java中HashMap和HashTable有啥共同点和区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java中HashMap和HashTable有啥共同点和区别相关的知识,希望对你有一定的参考价值。
Hashtable和HashMap的区别:1.Hashtable是Dictionary的子类,HashMap是Map接口的一个实现类;
2.Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。即是说,在多线程应用程序中,不用专门的操作就安全地可以使用Hashtable了;而对于HashMap,则需要额外的同步机制。但HashMap的同步问题可通过Collections的一个静态方法得到解决:
Map Collections.synchronizedMap(Map m)
这个方法返回一个同步的Map,这个Map封装了底层的HashMap的所有方法,使得底层的HashMap即使是在多线程的环境中也是安全的。
3.在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断。 参考技术A HashMap和Hashtable都实现了Map接口,主要的区别有:
1、同步方面:Hashtable的方法是同步的,HashMap未经同步,所以在多线程场合要手动同步HashMap。
2、赋值方面:Hashtable不允许 null 值(key 和 value 都不可以),HashMap允许 null 值(key和value都可以)。
3、遍历方式不同:Hashtable比HashMap多一个elements方法。
4、动态数组增加方式不同:Hashtable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。 参考技术B 1 HashMap不是线程安全的
hastmap是一个接口 是map接口的子接口,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value,而hashtable不允许。
2 HashTable是线程安全的一个Collection。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。本回答被提问者和网友采纳
java读书笔记---HashMap和HashTable
首先来说说HashMap,HashMap是一个类,Java中所有的类都继承自一个Object类。Object类中定义了hashCode()方法,换言之,任何类都会有这个hashCode()方法。
因此key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。
先来看HashMap中定义的两个方法
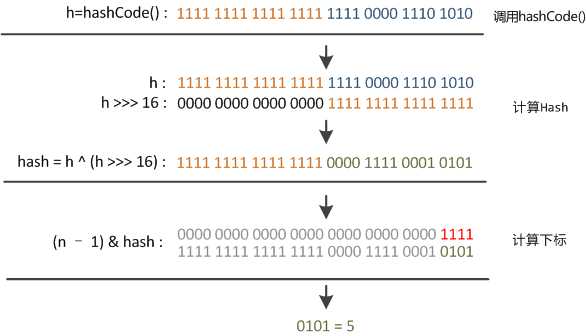
方法一: static final int hash(Object key) { //jdk1.8 & jdk1.7 int h; // h = key.hashCode() 为第一步 取hashCode值 // h ^ (h >>> 16) 为第二步 高位参与运算 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } 方法二: static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的 return h & (length-1); //第三步 取模运算 }
比如我们定义了Map map=new HashMap();当我们使用map.put("name","xiaoming")添加键值对的时候就会调用方法一的hash(Object key)的方法,该方法会返回"name"的hashCode值与“name”.hashCode()的值右移16位之后进行按位异或运算之后的值,这个值也相当于是在普通的hashCode()方法的基础上又做了一层加密。(事实上String类型的hashCode()方法在String类中已经重现了,但是在Object类中并没有实现,是在底层的C语言中实现的)
indexFor()方法是指定了HashMap对象在数组中的位置。另外当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如下图所示
HashMap和HashTable的作用大致相同,不同点如下所示
1.Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
2.Hashtable中,key和value都不允许出现null值。在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
3.两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
4.哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
5.Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
以上是关于java中HashMap和HashTable有啥共同点和区别的主要内容,如果未能解决你的问题,请参考以下文章