自然语言处理时,通常的文本清理流程是什么?
Posted 优达学城Udacity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理时,通常的文本清理流程是什么?相关的知识,希望对你有一定的参考价值。
在自然语言处理时候,经常有粉丝会问:“尽管文本清理受所做的任务影响很大,但是否有一些标准的清理流程,以及这些清理背后的逻辑。比如,是否有必要替换URLs,时间,货币,姓名,地名,数字等。”
这次,优达菌请到了我们Udacity无人驾驶课程经理 Aaron,给大家带来对这个问题的看法和解答。
我们以英文文本处理为例。大致分为以下几个步骤:
Normalization
Tokenization
Stop words
Part-of-Speech Tagging
Named Entity Recognition
Stemming and Lemmatization
Normalization
得到纯文本文件后,第一步通常做的就是 Normalization。
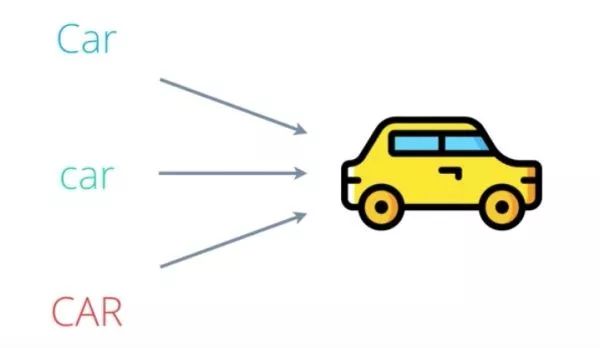
在英语语言中,所有句子第一个词的首字母一般是大写。有时候全部大写,用于表示强调和区分风格。这对人类读者而言非常方便。但从机器学习算法角度来说,无法区分'Car'/'car'/'CAR'。它们都是一个意思。因此我们一般把文本中的所有字母统一转换成大写或者小写(通常情况是小写),每一个词用一个唯一的词来表示。
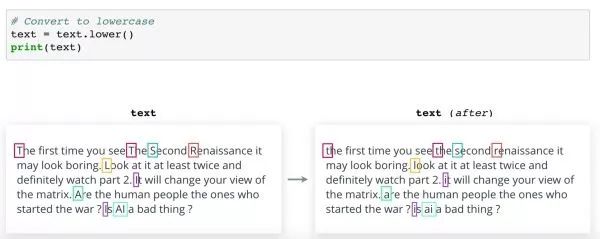
上图这是文本样本,是电影《The Second Renaissance》的一段影评。这部电影是关于智能机器人对人类发动战争,争取权利的故事。如果将影评存储在名为“文本”的变量中,将其转换成小写,只需在 Python 中调用 lower() 方法即可。这是转换后的样子。请注意更改的所有字母。其他语言可能有,也可能没有对应的大小写。但是根据你的 NLP 任务的不同,类似原理可能也适用。
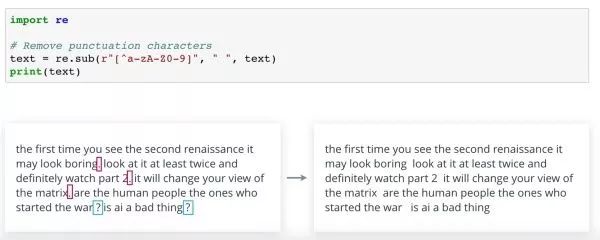
你可能还想清除文本中的句号、问号、感叹号等。特殊字符,并且仅保留字母表中的字母和数字。文档分类和聚类等应用中若要将所有文本文档作为一个整体,那么正则表达式这个方法特别有效。这里,可以匹配小写'a'至'z'大写'A'至'Z'或者数字'0'到'9'的范围之外的所有字符并用空格代替。这个方法无需指定所有标点符号。 但是,也可以采用其它正则表达式。
小写转换和标点移除是两个最常见的文本 Normalization 步骤。是否需要以及在哪个阶段使用这两个步骤取决于你的最终目标。
Tokenization
Token 是“符号”的高级表达。一般指具有某种意义,无法再分拆的符号。在英文自然语言处理中,Tokens 通常是单独的词。因此,Tokenization 就是将每个句子分拆成一系列词。
通常情况下,最简单的方法是使用 split() 方法返回词列表。
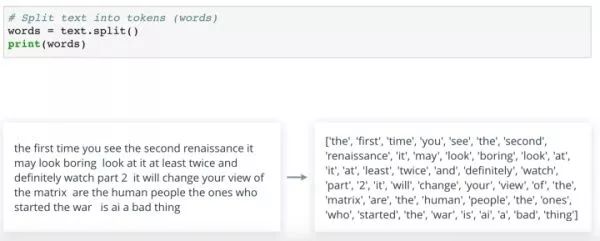
这里默认情况下是将一段话在空格字符处分拆,除了空格,也包其他标签、新行等。这种方法还很智能,可以忽略一个序列中的两个或多个空格字符。因此不会返回空字符串。 你同样可以使用可选参数对它进行控制。目前为止,我们只使用了 Python 的内置功能。 当然,我们也可以使用工具箱,例如 NLTK,一种处理英文最常用的自然语言工具箱, 某些运算会简单得很多。 在 NLTK 中分拆文本的最常见方法是 使用 nltk.tokenize 中的 word_tokenize() 函数。这与split() 执行的效果差不多,但更加聪明一些。在尝试传入未标准化的原始文本时,你会发现,根据标点符号位置的不同,对它们的处理也不同。
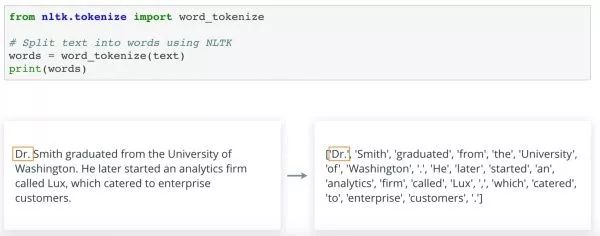
例如,头衔'Dr'后面的句号'.'与'Dr'保留在一起作为一个 Token。可想而知,NLTK 使用某种规则或模式决定如何处理每个标点符号。
有时,我们可能需要将一段话分解成句子而不是单词。比如,如果你想翻译文本,可能需要将文本分拆成句子。

