从统计视角看第二语言教学和自然语言处理的共同本质
Posted 外研社国际汉语
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从统计视角看第二语言教学和自然语言处理的共同本质相关的知识,希望对你有一定的参考价值。
从统计视角
看第二语言教学和自然语言处理的
共同本质
宋飞 | 北京第二外国语学院汉语学院
提要
第二语言教学和自然语言处理以往从研究范式上看差异明显,背后反映出的则是基于“规则”和基于“统计”的不同的研究思路。自然语言处理经历了由偏重“规则”到重视“统计”的发展,这对第二语言教学的发展具有重要的启示作用。从统计视角看,为分别解决人和计算机“学习”语言的问题,第二语言教学和自然语言处理的研究思路本质上应当是相通的。其相通之处在于,自然语言处理是以统计语言模型来模拟人在语言学习和使用中的认知特点,而基于统计的自然语言处理实践又有助于揭示出语言教学的规律,即: 不应过高估计语法在语言学习中的作用,要使学习者建立正确的语言模型,必须依靠大量规范的语料的训练。
01
引言
第二语言教学和自然语言处理都是研究语言的学科,在一些高校的学科设置中,二者也常常被划为语言学及应用语言学专业下的两个方向。甚至于通俗地讲,二者的研究任务也“类似”:第二语言教学研究的是怎样更好地教人掌握一门语言,而自然语言处理研究的则是怎样更好地教计算机“掌握”一门语言。但长期以来,第二语言教学和自然语言处理是存在一定隔阂的两个学科领域,彼此间的交流并不充分。其中的原因有很多,目前来看最主要的原因之一可能是“班底”不同,第二语言教学领域的研究者多是语言学专业出身,更多采用文科的研究范式,而自然语言处理领域的研究者则大批出身于计算机相关专业,多采用理科的研究范式。由此带来的结果是,两个领域的研究者研究语言的基本思路往往各不相同,第二语言教学多强调“规则”,而自然语言处理则特别重视“统计”。近年来,随着两个领域的交流不断增多,基于规则和基于统计的研究方法开始搭配使用,但底层的语言观并未真正打通。
基于规则和基于统计的语言研究各自有其诞生的合理性。先从规则说起,通过建立规则理解世界的运行规律是人的天性。人类受生命长度和记忆容量的限制,需要在有限经验的基础上抽象出各类规则,建立因果关系来理解世界。因此, 基于规则的语言研究一定离不开语法规则体系的建立,语法规则是其用来发现和理解语言规律的工具和基础。在这样的背景下,第二语言教学常常把语法教学作为重中之重, 这似乎是一件顺理成章的事情。而基于统计的语言研究则不同,严格的数学训练让研究者异常重视数据和数学建模的作用,作为语言“教学”对象的计算机跟人类相比,也不会受到生命长度和记忆容量的限制。因此,基于统计的语言研究倾向于相信“一切规则生于语料”,以丰富的语料数据训练语言模型,而非人为去构造一个语法规则体系。所以基于规则的语言研究倾向于强调规则的稳定性,一旦规则遇到挑战,要么以批判的态度认为“例外”是错的,要么通过为“例外”补充新的规则来完善现有的规则体系。而基于统计的语言研究则通常不认为规则有什么恒定不变的必要,语料是动态的,语言模型就应当是动态的。
规则的困境
02
(一)不同领域,共同问题
国内第二语言教学课堂上较为常见的场景之一,就是教师以教材课文为纲,提取其中的“语法点”,再分别进行讲解。学生在下面拼命地记录教师讲授的语法规则,试图以此建构起完整的语法规则体系,从而掌握这门语言。当学生提出针对某词用法的疑问时,教师也往往从语法的角度进行分析,教师讲得头头是道,学生听得也很信服。但实际上过分重视语法教学对于学习者掌握一门语言并不能起到很好的作用。从身边许多人围绕语法学习英语的例子可以看到,大批人学了十多年的英语, 如果没有英文字幕,还是听不懂英文电影,跟外国人交流还是张不开口。以语法教学带动语言教学似乎存在一些问题。
