实例教程:如何用自然语言处理来预测垃圾邮件?
Posted 读芯术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实例教程:如何用自然语言处理来预测垃圾邮件?相关的知识,希望对你有一定的参考价值。
全文共2860字,预计学习时长6分钟
自然语言处理可以帮助计算机进行文本分析,比如说检测垃圾邮件、自动纠错等。那么,自然语言处理技术是如何用于理解人类语言的?

本文详细讲述了如何执行基本自然语言处理任务并使用机器学习分类器来预测SMS是垃圾邮件还是非垃圾邮件。通过理论和代码的配合,用最生动的实例让你轻松掌握这一主题。

自然语言处理
在机器学习领域中,自然语言处理指的是教会计算机理解、分析、处理并能潜在地生成人类语言。
在现实生活中,自然语言处理主要表现在:
信息检索(谷歌发现相关或者相似的结果)
知识提取(谷歌邮箱从无数邮件中构建事件信息)
机器翻译(谷歌翻译将一种语言翻译成另一种语言)
文本简化(Rewordify能够简化句子含义)
情感分析(Hater News能够展现用户的情感 )
文本总结(Smmry或者Reddit的 autotldr机器人能够总结句子 )
垃圾邮件过滤(谷歌邮箱能够过滤垃圾邮件)
自动预测(谷歌搜索能够预测用户的搜索结果)
自动纠错(谷歌键盘和 Grammarly能够纠正拼写错误)
语音识别(谷歌 WebSpeech或者Vocalware)
问答(IBM的沃森机器人能够对问题进行回答)
自然语言生成(从图像或者视频数据中生成文本)
(Natural Language Toolkit)NLTK: NLTK是一套基于python的自然语言处理工具集。NLTK不是从头开始构建所有工具,而是提供所有常见的自然语言处理任务。
安装NLTK
在Jupyter Notebook中键入pip以用来安装 NLTK,或者如果它不在cmd类型中起作用,请输入-da conda-forge nltk。 这应该适用于大多数情况。
安装NLTK链接: http://pypi.python.org/pypi/nltk
导入NLTK库

在输入以上信息之后,我们就会得到NLTK Downloader Application,这在自然语言处理任务中是非常有用的。
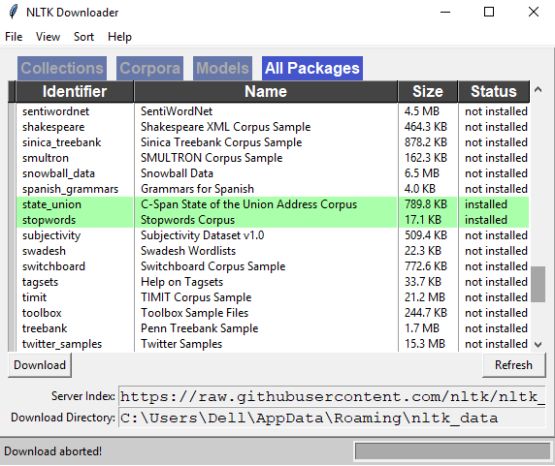
在系统中已经安装了Stopwords Corpus,这有助于删除多余的重复单词。同样,我们可以安装其他有用的工具包。
读取和发现数据集
为什么需要清理文本?
在读取数据时,以结构化或非结构化格式获取数据。结构化格式是具有明确定义的模式,而非结构化数据没有适当的结构。在这两种结构之间,可采用半结构化格式,其结构比非结构化格式更好。

