自然语言处理实战--中文分词2
Posted 算法艺术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理实战--中文分词2相关的知识,希望对你有一定的参考价值。
前言:
2
统计分词
主要思想:将分词作为字在字符串中的序列标注任务来实现的;每一个字在构造一个特定的词语时,都占据着一个确定的构词位置。
词位:B(词首),M(词中),E(词尾),S(单独成词)
如:咬死/老猎人/的/狗
数学抽象表示:

理想的输出为:
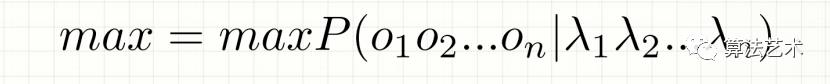
问题:P(o|lambda)是关于2n个变量的条件概率,且n不固定,因此无法对P(o|lambda)进行精确计算
所以:对lambda观测独立性假设,每个字的输出标记仅仅与当前的字有关
此时目标函数就大大简化
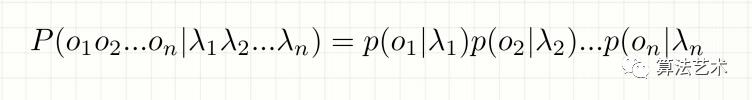
但是完全不考虑上下文,会出现不合理的情况,如BBB,BEM等
贝叶斯公式:
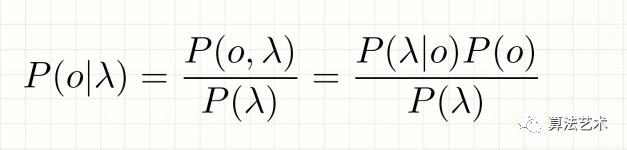
lambda为给定输入,P(lambda)是常数,可以忽略
最大化:
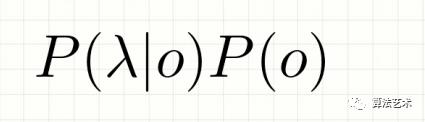
对于上式:
1.作马尔可夫假设
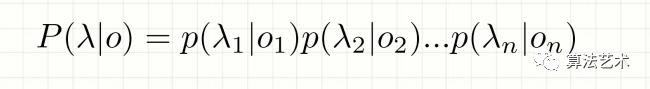
P(o)有:
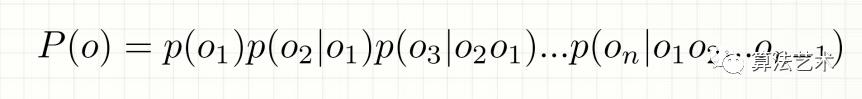
2.齐次作马尔可夫假设:每个输出仅与上一个输出有关
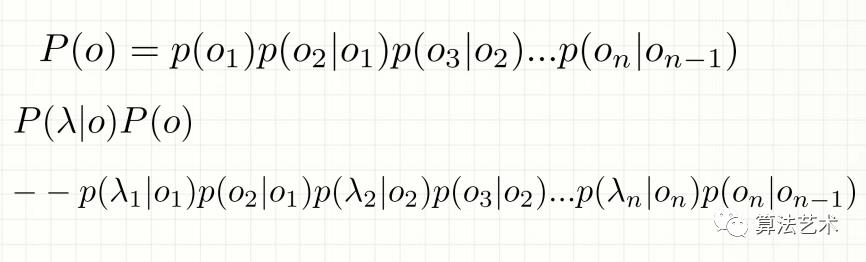
隐含马尔可夫模型:假设只与前一个输出有关
条件随机场模型:假设与前后输出都有关
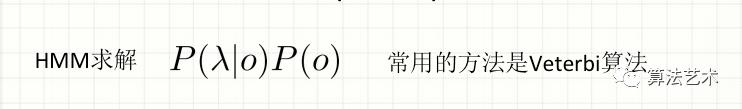
Veterbi算法:动态规划思想
如果最终优化的路径经过某个Oi,那么从初始节点到O_{i-1}的路径必然也是一个最优路径
HMM状态转移示意图:
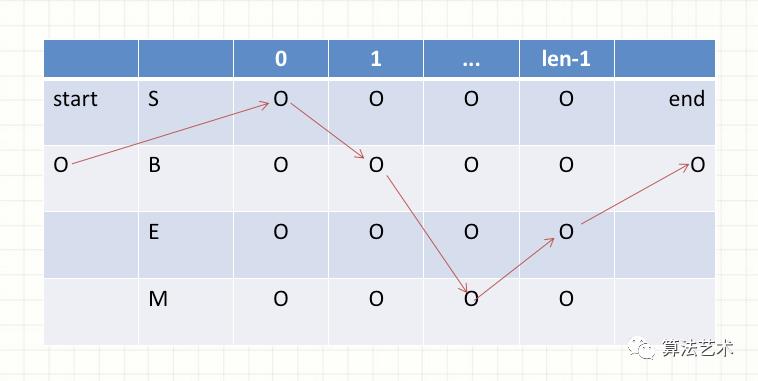
代码实现HMM:
class HMM(object):"""主要是初始化一下全局信息,用于初始化一下成员变量,如状态集合(标记S,B,M,E),以及存取概率计算的中间文件"""def __init__(self):import os# 主要是用于存取算法中间结果,不用每次都训练模型self.model_file = './data/hmm_model.pkl'# 状态值集合self.state_list = ['B', 'M', 'E', 'S']# 参数加载,用于判断是否需要重新加载model_fileself.load_para = False"""接受一个参数,用于判别是否加载中间文件结果。当知己加载中间结果时,可以不用过语料库训练,直接进行分词调用。否则,该函数用于初始化初始概率,转移概率以及发射概率等信息。这里的初始概率是指,一句话第一个字被标记成“S”,“B”,“M”,“E”的概率"""# 用于加载已计算的中间结果,当需要重新训练时,需初始化清空结果def try_load_model(self, trained):if trained:import picklewith open(self.model_file, 'rb') as f:self.A_dic = pickle.load(f)self.B_dic = pickle.load(f)self.Pi_dic = pickle.load(f)self.load_para = Trueelse:# 状态转移概率(状态->状态的条件概率)self.A_dic = {}# 发射概率(状态->词语的条件概率)self.B_dic = {}# 状态的初始概率self.Pi_dic = {}self.load_para = False"""用于通过给定的分词语料进行训练。"""# 计算转移概率、发射概率以及初始概率def train(self, path):# 重置几个概率矩阵self.try_load_model(False)# 统计状态出现次数,求p(o)Count_dic = {}# 初始化参数def init_parameters():for state in self.state_list:self.A_dic[state] = {s: 0.0 for s in self.state_list}self.Pi_dic[state] = 0.0self.B_dic[state] = {}Count_dic[state] = 0def makeLabel(text):out_text = []if len(text) == 1:out_text.append('S')else:out_text += ['B'] + ['M'] * (len(text) - 2) + ['E']return out_textinit_parameters()line_num = -1# 观察者集合,主要是字以及标点等words = set()with open(path, encoding='utf8') as f:for line in f:line_num += 1line = line.strip()if not line:continueword_list = [i for i in line if i != ' ']words |= set(word_list) # 更新字的集合linelist = line.split()line_state = []for w in