要找到“症结”所在,不妨先了解和借鉴计算机是用什么方法“掌握”一门语言的。目前iPhone 在全球的市场占有率非常高,在 iPhone 受人欢迎的各种功能当中,有一个私人助理 Siri 扮演了重要角色。Siri 反映出当人类用户跟计算机用自然语言交流时,计算机可以识别和理解用户的语言,并且用自然语言回答,这意味着计算机的确在某种程度上“掌握”了用户的语言,其中又包括了“听懂”“理解”“反馈”三个阶段。在计算机“听懂”用户自然语言的过程中,涉及的关键技术语音识别(voice recognition)¹ 的发展,对于找到上述“症结” 具有重要的参考作用。
在二十世纪六十年代 IBM 的 Watson 实验室聘请了一批语言学家,开始基于规则研究语音识别技术。在取得了最初的成效后,接下来几年中,语音识别率一直没有得到本质的提高,维持在 70% 左右。到了二十世纪七十年代,当时的实验室的负责人弗莱德里克·贾里尼克(Frederick Jelinek)² 转变了研究思路,建立了基于统计的研究语音识别问题的框架,使语音识别的正确率迅速从 70% 提升到了 90%。事后贾里尼克说了一句在语音识别研究领域广为流传的话:“我每开除一名语言学家,我的语音系统识别率就提高一些。”³ 这句话无疑带有对语言学家的偏见,但背后所反映的真实背景,则是基于统计的语言研究在一些具体问题处理上的效果超过了基于规则的语言研究。
(二)问题出现的关键原因
要了解为什么会出现上述情况,首先需要弄清楚语音识别早期的研究思路出了什么问题。类似于第二语言教学,问题就出在语法规则上。早期语音识别的内在逻辑是,人之所以没学会某种语言,是因为没有掌握它的规则,而计算机依靠其强大的存储性能和逻辑运算能力,通过输入语法规则来“掌握”一门语言,理应取得良好的效果。但 事实证明这个逻辑是行不通的,其中包含两个关键原因:
第一,经过测试,要覆盖 20% 的自然语料,已经需要上万条语法规则,其中还不包含词法规则。⁴ 更重要的是这些语法规则不是天然存在的, 而是人为总结出来的。这就决定了这些语法规则之间必然有各种各样的矛盾。为此还需要将其各自的使用环境形式化后输入计算机。而要做到覆盖 50% 的自然语料,“长尾效应”⁵ 会使语法规则的数量成指数级增长,其工作难度相当之大。
第二,假设可以穷尽一种语言的全部语法规则,使其覆盖 100% 的语料, 但是由于规则数量实在太大,要让计算机能够成功解析这些规则也几乎是不可能的。在计算机科学中,图灵奖得主高德纳(Donald Knuth)提出了“计算复杂度”(Computational Complexity)⁶ 的概念,用以衡量计算机处理自然语言的算法耗时。对于自然语言的 “上下文有关文法”⁷,计算复杂度大约是语句长度的6次方。这样的计算量无论对于计算机还是对于人脑来说都是一个恐怖的数字。
如果把自然语言处理遇到的以上问题放到第二语言教学中,或许就在很大程度上解释了为什么十多年英语语法的学习,也不足以让学习者看懂英文电影或考好GRE。因为即使学了十多年的英语语法,也不足以覆盖英语的全部用法。
回到汉语作为第二语言教学当中,假如留学生学了“被”字句,建立了陈述句到“被”字句的 转换规则,就可以依据该规则把“我摔了手机”说成“手机被我摔了”,做出正确的转换。但如果简单根据这个规则,把“我姓刘”说成“刘被我姓了”,把“我像妈妈”说成“妈妈被我像了”,无疑是错误的。由此可以看出,为了完善一个规则,常常还需补充更多的规则。
此外,仅仅不断完善语法规则也是不够的。比方说,“我差一点儿及格”,是说我没及格,“我差一点儿没及格”,是说我及格了,多了一个“没”,意思相反,逻辑通畅。但是如果扩展到“我差一点儿摔倒”和“我差一点儿没摔倒”,有没有这个“没”,都是没摔倒,这就不单单涉及语法规则,而涉及语义规则了。但语义规则表述的复杂度却往往比语法规则更高。即便学习者听懂了这些规则,能不能正确和顺畅地使用,也说不好。
