数据结构与算法中的栈
Posted IT学习乐园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法中的栈相关的知识,希望对你有一定的参考价值。

最近晚上在家里看Algorithems,4th Edition,我买的英文版,觉得这本书写的比较浅显易懂,而且“图码并茂”,趁着这次机会打算好好学习做做笔记,这样也会印象深刻,这也是写这一系列文章的原因。另外普林斯顿大学在Coursera 上也有这本书同步的公开课,还有另外一门算法分析课,这门课程的作者也是这本书的作者,两门课都挺不错的。
计算机程序离不开算法和数据结构,本文简单介绍栈(Stack实现,典型应用等,希望能加深自己对这个简单数据结构的理解。
概念很简单,栈 (Stack)是一种后进先出(last in first off,LIFO)的数据结构,如下图:

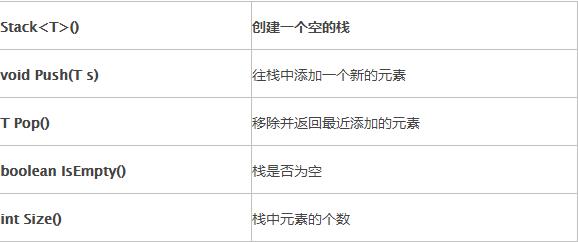
对于Stack 我们希望至少要对外提供以下几个方法:
要实现这些功能,我们有两中方法,数组和链表,先看链表实现。
我们首先定义一个内部类来保存每个链表的节点,该节点包括当前的值以及指向下一个的值,然后建立一个节点保存位于栈顶的值以及记录栈的元素个数;

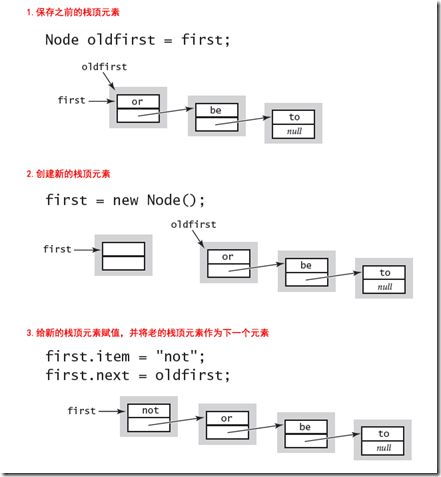
现在来实现Push方法,即向栈顶压入一个元素,首先保存原先的位于栈顶的元素,然后新建一个新的栈顶元素,然后将该元素的下一个指向原先的栈顶元素。整个Pop过程如下:
实现代码如下:

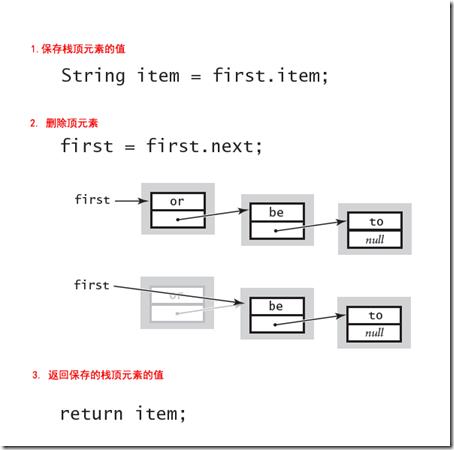
Pop方法也很简单,首先保存栈顶元素的值,然后将栈顶元素设置为下一个元素:

基于链表的Stack实现,在最坏的情况下只需要常量的时间来进行Push和Pop操作。
我们可以使用数组来存储栈中的元素Push的时候,直接添加一个元素S[N]到数组中,Pop的时候直接返回S[N-1].

首先,我们定义一个数组,然后在构造函数中给定初始化大小,Push方法实现如下,就是集合里添加一个元素:

Pop方法:

在Push和Pop方法中,为了节省内存空间,我们会对数组进行整理。Push的时候,当元素的个数达到数组的Capacity的时候,我们开辟2倍于当前元素的新数组,然后将原数组中的元素拷贝到新数组中。Pop的时候,当元素的个数小于当前容量的1/4的时候,我们将原数组的大小容量减少1/2。
Resize方法基本就是数组复制:

当我们缩小数组的时候,采用的是判断1/4的情况,这样效率要比1/2要高,因为可以有效避免在1/2附件插入,删除,插入,删除,从而频繁的扩大和缩小数组的情况。下图展示了在插入和删除的情况下数组中的元素以及数组大小的变化情况:

分析:1. Pop和Push操作在最坏的情况下与元素个数成比例的N的时间,时间主要花费在扩大或者缩小数组的个数时,数组拷贝上;2. 元素在内存中分布紧凑,密度高,便于利用内存的时间和空间局部性,便于CPU进行缓存,较LinkList内存占用小,效率高。
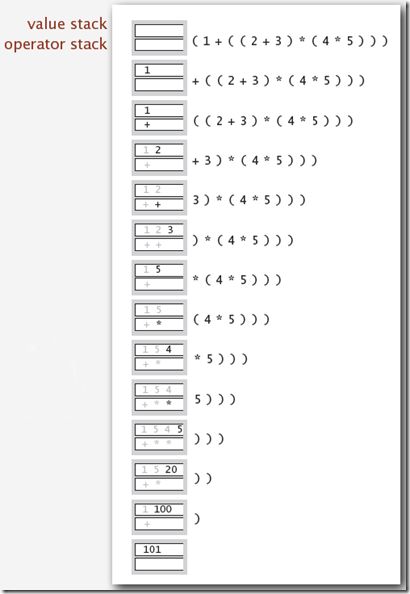
Stack使用的一个最经典的例子就是算术表达式的求值了,这其中还包括前缀表达式和后缀表达式的求值。E. W. Dijkstra发明了使用两个Stack,一个保存操作值,一个保存操作符的方法来实现表达式的求值,具体步骤如下:
1:当输入的是值的时候Push到属于值的栈中;
2:当输入的是运算符的时候,Push到运算符的栈中;
3:当遇到左括号的时候,忽略;
4:当遇到右括号的时候,Pop一个运算符,Pop两个值,然后将计算结果Push到值的栈中。
下面是在C#中的一个简单的括号表达式的求值:

运行结果如下:

下图演示了操作栈和数据栈的变化。
看完本文请分享一下吧!让其他人也可以GET到新知识!
来源:http://www.cnblogs.com/yangecnu/p/Introduction-Stack-and-Queue.html
编辑:@IT技术头条
免责声明:
2.如果出处标注有误或侵犯到原著作者权益,请联系删除,联系邮箱:drohon@126.com。
精彩文章回顾

非同名微博账号:@IT技术头条
戳文章最下方的“留言”说点什么吧!
以上是关于数据结构与算法中的栈的主要内容,如果未能解决你的问题,请参考以下文章