这时,我们可以通过 NLTK 使用 sent_tokenize()实现这一点。然后可以根据需要将每个句子分拆成词,NLTK 提供多种 Token 解析器。包括基于正则表达式的令牌解析器,可以用于一步清除标点符号并将其 Tokenize。
Stop Word
Stop Word 是无含义的词,例如'is'/'our'/'the'/'in'/'at'等。它们不会给句子增加太多含义,单停止词是频率非常多的词。 为了减少我们要处理的词汇量,从而降低后续程序的复杂度,需要清除停止词。

在上述句子中,即使没有'are'和'the',我们仍然能推断出人对狗的正面感情。你可以自己思考一下 NLTK 将英语中的哪些词作为停止词。

这里,NLTK 是基于特定的文本语料库或文本集。不同的语料库可能有不同的停止词。在一个应用中, 某个词可能是停止词。而在另一个应用这个词就是有意义的词。要从文本中清除停止词,可以使用带过滤条件的 Python 列表理解。
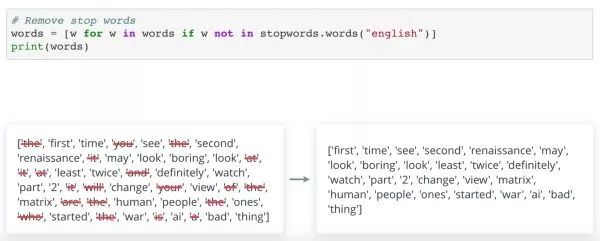
这里,我们将影评 Normalization 和 Tokenization 之后 清除其中的停止词。结果有点难懂,但现在输入量缩小了很多,并保留了比较重要的词汇。
Part-of-Speech Tagging

还记得在学校学过的词性吗?名词、代词、动词、副词等等。识别词在句子中的用途有助于我们更好理解句子内容。并且,标注词性还可以明确词之间的关系,并识别出交叉引用。同样地,NLTK给我们带来了很多便利。你可以将词传入 PoS tag 函数。然后对每个词返回一个标签,并注明不同的词性。
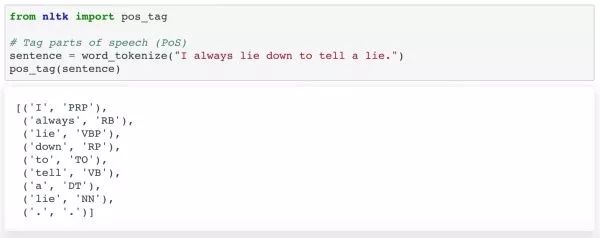
这里函数正确地将出现的第一个'lie'标注为动词,将第二个标注为名词。关于标签含义的更多详细信息,请参阅 NLTK 文档。词性标注的一个典型应用是句子解析。

上面的示例是 NLTK 手册中使用自定义语法解析歧义句的一个示例。实例中解析器返回了两种有效解释。我们也可以使用代码画出解析树,以便可以轻易地看出两者的区别。
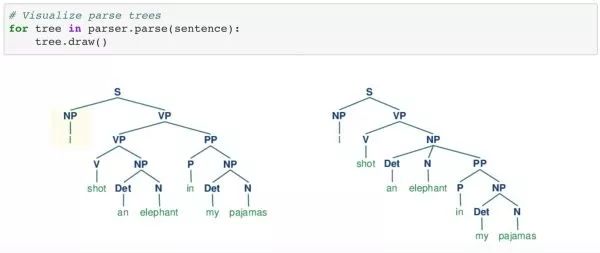
"I / shot an elephant / in my pajamas" ("我穿着睡衣杀了一头象")以及 "I / shot / an elephant in my pajamas";("我杀了一头穿着我睡衣的象")
另外,还有其他很多方法可以进行 PoS,比如 Hidden Markov Models (HMM) 以及 Recurrent Neural Networks (RNNs)
Named Entity
Named Entity 一般是名词短语,又来指代某些特定对象、人、或地点 可以使用 ne_chunk()方法标注文本中的命名实体。在进行这一步前,必须先进行 Tokenization 并进行 PoS Tagging。

