R基础:R语言数据结构1
Posted Ai尚研修科研技术动态
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R基础:R语言数据结构1相关的知识,希望对你有一定的参考价值。
R语言数据类型有:数值型、字符串型、逻辑型、日期型。
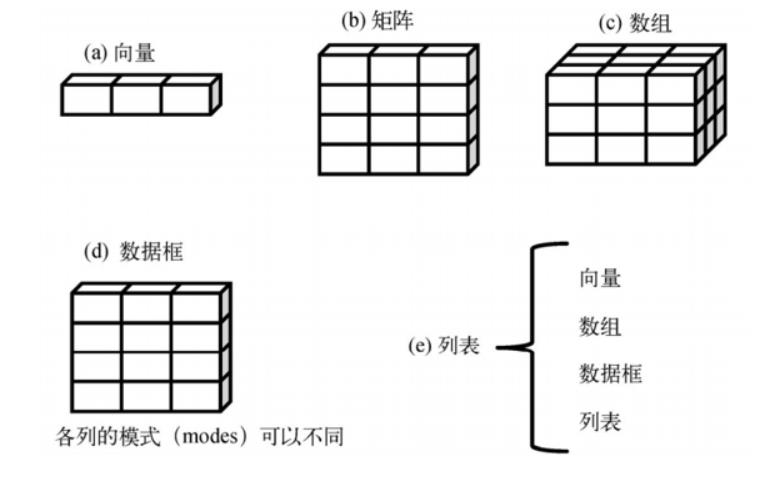
R语言对象的类型有:向量、标量、矩阵、数组、列表、数据框、因子等
向量:是一种一位的数据结构。
矩阵:则是二维的数据结构,是二维的向量。
数组:二维以上的向量。
数据框:是一种可以包含不同数据类型的矩阵,也算是二维的。
列表:是R里最复杂的数据结构,是一种有序的结合体,并具有对称性。
因子:其实就是一个数据集里的成分,在创建矩阵、数据框的时候我们都 经常用到因子,因子在R中非常重要。
几种数据类型:
向量(Vector):存储数值型、字符型或逻辑型数据的一维数组,存放的值一定是同种类型
k <- c(1, 2, 3, 4,5) #数值型向量k <- c("one", "two", "three") #字符型向量k <- c(TRUE, FALSE) #逻辑型向量> View(k)#查看k> str(k)#查看数据类型num [1:5] 1 2 3 4 5
矩阵(Matrix):每个元素拥有相同的模式(数值型、字符型或逻辑型)的二维数组
h=matrix(10001:10020)rname = c("L1","L2","L3","L4","L5")cname = c("lengh","reads","ratio","density")data = matrix(h,nrow = 5,ncol = 4,dimnames=list(rname,cname),byrow = TRUE)> str(data)#查看数据类型int [1:5, 1:4] 10001 10005 10009 10013 10017 10002 10006 10010 10014 10018 ...- attr(*, "dimnames")=List of 2..$ : chr [1:5] "L1" "L2" "L3" "L4" .....$ : chr [1:4] "lengh" "reads" "ratio" "density"
byrow=T:按行填充 byrow=F:按行填充
数组(Array):与矩阵类似,但维度可以大于2,c(行,列,块)
dim1 <- c('A1','A2')dim2 <- c('B1','B2','B3')dim3 <- c('C1','C2','C3','C4')z <- array(1:24,c(2,3,4),dimnames = list(dim1,dim2,dim3))#c(2,3,4)可以理解为2行3列4块> z, , C1B1 B2 B3A1 1 3 5A2 2 4 6, , C2B1 B2 B3A1 7 9 11A2 8 10 12, , C3B1 B2 B3A1 13 15 17A2 14 16 18, , C4B1 B2 B3A1 19 21 23A2 20 22 24
数据框(Data.fram):与矩阵类似,有行和列两个维度,数据框的每一列可以是不同的模式,但每个组件长度需相等,即类似于每个组件长度都相等的列表,数据框是R中最常数据的数据结构。
patientID <- c(1,2,3,4)age <- c(25,34,28,52)diabetes <- c('Type1','Type2','Type1','Type1')status <- c('Poor','Improved','Excellent','Poor')#生成一个名为patientdata的数据框patientdata <- data.frame(patientID,age,diabetes,status)> patientdatapatientID age diabetes status1 1 25 Type1 Poor2 2 34 Type2 Improved3 3 28 Type1 Excellent4 4 52 Type1 Poor#选取不同的元素> patientdata[1:3]patientID age diabetes1 1 25 Type12 2 34 Type23 3 28 Type14 4 52 Type1> patientdata[c('diabetes')]diabetes1 Type12 Type23 Type14 Type1> patientdata$patientID[1] 1 2 3 4
因子(Factor):
变量可以是连续性变量、名义变量和有序变量。
名义变量是没有顺序之别的分类变量,如性别。有序变量是有顺序高低的分类变量,如年龄。
名义变量和有序变量在R中称为因子(factor),因子在R中非常重要。
> diabetes[1] "Type1" "Type2" "Type1" "Type1"> diabetes=factor(diabetes)#作为因子输出> diabetes[1] Type1 Type2 Type1 Type1Levels: Type1 Type2> age[1] 25 34 28 52> ageOrdered=factor(age,ordered = T)#作为因子输出> ageOrdered[1] 25 34 28 52Levels: 25 < 28 < 34 < 52#数值型变量可以用levels和labels参数来编码成因子。例如将男性编码成1,女性编码成2。> sex <- c(1,2,1,1,2)> sex[1] 1 2 1 1 2> sex <- factor(sex,levels = c(1,2),labels = c('Male','Female'))> sex[1] Male Female Male Male FemaleLevels: Male Female
列表(List):对象的有序集合,例如某个列表可以是若干向量、矩阵、数据框,甚至其他列表的组合,是R的数据类型中最为复杂的一种。
> g <- 'My First List'> h <- c(25,26,18,39)> j <- matrix(1:10,nrow = 5)> k <- c('one','two','three')> list <- list(title=g,ages=h,j,k)> list$title[1] "My First List"$ages[1] 25 26 18 39[[3]][,1] [,2][1,] 1 6[2,] 2 7[3,] 3 8[4,] 4 9[5,] 5 10[[4]][1] "one" "two" "three"#选择列表中元素> list[["title"]][1] "My First List"> list[["age"]]NULL> list[["ages"]][1] 25 26 18 39> list[["2"]]NULL> list[[2]][1] 25 26 18 39
参考
R语言实战第二版
以上是关于R基础:R语言数据结构1的主要内容,如果未能解决你的问题,请参考以下文章