复旦大学黄萱菁:自然语言处理中的表示学习
Posted 读芯术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了复旦大学黄萱菁:自然语言处理中的表示学习相关的知识,希望对你有一定的参考价值。
不到现场,照样看最干货的学术报告!
嗨,大家好。这里是学术报告专栏,读芯术小编不定期挑选并亲自跑会,为大家奉献科技领域最优秀的学术报告,为同学们记录报告干货,并想方设法搞到一手的PPT和现场视频——足够干货,足够新鲜!话不多说,快快看过来,希望这些优秀的青年学者、专家杰青的学术报告 ,能让您在业余时间的知识阅读更有价值。
黄萱菁,复旦大学计算机科学技术学院教授、博士生导师。1998年于复旦大学获计算机理学博士学位,研究领域为人工智能、自然语言处理、信息检索和社会媒体分析。兼任中国中文信息学会常务理事,社会媒体专委会副主任,中国计算机学会中文信息技术专委会副主任。在SIGIR, IEEE TKDE, ACL, ICML, IJCAI, AAAI, SCIS, CIKM, EMNLP, WSDM和COLING等多个高水平国际学术期刊和会议上发表了近百篇论文,负责的多个科研项目受到国家自然科学基金、科技部、教育部、上海市科委的支持。近年来担任2014年ACM 信息与知识管理会议竞赛主席,2015年ACM 互联网搜索与数据挖掘会议组织者,2015年社会媒体处理大会程序委员会副主席,2016年、2019年全国计算语言学会议程序委员会副主席,2017年国际自然语言处理与中文计算会议程序委员会主席等学术职务,并入选由清华大学—中国工程院知识智能联合研究中心和清华大学人工智能研究院联合发布的“2020年度人工智能全球女性”及“2020年度AI 2000人工智能全球最具影响力提名学者”。

自然语言处理中的表示学习

首先,黄萱菁教授介绍了语言表示学习的内容。语言表示学习是一个非常主观性的概念,可以从很多角度给一个定义。从认知科学角度,语言表示是语言在人脑中的表现形式,关系到人们如何理解和产生语言;从人工智能角度,语言表示是语言的形式化或者数学描述,以便在计算机中表示语言,并且能够让计算机程序进行自动处理。好的文本表示是一个非常主观性的概念,需要具有很好的表示能力,比如说模型具有一定的深度;能够让后续学习任务变得简单,能够带来下游任务性能的提升;具有一般性,是任务或者领域独立的。
早期的语言表示主要采用符号化的离散表示,词表示为One-Hot向量,即一维为1、其余维为0的向量,比如电脑和计算机;句子或篇章通过词袋模型、TF-IDF模型、N元模型等方法进行转换。离散表示的缺点是词和词之间没有距离的概念,比如电脑和计算机语义几乎相同,但是它们的One-Hot表示完全不同,这是不合理的。目前主流语言表示采用更加精确的数学表示,通常使用基于深度学习的表示。深度学习是机器学习的一个子领域,传统机器学习方法通常需要人工设计的表示和特征提取方法,深度学习则不需要特征提取,甚至可以进行自动的表示学习。深度学习在自然语言处理的许多任务中都获得了重大进展,卷积神经网络、循环神经网络、对抗神经网络等神经网络一方面可以成功运用于分词、词性标注、命名实体识别等基本自然语言处理任务,另一方面也可以极大提升自动问答、对话等应用系统的性能。
接下来,黄萱菁教授的报告内容聚焦于表示学习,特别是语义表示。基于神经网络的表示学习是将不同粒度文本的潜在语法或语义特征分布式地存储在一组神经元中,用稠密、连续、低维的向量进行表示,这里的不同粒度包括词语、短语、句子、句对等。短语在语义层面上类似词语,结构上类似于句子,不同粒度的语言表示有不同的用途,比如词语和短语表示主要用于预训练,服务于下游任务,而句子和句对表示可以直接用于文本分类、匹配、阅读理解、语篇分析等具体任务。