而且语法规则会随着语言的发展而不断变化。二十年前,很多北方人,包括语言学家在内,听到 “我有吃过早饭”这个说法,多数会认为这是病句, 违反了语法规则。现在却有越来越多的北方人在口语中使用这种“有+V 过”的结构,语言学家也不能轻易断言这是不是或会不会成为一种新的句子 结构。
由此看来,第二语言教学因为同样的原因,面临着自然语言处理面临过的同样的困境,单纯基于规则的教学和研究面临着严峻的挑战。
03
统计的共性
(一)计算机的语言学习“思维”
相比人类,计算机“掌握”语言的方法和途径更容易判断。因为人的语言环境更为复杂,除了教师在课上的讲授和练习,课下还有很多接触目的语的机会,这些机会可能是观看影视作品,可能是和外国朋友交流,可能是阅读目的语的著作,等等,很多接触是很难意识到的,即便意识到也很难进行效用的对比和衡量。但计算机不同,计算机的所有输入和算法是可控、可统计的,研究者可以清楚地根据计算机的输出结果判断其对一门语言的“掌握”程度,并由此溯源产生这种结果的数据和机器学习方法。因此,如果计算机能够比较好地“掌握”一 门语言,其中的方法对于第二语言教学应当有比较大的参考价值。
那么我们来看基于统计的自然语言处理是怎么做的。那就是不依赖于语法规则,而是通过大量真实、规范的语料来训练计算机语言模型的参数,进而建立一个语言模型。要判断一句话理解得或说得是否正确,就用其可能性(概率)来衡量。
假设 S 是一个有具体含义的句子,由按照特定顺序排列的一组词 w1、w2、……、wn 组成。想要知道句子 S 在自然语言中出现的可能性,也就是求它的概率 P(S)。将 S 展开,我们会发现:
P(S)= P(w1, w2, ……, wn)= P(w1)·P(w2| w1)·P(w3| w1, w2)……P(wn| w1, w2, …, wn-1)
其中,P(w1)是第一个词出现的概率,P(w2| w1)是第一个词出现的前提下,第二个词出现的概率,也叫第二个词出现的条件概率,以此类推,P(wn| w1, w2, ……, wn-1)是前面所有词出现后,最后一个词出现的概率。由于每个变量 w 的取值范围都是零到一本词典所包含的词的数量,所以越到后来条件概率的计算越复杂。为了简化运算,俄罗斯数学家马尔可夫提出了二元模型(Bigram Model)⁸,即假设每一词的出现概率只和它前面一个词相关。事实证明,二元模型已经足以解决很多实际问题。简化后的二元模型中,句子 S 出现的概率 P(S) 的计算方法如下:
P(S)= P(w1, w2, ……, wn)= P(w1)·P(w2| w1)·P(w3| w2)……P(wn| wn-1)
要想求 P(S),接下来的问题,就是如何计算条件概率 P(wi|wi-1)。根据条件概率的定义:
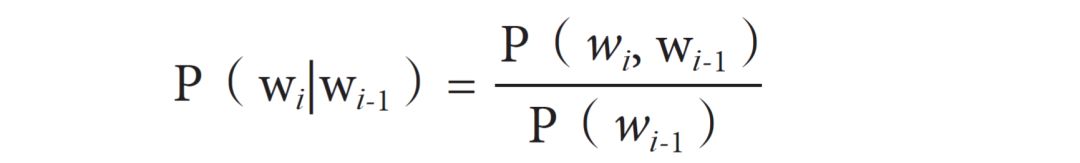
要估计其中的边缘概率 P(wi-1)和联合概率 P(wi, wi-1)并不困难,只需要按需收集语料,在计算机中建立一个符合语言模型要求的相应领域的语料库或平衡语料库,之后让计算机先计算单词频以及任意两个词搭配的频率(frequency),如果语料库足够大且配比得当,频率就可以近似地被看作概率(possibility)。边缘概率 P(wi-1)就可以从单词频的数据库中调取,而联合概率 P(wi, wi-1)则可以从搭配频率数据库中调取。由此就可以计算任一句子在自然语言中出现的概率了。
为了让读者无需数学基础就能理解,举一个例子。比如,笔者用语音向 Siri 输入:“我是一个中国人。”当服务器收到这一连串发音的时候,会先调取第一个音节,看发音为“wǒ”的所有汉语词中,哪个词的频率是最高的。调取结果显示,发音是“wǒ”的四个词及其词频数据如下:
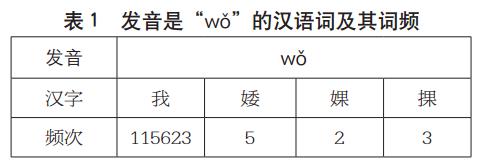
由上表可见,其中“我”频率最高,服务器就先假设第一个词就是“我”。之后,调取第二个音节“shì”,并进而调出所有读音为“shì”的词,然后看“我”跟这些词分别共现的频率,结果发现“我”和“是”共现的概率最高,服务器就假设第二个词为“是”。以此类推,服务器将这句话中所有音节的所有可能的词都组合一遍,然后得出每个
