自然语言处理:NLTK的自然语言经典应用
Posted 神灯小叮当
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理:NLTK的自然语言经典应用相关的知识,希望对你有一定的参考价值。
今天,小叮当继续为大家分享自然语言处理的干货~
一、什么是自然语言处理?
我们来回顾下,什么是是自然语言处理?
简单来说,自然语言处理就是使字符串通过特征工程等方法变成计算机可以理解的0,1数据。
上次,我们简单了解了文本预处理。那么文本预处理使我们得到了什么呢?我们以啊甘名言“生活就像一块巧克力”为例,进行举例。
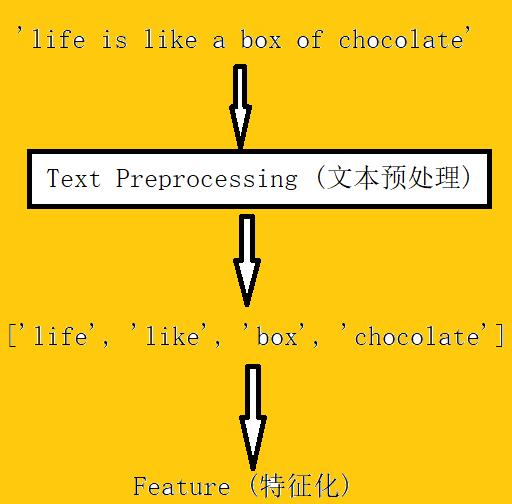
那么将预处理后的文本变成特征,我们该怎么做呢?这就要用到我们自然语言处理中的以下应用了。
二、NLTK在NLP上的经典应用
1.情感分析
最简单的例子就是,来分析微博评论对一条微博持支持或反对的态度。例如分析“花
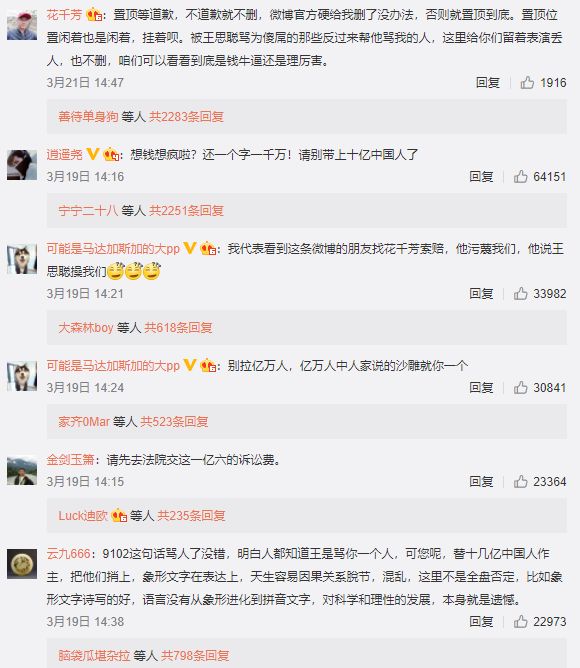
情感分析可以通过建立sentiment dictionary(情感字典)来实现。例如:like-(1),good-(2),bad-(-2),terrible-(-3) 这代表着like的情感正面程度分值为1,good的情感正面程度为2,bad的情感正面程度为-2,terrible的情感正面程度为-3。
当然,这些情感字典的分值是由一群语言学家共同讨论给出。我们可以看到这种方法类似于关键词打分机制。
例如,AFINN-111就是一个典型的情感字典。
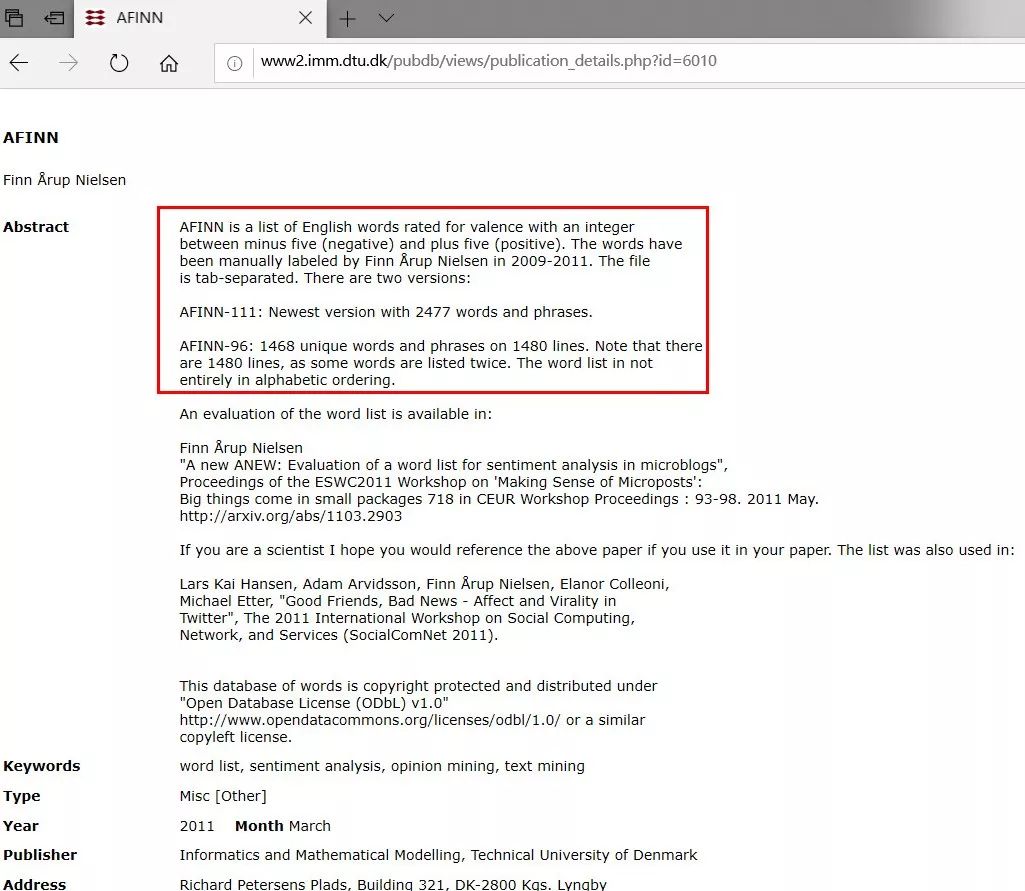
我们在对应网站上可以将其下载下来

使用NLTK完成简单的情感分析如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'IT小叮当'
