SFFAI 24 报名通知 | SFFAI X ICT 自然语言处理预训练专场
Posted 人工智能前沿讲习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SFFAI 24 报名通知 | SFFAI X ICT 自然语言处理预训练专场相关的知识,希望对你有一定的参考价值。

论坛主题
SFFAI X ICT 自然语言处理预训练专场
召集人

柳阳,中国科学院计算技术研究所智能信息处理重点实验室在读博士,本科毕业于南京大学。目前研究兴趣为网络表示学习应用,涉及领域有城市活动建模和区块链特定账户和交易模式挖掘。
论坛讲者

罗玲,2018年获南开大学工学学士学位,专业计算机科学与技术,现保送至中国科学院计算科学技术研究所智能信息处理实验室,研究兴趣为自然语言处理、语义分析,意⻅挖掘,文本摘要等。2018年在IJCAI会议一作发表论文1篇,大四于计算所实习期间参与债券舆情分析与金融风险感知等多个项目,并于2018年暑期入选腾讯犀牛鸟精英人才计划,赴腾讯AI Lab交流合作。
题目:From Word Representation to BERT
摘要:本次分享主要是通过简要介绍预训练词向量研究历程(word2vec,glove,ELMo等),重点介绍BERT的主要贡献。作为刷新GLUE榜单11项NLP任务(句子关系判断,分类任务,序列标注任务等)成绩的预训练模型,BERT不仅沿袭将词向量和下游任务结合在一起实现上下文相关的优点,并且通过masked语言模型实现了真正的深度双向模型。这使得BERT不仅能更好的处理sentence-level的任务,在token-level的语言任务上也达到了不错的效果。本次分享还将简要介绍BERT的相关应用以及一些近期的相关工作,探讨BERT对NLP任务的影响和未来发展。
Spotlight:
分享预训练词向量研究历程;
介绍BERT的背景知识,模型思路和重大贡献以及相关应用;
介绍近期相关工作,谈谈未来发展和感想。

马聪,2017年获北京科技大学工学学士学位,专业智能科学与技术,现保送至中国科学院自动化研究所模式识别国家重点实验室,研究兴趣为自然语言处理、机器翻译、多模态信息处理等。曾任中国科学院大学人工智能技术学院首届学生会主席。研究生入学至现在,以第三作者的身份分别参与了一篇EMNLP会议论文和一篇TKDE期刊论文。
题目:Generative Pre-Training in NLP & Its Generalization
摘要:本次分享将主要关注OpenAI在自然语言处理领域的两个预训练的工作GPT和GPT-2.0. 通过分析GPT的两个模型,重点探讨基于单向语言模型的NLP预训练过程对序列生成任务的作用以及利用预训练模型进行NLP多种任务无监督测试的方式和效果。GPT-2.0在机器翻译、问答系统、文本摘要等复杂任务上的性能展示出NLP预训练模型的强大功能以及其在自然语言序列生成中性能。本次分享还将简要介绍利用预训练模型在后续任务利用监督信息进行fine-tune的一些近期工作。
Spotlight:
分享GPT、GPT-2.0的设计思路和性能分析;
介绍GPT系列模型所应用的各种NLP任务定义及示例;
介绍NLP领域无监督预训练搭配监督微调的近期工作。

最近,在自然语言处理(NLP)领域中,使用语言模型预训练方法在多项 NLP 任务上都获得了不错的提升,广泛受到了各界的关注。今天,两位主讲嘉宾为大家精选了近期语言模型预训练方法中的几个代表性模型(包括 ELMo,OpenAI GPT 和 BERT),和大家一起学习分享最新的研究进展。
你可以仔细阅读,带着问题来现场交流哦。
1

