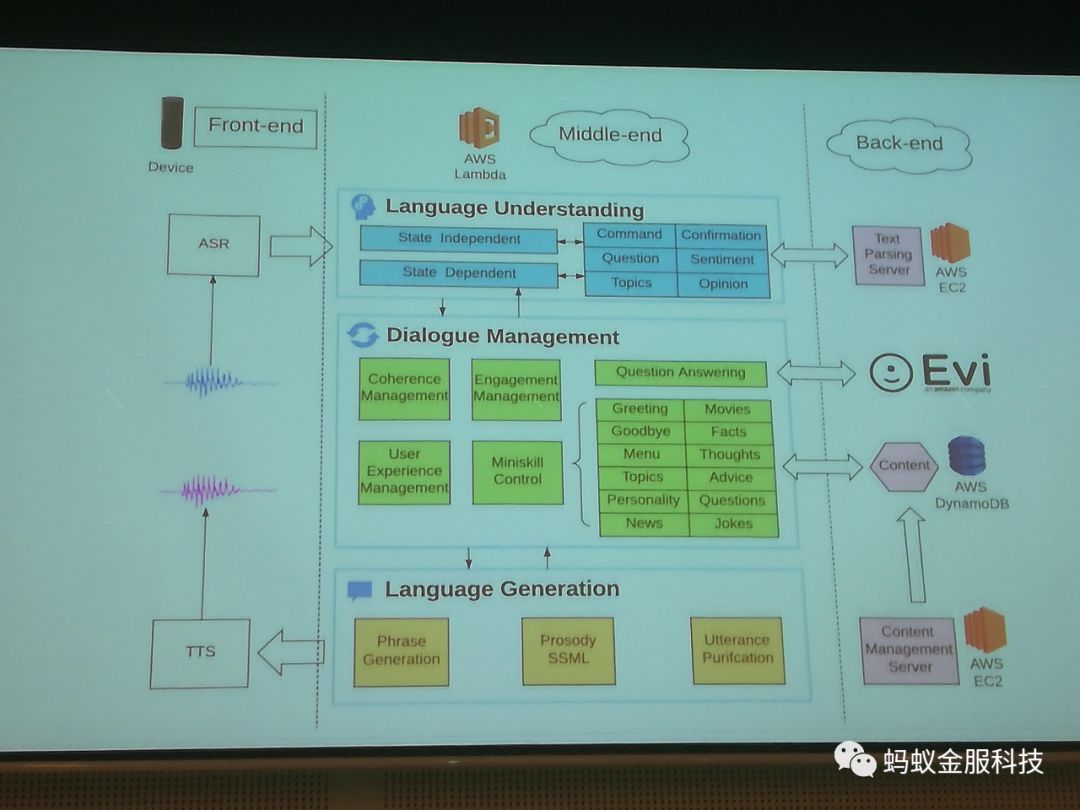
总的来说,这届ACL中基于神经网络的文章占绝大多数。但是一个关于Amazon Prize的slide也很有趣。华盛顿大学的Yejin Choi教授通过这个slide,说明神经网络大规模运用还有些许多工作要做;她的实验室本来想用一个统一的神经网络模型做一个可以参加Amazon Prize的对话系统。但是最终的实现的冠军系统还是运用各种已有的子系统。见下图:
最佳论文奖
总体看来今年的最佳论文倾向于新问题设计与对应数据集构建。
Know What You Don’t Know: Unanswerable Questions for SQuAD:提出了SQuAD2.0,主要是增加了一类不可回答的问题(即:在给定的段落中无法找打对应问题的答案)
Learning to Ask Good Questions: Ranking Clarification Questionsusing Neural Expected Value of Perfect Information:从StackExchange上抽取(post,question,answer),并把问题转换成给定post,如何选择好而有效的question。
Let's do it "again": A First Computational Approach to Detecting Adverbial Presupposition Triggers:对“again”构建数据集并测试了不同的模型
Tutorial(教程): Neural Semantic Parsing
https://github.com/allenai/acl2018-semantic-parsing-tutorial
经典的语义分析模型(例如:CCG,AMR等)现在已经被基于神经网络模型超越。
CCG模型要使用比较复杂的学习算法,并且很难上手,需要花费比较多的时间去让你的算法起作用,除此之外,模型对没有见到过的数据扩展性还是比较差。而神经网络模型简单,效果又好。报告人称他们现在在CCG模型方向只是有空白日想想而已了。这次tutorial主要分为:
1.数据集:包括一些经典的数据集(Geoquery,ATIS,CoNala等)
2.模型:限制解码算法,各种训练算法(Maximum Margin,结构学习,强化学习等)
3.如何搭建语义分析器:提供了各种开源模型工具,以及要搭建分析器所需要的一些处理工具,主推了Allen NLP开源工具。
如果大家感兴趣可以深入Slides了解详细信息。
Machine Translation 机器翻译
The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation
https://github.com/kweonwooj/papers/issues/106
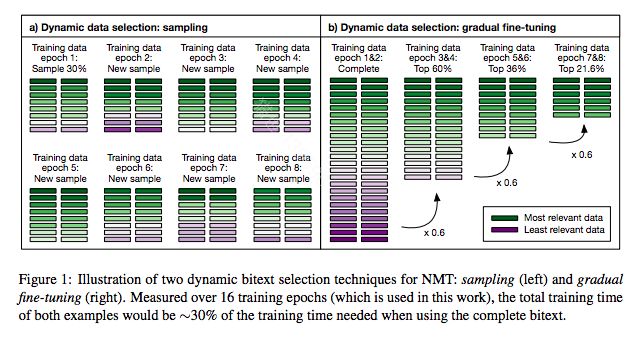
Dynamic Sentence Sampling for Efficient Training of Neural Machine Translation
本篇文章关注训练速度(收敛),在NMT中作者观察到其中一部分样本过分训练,其他样本训练不足。作者的思路是对每个样本进行加权采样,对于训练不充分的提高采样概率。是否充分作者基于一个句子在前后两轮cost的变化。
A Simple and Effective Approach to Coverage-Aware Neural Machine Translation
传统的seq2seq模型倾向短句子生成,一个常见的解决方案是对生成的句子进行归一化,但该方法并不能有效感知译文内容的覆盖度。本文提出了覆盖度感知概念,定义成每一个待解码的词在源端的attention系数的求和。核心思想是将覆盖度感知特征作用到每一个解码时刻和NMT分数线下插值融合,用于beam search 过程。
第二届NMT 研讨会:
https://sites.google.com/site/wnmt18/schedule
Google的Jacob Delvin讲了他在微软的一个工作:如何将基于RNN的NMT模型fit到离线手机应用,在不明显损失翻译质量的前提下,在速度和内存做最大程度上的优化。最终的模型可以在损失2个BLEU点的情况下,模型大小缩减到44M,解码速度达到单线程400多词每秒。