词语表示学习也称词嵌入,它把词语从符号空间映射到向量空间。2013年之前,只有少量工作研究词嵌入,包括非常有名的、Bengio提出的神经语言模型;2013年之后有了大量新工作,特别有代表性的是word2vec和glove;2016年之后出现了短暂冷却现象;2018年之后又出现大量新工作,与从前学习相对比较独立的词向量不同,新工作学习带有上下文的语境化的词向量,经典工作有Elmo和Bert,相关的两篇论文都获得了NAACL最佳论文奖。学习上下文无关的词向量的众多模型中,word2vec是最高效的算法之一,它包括两个模型,一个是连续词袋模型,用上下文信息的平均预测目标词;另一个是跳词模型,用目标词预测上下文,这两种模型都可以学习高质量的词表示。不同于word2vec,glove是由斯坦福完成的,它直接建模两个词的共现频率和该词所对应向量内积间的关系,使它们尽可能接近,作者给出不同维度、不同语料训练词向量的结果,在实际研究过程中很有用。
短语和句子表示学习的方法是类似的,都和结构预测紧密相关。几种常见的语义组合函数都可以用于从词语序列语义表示生成短语句子的表示,包括递归神经网络、卷积神经网络、循环神经网络、Transformer等等,这些方法也可以组合起来使用。
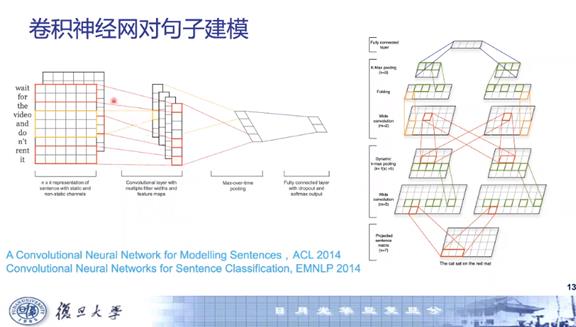
上图是卷积神经网络对句子建模的经典工作,采用双通道CNN得到句子表示,用于文本分类,通过动态Pooling机制解决句子变长的问题。循环神经网络用于对句子进行序列化建模,为了解决序列化建模过程中出现的梯度消失或者梯度弥散情况,先后有人提出了长短时记忆单元(LSTM)和门循环单元(GRU)。循环神经网络可以扩充为编码器-解码器的架构。其中编码器没有输出,在解码的时候则不需要新的输入;编码器用于理解,解码器用于生成,如果在解码的时候引入注意力机制,就可以进一步提升模型的性能。
接着,黄萱菁教授介绍了所在项目组在短语和句子表示学习方面所做的工作,他们在句子建模方面做的一项代表性工作是基于门机制的递归神经网络。利用树结构神经网络可以获得句子树结构,他们对树结构递归神经网络进行了改进,添加门机制,希望对上下文窗口之间的相邻字词组合关系进行更为精细的建模,从字间的关系构建词间的关系,从而构建整个句子结构。
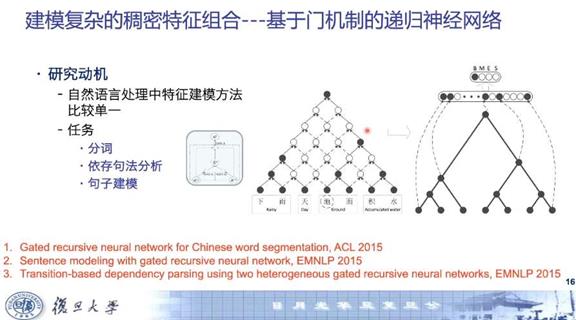
上图所示的例子“下雨天地面积水”,当前目标字是“地”,需要判断“地”是词首还是词尾。“天地”中“地”是词尾,“地面”中“地”是词首。实际上,这个句子非常复杂,任何两个相邻字都可以构成一个词。为了在给定上下文时预测“地”的标签是词尾还是词首,网络从底层到顶层,递归地进行特征组合。图中黑色是活跃神经元,空心是抑制神经元,边表示消息传递,实线边表示接受消息上传,虚线边表示拒绝,通过这样的过程可以得到整个句子的树结构(上图中最右侧),“下雨天-地面-积水”,还可以通过把所有组合特征合并到网络中来估计树结构的得分,这种模型可以同时得到句子表示和中间结果,可用于分词、依存句法分析和句子建模等任务。
黄萱菁教授的项目组所做的另一个改进是对二叉树的改进。句子的表示可以认为是句中所有词表示的组合,递归神经网络用一棵句法树,把词按照句法树的成分结构进行不断地递归组合,最后得到整个句子的表示。但是,递归神经网络只能处理二叉树的结构,而不能方便地拓展到依存句法树。因此,他们把递归神经网络和卷积神经网络进行组合,提出了一种可以处理多叉树的递归卷积神经网络模型,引入卷积层和池化层,从而把递归神经网络拓展到依存句法树上。再进一步地,黄萱菁教授的项目组发现在自然语言处理中,虽然可以用语义组合的方式得到句子的表示,但实际上并非所有短语句子语义都是合成性的,有一些短语语义不能由成分组合得到,比如马马虎虎、九牛二虎和马、老虎、牛没有关系。所以为了提升语义结构组合能力,他们采用了树结构LSTM,基于句法树递归对句子进行建模,并引入了参数化的控制器,从而能够自适应确定非叶节点的合成方式是合成性还是非合成性。模型分成三部分,分别是合成性非叶节点、非合成性的非叶节点和控制器。合成性非叶节点相应短语的表示,例如His performance是由子成分表示组合而来的;对于非合成性非叶节点的相应短语表示,例如at fever pitch不是由主成分得来,而是作为基本语言单位学习得到,具体则使用开关控制器控制合成的方式。

