花式自然语言处理
Posted NLP Funs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了花式自然语言处理相关的知识,希望对你有一定的参考价值。
NN/LSTM/GRU
“由于RNN一点也不花,此文没有它一席之地。”
CNN
“用什么模型?”
"CNN!CNN是最好的模型!“
”CNN给我使劲叠!!听说有个著名CNN模型有117层?“
”你叠就对了,绕地球一圈!!"
CNN并非不能处理NLP任务,实际之前有多人在分类任务上用CNN来提取文本特征,进而分类,从效果到速度都完胜RNN——毕竟人家是天然并行的。但在去年前CNN在seq2seq任务上没取得过更好的结果,原因也很简单,seq2seq的任务必然要求后一时刻的state带着前面的信息,这是CNN做不到的,直道Facebook(FB)大作《Convolutional Sequence to Sequence Learning》(ConvS2S)问世。该文全程使用CNN模型完成经典seq2seq任务机器翻译,取得了SOA,还顺手在摘要任务上做了个评测以证明模型的有效性。
为实现ConvS2S,FB在早前还提出了一个新的基于CNN的门控单元[2]来对NLP任务实现特征提取,其思想可谓是大道至简:
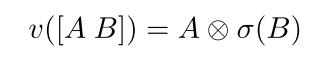
其中,A和B分别是当前层通过CNN层分别计算两次的结果。Gate(B)是由sigmoid函数计算的门单元。也就是说,本层输出是由本层结果以及根据本层结果计算的门来控制输出的(可联想LSTM结构)。但由于CNN的感受野限制,基于CNN的模型一般都需要堆叠多层才能获取到更多依赖。
ConvS2S采用GLU来对每层的特征进行提取,总体框架仍然是采用的Encoder-Decoder模式,Encoder负责提取源文本特征,Decoder负责生成序列输出,其中encoder-decoder cross的部分,采用点乘(dot-product)的方式来获取注意力分数。
此后,CNN算是正式跻身NLP seq2seq任务中了。随后,基于膨胀卷积(dilated CNN)的模型也在机器翻译的任务中取得了较好的成绩[3]。膨胀卷积,又名空洞卷积,它的实现方式是在设定感受野中增加权值为0(挖空)的值,在扩大感受野范围的情况下不增加参数,并能让感受野捕捉到更远距离的依赖。
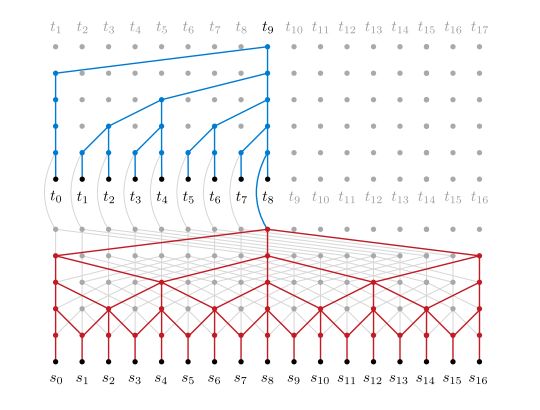
膨胀卷积:encoder(红色)第一层为rate=1(无膨胀),第二层为rate=2(挖空1个),第三层为rate=4(挖空3个),依此类推,decoder部分为蓝色,和红色一样。

Attention-based MLP
“就怕你不注意,你只要肯注意,就整对了!”