推荐理由:一般来说,词向量在NLP的任务中需要解决两个问题:(1)词使用的复杂特性,如句法和语法;(2)如何在具体的语境下使用词,比如多义词的问题(在“我买了一个苹果手机”和“我买了5斤苹果”中的“苹果”的embedding应该是不同的)。该论文提出了ELMo模型,以基于多层双向LSTM语言模型为基础,用各层之间的线性组合来动态表示词向量,这样来解决多义词问题。ELMo训练即是通过计算前向和后向的语言模型的对数似然函数来优化模型。ELMo的使用即是将通过ELMo得到的所有词向量的线性组合运用到下游任务中。本文在Question answering、Textual entailment、Semantic role labeling、Coreference resolution、Named entity extraction、Sentiment analysis六个方向都做了实验,得到了很不错的提升。此外训练效率很高,使用ELMO词向量可以少98%epoch就能训练好,对于数据量越少的情况,使用ELMo效果好的越多。在BERT出现之前ELMo模型也算是小火了一把,读懂ELMo,以及对比各个主流模型的优缺点,会更能理解词向量和语义间的关系。
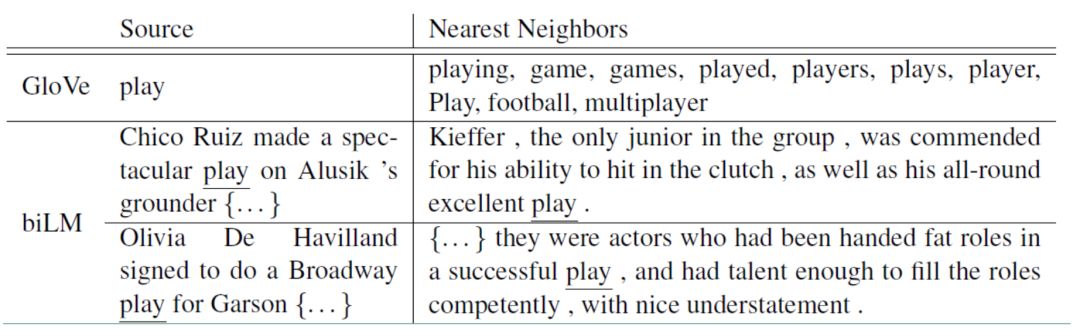
该图为ELMo得到的contextualized embedding的一例子
推荐理由来自:罗玲
2

推荐理由:作为截止2018年10月刷新了GLUE榜单上11项NLP任务的预训练模型,BERT可谓是在自然语言处理研究带来了一股浪潮。BERT使用了masked语言模型,实现了真正深度双向模型,不仅能更好地处理sentence-level的自然语言任务,而且在token-level的任务上也达到了不错的效果。BERT的预训练思想与结构,都值进一步的关注和探讨。
推荐理由来自:罗玲
3

推荐理由:Transformer提出之后,多头注意力机制现在广泛的运用在了各个NLP的任务上。本文就是基于多头注意力机制等,在语义角色标签任务上得到提升,获得了EMNLP 2018的最佳长篇论文。目前最先进的语义角色标签使用的是没有外部语言特征的深度神经网。但此前的研究表明黄金语法树可以极大地提高语义角色标签的解码。这篇文章提出了一种神经网络模型,名为linguistically-informed self-attention,它结合了多头注意力和多任务学习,能够预测检测结果和语义角色标签。这篇论文有很多亮点:一个共同训练句法和语义任务的转换器;在测试时注入高质量解析的能力;和范围外评估。同时还通过训练一个注意力头来关注每个token的句法父项,使Transformer的多头注意力对句法更加敏感。
推荐理由来自:罗玲
4

推荐理由:Open AI提出的自然语言处理中的预训练模型GPT-2.0版本。该篇论文中的预训练模型基本延续了GPT-1.0的模型结构,是基于Transformer的自注意力网络结构进行单向语言模型训练,其改进在于层归一化(Layer Norm)的位置,以及对层数的增加(最多达到48层)。另外该论文中使用了800万的丛Reddit上爬取的WebText数据资源来进行预训练,更大规模的训练数据,更大规模的网络架构使得GPT-2.0在语言模型上的预训练效果得到了进一步的提升。值得注意的是,GPT-2.0在一系列NLP的任务上进行了无监督测试的实验和分析,即在预训练过后,不进行fine-tune而直接进行测试。GPT-2.0在阅读理解、自动摘要、机器翻译、问答系统等较为复杂的NLP任务上都进行了无监督的测试,虽然无监督测试的结果同监督训练的性能还有一定的距离,但是GPT-2.0的无监督测试效果已经比无监督测试的一些state-of-the-art有了不小的提升。同时GPT-2.0在文本生成的效果上得到了非常流畅的结果,这大大归功于大规模语言模型的训练,也展示出了语言模型训练对文本生成的重要作用。
推荐理由来自:马聪
5