__time__ = '2019-03-25 14:24'
#NLTK进行情感分析
#建立情感字典
sentiment_dictionary ={}
for line in open('E:\自然语言处理学习\情感分析字典AFINN\AFINN\AFINN-111.txt'):
word,score = line.split(' ')
sentiment_dictionary[word] = int(score)
sentence_1 ='i love you!'
sentence_2 ='i hate you!'
import nltk
word_list1 = nltk.word_tokenize(sentence_1)
word_list2 = nltk.word_tokenize(sentence_2)
#遍历每个句子,把每个词的情感得分相加,不在情感字典中的词分数全部置0
s1_score = sum(sentiment_dictionary.get(word,0) for word in word_list1)
s2_score = sum(sentiment_dictionary.get(word,0) for word in word_list2)
print('我是句子'+sentence_1+'的正面情感得分:',s1_score)
print('我是句子'+sentence_2+'的正面情感得分:',s2_score)
运行结果如下
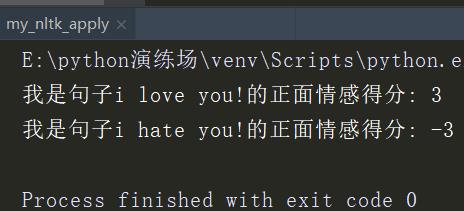
可以看到,使用这种方法,我们已经可以对句子进行简单的情感分析。
但是这种方法存在以下问题:
(1)出现网络新词不在字典里怎么办?
(2)出现特殊词汇怎么办?
(3)更深层的语义怎么理解?