Semantic Parsing 语义分析
语义分析的目的是对自然语言做理解,以生成可以用程序来执行的合乎语法与语义的结构化表示。本次ACL大会上,关于该领域一些突出的文章如下:
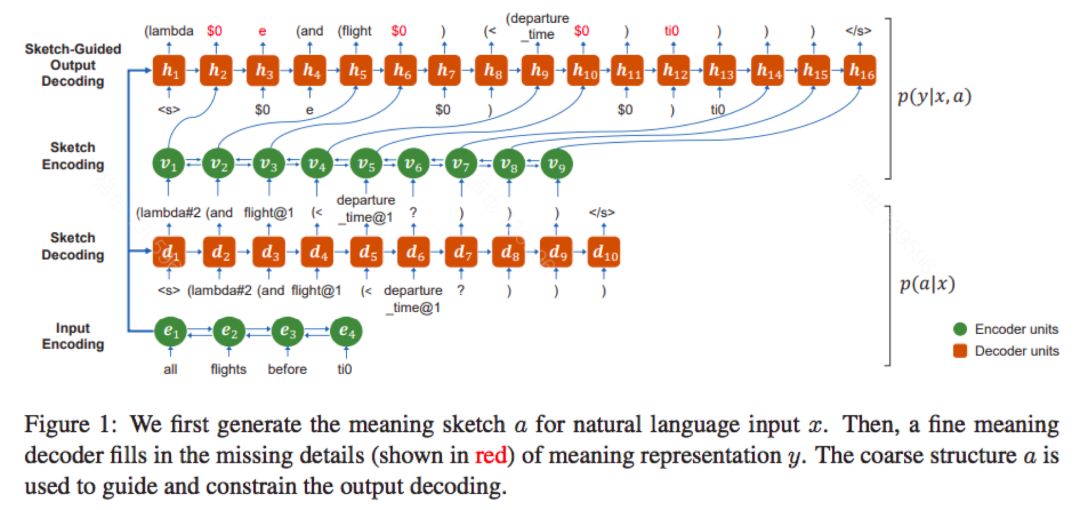
Coarse-to-fine decoding for neural semantic parsing
用两级encoder->decoder来实现。第一级做sketch,第二级再把具体的variable生成。优点是分解问题。比一步生成,相对简单。
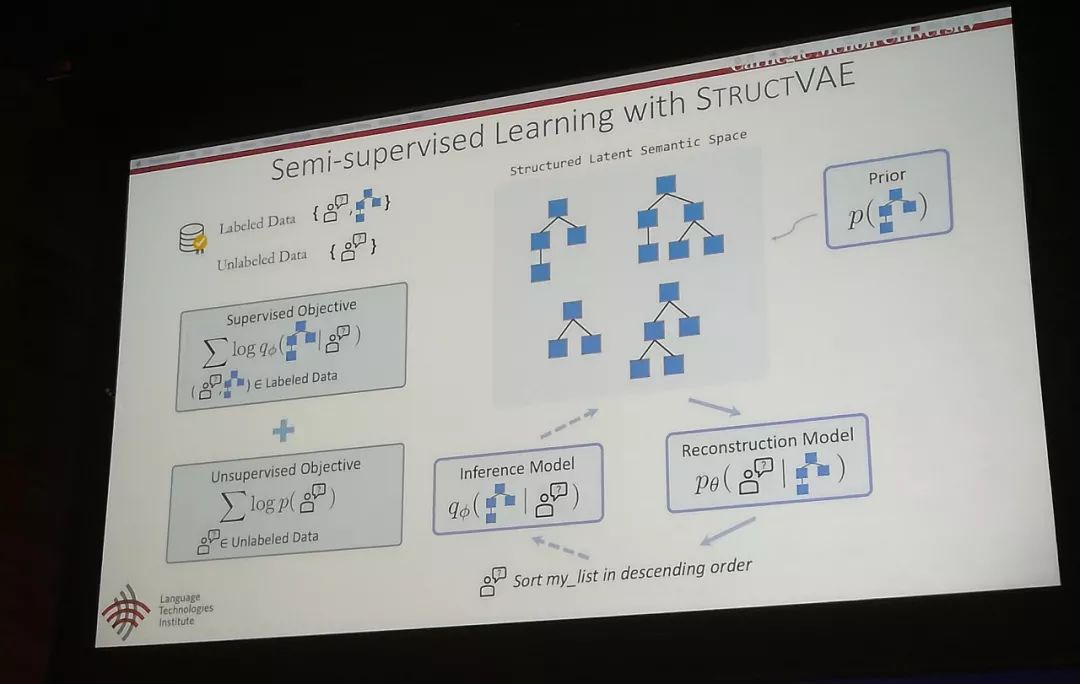
Semi-supervised learning with strucuture VAE
这个方法定义了结构化的latent semantic representation。用后验概率来选择最好的latent semantic representation。此方法和如上方法类似。
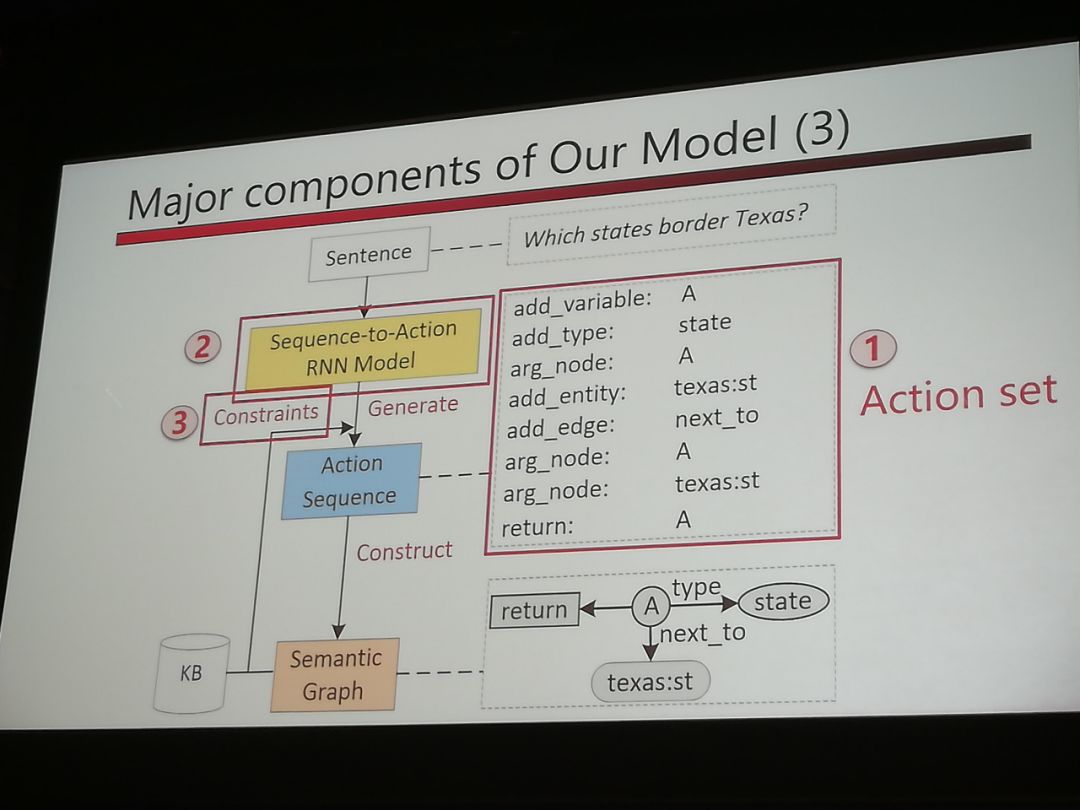
Sequence-to-Action: End-to-end Semantic Graph Generation for Semantic Parsing
这个是基于semantic graph的semantic parsing。优点是semantic graph可以用来表示sentence meaning。句子的含义可以用graph来表示。用RNN来生成图。
Question Answering 机器问答
关注点在如何利用常识和知识库,理解上下文、多段文本以及多文档。
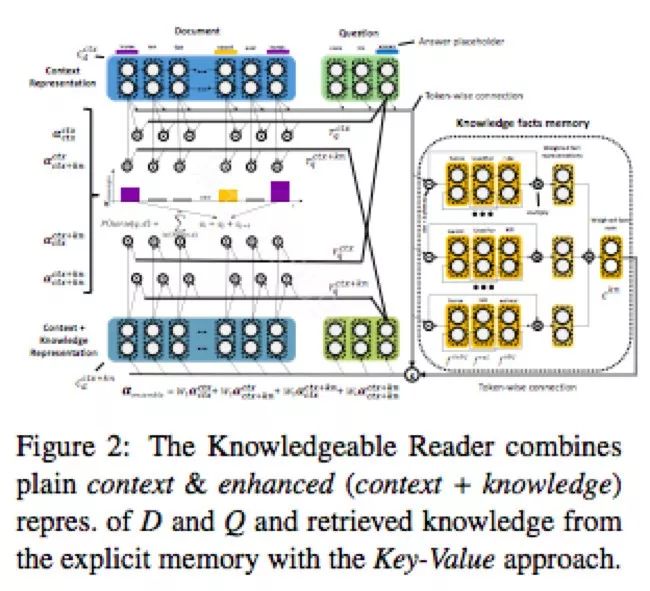
Knowledgeable Reader: Enhancing Cloze-Style Reading Comprehension with External Commonsense Knowledge
本文介绍了一种神经阅读理解模型,将常识知识编码为键值记忆,结合外部知识和上下文表示来推断答案。