在句对表示学习方面,许多自然语言处理任务都可以建模为句对编码任务,比如句子的重述、蕴含分析、语篇分析等等,句子编码的目的是给定两个句子,建模其语义关系来学习表征。比如句子的蕴含分析,需要预测文本和假设之间是什么关系,如蕴含关系、中立关系、矛盾关系等等。黄萱菁教授的项目组在句对表示学习方面所做的工作是对语篇关系进行检测,即检测篇章中句子间的关系。以两个句子为例,一个发生在Early in the morning,另外一个发生在mid morning,它们之间是承接关系。用词向量差值可以表现句间关系,把两个句子的所有词两两做词向量的差值可以得到位移矩阵。通过位移矩阵可以预测句间关系,比如承接关系对应的矩阵中有大量平行箭头。另外,由于矩阵大小随句子长度变化,所以引入Fisher Vector的方法,把矩阵转变为定长向量,进行语篇关系分类。同时,项目组还利用门机制组合多种句子匹配函数,采用双向LSTM表示句中的词语,每个词语所对应的LSTM隐状态就表征词语和上下文。为了度量隐状态之间的相关性,项目组提出门相关性网络,它可以组合许多匹配函数,比如双线性张量和单层神经网络。
之后黄萱菁教授介绍了近期研究趋势,包括模型层面研究趋势、学习层面研究趋势、理解和解释层面的研究趋势。
模型层面包括图神经网络和Transformer。真实数据场景中,许多数据结构无法采用现有神经网络表示,比如社交网络、蛋白质交互关系、互联网等等。为了对这类图结构数据进行建模,研究者们提出图神经网络,它可以建模节点之间的语义关系、语义关联,可以很灵活地对结构化数据进行表示学习。把图神经网络用在语言表示的思路是定义或者学习一个句子的图结构,并且在图神经网络节点中加上上下文特征。句子结构可以用三种方式表示,分别是序列结构、句法树结构、任务相关语义结构,没有单一结构能够表示所有任务。黄萱菁教授的项目组把Transformer的自注意力机制扩展到图神经网络,提出语境化非局部网络,使得不同任务动态学习结构,它既可以学习节点和边的属性,对它进行编码,也可以学习节点之间的连边。这两点使得他们可以根据词语语境化表示和句子复杂结构更好地学习句子表示。Transformer是这几年最火的概念,它是全自注意力的机制,完全取代了神经网络中的经典合成函数,在各种任务上都取得了非常好的结果,它的成功可以归因于非局部结构偏置,句中任何一对词的依存关系都可以被建模。通过摒弃复杂语义组合和使用非局部结构偏置,Transformer可以提供更有效的计算,为Bert等模型打下基础,也有很好的可扩展性。但Transformer有一些缺点,例如两两之间计算开销非常大,和文本长度的平方呈正比,所以它需要大规模训练数据。黄萱菁教授的项目组提出了轻量化版本的星型Transformer,把全连接结构改成星型结构,任何两个节点都可以通过中继节点相连,这样模型的复杂度就从平方变成了线性,同样可以通过中继节点处理长距离依赖,通过圆环上的弧处理局部依赖。因为引入了局部依赖,就不再需要Position Embedding,因为复杂度降低可以适用于小规模和中等规模的数据。