推荐理由:GPT-1.0的工作,该篇论文采取单向语言模型预训练的思想搭配fine-tune在一系列的NLP任务上达到了state-of-the-art的效果。预训练的过程中使用Transformer的解码器作为特征提取器,预训练过程以语言模型的目标函数作为优化目标;在fine-tune阶段,使用语言模型配合具体任务的损失函数线性加权进行训练。从整个工作的框架上分析,该篇工作属于半监督的范式。在成分分析实验部分,论文发现不进行模型预训练而直接进行监督训练会使得性能有较大的损失,而对于fine-tune部分删去语言模型损失函数与监督损失函数的线形叠加,只使用监督损失函数,会使得NLI任务的性能有一定下降,但是问答系统及文本分类的性能并没有受到影响,反而有小幅提升。总结来说,本文利用单向语言模型预训练Transformer在NLP预训练配合无监督及监督fine-tune做了初探性的工作,并展示出NLP任务也能受到预训练的益处。
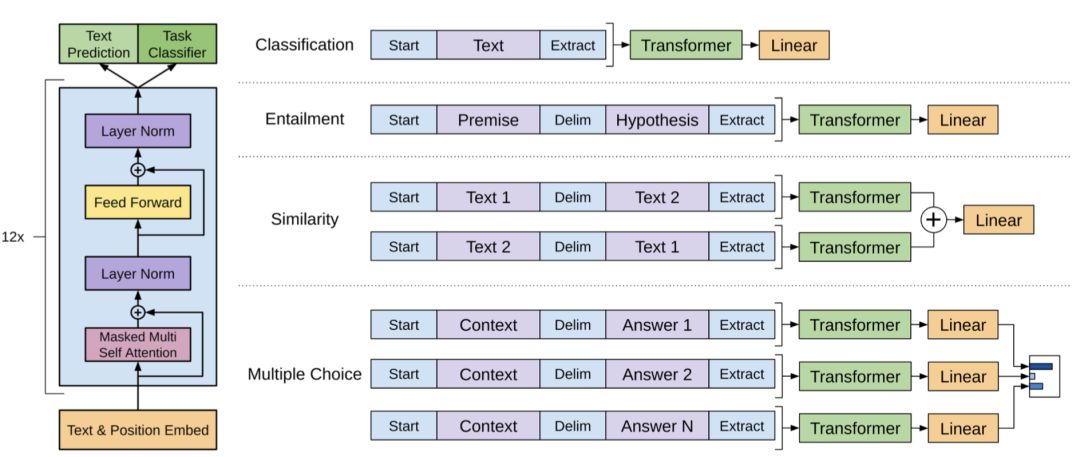
该图为GPT-1.0模型结构图
推荐理由来自:马聪
6

推荐理由:在面对在迁移学习中,源和目标设置之间的差异(例如,领域适应、持续学习和多任务学习中的任务)的时候,稳健的无监督方法是很有必要的。而对于跨语种嵌入映射任务的核心思想:分别训练单个语种语料,再通过线性变换映射到shared space,该文章研究的无监督方法self-learning。但self-learning初始化不好时,易陷入差的局部最优。本文通过观察到不同语种中相同的词有相似的相似度分布,于是提出了一种更有鲁棒性的初始化的方法。所以,利用领域专业知识和分析见解可以使模型更加稳健,这也是做NLP task的一种启发。
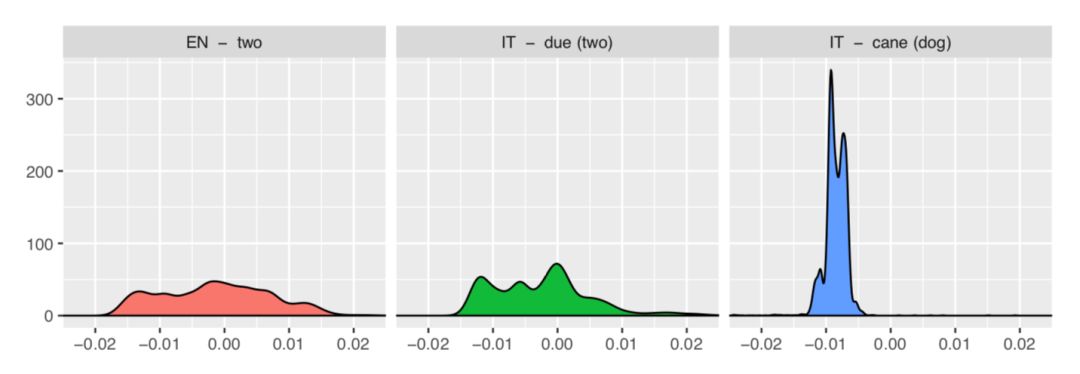
该图为不同语种中相同的词有相似的相似度分布
推荐理由来自:罗玲
7