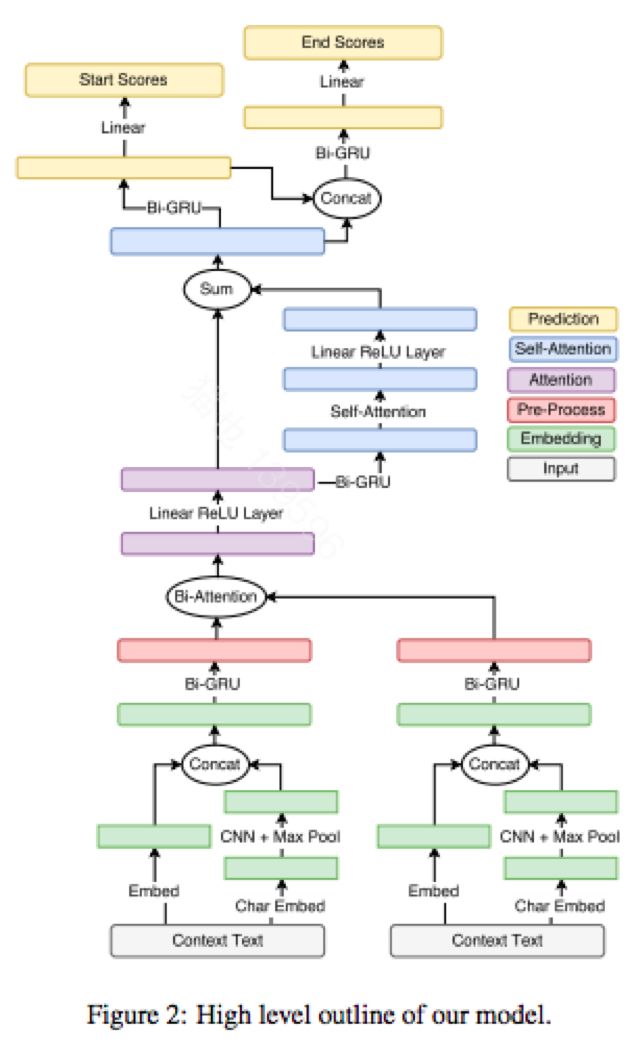
Simple and Effective Multi-Paragraph Reading Comprehension
将神经网络段落级QA系统之间应用到文档或多文档级别时,段落级QA模型经常被不相关的文本分散注意力。这篇文章提出了一个训练方法,通过从每个文档中抽取多个段落并使用目标函数来获得全局正确答案,从而忽略不包含答案的段落。
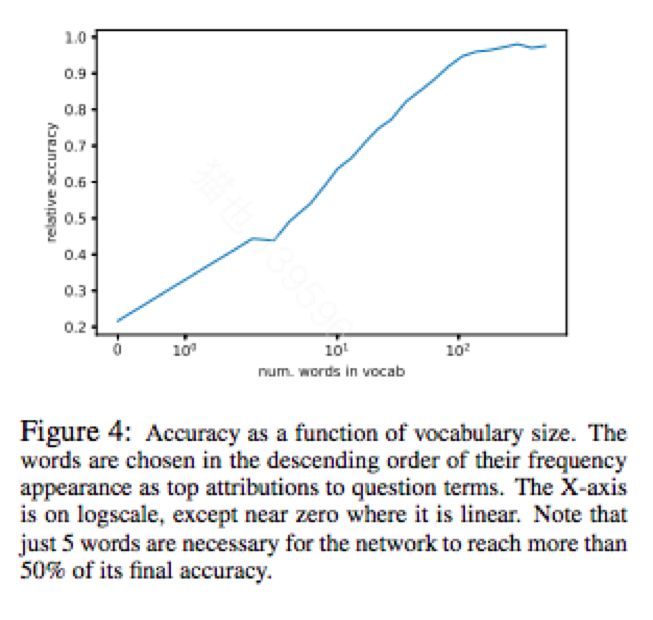
Did the Model Understand the Question
本文分析了三个问题回答任务的最先进的深度学习模型:(1)图像,(2)表格,以及(3)文本段落。使用归因概念(单词重要性),发现这些深层网络经常忽略重要的问题术语。结果表明,归因可以增加标准的准确度量,并有助于调查模型性能。当模型准确但由于错误的原因时,归因可能会在模型中表现出错误的逻辑,表明测试数据存在不足之处。
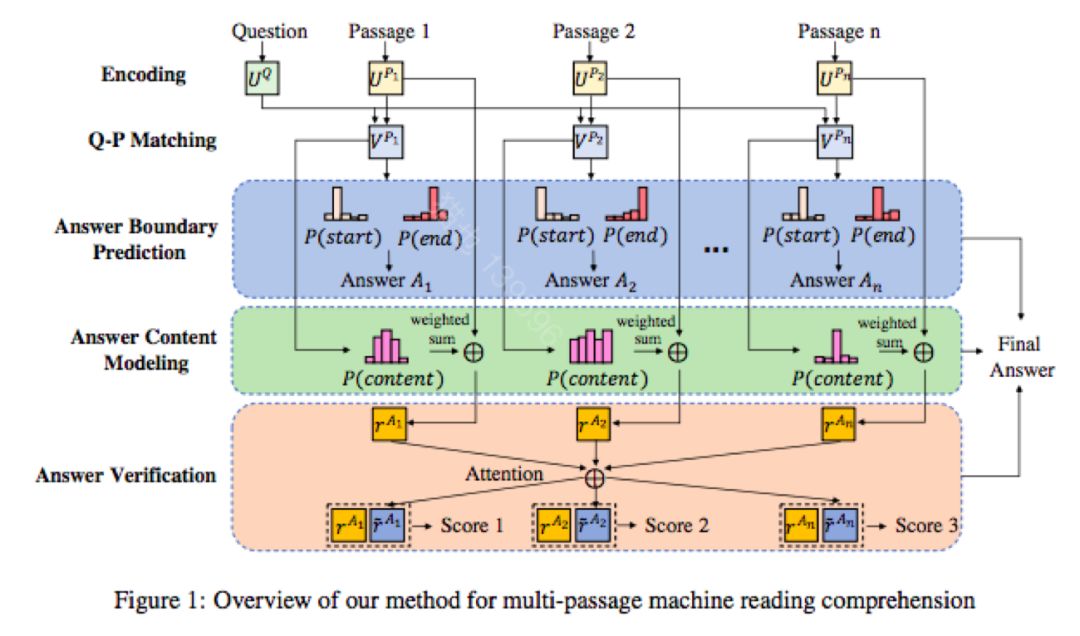
Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification
与单段落的机器阅读理解相比,多段落机器阅读理解的挑战在于不同的段落里可能含有相互混淆的内容。文章提出一个端到端的神经模型,使那些来自不同段落的答案候选者能够根据他们的内容表示来相互验证。具体来说,共同训练三个模块,可以根据三个因素预测最终答案:答案边界,答案内容和跨段落答案验证。
Domain adaptation 自适应
如下几篇文章的方法虽然传统,但是有效。
Strong baselines for neural semi-supervised learning under domain shift
基本结论是可以采用tri-training。就是三个模型在unlabeled数据上打标。对于某个数据,如果两个同意,就把这个数据与打标结果带入训练集,bootstrap训练集。这个方法虽然传统,但是比其它的方法,比如adversarial learning等有效。