为了解决这些问题,我们可以结合机器学习来进行情感分析。通过自己训练语料来使用机器学习进行预测。
以简单的贝叶斯训练示例,代码如下:
from nltk.classify import NaiveBayesClassifier
from nltk import word_tokenize
#简单手造的训练集
s1 = 'i am a good boy'
s2 = 'i am a handsome boy'
s3 = 'he is a bad boy'
s4 = 'he is a terrible boy'
# #建立词库,寻找所有句子中出现的不同的词
# s = list(set(word_tokenize(s1)+word_tokenize(s2)+word_tokenize(s3)+word_tokenize(s4)))
#预处理,对出现的单词记录为True
def preprocess(sentence):
return {word: True for word in sentence.lower().split()}
#预处理后得到字典类型,key表示fname对应句子中出现的单词
#value表示每个文本单词对应的值
#给训练集加标签
training_data = [[preprocess(s1),'pos'],
[preprocess(s2),'pos'],
[preprocess(s3),'neg'],
[preprocess(s4),'neg']
]
#将训练数据喂给贝叶斯分类器
model = NaiveBayesClassifier.train(training_data)
new_s1 = 'i am a good girl'
new_s2 = 'she is a terrible girl'
#输出预测结果
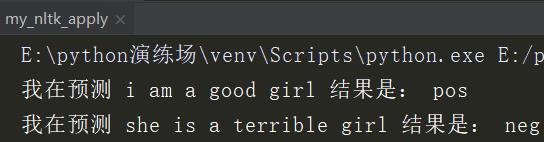
print('我在预测 '+new_s1+' 结果是:',model.classify(preprocess(new_s1)))
print('我在预测 '+new_s2+' 结果是:',model.classify(preprocess(new_s2)))
运行结果为
2.文本相似度
文本相似度都应用在哪里呢?举个简单的例子,大家在百度中搜索“IT小叮当”时,搜索页面会会根据我们的关键词,返回一系列的页面内容。
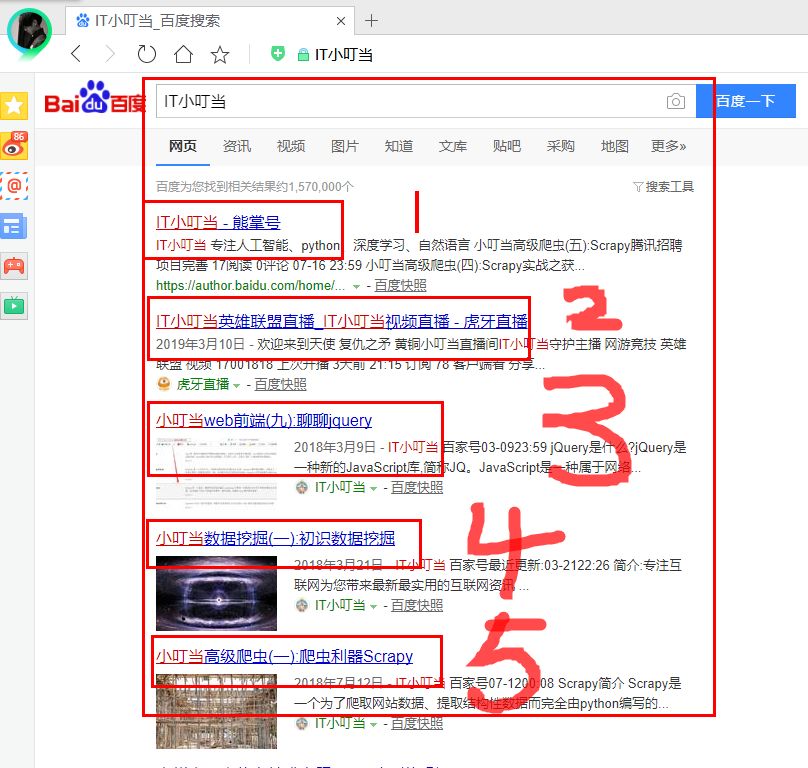
这时,网页会根据我们的搜索结果和关键词的相似度和其它的一些算法,对搜索的结果进行排序。
在NLP中处理句子时,句子的文本特征还可以用词元素的频率来进行表示。
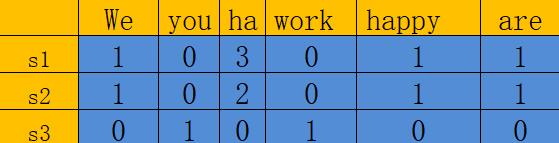
s1表示sentence1,句子1。表中的数值代表了单词出现的频率,根据这个我们可以猜测出句子内容如下:
句子1(s1):ha ha ha we are happy
句子2(s2): ha ha we are happy
句子3 (s3): you work
如此以来,句子1便可被向量[1,0,3,0,1,1]进行表示。句子2便可以被向量[1,0,2,0,1,1]表示,句子3可以被向量[0,1,0,1,0,0]表示。
用频率表示句子的好处是:
(1)所有句子的向量长度都是一样的,便于后期的机器学习
(2)向量的长度就是处理文本中不同的词的个数
在句子被向量化后,我们根据余弦定理便可计算出句子的相似度。
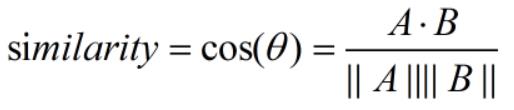
在NLTK中进行频率统计
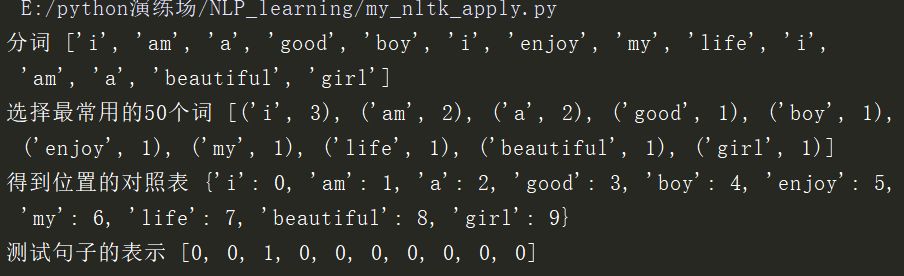
import nltk
from nltk import FreqDist
#随手自己做的词库
corpus = 'i am a good boy ' 'i enjoy my life ' 'i am a beautiful girl'
#文本预处理 分词、停用词、词干提取、词形归一
tokens = nltk.word_tokenize(corpus)
print('分词',tokens)
#频率统计
fdist = FreqDist(tokens)
#选择最常用的50个单词
standard_freq_vector = fdist.most_common(50)
#记录向量长度
size = len(standard_freq_vector)
print('选择最常用的50个词',standard_freq_vector)
#定义函数根据出现的频率大小记录下每个单词的位置
def position_record(v):
res = {}