推荐理由:元学习在少样本学习、强化学习和机器人学习中得到了广泛的应用,最突出的例子是与模型无关的元学习。在解决样本数量有限的问题上,元学习非常有用。对机器翻译领域来说,特别是一些小语种,可能收集的数据样本比较少,那么这个时候我们又希望这个翻译系统也能达到不错的效果,那就只能在小样本上面处理了。该论文(1)构造一个translation task generator用来生成不同的翻译task用于meta-train和meta-test,这就是一般Few-Shot Learning的构造;(2)将采集的task用于MetaNMT的训练,使用MAML训,目的就是为了得到一个好的初始化参数用于Meta-Test的task实现Fast Adaptation;(3)使用了一个Universal Lexical Representation 来表征不同的语种的特征,从而得到合适的embedding用于MetaNMT的训练。这篇paper是第一篇使用Meta Learning在Few-Shot NLP问题上的paper,相信Meta Learning未来还能更好地运用到更多NLP的任务中。
荐理由来自:罗玲
8

推荐理由:这篇工作发表在NAACL’19中。该论文主要是利用预训练ELMO模型,并将其后续搭配机器翻译、自动摘要工作来训练其在文本生成上的实验效果。在机器翻译任务上,该论文发现,当预训练完成后,在监督学习的fine-tune部分,如果监督的语料规模比较小,会使得预训练的模型好于只利用小规模训练的翻译模型;但是当翻译任务的语料规模较大时,预训练模型所展现出来的优势便不再明显。此外在文本摘要的任务上,利用预训练模型并配合fine-tune也会使得实验性能有一定的提升。
荐理由来自:马聪
9

