国产的自然语言处理框架ERNIE
Posted 算法学习分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了国产的自然语言处理框架ERNIE相关的知识,希望对你有一定的参考价值。
看到题目是否引发一些刻板印象?国产的自然语言处理,主要是用于处理中文?有没有用到最前沿的技术?是不是只提供服务,里面是黑盒?是否全面开源并提供模型?平台是否通用?本文将为您一一解答。
ERNIE是继BERT,ELMo之后又一个以芝麻街人物命名的自然语言模型。ERNIE全称 Enhanced Language Representation with Informative Entities。
01
原理
ERNIE的结构类似BERT框架,或可视为BERT的延续。也是通过海量无标签数据预训练模型,并在特定领域使用fine-tuning调优,同样也使用了在序列中插入符号,以适配不同的训练任务,以及Mask遮蔽部分数据的方法。
从全称可以看出,它最初主要致力于在自然语言处理中加入关于实体的信息。在ERNIE 1.0阶段,着重改进了遮蔽策略,BERT遮蔽语料中的词,而ERNIE把短语和一些专有名词也作为遮蔽的对象。之前的自然语言模型都是国外模型,因为分词有一定难度,所以处理中文时只是简单地以字为单位。可以想见,引入了词和短语后,ERNIE 1.0处理中文时有明显优势,在其它语言处理中也有提升。从原理上看,ERNIE在数据处理和模型结构中融入了更多的人类知识,比如短语、专有名词等等。
发展趋势
从互联网上抓取大量数据训练是自然语言处理的天然优势。那么,是不是掌握了所有数据就能解决所有问题?如何使用通用的知识解决具体问题?如何利用这些庞杂的数据,如何将散落在神经网络参数的中“知识”用于具体的场景之中,是目前研究的重要方向。
起初是从网络是训练和提取词的特征(GloVe);而后是提取词在某种前提下(如上下文)的特征(ELMo);然后是调整模型结构使之从一开始就适合解决多种问题,以便后期针对具体问题基于整个模型调优(GPT, BERT);继而希望使用单个模型解决各种问题(CTRL, ENRIE)。
ERNIE 2.0 核心
ERNIE 2.0核心目标有两点:同一模型适配多种任务,逐步进化。
同一模型适配多种任务,之前介绍用于续写的CTRL模型也有同样的目标,它具体的实现方法是把文章的类型信息作为序列的第一个元素代入训练,以便在预测时生成不同类型 文章;而ERNIE 2.0则是将任务类型Task Embedding与Word Embedding、Position Embedding、Segment Embedding一起作为模型的输入。
起初,模型的输入是词向量Word Embedding用于学习词义,用多个特征描述一个词汇;而后从RNN过渡到Attention模型时,加入了位置信息Position Embedding,通过训练学习位置的作用,模型不再依赖循环神经网络处理词的先后关系;BERT模型加入了段信息Segment Embedding用于组织数据,使单个可模型用于多种场景,比如单句的感情色彩分类,两句语义是否相同等等;ERNIE 2.0又引入了任务类型,用于学习不同的任务。
逐步进化也是一个难点,之前的架构基于海量数据预训练一个大模型,在解决具体问题时基于该模型调优。这样即利用了海量的知识,又减少了解决具体问题运算量。引发的问题是如何将调优时积累的知识汇入基础模型。看似不是什么核心技术,实际应用中却至关重要。
如果每一次加入少量信息都重新训练整个模型,其运算量是不可想象的;如果用针对具体任务fine-tuning后的模型替换通用模型,则某些通用知识会被具体任务中的领域知识所覆盖,损失了通用性。所以需要在学习新任务时不忘记前面学到的知识,同时还要保证学习速度。ERNIE在训练新任务时,先用之前的参数设置模型,然后用新任务的数据和原来的类似数据一起训练模型,以保证旧知识不被忘掉,而训练新任务的迭代次数自动计算生成,以保证学习速度。
ERNIE 2.0可谓良心之作,除了逐步多任务训练,还加入了一些新的技术:ERNIE可同时支持两个损失函数:一个在句子层面,一个在词层面。除了词和句,ERNIE还把任务划分成三类:词任务、句法任务、语义任务。在使用无标签数据方面,也更上一层楼。
词任务(Word):引入短语和专有名词的Mask(ERNIE 1.0功能);英文方面可预测大小写;标记同一文档中多次出现的词(可能在同一文档中含义相同,某词出现次数多也可能与主题相关)。
