《2018自然语言处理研究报告》@清华-中国工程院知识智能联合实验室发布
Posted 软件定义世界(SDX)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《2018自然语言处理研究报告》@清华-中国工程院知识智能联合实验室发布相关的知识,希望对你有一定的参考价值。
热门下载(点击标题即可阅读)
摘自AMiner
机器之心整理
参与:李亚洲、思源
自然语言处理是现代技术最重要的组成部分之一,而最近清华大学和中国工程院知识智能联合实验室发布一份非常全面的 NLP 报告。该报告从 NLP 的概念介绍、研究与应用情况、专家学者概要以及发展趋势这 5 个方向纵览了这一领域的当下与未来,机器之心简要介绍了该报的概要信息,但读者可以从这些方面纵览 NLP 的发展面貌,完整内容请下载查看原报告。
根据 AMiner 研究报告的摘要所述,分析师们主要从以下五个方向六大章节梳理自然语言处理的发展状况:
自然语言处理概念。首先对自然语言处理进行定义,接着对自然语言的发展历程进行了梳理,对我国自然语言处理现状进行了简单介绍,对自然语言处理业界情况进行介绍。
自然语言处理研究情况。依据 2016 年中文信息学会发布的中文信息处理发展报告对自然语言处理研究中的重要技术进行介绍。
自然语言处理领域专家介绍。利用 AMiner 大数据对自然语言处理领域专家进行深入挖掘,对国内外自然语言处理知名实验室及其主要负责人进行介绍。
自然语言处理的应用及趋势预测。自然语言处理在现实生活中应用广泛,目前的应用集中在语言学、数据处理、认知科学以及语言工程等领域,在介绍相关应用的基础上,对机器翻译未来的发展趋势做出了相应的预测。
1 概述篇
在概述篇中,该报告重点介绍了自然语言处理的概念、发展历程、我国 NLP 目前的发展状况和业界的研究与应用。
1.1 自然语言处理概念
自然语言是指汉语、英语、法语等人们日常使用的语言,是自然而然的随着人类社会发 展演变而来的语言,而不是人造的语言,它是人类学习生活的重要工具。概括说来,自然语 言是指人类社会约定俗成的,区别于人工语言,如程序设计的语言。
自然语言处理,是指用计算机对自然语言的形、音、 义等信息进行处理,即对字、词、句、篇章的输入、输出、识别、分析、理解、生成等的操作和加工。实现人机间的信息交流,是人工智能界、计算机科学和语言学界所共同关注的重要问题。自然语言处理的具体表现形式包括机器翻译、文本摘要、文本分类、文本校对、信息抽取、语音合成、语音识别等。可以说,自然语言处理就是要计算机理解自然语言,自然语言处理机制涉及两个流程,包括自然语言理解和自然语言生成。
1.2 自然语言处理发展历程
自然语言处理是包括了计算机科学、语言学心理认知学等一系列学科的一门交叉学科,这些学科性质不同但又彼此相互交叉。因此,梳理自然语言处理的发展历程对于我们更好地了解自然语言处理这一学科有着重要的意义。