推荐理由:这一篇工作是微软提出的利用多任务训练的架构MT-DNN在自然语言处理中进行预训练。该工作的基础模型共享Transformer,即把Transformer作为预训练的特征提取器,在不同的任务上共享该部分的参数。在下游任务上对应不同的task-specific架构,并搭配对应任务的损失函数,训练的过程进行整体模型的参数修改。该工作所使用的多任务搭配预训练的架构展示出不同的任务协同训练,可以一定程度为模型参数学习提供正则化的效果,是预训练模型并应用在下游任务的一种重要方式。
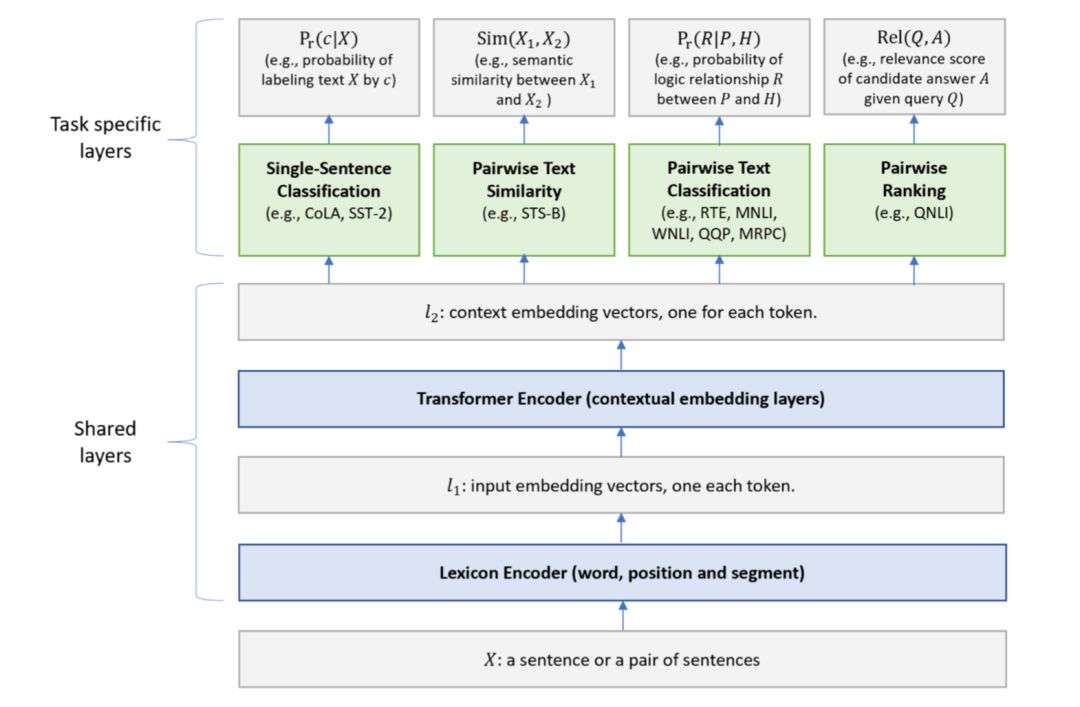
该图为MT-DNN模型架构图
推荐理由来自:马聪
10

推荐理由:这篇工作发布了一个工具包,来帮助研究工作人员对预训练的词向量进行抽取使用、评估以及可视化分析。文章中对预训练的词向量的分析主要基于词级别的语义相似度的分析上。作者开源了工具包的代码,同时分析了ELMO、BERT等预训练模型所学到的词向量以及效果分析。研究者在使用NLP预训练的模型前,可以利用该工具包分析一下不同预训练模型的特点和效果,以选择更适合研究任务的预训练模型。
推荐理由来自:马聪

时间
2019年4月14日(周日)
14:00 -- 17:00
地点
科学院南路6号中国科学院计算技术研究所四层
报名方式
点击下方阅读原文 或 扫描二维码报名
活动名额
1、为确保小范围深入交流,本次活动名额有限(不收取任何费用);
2、活动采取审核制报名,我们将根据用户研究方向与当期主题的契合度进行筛选,通过审核的用户将收到确认邮件;
SFFAI招募召集人!
Student Forums on Frontiers of Artificial Intelligence,简称SFFAI。
现代科学技术高度社会化,在科学理论与技术方法上更加趋向综合与统一,为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI自2018年9月16日举办第一期线下交流,每周一期,风雨无阻,截至目前已举办18期线下交流活动,共有34位讲者分享了他们的真知灼见,来自100多家单位的同学参与了现场交流,通过线上推文、网络直播等形式,50000+人次参与了SFFAI的活动。SFFAI已经成为人工智能学生交流的第一品牌,有一群志同道合的研究生Core-Member伙伴,有一批乐于分享的SPEAKER伙伴,还有许多认可活动价值、多次报名参加现场交流的观众。
2019年春季学期开始,SFFAI会继续在每周日举行一期主题论坛,我们邀请你一起来组织SFFAI主题论坛,加入SFFAI召集人团队。每个召集人负责1-2期SFFAI主题论坛的组织筹划,我们有一个SFFAI-CORE团队来支持你。一个人付出力所能及,创造一个一己之力不可及的自由丰盛。你带着你的思想,带着你的个性,来组织你感兴趣的SFFAI主题论坛。
当召集人有什么好处?
谁可以当召集人?
怎样才能成为召集人?
为什么要当召集人?
历史文章推荐:
若您觉得此篇推文不错,麻烦点点在看↓↓
以上是关于SFFAI 24 报名通知 | SFFAI X ICT 自然语言处理预训练专场的主要内容,如果未能解决你的问题,请参考以下文章