Attention机制最早使用在CV领域,意思是一张图片着重关注的区域。14年Bahdanau将这个机制应用到了NLP任务上,并在机器翻译领域取得了非常好的SOA结果。attention机制分为2种,加性attention和乘性attention。
加性attention
加性attention用法和Bahdanau论文[4]里的一致:
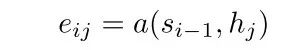
其中,a表示一个MLP,参与计算的输入数据是以相加的形式传入MLP的,因此被称为加性attention。
乘性attention
乘性attention的用法比加性更为简单一点,采用点乘的方式直接计算向量之间的相似度,并以此作为attention分数,上述ConvS2S就是采用的该种方式。
讲到这,就该介绍attention机制的神作《Attention is all your need》了。就在ConvS2S问世不久,Google就提出了这个模型,并命名为transformer。Transformer最大的特点是全程未使用任何特殊结构,attention+MLP走天下,最后还拿到新的机器翻译任务SOA。框架仍然是Encoder-Decoder,encoder、decoder不交互部分采用乘性self-attention,计算源文本中每个词与全文的依赖。和GLU不同,self-attention一步就可以获取到全局依赖。Cross-attention部分通过乘性attention计算目标词和源文本的相似度依赖,从而得到与源文本有依赖的新的输出。
不难看出,无论是ConvS2S,还是tranformer,在设计交互attention计算的时候,都不免有LSTM/GLU的思想在里面:有一部分要forget,有一部分要update。
这篇文章另一个贡献是使用了多头机制,实际也就是在多个维度中有个类似ensemble的操作,可以看作是在不同子空间中学习语义关系,最后再融合起来(这其实也是一个上分利器哦)。
GAN
“来啊,对抗啊”
“来啊,生成啊“
17年GAN在CV领域大火的时候,开始有研究者将GAN的思想迁移到NLP任务上,并将其誉为最好用的生成模型,在机器翻译任务上取得较好的成绩,其中佼佼者为FB在无监督机器翻译上做出的贡献《Unsupervised Machine Translation Using Monolingual Corpora Only》。该篇文章利用GAN模型将两种不同语言映射到同一共享隐空间,模型通过学习这个共享隐空间的特征重建两种语言。
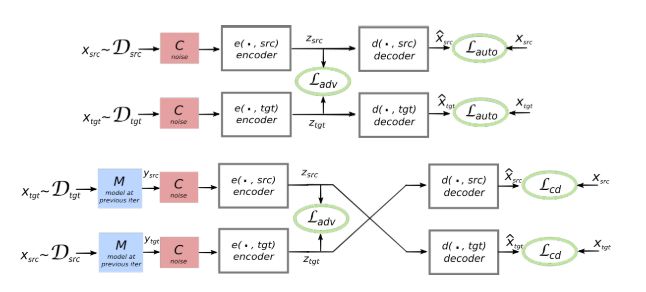
构建无监督机器翻译模型有多难我这个长期奋斗在该任务一线的人可以抹泪和你说三天三夜不重复,所以这个模型无关人员可以放一边了。
将无监督的思想用于NLP任务是很多NLP researchers的奋斗方向,除了这篇外还有好几篇相关工作[7,8]。毕竟从拟人化来说,人类学会很多NLP相关任务其实都是弱监督甚至无监督的。但FB的这篇paper取得的成果除了本身取得的成果之外,还创新性的使用了GAN来工作,调试模型可以想象的艰难,最后取得很好的成果,请容许我向大厂致敬。
强化学习
“我不是针对谁,上面的花样都是弱鸡”
强化学习目前在处理序列问题上获得很多可喜的成果,而NLP很多任务天然就是序列任务,因此在未来的工作中,我认为最有前景的就是将强化学习思想应用于NLP任务上。
早在16年,微软就提出了强化机器翻译模型——对偶学习[9]。该模型思想为,建立两个独立单语语言模型AB,模型A能正常输出语言a,模型B能正常输出语言b,少量平行语料初始化2个翻译模型a-b, b-a。给定一个句子x∈a,由翻译模型a-b将其翻译成语言b,交由单语模型B对其进行语法、顺序等问题的矫正,随后再由翻译模型b-a将其翻译成语言a,再交由单语模型A对其进行问题矫正。最终模型的更新由中间2次结果与其单语语言模型计算的reward值决定。对偶学习创新性提出的将强化学习思想应用到NLP任务上,在此前鲜有人提;同时,对偶学习是一个全新的学习范式,它能同时使用少量标注语料学习2个模型,还融合了强化学习思想,是一项非常值得深入研究的工作。
如前所述,NLP很多任务天然就是序列任务,和强化学习直接相关,例如生成模型的下一时刻应该生成一个什么样的词语,可以完全看作是agent在词表这个动作空间上做的选择(只是这个空间有点大),并且这个空间还是天然离散的,可以直接使用强化的方法。还有序列标注任务,比如中文分词。在最近我们遇到的项目里就有这个问题,多种分词情况都是正确的,但label确只标注了一种情况是正确的,这样loss引导出来的指标和我们想要得到的指标完全不一致,但若使用强化学习的方法就可以避免这样的“一对一”问题,将其转换为“一对多”的问题来解决。目前也有越来越多的researchers在向着这个方向工作了[10-13],更证明这个方向在NLP任务上的未来可期。
Reference
[1] Language Modeling with Gated Convolutional Networks
[2] Convolutional Sequence to Sequence Learning
[3] Neural Machine Translation in Linear Time
[4] Neural Machine Translation by Jointly Learning to Align and Translate
[5] Attention Is All You Need
[6] Unsupervised Machine Translation Using Monolingual Corpora Only
[7] Adversarial training for unsupervised bilingual lexicon induction
[8] UNSUPERVISED NEURAL MACHINE TRANSLATION
[9] Dual Learning for Machine Translation
[10] Sequence Generative Adversarial Nets with Policy Gradient
[11] Learning Structured Representation for Text Classification via Reinforcement Learning
[12] An actor Critic algorithm for sequence prediction
[13] Deep Reinforcement Learning for Dialogue Generation
以上是关于花式自然语言处理的主要内容,如果未能解决你的问题,请参考以下文章