从以上信息可以看到,当读取半结构化数据时,很难对这些数据做出解释,所以可以使用pandas来轻松理解数据。
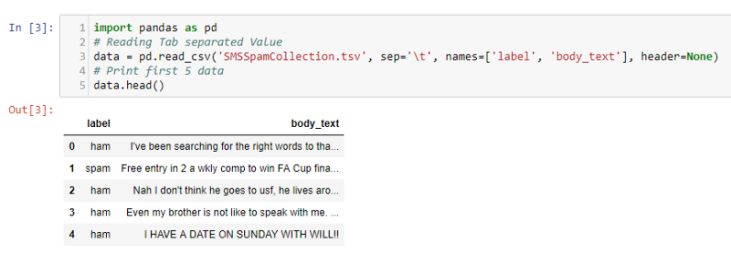
预处理数据
为了能够突显机器学习系统能够接受的属性,对文本数据进行清理非常必要的。
对数据进行清理(或预处理)的步骤
1. 删除标点符号
标点符号可以提供语法语境以能够帮助我们理解句子。但是对于矢量化数据来讲,它计算的是单词的数量而不是靠上下文来理解,标点不会增加价值,所以可以删除所有的特殊字符。 例如:How are you? >How are you
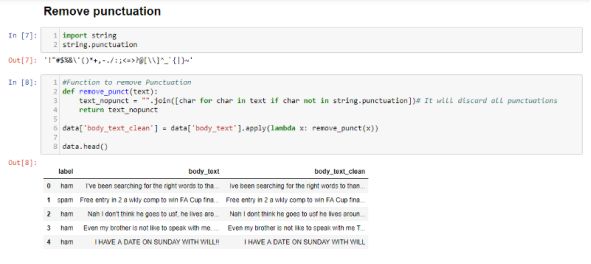
在body_text_clean中,像 I’ve-> I’ve这样的所有标点都被省略了。
2.标记化
标记化将文本分成句子或单词等单位。它为以前的非结构化文本提供了结构。 例如:Plata o Plomo->'Plata','o','Plomo'。
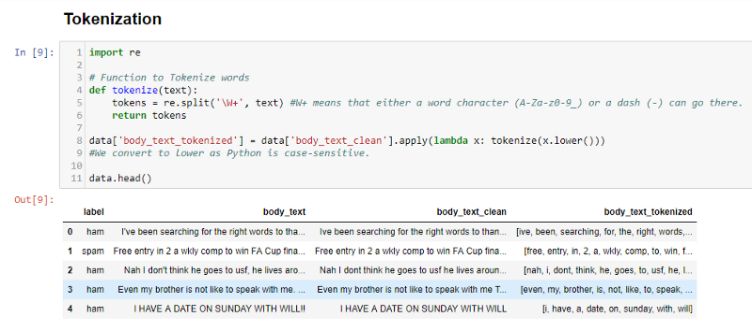
In body_text_tokenized, we can see that all words are generated as tokens.
在body_text_tokenized中,我们可以看到所有单词都生成为标记。
3.删除停用词
停用词是可能出现在任何文本中的常用词。他们没有提供太多的数据信息,所以我们进行删除处理。 例如:silver or lead is fine for me-> silver, lead, fine.

在body_text_nostop中,删除了所有不必要的单词,例如been,for。
词干提取
词干提取有助于将词语简化为词干形式。通常来讲,以相同的方式处理相关单词是有意义的。它通过简单的基于规则的方法去除了诸如“ing”,“ly”,“s”等内容。它减少了单词的语料库,但实际的单词往往被忽略了。 例如:Entitling,Entitled-> Entitl
注意:某些搜索引擎会将与词干相同的词视为同义词。
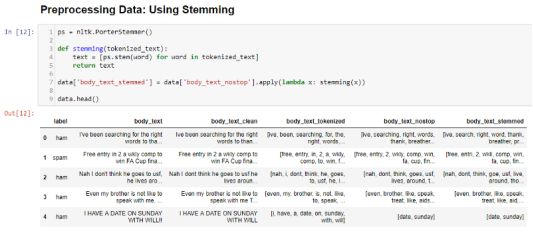
在body_text_stemmed中,像entry,wkly这样的词语被包含在entri中,即使wkli没有任何意义。
单词变体还原
单词变体还原派生出一个单词的规范形式,即根形式。 它优于词干,因为它是基于字典的,即对词根的形态分析。例如:Entitling,Entitled-> Entitle
简而言之,词干提取通常更快,因为它只是简单地删除单词的结尾,而不理解单词的上下文。 单词变体还原更慢,更准确,因为它需要根据单词的上下文进行准确的分析。
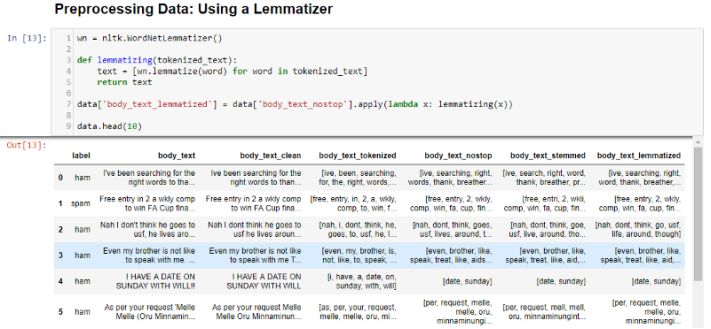
在body_text_stemmed中,我们提取像chances这样的词被单词变体还原为chance,而它可以被提取成chanc。
矢量化数据
矢量化是将文本编码为整数(即数字形式)以创建特征向量的过程,以便机器学习算法可以理解数据。
词袋(Bag-Of-Words模型)
Bag of Words(BoW)或CountVectorizer描述了文本数据中存在的单词。 如果句子中存在则给出1的结果,如果不存在则给出0。 因此,它在每个文本文档中创建了一个包含文档矩阵计数的单词。