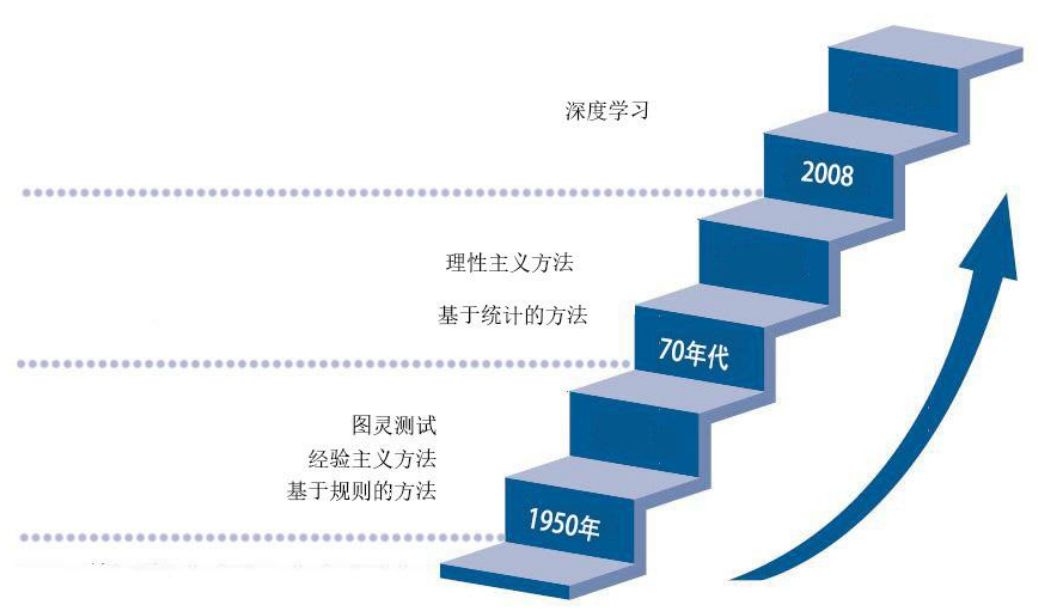
从 2008 年到现在,在图像识别和语音识别领域的成果激励下,人们也逐渐开始引入深度学习来做自然语言处理研究,由最初的词向量到 2013 年 word2vec,将深度学习与自然语言处理的结合推向了高潮,并在机器翻译、问答系统、阅读理解等领域取得了一定成功。深 度学习是一个多层的神经网络,从输入层开始经过逐层非线性的变化得到输出。从输入到输出做端到端的训练。把输入到输出对的数据准备好,设计并训练一个神经网络,即可执行预想的任务。RNN 已经是自然语言护理最常用的方法之一,GRU、LSTM 等模型相继引发了一轮又一轮的热潮。
1.3 我国自然语言处理现状
目前自然语言处理的研究可以分为基础性研究和应用性研究两部分,语音和文本是两类 研究的重点。基础性研究主要涉及语言学、数学、计算机学科等领域,相对应的技术有消除歧义、语法形式化等。应用性研究则主要集中在一些应用自然语言处理的领域,例如信息检索、文本分类、机器翻译等。由于我国基础理论即机器翻译的研究起步较早,且基础理论研究是任何应用的理论基础,所以语法、句法、语义分析等基础性研究历来是研究的重点,而且随着互联网网络技术的发展,智能检索类研究近年来也逐渐升温。
1.4 自然语言处理业界发展

1. Google
Google 是最早开始研究自然语言处理技术的团队之一,作为一个以搜索为核心的公司,Google 对自然语言处理更为重视。Google 拥有着海量数据,可以搭建丰富庞大的数据库,可以为其研究提供强大的数据支撑。Google 对自然语言处理的研究侧重于应用规模、跨语言和跨领域的算法,其成果在 Google 的许多方面都被使用,提升了用户在搜索、移动、应用、广告、翻译等方面的体验。
2. 百度
百度自然语言处理部是百度最早成立的部门之一,研究涉及深度问答、阅读理解、智能 写作、对话系统、机器翻译、语义计算、语言分析、知识挖掘、个性化、反馈学习等。其中,百度自然语言处理在深度问答方向经过多年打磨,积累了问句理解、答案抽取、观点分析与 聚合等方面的一整套技术方案,目前已经在搜索、度秘等多个产品中实现应用。篇章理解通过篇章结构分析、主体分析、内容标签、情感分析等关键技术实现对文本内容的理解,目前,篇章理解的关键技术已经在搜索、资讯流、糯米等产品中实现应用。百度翻译目前支持全球 28 种语言,覆盖 756 个翻译方向,支持文本、语音、图像等翻译功能,并提供精准人工翻 译服务,满足不同场景下的翻译需求,在多项翻译技术取得重大突破,发布了世界上首个线 上神经网络翻译系统。
3. 阿里巴巴
