项目应用自然语言处理-python实现jieba中文分词
Posted 人工智能学术前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目应用自然语言处理-python实现jieba中文分词相关的知识,希望对你有一定的参考价值。
自然语言处理-python实现中文分词


jieba分词器介绍

自然语言处理中,英文中,词与词之间有空格进行分割,但是中文中的词需要进行分析,切分操作。
jieba分词器支持三种分词模式:
1.精确模式,试图将句子最精确地切开,适合文本分析;
2.全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
3.搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
下面使用jieba官方的demo例子做简单的应用。

输出后的3中模式的效果
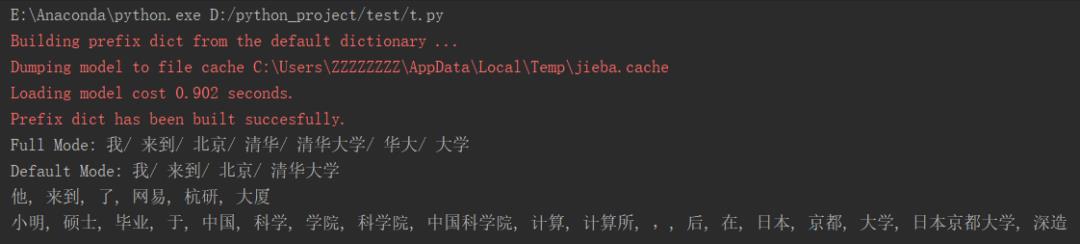
jieba自定义词典
jieba自己已经有词典,但是你还可以自己向词典中增加。比如一些人名、地名、机构名,词典中未收录,为了避免分词分错,可以自行增加。
1.构造txt文档增加词
自己写一个txt文档,然后通过调用txt文档使用新加入的词,txt文档书写时,词典的格式和jieba分词器本身的分词器中的词典格式必须保持一致,一个词占一行,每一行分成三部分,一部分为词语,一部分为词频,最后为词性(可以省略),用空格隔开。
2.程序中动态修改词典
调用jieba的函数add_word(word, freq=None, tag=None) 和 del_word(word) 可以在词典中增加删除单词。
下面时使用增加新词和未增加新词的对比分词结果输出。
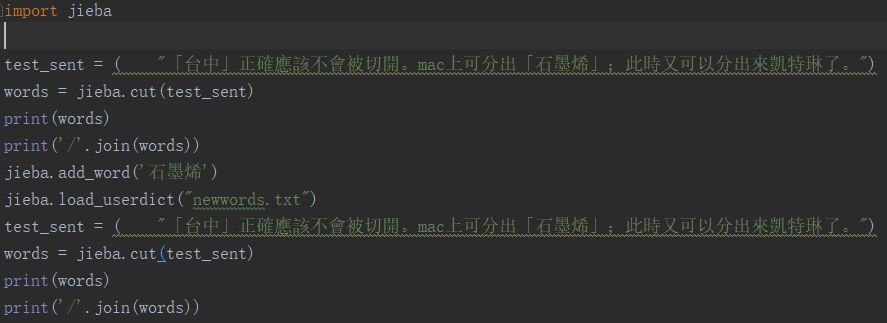
输出结果如下,可以看到石墨烯 本来被分成两个词,经过添加后,正确的划分为了1个词。