linelist:line_state.extend(makeLabel(w))assert len(word_list) == len(line_state)for k, v in enumerate(line_state):Count_dic[v] += 1if k == 0:self.Pi_dic[v] += 1 # 每个句子的第一个字的状态,用于计算初始状态概率else:self.A_dic[line_state[k - 1]][v] += 1 # 计算转移概率self.B_dic[line_state[k]][word_list[k]] =self.B_dic[line_state[k]].get(word_list[k], 0) + 1.0 # 计算发射概率self.Pi_dic = {k: v * 1.0 / line_num for k, v in self.Pi_dic.items()}self.A_dic = {k: {k1: v1 / Count_dic[k] for k1, v1 in v.items()}for k, v in self.A_dic.items()}#加1平滑self.B_dic = {k: {k1: (v1 + 1) / Count_dic[k] for k1, v1 in v.items()}for k, v in self.B_dic.items()}#序列化import picklewith open(self.model_file, 'wb') as f:pickle.dump(self.A_dic, f)pickle.dump(self.B_dic, f)pickle.dump(self.Pi_dic, f)return self"""viterbi实现过程"""def viterbi(self, text, states, start_p, trans_p, emit_p):V = [{}]path = {}for y in states:V[0][y] = start_p[y] * emit_p[y].get(text[0], 0)path[y] = [y]for t in range(1, len(text)):V.append({})newpath = {}#检验训练的发射概率矩阵中是否有该字neverSeen = text[t] not in emit_p['S'].keys() andtext[t] not in emit_p['M'].keys() andtext[t] not in emit_p['E'].keys() andtext[t] not in emit_p['B'].keys()for y in states:emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0 #设置未知字单独成词(prob, state) = max([(V[t - 1][y0] * trans_p[y0].get(y, 0) *emitP, y0)for y0 in states if V[t - 1][y0] > 0])V[t][y] = probnewpath[y] = path[state] + [y]path = newpathif emit_p['M'].get(text[-1], 0)> emit_p['S'].get(text[-1], 0):(prob, state) = max([(V[len(text) - 1][y], y) for y in ('E','M')])else:(prob, state) = max([(V[len(text) - 1][y], y) for y in states])return (prob, path[state])"""对文本分词"""def cut(self, text):import osif not self.load_para:self.try_load_model(os.path.exists(self.model_file))prob, pos_list = self.viterbi(text, self.state_list, self.Pi_dic, self.A_dic, self.B_dic)begin, next = 0, 0for i, char in enumerate(text):pos = pos_list[i]if pos == 'B':begin = ielif pos == 'E':yield text[begin: i+1]next = i+1elif pos == 'S':yield charnext = i+1if next < len(text):yield text[next:]
输出结果:
import jiebasent = '中文分词是文本处理不可或缺的一步!'seg_list = jieba.cut(sent, cut_all=True)print('全模式:', '/ ' .join(seg_list))seg_list = jieba.cut(sent, cut_all=False)print('精确模式:', '/ '.join(seg_list))seg_list = jieba.cut(sent)print('默认精确模式:', '/ '.join(seg_list))seg_list = jieba.cut_for_search(sent)print('搜索引擎模式', '/ '.join(seg_list))#可以设置自定义词典jieba.set_dictionary('./data/dict.txt.big')
以上是关于自然语言处理实战--中文分词2的主要内容,如果未能解决你的问题,请参考以下文章