Machine Learning 机器学习
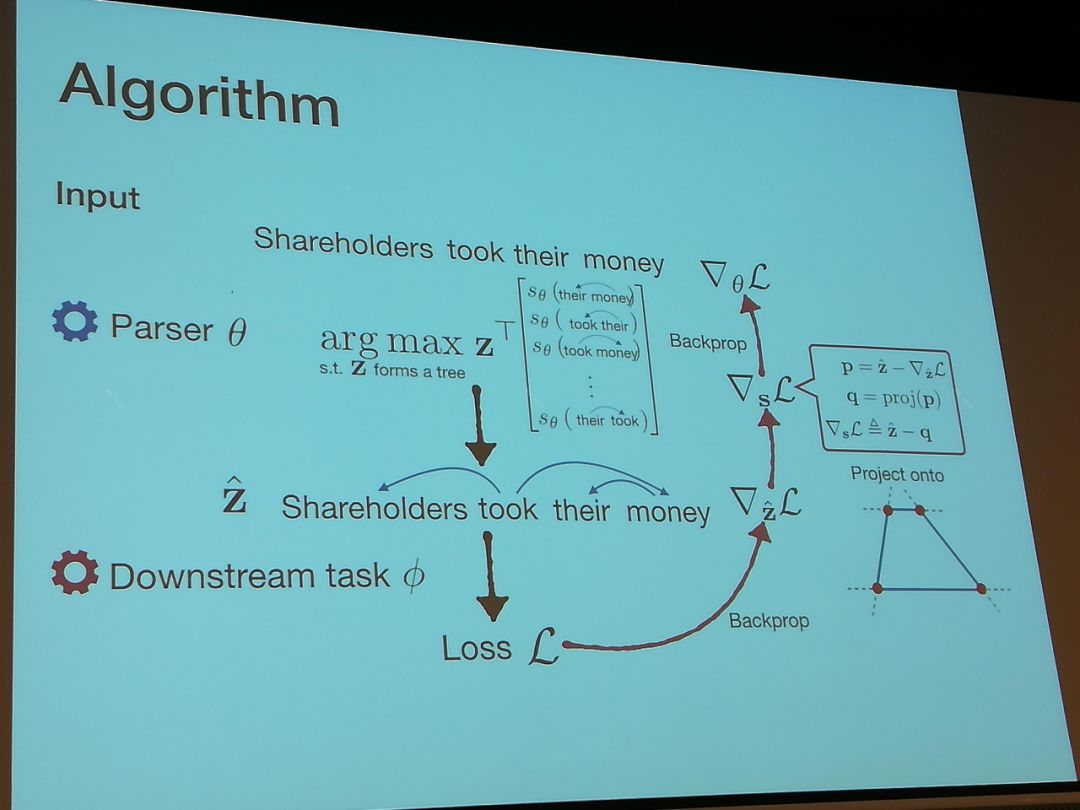
Backpropagating through structured argmax using a SPIGOT
在NLP的许多问题中,比如parsing等,有含有结构的结果。比如parsing产生的parsing tree就具有结构。产生这些结构的函数,比如argmax都不可以differentiate。此论文提出的算法是将这些argmax作为constraint,比如single headness是所有子节点到父节点的概率和为1.0。在做relaxation后,这个要求改为概率和小于等于1.0。再把gradient在做error back propagation时做个满足这些要求的投影。效果比skip-through要好些也严格些。
Text classification 文本分类
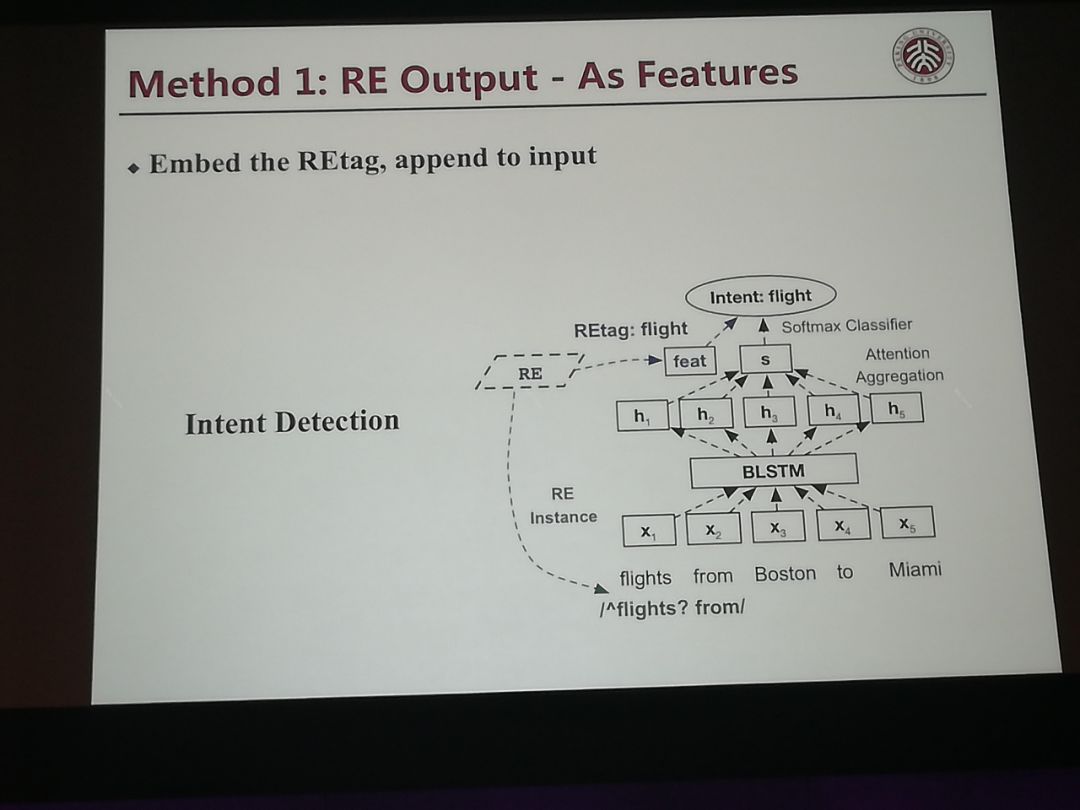
Marying up Regular Expressions with Neural Networks: A Case Study for Spoken Language Understanding
三个利用正则表达式的方法。第一个是将正则表达式的结果作为输入,但是用来作为soft-max的输入层,第二个是正则表达式中的热词,作为attention用到的输入。第三个方法是将正则表达式的输出和Neural Network的结果融合在一起。这个方法在我们的工作也早已实验过。
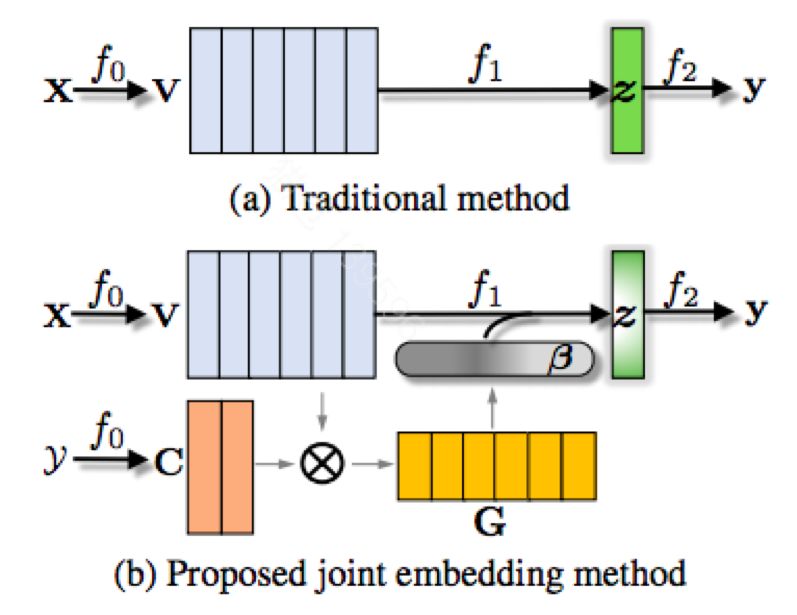
Joint embedding of words and labels for text classification
有些场景下,label中含有些词。比如“机票火车票”。之前的方法没有利用到这个信息。这片文章将label embedding也带入。用类似attention的方法,将word embedding的信息和label embedding的信息结合起来。其中,可以将“机票火车票”对应的label embedding用它的每个字的word embedding来做初始化。这个方法很新颖。