阿里自然语言处理为其产品服务,在电商平台中构建知识图谱实现智能导购,同时进行全网用户兴趣挖掘,在客服场景中也运用自然语言处理技术打造机器人客服,例如蚂蚁金融智能小宝、淘宝卖家的辅助工具千牛插件等,同时进行语音识别以及后续分析。阿里的机器翻译主要与其国家化电商的规划相联系,可以进行商品信息翻译、广告关键词翻译、买家采 购需求以及即时通信翻译等,语种覆盖中文、荷兰语、希伯来语等语种,2017 年初阿里正式 上线了自主开发的神经网络翻译系统,进一步提升了其翻译质量。
4. 腾讯
AI Lab 是腾讯的人工智能实验室,研究领域包括计算机视觉、语音识别、自然语言处理、机器学习等。其研发的腾讯文智自然语言处理基于并行计算、分布式爬虫系统,结合独特的语义分析技术,可满足自然语言处理、转码、抽取、数据抓取等需求,同时,基于文智 API 还可以实现搜索、推荐、舆情、挖掘等功能。在机器翻译方面,2017 年腾讯宣布翻译君 上线「同声传译」新功能,用户边说边翻的需求得到满足,语音识别+NMT 等技术的应用保证了边说边翻的速度与精准性。
除此之外,该报告还介绍了微软亚洲研究院、Facebook、京东和科大讯飞等在 NLP 方面有非常多研究与应用的机构。
2 技术篇
自然语言处理的研究领域极为广泛,各种分类方式层出不穷,各有其合理性,我们按照中国中文信息学会 2016 年发布的《中文信息处理发展报告》,将自然语言处理的研究领 域和技术进行以下分类,并选取其中部分进行介绍。
基础技术:词法与句法分析、语义分析、语篇分析、知识图谱、语言认知模型、语言知识表示和深度学习
应用技术:机器翻译、信息检索、情感分析、自动问答、自动文摘、信息抽取、信息推荐与过滤、文本分类与聚类、文字识别
2.1 自然语言处理基础技术
自然语言的基础技术包括词汇、短语、 句子和篇章级别的表示,以及分词、句法分析和语义分析以及语言认知模型和知识图谱等。
2.1.1 词法、句法及语义分析
词法分析的主要任务是词性标注和词义标注。词性是词汇的基本属性,词性标注就是在 给定句子中判断每个词的语法范畴,确定其词性并进行标注。解决兼类词和确定未登录词的 词性问题是标注的重点。进行词性标注通常有基于规则和基于统计的两种方法。一个多义词往往可以表达多个意义,但其意义在具体的语境中又是确定的,词义标注的重点就是解决如何确定多义词在具体语境中的义项问题。标注过程中,通常是先确定语境,再明确词义,方 法和词性标注类似,有基于规则和基于统计的做法。
判断句子的句法结构和组成句子的各成分,明确它们之间的相互关系是句法分析的主要任务。句法分析通常有完全句法分析和浅层句法分析两种,完全句法分析是通过一系列的句法分析过程最终得到一个句子的完整的句法树。句法分析方法也分为基于规则和基于统计的
方法,基于统计的方法是目前的主流方法,概率上下文无关文法用的较多。完全句法分析存 在两个难点,一是词性歧义;二是搜索空间太大,通常是句子中词的个数 n 的指数级。浅层句法分析又叫部分句法分析或语块分析,它只要求识别出句子中某些结构相对简单的成分如 动词短语、非递归的名词短语等,这些结构被称为语块。一般来说,浅层语法分析会完成语块的识别和分析、语块之间依存关系的分析两个任务,其中语块的识别和分析是浅层语法分析的主要任务。