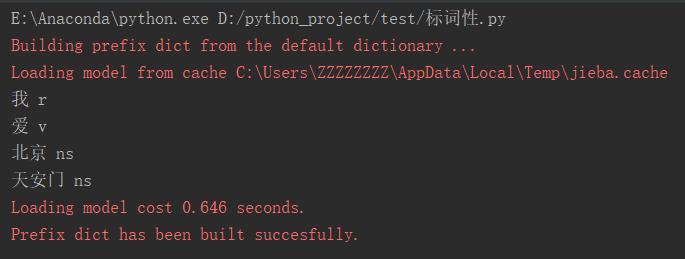
jieba分词后标注词性
接着上例,分好的词,我们继续对词进行标注词性。
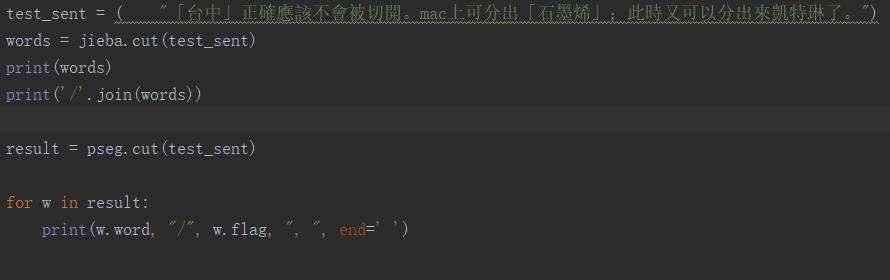
输出结果:

词性标注
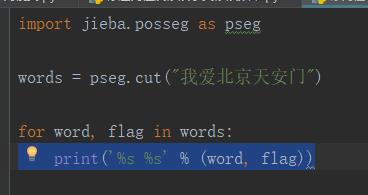
输出结果:
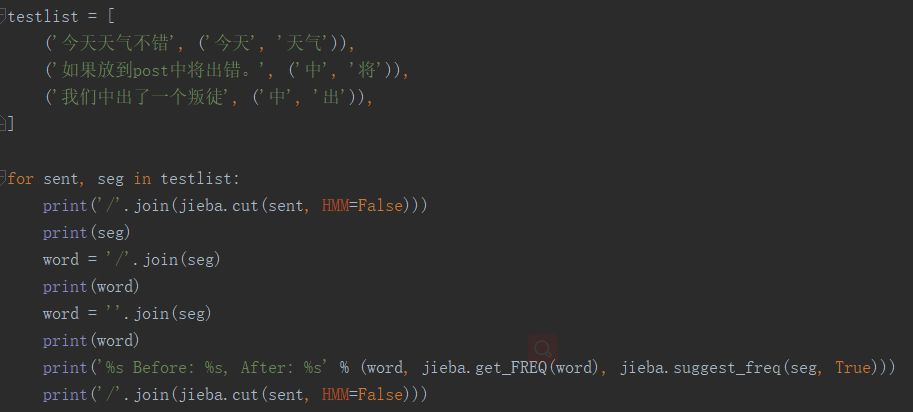
jieba更改原有的词频统计
因为,前面我们自定义了加减了词典,所有会出现原有jieba默认的词频会受影响发生改变,有两种情况。
1.本该分,但系统没分的例子。
加入自定义的该分词后,原来词频 会减少。
例子如下:
输出结果
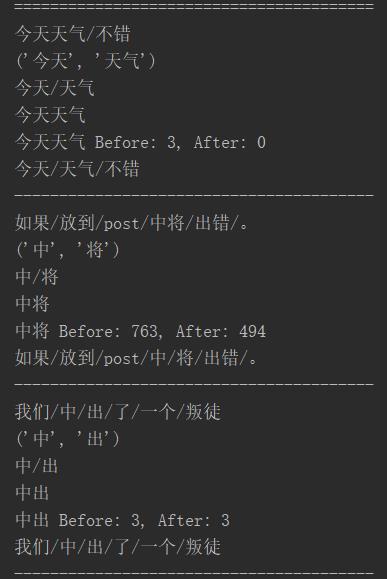
相反的,另一种情况。
2.本不该分,但系统分了的例子。
加入自定义的该合并的词后,原来词频 会增加(生成)。
例子如下:

输出结果:

更多精彩内容,尽在阅读原文
以上是关于项目应用自然语言处理-python实现jieba中文分词的主要内容,如果未能解决你的问题,请参考以下文章
自然语言处理之中文分词器-jieba分词器详解及python实战