Universal Language Model Fine-tuning for Text Classification
先在大量数据上训练一个基于LSTM的语言模型,第二步再在target domain上细调语言模型,第三步再去细调classification模型。
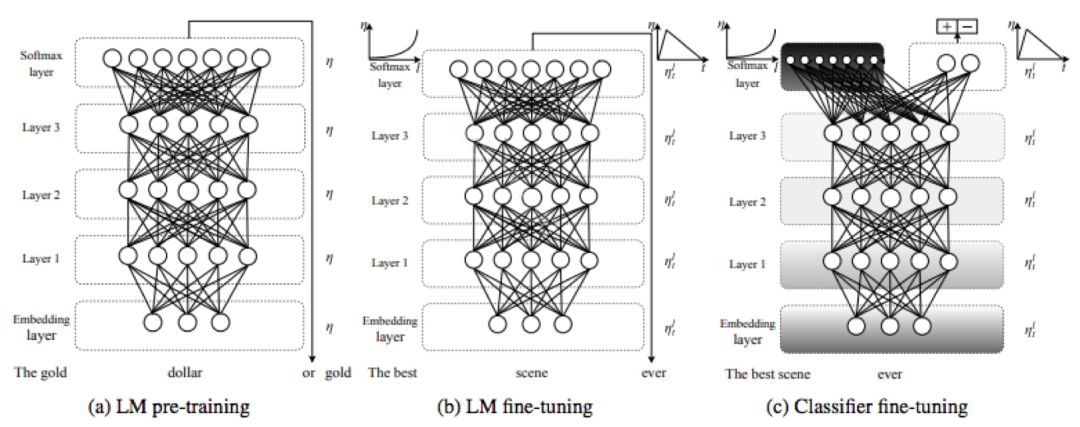
Unsupervised Random Walk Sentence Embeddings
这个方法考虑到了词频以及去除large variantions。

Summarization 归总
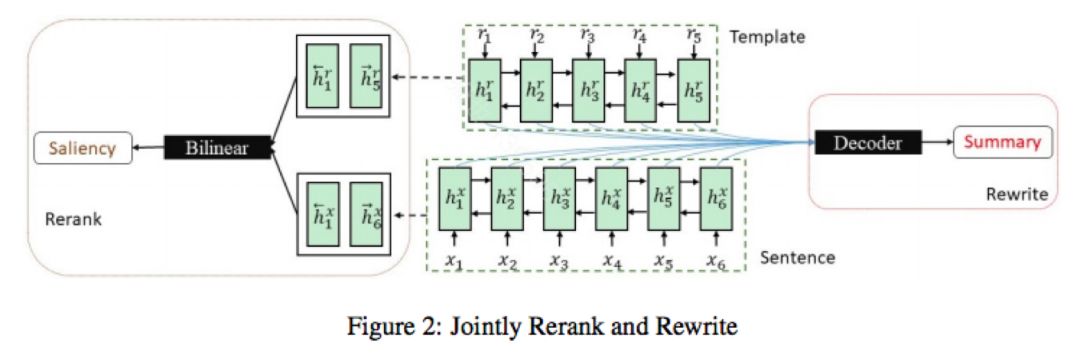
Retrieve, rerank and rewrite: soft template based neural summarization
采用第三方提供的IR结果,作为summarization的候选。再学习排序,以及基于这些IR结果为初始化的生成。 信息的来源包括IR获得的模版生成的summary与输入的saliency以及decoder生成的summary和reference summary的区分。
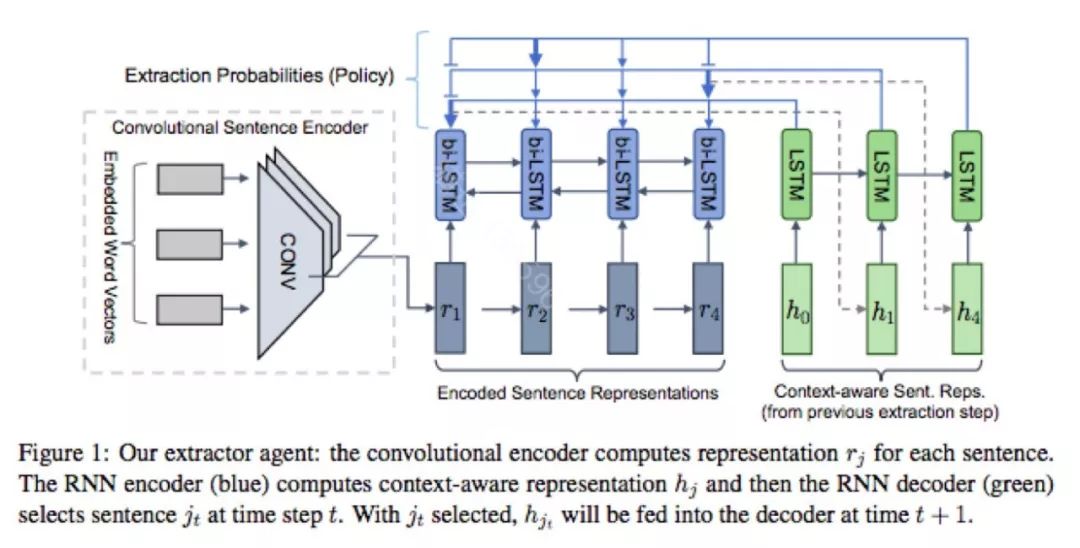
Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting
本文解决long document的summarization问题,通常包括2步, Extractor 和Abstractive。这里的extractor 负责从原文中抽取合适的句子,abstractive负责改写。抽取合适的句子采样强化学习的思路(A2C),reward 基于ROUGE。为了使训练更加稳定,两个部分分别做了pretrain。但是通常extractor并不会有标准答案句子,这里通过summary 去算原文句子里的相似度,来获取gold sentence。另外extractor 是基于point network.