BOW应用于body_text,因此每个单词的计数存储在文档矩阵中。
N-Grams
N-gram是在源文本中找到的相邻单词或长度为n的字母的所有组合。n=1的Ngrams称为unigrams。类似地,也可以使用bigrams(n=2),trigrams(n=3)等。
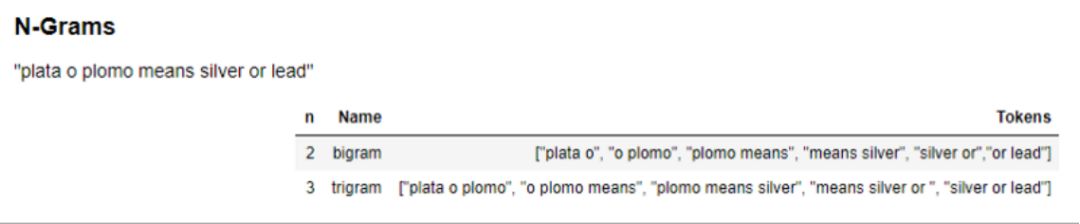
与bigrams和trigrams相比,Unigrams通常不包含太多信息。n-gram背后的基本原理是它们认为字母或单词可能遵循给定的单词。n-gram越长(n越高),你需要处理的环境越多。

N-Gram应用于body_text,因此句子词中每个组词的计数存储在文档矩阵中。
TF-IDF
TF-IDF能够计算文档中出现的单词与其在所有文档中的频率相比的“相对频率”。 它比“术语频率”更有助于识别每个文档中的“重要”单词(该文档中的频率高,其他文档中的频率低)。
注意:将其用于搜索引擎评分,文本摘要,文档聚类。

