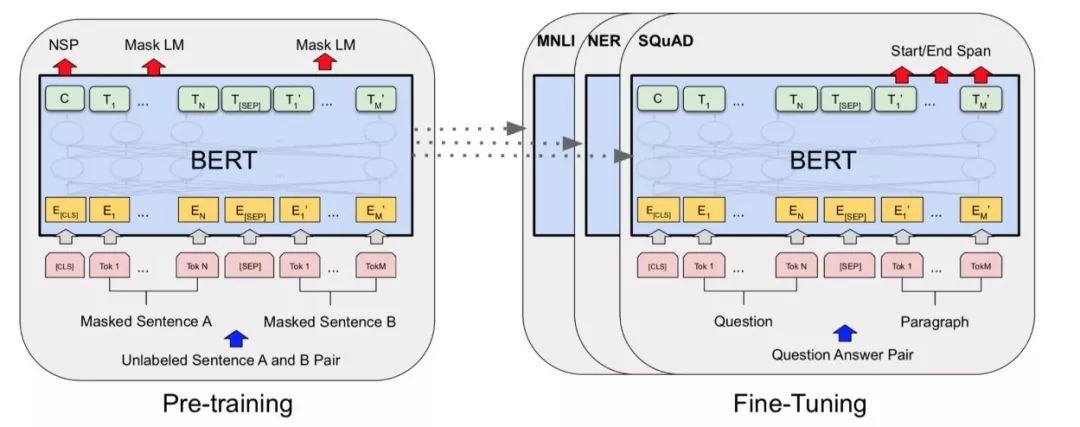
自然语言处理的新燃料,谷歌提出PAWS 和PAWS-X 数据集
Posted 将门创投
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理的新燃料,谷歌提出PAWS 和PAWS-X 数据集相关的知识,希望对你有一定的参考价值。
LET'S GET HIGH
将门 X 机器人学家