Dialogue system 对话系统
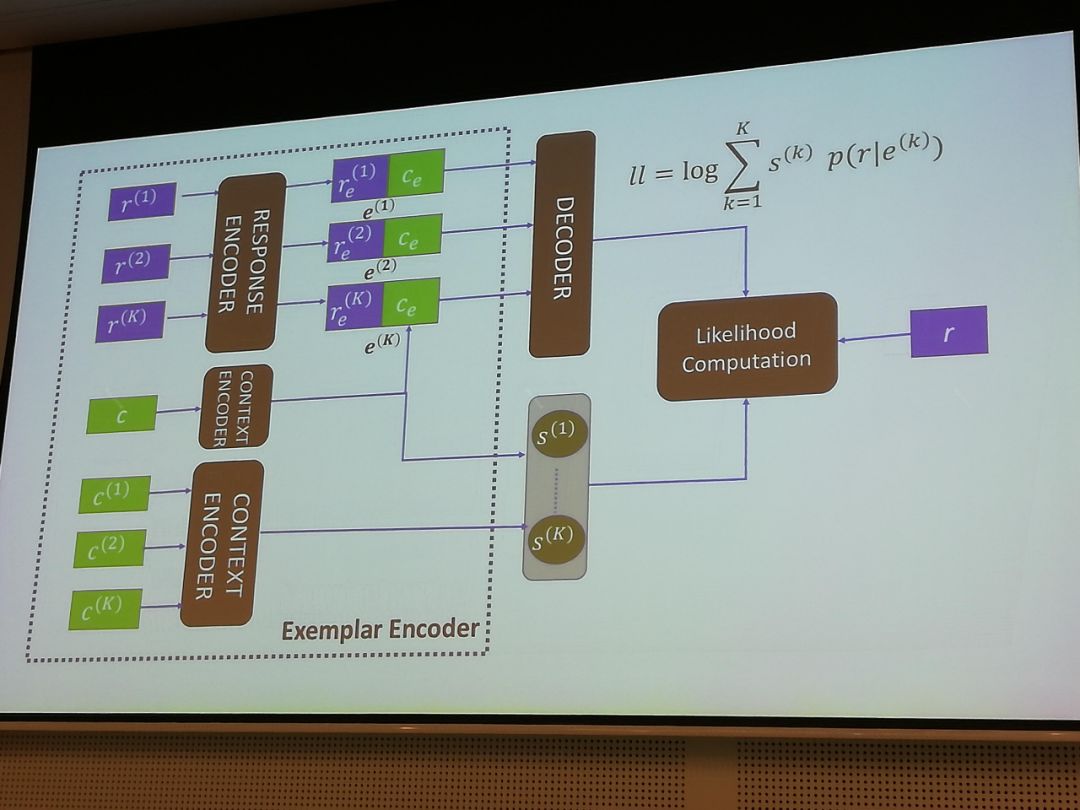
Examplar Encoder-Decoder for Neural Conversation Generation
基本思路是找到训练集中和当前输入query接近的context-response配对。训练的generator,是采用了这些配对所对应的权重的语言模型。

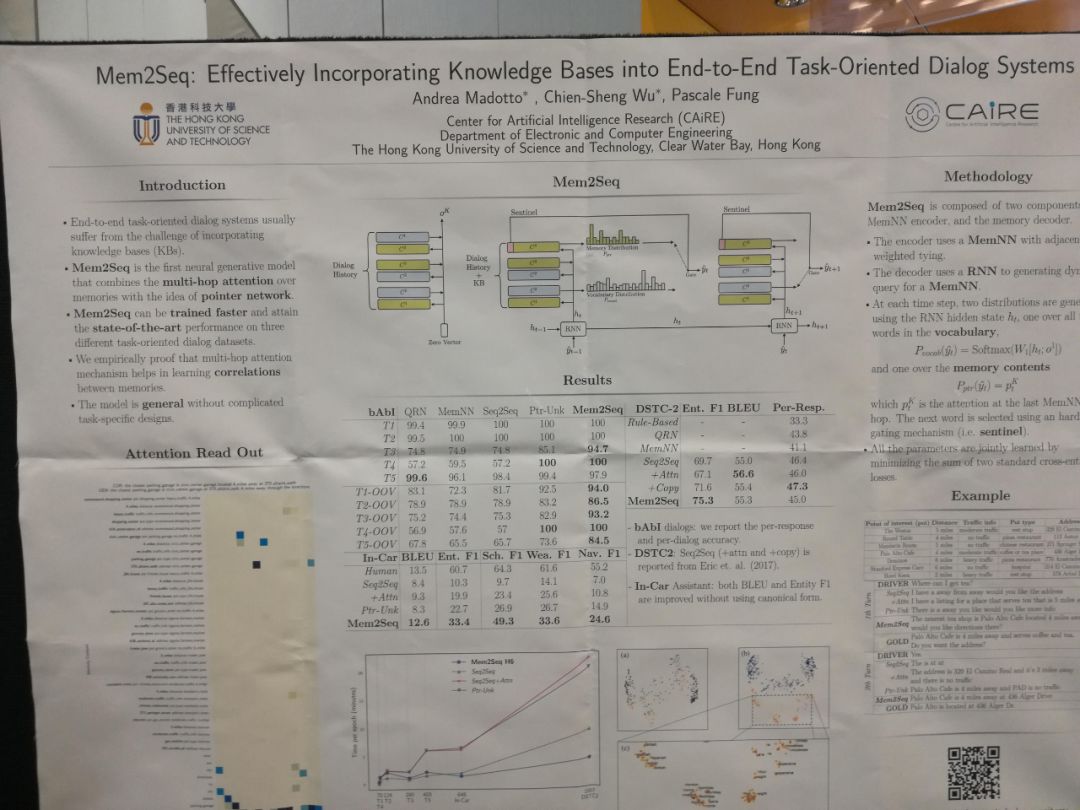
Mem2Seq: Effectively Incorporating Knowledge Bases into End-to-End Task-Oriented Dialog Systems
本文的主要思路是用memory来记录下过去的回答历史,并设定一classifier来判断是否可以从对话历史中提取反应。如果不能,则用一语言模型来提出反应。是一个结合了retrieval-based和generation-based的方法。
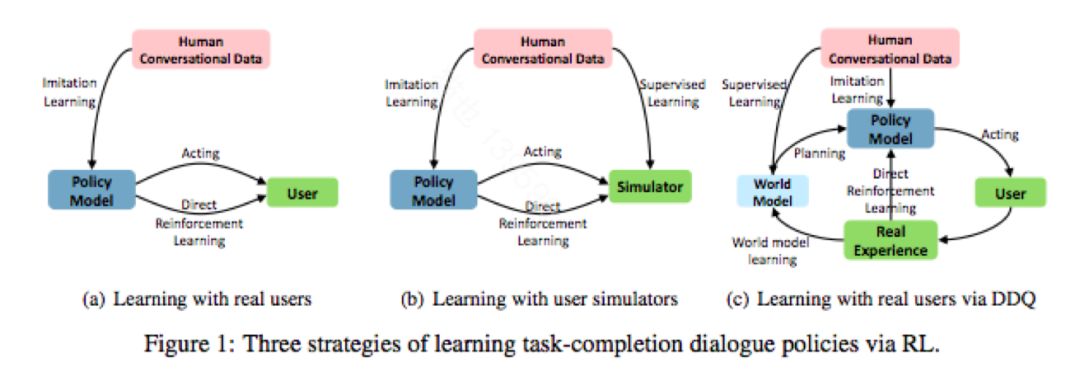
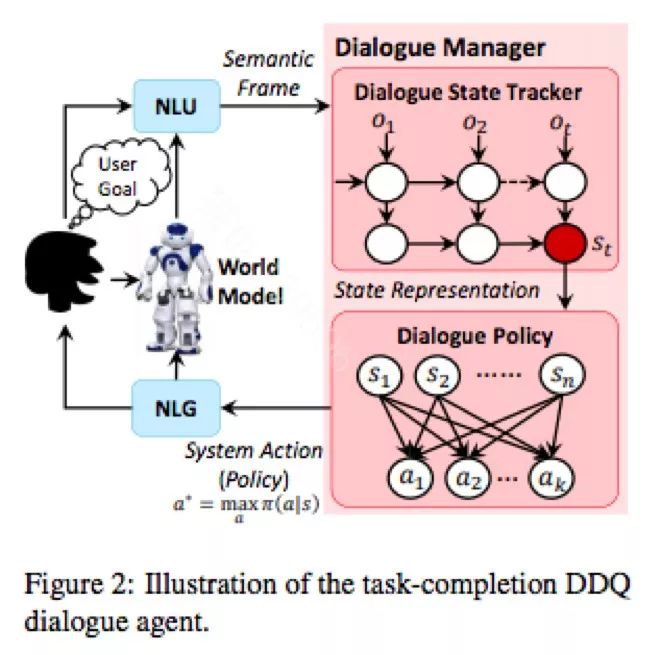
Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning
微软高剑锋等人有很系统的工作,值得去系统学习一下。他们今年ACL给了Tutorial,另外,还有一篇很有意思的论文Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning,主要将planning引入到强化学习算法框架中,将真实用户引入到模型学习中。