如图,这是一个非常简单的示例。NLTK 还可以识别出不同的实体类型,分辨出人、组织和 GPE(地缘政治实体)。 另外,它还将'Udaticy'和'Inc'这两个词识别成一个实体,效果不错。Named Entity 并不是所有的情况都识别的很好,但如果是对大型语料库进行训练,却非常有效。命名实体识别通常用于对新闻文章建立索引和进行搜索。我们可以搜索自己感兴趣的公司的相关新闻。
Stemming and Lemmatization
为了进一步简化文本数据,我们可以将词的不同变化和变形标准化。Stemming 提取是将词还原成词干或词根的过程。

例如'brancing'/'branched'/'branches'等,都可以还原成'branch'。总而言之,它们都表达了分成多个路线或分支的含义。这有助于降低复杂度,并同时保留词所含的基本含义。Stemming 是利用非常简单的搜索和替换样式规则进行的。
例如,后缀'ing'和'ed'可以丢弃;'ies'可以用'y'替换等等。这样可能会变成不是完整词的词干,但是只要这个词的所有形式都还原成同一个词干即可。因此 它们都含有共同的根本含义。
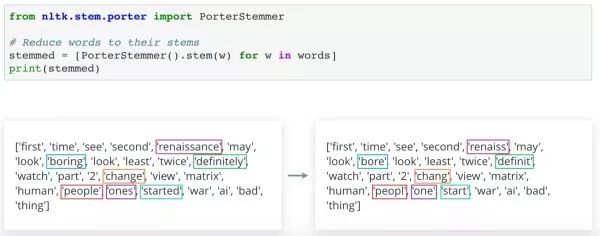
NLTK 有几个不同的词干提取器可供选择,例如PorterStemmer()方法。上图例子中我们已经清除了 Stop Words,所以部分转换效果非常好。例如,'started'还原成了'start'。但是像其它词,例如'people'末尾的'e'被删除,出现这样的原因是因为规则过于简单。
Lemmatization 是将词还原成标准化形式的另一种技术。在这种情况下,转换过程实际上是利用词典,将一个词的不同变形映射到它的词根。通过这种方法,我们能将较大的词形变化,如 is/was/were 还原成词根be。NLTK 中的默认词形还原器使用 nltk.stem.wordnet 数据库将词还原成词根。
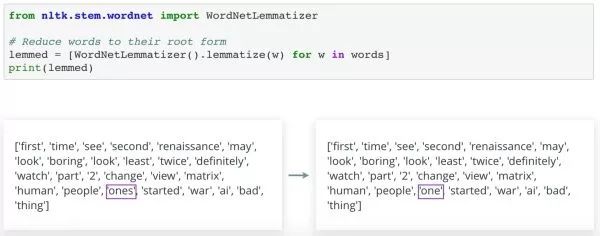
这里我们试一下像词干提取一样,将 WordNetLemmatizer() 的实例初始化,并将各个词传入 lemmatize()方法。结果中只有词ones被还原成了one,其它词并无任何变化。仔细读各个词,你会发现ones是这里唯一的复数名词。实际上,这就是它被转换的原因。

Lemmatization 需要知道每个词的词性。在这个例子中WordNetLemmatizer()默认词性是名词。但是我们可以指定 PoS 参数,修改这个默认设置。我们传入 'v' 代表动词。现在,两个动词形式'boring'和'started'都被转换了。

小结一下,在前面的示例中,可以看出 Stemming 有时会生成不是完整英语词的词干。Lemmatization 与 Stemming 类似,差别在于最终形式也是有含义的词。这就是说,Lemmatization 需要字典,而 Stemming 不需要字典。因此,根据你施加约束的不同,Stemming 是对内存要求较低的方案。
总结
上文内容其实来自Udacity「自然语言处理工程师」的课程。总结一下典型英文自然语言处理工作流程是什么样 对于纯文本句子。首先将其转换成小写,并清除标点符号,将其 Normalization。然后用 Tokenization 将其分拆成词,接下来可以清除 Stop Words,以减少要处理的词汇量。根据应用的不同,可以选择同时进行 Stemming 和 Lemmatization,将词还原成词根或词干。常见的方法是先进行 Lemmatization,再进行Stemming。这个程序将自然语言句子转换成标准化记号序列,这样可以用于进一步分析。
更多干货:
2018/9/14 每日优达

亚马逊alexa x IBM Watson 联合打造的网红课程【自然语言处理工程师】纳米学位开放限定报名,通过学习,你将掌握包括文本分析、语音识别、语义分析和机器翻译等技术在内的自然语言处理核心技能。戳【阅读原文】,了解更多详情,席位有限,抢先预订!
以上是关于自然语言处理时,通常的文本清理流程是什么?的主要内容,如果未能解决你的问题,请参考以下文章