学习层面近期研究趋势包括元学习、多任务学习、迁移学习等。在处理语言合成性时,如果采用同一个不变参数建模语言合成性,将无法捕捉合成的丰富性并且降低语言表现力;如果为每种合成策略分配独立的函数,但这些函数是硬编码的,就增加了复杂度,会引起数据稀疏。黄萱菁教授的项目组采用元学习的解决方案,他们不是直接采用可学习的参数化合成函数而是引入元神经网络,元神经网络可以动态生成真正用于组合树结构的基网络参数,从而扩展了模型表现力。多任务学习是一种联合多个任务同时学习来增强模型表示和泛化能力的手段。黄萱菁教授介绍了他们组一篇通过整合来自多个分词标准共享知识的论文,论文提出基于对抗策略的多标准学习方法,具体是把每个分词标准当成一个任务,在多任务学习框架下提出了三种共享和私有模型,平行模式、叠加模式和组合模式。黄色共享层用于提取不变特征,灰色私有层提取不同分词标准的私有特征。进一步地,利用对抗策略,从而可以确保共享层能够提取所有分词标准的不变特征,要求共享层不能预测出分词具体用哪一个标准语料库。迁移学习包括两个阶段,第一阶段是学习可迁移的知识,第二阶段是把知识迁移到新的任务。可迁移的知识可以通过监督学习或者无监督学习方式得到。无监督学习更加热门更受重视,先通过无监督方式学习可迁移的知识表示,再把知识迁移给新任务。预训练模型普遍采用无监督学习,其中ELMo采用双向LSTM;GPT首次用transformer decoder来进行预训练,decoder相当于是单向的语言模型,等于mask掉当前和后面的词;BERT是双向的语言模型,为了让预测的时候待预测词看不到自己,它引入了mask language model,随机mask待预测的词,再用双向语言模型预测这些词。预训练模型以ELMo为开始,以BERT为发展高潮,之后出现了非常多新的模型,这些模型逐渐发展,训练语料越来越大、参数数量越来越多、表现性能越来越高。今年他们组的一篇期刊文章对预训练模型进行了分类,按照是否语境化可以分为静态和动态模型,按照模型架构可以分成LSTM、Transformer Decoder、Transformer Encoder、完整的Transformer;根据学习任务来分,分成基于监督学习的模型,比如CoVe,和更多基于无监督或者自监督的预训练模型。
最后黄萱菁教授简单总结了当前自然语言处理研究面临的窘境。许多NLP竞赛成绩增长越来越慢,表明NLP系统性能趋于平台化,接下来神经网络NLP该往何处去?模型的可解释性将变得越来越重要,现在许多模型有着优越的性能,但是可解释性很低,如果不了解其中优缺点,很难在各种场景下做出最佳的选择。近期一些研究从可解释性角度对自然语言处理进行研究,可解释性包括面向模型可解释性和任务可解释性。面向模型的可解释性可以从认知角度、语言学角度看模型编码了哪些语言学特征,人类神经机理有什么相似程度;任务角度可以给定一个任务例如抽取式摘要、命名实体识别,研究模型的组成部分,了解不同设置下模型各自适应场景是什么,掌握怎么样进一步提高现有模型有效方向等。
(整理人:张雪丰)
AI未来说*青年学术论坛
第一期 数据挖掘专场
1.
2.
3.
4.
5.
第二期 自然语言处理专场
1.
2.
3.
4.
5.
第三期 计算机视觉专场
1.
2.
3.
4.
5.
第四期 语音技术专场
1.
2.
3.
4.
5.
第五期 量子计算专场
1.
2.
3.
4.
5.
第六期 机器学习专场
1.
2.
3.
4.
5.
第七期 自动驾驶专场
1.
2.
3.
4.
第八期 深度学习专场
1.
2.
3.
第九期 个性化内容推荐专场
1.
2.
第十期 视频理解与推荐专场
1.
第十一期 信息检索与知识图谱专场
1.
2.
3.
4.
5.
第十二期 年度特别专场
1.
2.
3.
4.
第十三期 AI助力疫情攻关线上专场
1.
2.
3.
4.
第十四期 深度学习线上专场
1.
2.
3.
4.
第十五期 大数据线上专场
1.
2.
3.
4.

我们一起分享AI学习与发展的干货
推荐文章阅读
读芯君爱你
以上是关于复旦大学黄萱菁:自然语言处理中的表示学习的主要内容,如果未能解决你的问题,请参考以下文章