自然语言处理 | 统计语言模型
Posted 斜述视角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理 | 统计语言模型相关的知识,希望对你有一定的参考价值。
我们聊一下自然语言处理(NLP)这一方向,当前的语音识别,机器翻译等人工智能领域备受欢迎和关注,那么计算机到底是怎么处理自然语言的,换句话说:计算机真的像人一样能够理解我们人类独特的语言吗?
在自然语言处理研究的早期,计算机科学家们走入了一个误区:当时,学术界普遍认为,要让计算机能够有效的处理自然语言,首先就是让计算机能像人类一样去理解自然语言。一致认为计算机应先做好两件事,即分析语句和获取语义。
计算机科学家们在此后的工作中发现,人类的语法规则实在太多,根本不可能穷尽,人类20%的语言,语法规则的数量也至少是几万条,语言学家们在有生之年怕是写不完的。这些语法规则写到后面甚至会出现前后矛盾。
自然语言从诞生之初起,就是一种具有上下文相关特征的语言。
人类的语言是存在歧义性的,比如:“I am a boy”。在大部分的场景里,这句英文的译文应是:“我是个男孩”。然而,总是翻译成“我是个男孩”并不一定是最佳的译文。如果是在饭店的场景里,“boy”一词更恰当的翻译是“服务生”。可是这种语言的歧义性,我们在日常生活中是怎么克服的呢?
我们所依靠的是上下文,有时人类是弄不清一句话它到底表示其中哪个含义,而解决这个问题的方法,就是依靠上下文。有了上下文,大多数情况下多义词就可以确定具体意思。
因此,计算机在处理自然语言时,一个基本问题就是为自然语言这种上下文相关的特征建立数学模型。
统计语言模型
1970年弗里德里克·贾里尼克针对自然语言处理的困境提出一个新观点:一个句子是否合理,就看它出现的可能性大小如何。如果可以通过某种数学方法计算得到一个句子能够出现的概率 ,那么概率越大的句子也可能出现。
比如,“我爱美丽的花”、“花的美丽爱我”,这两句话显然是第一句话更可能出现,相比整个人类使用汉语的历史长河中,都很少会出现第二句话。
假定S表示一句有意义的话,由一连串特定的按顺序排列的词组成,词分别是:
我们想知道S在文本中出现的可能性,即计算P(S)。
由题意知:
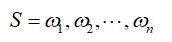
即:
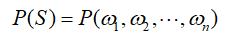
利用条件概率,S这个词序列出现的概率等于每个词出现的概率相乘,可以写成如下:
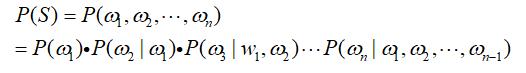
不难看出,每一个词出现的概率取决于其前面出现的所有词。然而随着作为条件一方的词语数量的增多,计算开始变得复杂。人们想到了一个偷懒但是还颇为有效的方法,假定每一个词出现的概率只与前面一个词有关(马尔科夫假设)。这时,上述公式可以简化为:
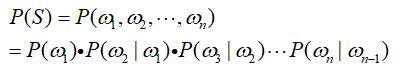
接下来的问题就是计算:
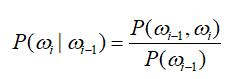
计算机库中存储了大量的人类的语言文本,即语料库。只要用计算机数一数
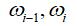 这一对相邻的词语,以及
这一对相邻的词语,以及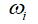 这个词在整个语料库中出现的频数即可(N表示整个语料库,f表示词语在语料库中的相对频度):
这个词在整个语料库中出现的频数即可(N表示整个语料库,f表示词语在语料库中的相对频度):
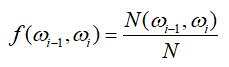
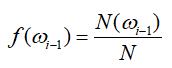
当语料库足够大时,根据大数定理,概率约等于频度:
约分化简后,可得:
证明完毕!
综上所述,计算机可以不用懂语法,只需要会算一点概率就行啦。
文章参考自:
1、吴军《数学之美》第二版;
2、CSDN许野平的专栏:为什么使用计算机处理自然语言如此困难。
以上是关于自然语言处理 | 统计语言模型的主要内容,如果未能解决你的问题,请参考以下文章