语义分析是指根据句子的句法结构和句子中每个实词的词义推导出来能够反映这个句 子意义的某种形式化表示,将人类能够理解的自然语言转化为计算机能够理解的形式语言。句子的分析与处理过程,有的采用「先句法后语义」的方法,但「句法语义一体化」的策略 还是占据主流位置。语义分析技术目前还不是十分成熟,运用统计方法获取语义信息的研究颇受关注,常见的有词义消歧和浅层语义分析。
自然语言处理的基础研究还包括语用语境和篇章分析。语用是指人对语言的具体运用,研究和分析语言使用者的真正用意,它与语境、语言使用者的知识涵养、言语行为、想法和 意图是分不开的,是对自然语言的深层理解。情景语境和文化语境是语境分析主要涉及的方 面,篇章分析则是将研究扩展到句子的界限之外,对段落和整篇文章进行理解和分析。
除此之外,自然语言的基础研究还涉及词义消歧、指代消解、命名实体识别等方面的研 究。
2.1.2 知识图谱
知识图谱,是为了表示知识,描述客观世界的概念、实体、事件等之间关系的一种表示 形式。这一概念的起源可以追溯至语义网络——提出于 20 世纪五六十年代的一种知识表示 形式。语义网络由许多个「节点」和「边」组成,这些「节点」和「边」相互连接,「节点」表示的是概念或对象,「边」表示各个节点之间的关系。
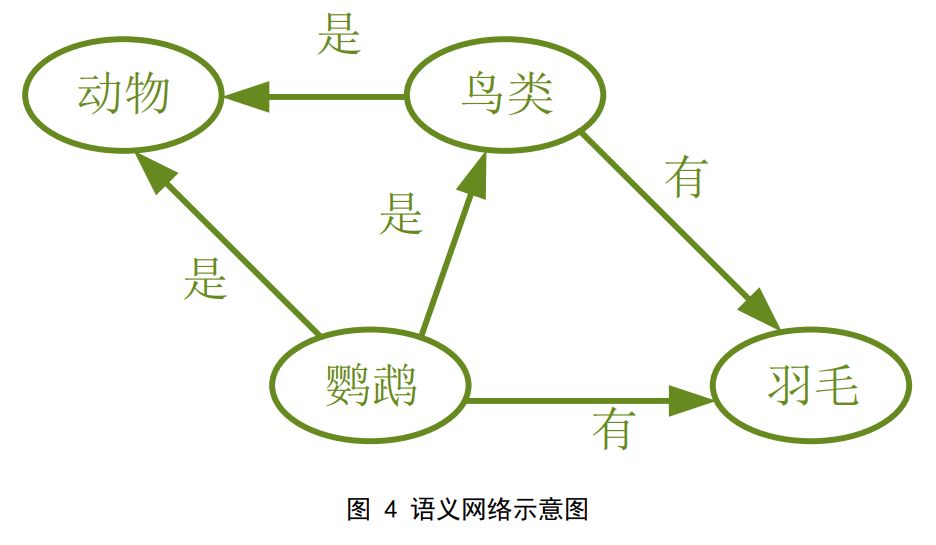
知识图谱在表现形式上与语义网络比较类似,不同的是,语义网络侧重于表示概念与概 念之间的关系,而知识图谱更侧重于表述实体之间的关系。现在的知识网络被用来泛指大规 模的知识库,知识图谱中包含的节点有以下几种:
实体:指独立存在且具有某种区别性的事物。如一个人、一种动物、一个国家、一种植物等。
语义类:具有同种特性的实体构成的集合,如人类、动物、国家、植物等。
内容:通常是实体和语义类的名字、描述、解释等,变现形式一般有文本、图像、音视 频等。
属性(值):主要指对象指定属性的值,不同的属性类型对应于不同类型属性的边。
关系:在知识图谱上,表现形式是一个将节点(实体、语义类、属性值)映射到布尔值 的函数。
知识图谱表示、构建和应用涉及很多学科,是一项综合的复杂技术。知识图谱技术既涉 及自然语言处理中的各项技术,从浅层的文本向量表示、到句法和语义结构表示被适用于资源内容的表示中,分词和词性标注、命名实体识别、句法语义结构分析、指代分析等技术被 应用于自然语言处理中。同时,知识图谱的研究也促进了自然语言处理技术的研究,基于知 识图谱的词义排岐和语义依存关系分析等知识驱动的自然语言处理技术得以建立。
2.2 自然语言处理应用技术
2.2.1 机器翻译
机器翻译(Machine Translation)是指运用机器,通过特定的计算机程序将一种书写形式 或声音形式的自然语言,翻译成另一种书写形式或声音形式的自然语言。机器翻译是一门交 叉学科(边缘学科),组成它的三门子学科分别是计算机语言学、人工智能和数理逻辑,各 自建立在语言学、计算机科学和数学的基础之上。