可能序列的概率,并从中找出概率最高的序列,最终识别出笔者说的那句话。
(二)人类大脑的语言学习思维
说到这里,很多人可能已经意识到计算机语音识别中的“学习”和人类大脑的学习方式类似了。A 跟 B 说:“我是一个中国人。”B 之所以能从那么多同音词中知道 A 说的第一个词是“我”,或许正因为 B 生活中接触的自然语料中,读音为“wǒ”的词中“我”出现的次数最多,可能性最大;之所以判断第二个词为“是”,而非“式”或者“氏”等,或许也正因为以前听到的语料中,“我”之后,搭配“是”的次数最多,可能性最大。
所以姑且做一个大胆的假设:从根本上说,不管是计算机还是人类,“学习”语言的方法本质上是类似的。人脑应当也是先有大量自然语料的输入,然后依据输入情况,在大脑中建立了一个简化后的词频库和搭配库,并在需要的时候从中调取相应参数。所谓的“简化后”,指的是大脑记录的不是词或词之间搭配的绝对频率,而是一个划分粗略的相对频级⁹。这和见一个人的次数多了,自然会觉得他比另一个人脸熟是同一个道理。其中更重要的是词之间搭配的频级,因为从以上公式可以看出,求 P(S)的运算中,大部分的计算围绕在词之间的搭配情况进行。这也是为什么我们对于母语中是否存在某个搭配、两个搭配中哪个出现得更多比较敏感的原因。这个假设如果成立,就意味着人类大脑中的语言模型是语料大数据训练得到的,而非通过掌握语法规则得到的。
举一些旁证。普林斯顿大学、哥伦比亚大学等美国常青藤盟校在中国分别开办有 PIB、CIB 等暑期中文项目。这些项目所采用的教学模式大都是由“明德模式”发展而来。明德模式的核心是drill session(操练课)。举例来说,要学生掌握“虽然……但是……”这个句型,通常分为以下几步:
第一步,教师课前把句型写在黑板上。
第二步,建立一个范句作为标准,比如“小张虽然喜欢中文,但是不喜欢汉字”。教师领读两三遍。
第三步,单点学生来复述。“你来!”“小张虽然喜欢中文,但是不喜欢汉字”。“你来!”…… 三个学生过后,范句已经练习了五六遍。
第四步,教师和学生再次一起复述。
第五步,范句建立之后,通常会替换掉其中的某一个成分来造一个新的句子。比如教师点一个学生说“爱”,学生就把“喜欢”替换成“爱”,“小张虽然爱中文,但是不爱汉字”。再点另一个学生说“讨厌”,“小张虽然讨厌中文,但是不讨厌汉字”。
在这个过程中,学生不需要知道“喜欢、爱、讨厌”都是心理动词,用来替换的词由教师来把握,但通过反复的练习作为语料输入,学生的大脑会潜移默化地将心理动词归为一个聚类。并且依据之前的假设,练习过的这些词的概率会上升。下次再听到类似的语音时,自然就优先识别为这些练习过的词,听力也会得到相应提高。而学生在输出时,只要“虽然”这个词一激活,无需刻意回忆, 搭配较多的词会被大脑自然地提取出来,由此在学生大脑中建立了“虽然……但是……”的语言模型。这种模式看起来“简单粗暴”,但在有经验的教师手中特别有效却是众所周知的。
回到每个人自身习得母语的过程,应当没有人是通过学习语法学会说母语的。家长从孩子出生起对他(她)说过的所有的话就是语料输入,这种输入是持续不间断的,也无需关心刚开始孩子是否听懂。按照假设,孩子大脑中的语言模型正是在这种语料输入下一点点建立起来的,孩子逐渐被训练得能听懂家长的语言。通常是到两岁之前的某一天,孩子通过之前对发音器官的各种尝试,已经有了充分的自信,突然之间开始有单个词的输出,而且一发而不可收。而在语料输入的过程中,输入的语料是什么样子,孩子的语言模型就会被训练成什么样子。如果家长照顾孩子比较少,而带孩子的人又不跟孩子交流,孩子迟迟学不会语言就不奇怪了。带孩子的人跟孩子说方言,孩子建立的就是方言的语言模型,这个人如果文化程度不高,孩子早期的语言用词也应当会有相应的特点。
结论
04