句法任务(Structure):通过重排段落中的句子,学习句与句之间的关系;句子间的距离是相邻关系、处于同一文档中、或者完全无关。
语义任务(Semantic):判断两句间语义或者修辞的相似度;通过搜索引擎技术提取某段文字的主旨,有三种关系:最强的关系是输入“主旨”,引擎找到了相应内容,且该内容被用户点击;弱关系是输入“主旨”,引擎找到了相应内容,但未被用户点击;第三种是无关,输入“主旨”查不到相应内容。
ERNIE 2.0 效果
ERNIE 2.0在中文任务中效果自不必说,在共计16个中英文任务上也超越了BERT和XLNet。
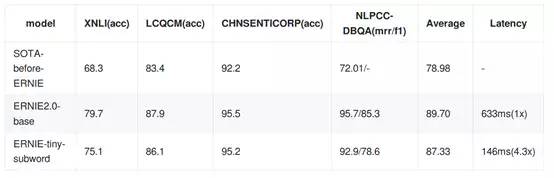
图片摘自论文, sota是State of the Arts的缩写,一般理解为比较先进的模型。
标准模型包含12个Encoder层,12头Attention,隐藏层维度768,是与BERT的基础版本类似的中型模型,为了提升ERNIE模型在实际工业应用中的落地能力,百度还发布了中文的ERNIE-tiny模型,预测提速4.3倍,减少了层数,加大了宽度(隐藏层元素个数)。从评测结果看,效果也不错,不过模型也不小,压缩包大小为1G左右。Git支持中文说明,其中展示了各种评测的具体效果。
02
代码分析
百度发布了ERNIE的完整代码和预训练模型,并且包含中文的说明文档。它的代码既不是TensorFlow也不是Pytorch,而是百度的深度学习平台飞桨PaddlePaddle,这提高了大多数开发者的学习成本。
代码位置在:https://github.com/PaddlePaddle/ERNIE/
核心代码在ernie/model/目录中,不过一两千行,目录中包含三个文件:
ernie.py ERNIE 2.0模型实现
ernie_v1.py ERINE 1.0模型实现
transformer_encoder.py 底层模型支持
其基础也是Transformer框架的Encoder部分,从实现transformer encoder可以看到飞桨平台和其它平台的语法差异。它与其它平台实现的函数名几乎都一样,如果熟悉其它深度学习工具,上手应该很快。
在核心模型外层,还实现了三组调用方法:预训练pretrain* ,调优fine-tuning,使用模型run_,还全面提供周边的辅助工具和文档,很像一个完整的软件,不加修改也可通过Python训练和使用。
03
深度学习框架哪家强
深度学习框架初看各有差异,实际都是实现各种层,优化器,误差函数,正反向传递;训练、预测、评估也都大同小异。只是思路和适配的场景略有不同。当然,从学习入门的角度看,只可能选择一个切入点,寻找最高效的方法,然后向外延展。
选择平台时,可参考以下几方面:
通用
首先,框架必须通用,看完一个新技术的论文之后都需要直接看代码,从这个角度看TensorFlow是首选,其次是Pytorch。易用性
飞桨和Pytorch的易用和理解难度都小于TensorFlow,都能很快上手。使用场景
使用场景又分移动端和主机端,移动端有其专门的工具;主机端需要考虑模型的大小、响应速度、稳定性等等因素。TensorFlow也是工业级应用的首选,飞桨支持多机多卡,在高效训练方面也有优势,而学术界更多地使用Pytorch。发展趋势
目前Pytorch和TensorFlow是两个最流行的深度学习框架,下图为最近几年各个领域发布论文的趋势图,实线是Pytorch,虚线为TensorFlow。不仅可从中看到深度学习领域的高速发展,也可看到近两年Pytorch的飞速发展。而今天的研究,将在明天成为产品。
TensorFlow 于2015年面世,这几年深度学习的高速发展,让TensorFlow超越之前的Caffe,Theano变为主流;TensorFlow框架出现较早,大家都使用它发论文,做产品;在行业快速兴起之后,它便成了主流。
Pytorch在2017年初推出,借助易用性成为学术界的新宠。Pytorch能快速发展,除了它本身的优点以外,很可能是由于它主要出现在研究领域,而研究领域对时间成本不是非常敏感。
某一框架能否被广泛使用,周边生态很重要。对于开源软件,大多数人都是拿来主义,越简单,工作量越少越好。工业领域需要计算学习成本、移植成本、收益、风险、稳定性,目前和未来的工作量,技术越成熟,成本计算越精确。投资回报可能比平台好坏更重要。垄断一旦形成,后来的平台如果没有决定性的优势,就很难发展起来。
以上是关于国产的自然语言处理框架ERNIE的主要内容,如果未能解决你的问题,请参考以下文章