目前,文本翻译最为主流的工作方式依然是以传统的统计机器翻译和神经网络翻译为主。Google、Microsoft 与国内的百度、有道等公司都为用户提供了免费的在线多语言翻译系统。速度快、成本低是文本翻译的主要特点,而且应用广泛,不同行业都可以采用相应的专业翻译。但是,这一翻译过程是机械的和僵硬的,在翻译过程中会出现很多语义语境上的问题,仍然需要人工翻译来进行补充。
语音翻译可能是目前机器翻译中比较富有创新意思的领域,搜狗推出的机器同传 技术主要在会议场景出现,演讲者的语音实时转换成文本,并且进行同步翻译,低延迟显示 翻译结果,希望能够取代人工同传,实现不同语言人们低成本的有效交流。
图像翻译也有不小的进展。谷歌、微软、Facebook 和百度均拥有能够让用户搜索或者自动整理没有识别标签照片的技术。除此之外还有视频翻译和 VR 翻译也在逐渐应用中,但是目前的应用还不太成熟。
2.2.2 信息检索
信息检索是从相关文档集合中查找用户所需信息的过程。信息检索的基本原理是将用户输入的检索关键词与数据库 中的标引词进行对比,当二者匹配成功时,检索成功。
以谷歌为代表的「关键词查询+选择性浏览」交互方式,用户用简单的关键词作为查询 提交给搜索引擎,搜索引擎并非直接把检索目标页面反馈给用户,而是提供给用户一个可能 的检索目标页面列表,用户浏览该列表并从中选择出能够满足其信息需求的页面加以浏览。
2.2.4 自动问答
自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。自动问答系统在回答用户问题时,首先要正确理解用户所提出的问题,抽取其中关键的信息,在已有的语料库或者知识库中进行检索、匹配,将获取的答案反馈给用户。这一过程 涉及了包括词法句法语义分析的基础技术,以及信息检索、知识工程、文本生成等多项技术。
根据目标数据源的不同,问答技术大致可以分为检索式问答、社区问答以及知识库问答 三种。检索式问答和社区问答的核心是浅层语义分析和关键词匹配,而知识库问答则正在逐步实现知识的深层逻辑推理。
除了这几种 NLP 应用,其它如情感分析、自动文本摘要、社会计算和信息抽取也都有广泛的应用,读者可查阅原报告了解详细内容。
3 人才篇
3.1 国外实验室及人才介绍
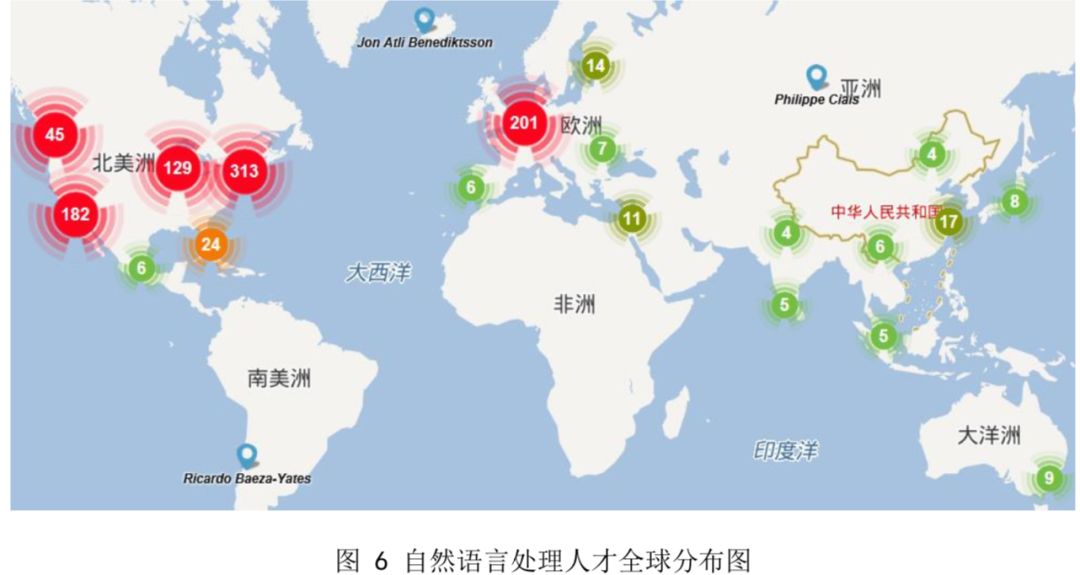
AMiner 基于发表于国际期刊会议的学术论文,对自然语言处理领域全球 h-index 排序 top1000 的学者进行计算分析,绘制了该领域顶尖学者全球分布地图。
这部分内容中,AMiner 还选取在 ACL、EMNLP、NAACL、COLING 等 4 个会议在近 5 年累计发表 10 次以上论文的国外学者及其所在实验室做简要介绍。包括:
Chris Dyer,卡内基梅隆大学语言技术研究所
Christopher D. Manning,斯坦福大学自然语言处理小组
Dan Klein,伯克利大学自然语言处理小组
除了以上提到的,国外还有一些知名自然语言处理实验室 :
圣母大学自然语言处理小组,负责人是 David Chiang
哈佛自然语言处理小组,负责人是 Stuart Shieber
哥伦比亚大学自然语言处理研究室,负责人为 Michael Collins
3.2 国内实验室及人才介绍
这部分,AMiner 基于论文数据整理了自然语言处理华人专家库,其中包括了来自 NUS、HKUS、 THU、PKU、FDU 等知名高校以及百度、科大讯飞、微软等公司的 367 位专家学者。
而后,AMiner 选取在 ACL、EMNLP、NAACL、COLING 等 4 个会议在近 5 年累计发表 10 次以 上论文的国内学者包括刘群、刘挺、周明、常宝宝、黄萱菁、刘洋、孙茂松、李素建、万小 军、邱锡鹏、穗志方等。

图:国内学者介绍示例
3.3 ACL2018 奖项介绍
2018 年 7 月 15 在墨尔本开幕的 ACL 公布了其最佳论文名单,包括 3 篇最佳长论文和 2 篇最佳短论文以及 1 篇最佳 demo 论文,值得一提的是 Amazon Door Prize 中北京大学和 哈工大 上榜,ACL2018 终身成就奖为爱丁堡大学 Mark Steedman 获得。
接下来,该报告对获奖论文进行了摘要介绍。读者们也可以参考机器之心文章《计算语言顶会 ACL 2018 最佳论文公布!这些大学与研究员榜上有名》
4. 应用篇
从知识产业角度来看,自然语言处理软件占有重要的地位,专家系统、数据库、知识库,计算机辅助设计系统 (CAD)、计算机辅助教学系统 (Cal)、计算机辅助决策系统、办公室 自动化管理系统、智能机器人等,全都需要自然语言做人机界面。长远看来,具有篇章理解 能力的自然语言理解系统可用于机器自动翻译、情报检索、自动标引及自动文摘等领域,有着广阔的应用前景。
随着自然语言处理研究的不断深入和发展,应用领域越来越广。
文本方面的应用主要有:基于自然语言理解的智能搜索引擎和智能检索、智能机器翻译、 自动摘要与文本综合、文本分类与文件整理、智能自动作文系统、自动判卷系统、信息过滤 与垃圾邮件处理、文学研究与古文研究、语法校对、文本数据挖掘与智能决策以及基于自然 语言的计算机程序设计等。
语音方面的应用主要有:机器同声传译、智能远程教学与答疑、语音控制、智能客户服 务、机器聊天与智能参谋、智能交通信息服务 (ATIS)、智能解说与体育新闻实时解说、语 音挖掘与多媒体挖掘、多媒体信息提取与文本转化以及对残疾人智能帮助系统等。