综上所述,本文认为:第一,从统计的视角看,第二语言教学和自然语言处理解决问题的思路和方法,本质应当是相通的。其相通之处在于,自然语言处理是以统计语言模型模拟人在语言学习和使用中的认知特点,而基于统计的自然语言处理实践又有助于揭示出语言教学的规律,语音识别的发展对第二语言教学的启发就是例子。第二,单纯依靠语法应当学不会也学不好一门语言。要想学好一门语言,必须依靠大量语料数据的输入,无从偷懒。语法规则虽然表面上看起来能说服学生,但学生汉语水平的提高到底是语法起了作用,还是语言学习环境中的语料训练潜移默化地起了作用,是说不太清楚的,以语音识别的发展实践来看,应该是语料训练语言模型的统计原理更符合人的认知特点。第三,要想建立正确的语言模型,需要有大量规范的语料来训练模型参数。
作者简介
宋飞,北京第二外国语学院汉语学院讲师,主要研究方向为国际汉语教学和中文信息处理。
附注
1 语音识别,通俗地说就是让机器通过识别和理解过程,把某种语言的语音信号转变为相应语言的文本或命令的技术。
2 弗莱德里克·贾里尼克,世界著名的语音识别和自然语言处理的专家,他在IBM 实验室工作期间,提出了基于统计的语音识别的框架, 这个框架结构对至今的语音和语言处理有着深远的影响,它从根本上使得语音识别有实用的可能。贾里尼克本人后来也因此当选美国 工程院院士。
3 原话是“every time I fire a linguist, the performance of the speech recognizer goes up”,参见《数学之美》(吴军著)2012 年 6 月第一版第 74 页。
4 参见《数学之美》(吴军著)2012 年 6 月第一版第 21 页。
5 “长尾效应”(Long Tail Effect)反映为一种特殊的函数曲线,指的是大多数需求集中在头部,分布在尾部的需求是个性化的、零散的需求。在本文中,“需求”指的是编写语法规则的需求。
6 参见 http://en.wikipedia.org/wiki/Donald_Knuth,2017-12-20。
7 “上下文有关文法”是描述自然语言的语法的一个概念,指在自然语言中一个单词是否可以出现在特定位置上要依赖于上下文。
8 马尔可夫在 1906 年首先做出了这类过程,而柯尔莫果洛夫在 1936 年将此一般化到可数无限状态空间。
9 词的频级系统指将相同频次或频次接近的词划为一个级别后,得到的某种语言中所有词的级别系统,反映的是词之间使用频率的相对差别。
参考文献
宋 飞 . 国际汉语教学中的性质状态类基层词库建设研究 . 中央民族大学博士学位论文,2015.
宋 飞 . 基于大规模文本语料库的现代汉语基层词相对词频定位法研究 . 语言文字应用,2014(4).
吴 军 . 数学之美 . 北京:人民邮电出版社,2012.
宗成庆 . 统计自然语言处理 . 北京:清华大学出版社,2008.

文章选自
《国际汉语教育(中英文)》
2018年第1期

刊物简介
《国际汉语教育(中英文)》是由中华人民共和国教育部主管,北京外国语大学主办,外语教学与研究出版社、北外中国语言文学学院、北外孔子学院工作处共同承办的学术刊物。国际标准连续出版物号为ISSN2096-3106,国内统一连续出版物号为CN10-1385/H,季刊,16开,公开发行。
本刊设立栏目如下:
1. 专家主题论坛
2. 专业建设研究
3. 教师培养发展
4. 汉语教学研究
5. 学习者研究
6. 学术研究新论
7. 二语习得研究
8. 汉语测评研究
9. 海外教学动态
10. 汉语国际传播
11. 新媒体教学研究
12. 教学资源研究
投稿联系:
电子邮箱:gjhyjy@fltrp.com
联系人:赵老师

编辑 | 汤梦焯
美编 | 黄渝婕 汤梦焯
原创稿件
转载请注明来自微信订阅号:外研社国际汉语
欢迎转发分享
以上是关于从统计视角看第二语言教学和自然语言处理的共同本质的主要内容,如果未能解决你的问题,请参考以下文章