Flights from New York to Florida.
Flights to Florida from New York.
Flights from Florida to New York.
上面三个句子都是相同的词语却是不同的意思。第一句和第二句都是表示从纽约到佛州的同义句,而第三句则表示相反的航程,是前两句的非同义句。
识别句子是否具有相同含义的人物在自然语言处理中被称为同意句识别(paraphrase identification),这对于句子问答、语义理解、语音助手等多个领域都十分重要。
但即便是像BERT一样强大的模型,如果仅仅在现有的自然语言理解数据上训练,很多时候都无法区分出同型同词不同义的句子。其中最主要的原因是现存的数据中缺乏同型异义或同意句训练对儿,使得机器学习算法无法有效识别出复杂的上下文语法词法特性。
创建PAWS英文数据集
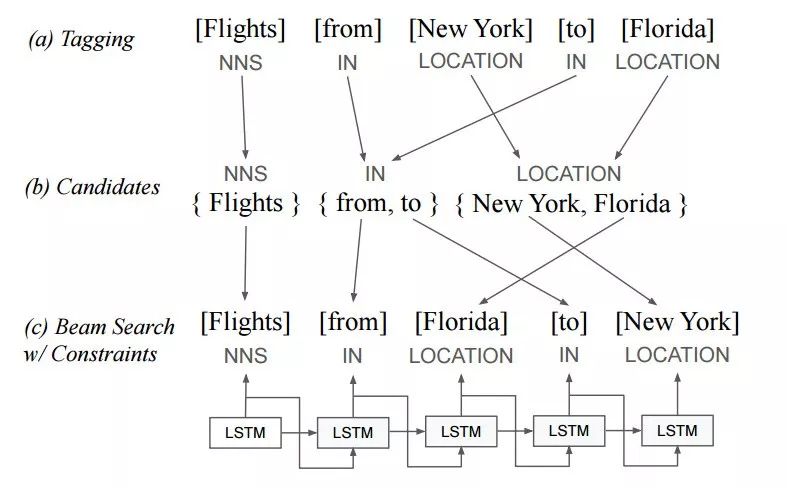
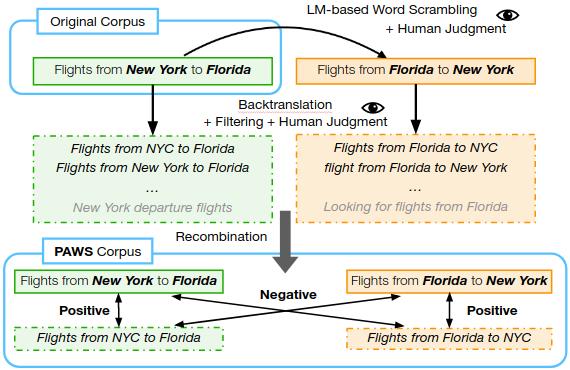
首先源句子被送入到一个序列化的语言模型中,创建出交换词序的变体同时包含有效的语义信息。但这时还无法确定它们是否是源句子的同义句。随后生成的句子变体将交与人类评测者来进行语法合理性评测,并由多个评测者来判断每个句子与源句子是否是同义句。
但其中一个重要的问题在于这种词序交换策略会倾向于生成非同义句(例如下面的句子交换了好坏:为什么坏事会发生在好人身上?/为什么好事会发生在坏人身上?)。为了保证同义句和非同义句间的平衡,研究人员引入了第三个步骤:backtranslation回译。
回译具有相反的偏执,倾向于在改变词序和词语选择时保持句子的含义不变。这一策略与前面的方法一起保证了PAWS数据的平衡,特别对于维基百科部分的句子尤为重要。
创建多语言PAWS-X 数据集
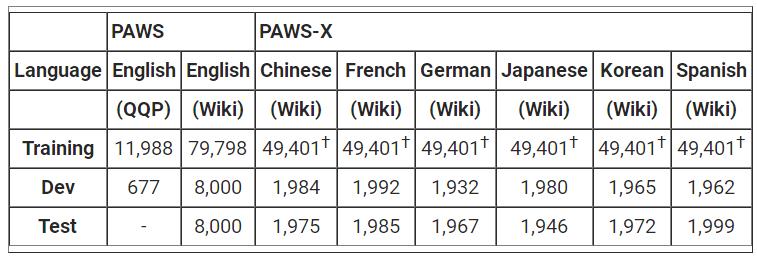
在构建PAWS数据集后,研究人员将这一数据集拓展到了多语言上:中文、法语、德语、韩语、日语和西班牙语。其中测试数据集由专业的人类翻译将英文翻译为对应的语言,对于训练数据来说则使用了神经机器翻译。
其中测试集是从PAWS中随机选出的4000对句子,针对六种语言一共得到了48000个翻译结果。其中每个句子对的翻译是彼此独立的,同时翻译结果也会进行随机采样由另一个翻译进行验证。这将人类翻译的测试集最终结果的错误率控制在了5%以内。翻译人员可以跳过不完整或含义模糊的句子,这导致了2%的句子没有翻译,最终将这些结果排除在外。
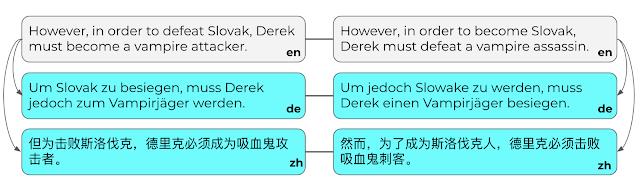
人类翻译的德语和中文句子对结果
基于新数据集的语言理解
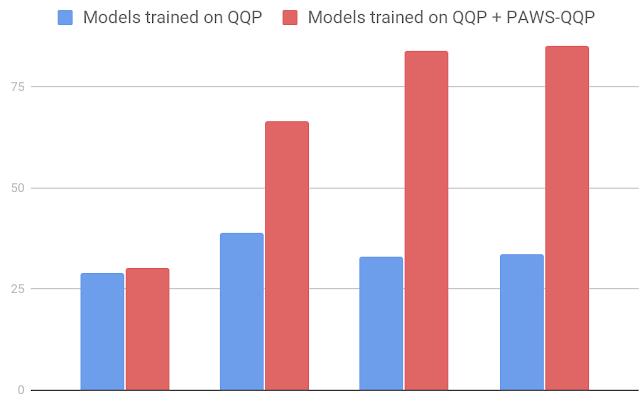
为了验证新数据集的效果,研究人员利用这些数据对多个模型进行了训练并测试了他们在同义句识别上的分类精度。结果表明像BERT和DIIN等强模型在PAWS的训练下,相较于目前的QQP(Quora Question Pairs)数据集得到了显著的提升。在PAWS的帮助下BERT的精度从33.5提高到了83.1。
但对于像词袋一类的弱模型来说,PAWS则没有带来显著的提升。这主要是由于弱模型在捕捉非局域上下文信息时的能力较差。下面的柱状体清晰地显示了PAWS对于测量模型对于词序和结构敏感性的有效性。
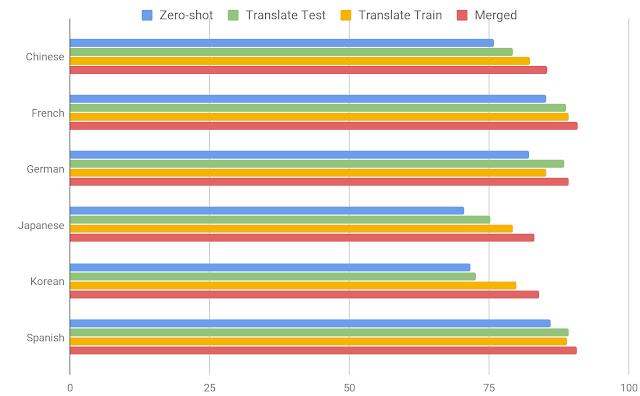
1.零样本学习:在PAWS英语数据集上训练,然后直接应用到其他语言上测试,没有机器翻译的参与;
2.翻译测试:利用英语训练数据训练模型,利用机器翻译将其他语言测试样本翻译到英语进行测试;
3.翻译训练:先利用机器翻译将英文训练数据翻译为目标语言,随后分别训练目标语言的分类模型;
4.融合:在所有语言上训练多语言模型,包括原始英文句子对和利用机器翻译将英文翻译为其他语言的数据共同作为训练集。
研究人员表示,这一数据集将有效推进多语言模型在句法结构、上下文、句子对比较等方面的深入研究。
如果想要了解更多详细的内容,可以参看论文:
https://arxiv.org/abs/1904.01130
并在这里找到数据集的和对应的测试代码:
https://github.com/google-research-data
参考资料

https://github.com/google-research-datasets/paws
https://github.com/google-research-datasets/paws/tree/master/pawsx
Quora:https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs
https://github.com/google-research/bertimg:https://miro.medium.com/max/1920/1*eKmT9U-IXvVWE6RV3bZ-IQ.jpegimgfrom:https://www.carolinabuzio.com/


来扫我呀
-The End-
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
将门创新服务专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
将门创投基金专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括机器智能、物联网、自然人机交互、企业计算。在三年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com
将门创投
让创新获得认可!
微信:thejiangmen
bp@thejiangmen.com
点击“❀在看”,让更多朋友们看到吧~
以上是关于自然语言处理的新燃料,谷歌提出PAWS 和PAWS-X 数据集的主要内容,如果未能解决你的问题,请参考以下文章