此外,建立在自然语言处理技术基础之上的心理学、认知学、哲学、混沌学说的共同发展,将使人们对智能的起源问题有新的认识。如果把计算机网络和未来的网格看作是由机器 组成的机器社会,那么一种属于机器的智能可能会因为人类的参与以及机器社会中各元素的相互作用而自然诞生。这样,机器必将能够通过「图灵测试」,达到「会思考」的层次。而 有关智能机器的研究也会诞生一系列新的领域,比如,机器心理学和机器认知学等。
其中,机器心理学主要研究机器的心理反应和意图。美国圣迭戈神经科学研究所研制的 机器人 DarwinV II,能够根据其感知对外部事物进行分类,并根据经验和知识采取相应的对策。然而,机器心理学的研究不能局限于此,人们还需要对机器的意识、知觉、思想、情感、 情绪、创造力、机器社会、机器交流等方面进行研究,而这一切还需要计算机科学、心理学、 神经科学的同步发展。
而后,AMiner 选取了一些自然语言处理应用较为频繁的场景进行介绍,如知识图谱、机器翻译、推荐系统等。
5 趋势篇
随着深度学习时代的来临,神经网络成为一种强大的机器学习工具,自然语言处理取得了许多突破性发展,情绪分析、自动问答、机器翻译等领域都飞速发展。
下图分别是 AMiner 计算出的自然语言处理近期热点和全球热点。通过对 1994-2017 年间自然语言处理领域有关论文的挖掘,总结出二十多年来,自然语言处理的领域关键词主要集中在计算机语言、神经网络、情感分析、机器翻译、词义消歧、信息提取、知识库和文本 分析等领域。旨在基于历史的科研成果数据的基础上,对自然语言处理热度甚至发展趋势进行研究。图中,每个彩色分支表示一个关键词领域,其宽度表示该关键词的研究热度,各关键词在每一年份(纵轴)的位置是按照这一时间点上所有关键词的热度高低进行排序。
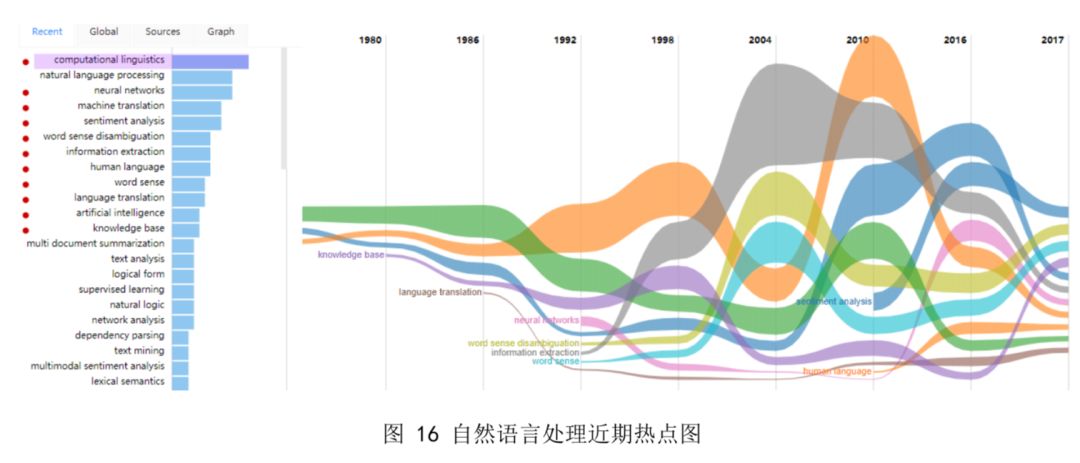
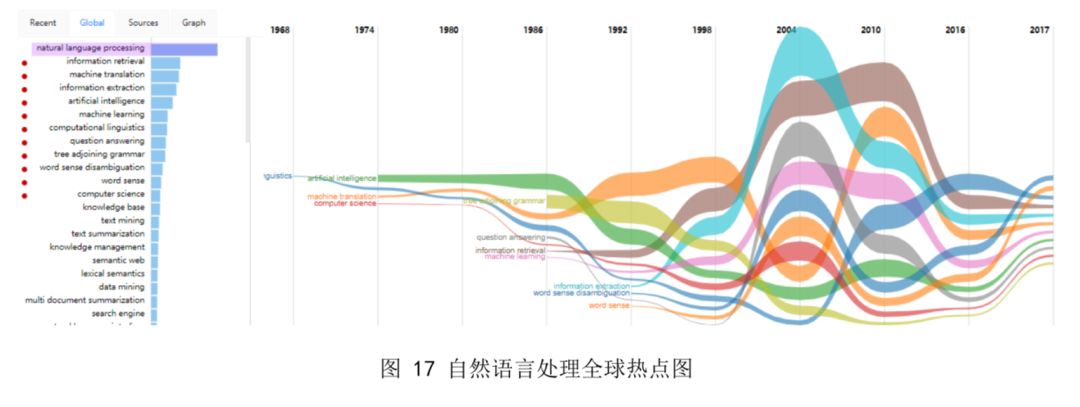
图 16 显示,情绪分析、词义消歧、知识库和计算机语言学将是最近的热点发展趋势,图 17 显示词义消歧、词义理解、计算机语言学、信息检索和信息提取将是自然语言处理全 球热点。
AMiner 同时在微博 @ArnetMiner 中发起了关于自然语言处理未来发展趋势的投票,得到了如下结果。


读BD最佳实践案例,赢DT未来!【政、工、农册免费在线试读】
18各行业,106个中国大数据应用最佳实践案例:
(1)《赢在大数据:中国大数据发展蓝皮书》;
(2)《赢在大数据:金融/电信/媒体/医疗/旅游/数据市场行业大数据应用典型案例》;
(3)《赢在大数据:营销/房地产/汽车/交通/体育/环境行业大数据应用典型案例》;
(4)《赢在大数据:政府/工业/农业/安全/教育/人才行业大数据应用典型案例》。【本册免费在线试读,PC打开连接:https://item.jd.com/12058567.html】
以上是关于《2018自然语言处理研究报告》@清华-中国工程院知识智能联合实验室发布的主要内容,如果未能解决你的问题,请参考以下文章