TF-IDF应用于body_text,因此句子中每个单词的相对计数存储在文档矩阵中。
注意:矢量化器输出稀疏矩阵。 稀疏矩阵是一个矩阵,其中大多数条目为0。为了有效存储,将仅存储非零元素的位置来存储稀疏矩阵。
特征工程:特征创造
特征工程指的是这样一个过程——在这个过程中使用数据领域知识来创建使机器学习算法起作用的特征。因为需要专业领域的知识,并且很难创建特征,它甚至更像一门艺术,不过机器学习算法可以很有效地预测结果。
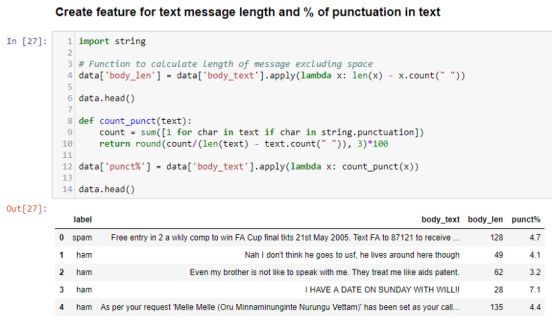
body_len显示排除邮件正文中空格的单词长度。
punct%显示邮件正文中标点符号的百分比。
检查特征是否正确
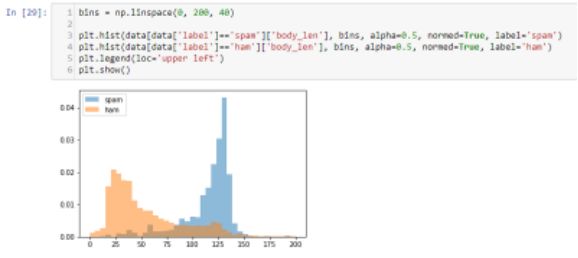
我们可以清楚地看到,与Hams相比,Spams拥有大量的单词。 所以这是一个很好的区分功能。
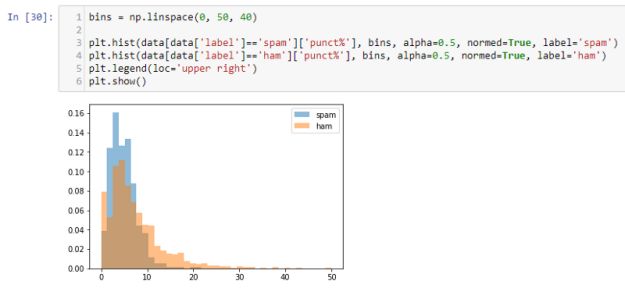
Spam有一定比例的标点符号,但与Ham相比相差并不远。令人惊讶的是,Spam有时会包含很多标点符号。 但是,它仍然可以被认为是一个很好的功能。
构建机器学习分类器:模型选择
使用机器学习的集合学习算法需要使用多个模型,它们组合产生的结果比单个模型(支持向量机/朴素贝叶斯)更好。集合学习算法是许多Kaggle比赛的首选。例如,构建随机森林,即构建多个随机决策树,并将每棵树的聚合用于最终预测。它可以用于分类以及回归问题,遵循随机的套袋策略。
Grid-search:它详尽地搜索给定网格中的整体参数组合以确定最佳模型。
Cross-validation:它将数据集划分为k个子集并使用同样的方法将其重复k次,在每次迭代中使用不同的子集作为测试集。
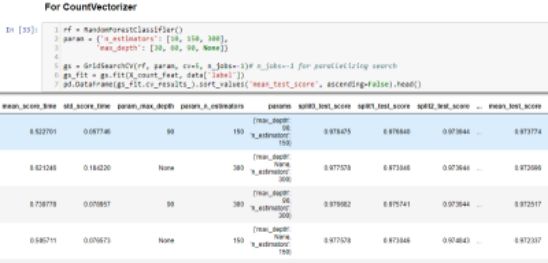
n_estimators和max_depth的mean_test_score = 150给出最佳结果。其中n_estimators是林中树的数量(决策树组),max_depth是每个决策树中的最大级别数。
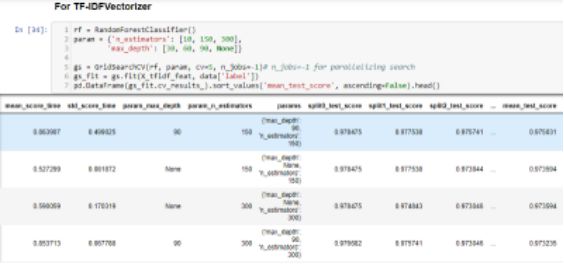
类似地,n_estimators = 150和max_depth = 90的mean_test_score给出最佳结果。
提高:可以使用GradientBoosting、XgBoost进行分类。GradientBoosting采用迭代方法将弱学习者结合起来,通过关注先前迭代的错误来创建强大的学习者,这需要花费大量的时间。 简而言之,与Random Forest相比,它遵循顺序方法而不是随机并行方法。
Spam-Ham分类器
所有上面讨论的部分被组合以构建Spam-Ham分类器。
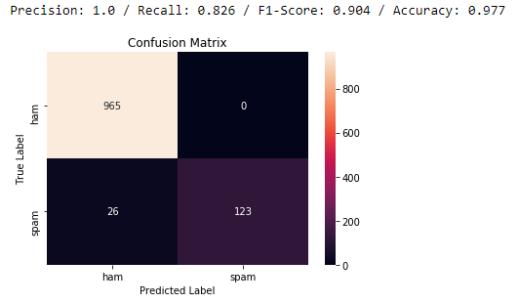
随机森林的准确率为97.7%。 从模型中也获得高价值的F1得分。 混乱矩阵告诉我们,我们正确预测了965个ham和123个spam。0个ham被错误地识别为垃圾邮件,26个spam被错误地预测为ham。 与把ham错误地识别为spam相比,将spam检测为ham是合理的。
以上代码可以在Github Repo中找到。
我们一起分享AI学习与发展的干货
编译组:草田
相关链接:
https://towardsdatascience.com/natural-language-processing-nlp-for-machine-learning-d44498845d5b
如需转载,请后台留言,遵守转载规范
推荐文章阅读
读芯君爱你
以上是关于实例教程:如何用自然语言处理来预测垃圾邮件?的主要内容,如果未能解决你的问题,请参考以下文章