Generation 生成
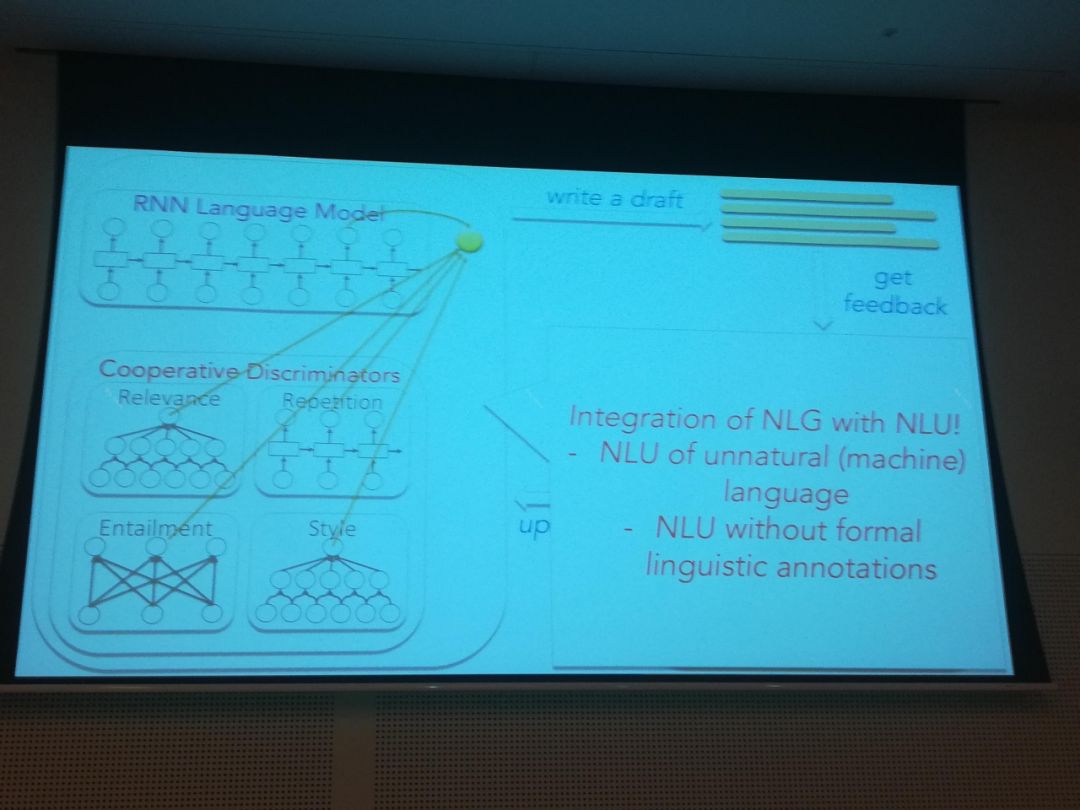
Learning to Write with Cooperative Discriminators
语音模型的打分要考虑关于生成的语言质量鉴别器。这些鉴别器包括“重复”、Entailment、Relevance和Lexical Style。请人来评比,比其它模型,比如Seq2Seq要效果更好。
Data 数据
MojiTalk: Generating Emotional Responses at Scale
从twitter上提取有emoji的对话。利用emoji作为打标来决定“replying to”所对应的text要生成的反应。因为可以从twitter上下载数据,所以可以生成大量的数据用来给”replying to”打标。

Tools 工具
https://github.com/marian-nmt/marian
重磅福利
一年一度的云栖大会(杭州9.19-9.22)即将到来,作为一枚贴心的小编,当然要给大家送上大大的福利啦!
在本文评论区留下你的参会想法,单条评论集满20个赞就可免费获赠云栖大会单日票一张!数量有限,赞多者得哦,小伙伴们快转发起来~!

— END —
蚂蚁金服科技,只为分享干货
您的转发是对我们最大的支持
欢迎在文章下方留言与我们进行交流哦~
以上是关于论文 | 自然语言处理顶会ACL 2018该关注什么?蚂蚁金服专家告诉你!的主要内容,如果未能解决你的问题,请参考以下文章