counter = 0
for word in v:
res[word[0]] = counter
counter +=1
return res
#把标准的单词位置记录下来,得到一个位置的对照表
standard_position_dict = position_record(standard_freq_vector)
print('得到位置的对照表',standard_position_dict)
#构造一个新的测试句子
test_s = 'he is a children'
#构建于标准向量同样大小的零向量
freq_vector = [0] * size
#简单的预处理 进行分词
test_s_tokens = nltk.word_tokenize(test_s)
#测试句子中的每一个单词,如果在词库中出现过,就在标准位置上+1
for word in test_s_tokens:
try :
freq_vector[standard_position_dict[word]] += 1
except KeyError:
#如果是新词就pass
continue
print('测试句子的表示',freq_vector)
运行结果如下:
3.文本分类
文本分类的概念比较广,例如判断某句话是否是某人说的,一则新闻是属于政治、军事、还是其它的类别等等。
今天,我们就来了解一种常见的文本分类方法TF-IDF。
TF : Term Frequency,衡量一个term在文档中出现的多么频繁。
TF(t) =( t出现在文档中的次数)/(文档中term的总数)
IDF: Inverse Document Frequency,衡量一个term有多重要。
有些词在文章中可能出现的次数很多,但却不一定对文章的语义理解有用。例如‘is’,'the','a'等。
为了平衡这一现象,我们适当的降低这些无用的高频词的权重,把有用的词的权重(weight)提高。
IDF(t)=log_e(文档总数/含有t的文档总数)
这样一来,如果一个词在很多的文本中出现,那么它的IDF值会很低,反过来,如果一个词在比较少的文本中出现,那么它的IDF值会很高
TF-IDF = TF*IDF
可见TF-IDF,不仅考虑了词频,而且考虑了词对整个文档的贡献度(权重)。这要比单纯地考虑词的频率要好很多,在语义理解方面。
我们可以举个例子来进一步理解这个公式

例如:一篇文档中有100个单词,其中单词life出现了5次。
则 TF(life)= (5/100)=0.05
文档总共有10M,life出现在其中的1000个文档中
则 IDF(life) = log(10000000/1000)=4
TF-IDF(life) = TF(life)*IDF(life)=0.05*4=0.2
NLTK实现TF-IDF
代码如下
import nltk
from nltk.text import TextCollection
#将所有文档放到TextCollection类中,进行自动断句,统计,计算
corpus = TextCollection(['i am a good boy',
'i am a handsome boy',
'i enjoy my life '])
#计算出一句话中某个词的TF-IDF
print('boy在第一句话中的TF-IDF值',corpus.tf_idf('boy','i am a good boy'))
#获得标准大小的句子来表示句子
#分词
tokens = nltk.word_tokenize('i am a good boy '
'i am a handsome boy '
'i enjoy my life ')
#建立标准词库
standard_vocab = list(set(tokens))
print('标准词库为:',standard_vocab)
#新句子
new_sentence = 'she is a beautiful girl'
#获得新句子的TF-IDF向量
new_sentence_vector=[]
#遍历所有vocabulary中的词
for word in standard_vocab:
new_sentence_vector.append(corpus.tf_idf(word,new_sentence))
print('新句子的向量表示',new_sentence_vector)
运行结果如下
可以看到,经过如上的TF-IDF操作,我们可以得到每个句子的TF-IDF相同长度的向量表示。
之后根据这些向量,我们便可以使用机器学习来为我们愉快地分类了。
以上是关于自然语言处理:NLTK的自然语言经典应用的主要内容,如果未能解决你的问题,请参考以下文章