redis-基础数据结构一
Posted 春娇的志明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis-基础数据结构一相关的知识,希望对你有一定的参考价值。
前言
Redis 作为基于键值对的 NoSQL 数据库,具有高性能,丰富的数据结构,持久化,高可用,分布式等特性,这些特性使得 Redis 从同等竞品中脱颖而出,现如今已成为互联网公司软件架构的标配。
因此作为一名后端开发人员,有必要也有责任去搞清楚 Redis 的正确使用方式,了解其底层原理有助于工作中问题的排查。
基础数据结构
Redis 与 Memcached 同为内存数据库,并且数据存储都为 Key-Value 键值形式,不同点在于 Redis 的键值具有丰富的数据结构。
string(字符串)
hash(哈希)
list(列表)
set(集合)
zset(有序集合)
每种数据结构,除了介绍常用 command,还会说明其内部编码,以及常见的使用场景。
简单说明一下 Redis 内部编码的概念。上面讲到的 5 种数据结构其实只是 Redis 对外界提供的数据结构,实际上每种数据结构底层都有多种实现,称为内部编码,Redis 会在合适的场景选择合适的编码。这么做的好处:
可以改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出更优秀的内部编码,无需改动外部数据结构和命令
多种内部编码实现可以在不同场景下发挥各自的优势
今天我们就来认识一下 5 种基础数据结构的前两种(篇幅原因)字符串和哈希。
字符串
字符串类型是Redis最基础的数据结构。字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字(整数、浮点数)。
由于 redis 的字符串是二进制安全的,因此也可以存储二进制(图片、音频、视频)字符串,但是值最大不能超过512MB。
命令
添加键值
-- 覆盖式添加
set key value [ex seconds] [px milliseconds] [nx|xx]
示例:
set hello world
参数说明([] 中的是可选参数):
ex seconds:为键设置秒级过期时间
px milliseconds:为键设置毫秒级过期时间
nx:键必须不存在,才可以设置成功,用于添加
xx:与nx相反,键必须存在,才可以设置成功,用于更新
-- key 不存在才添加
setnx key value
-- key 存在才添加
setxx key value
setnx 命令可以作为分布式锁的解决方案,因为是单线程架构,同一时间只有一个客户端能够 setnx 成功。
获取值
get key
如果要获取的键不存在,则返回 nil(空)。
批量设置值
mset key value [key value ...]
示例:
-- 通过mset命令一次性设置4个键值对
mset a 1 b 2 c 3 d 4
批量获取值
mget key [key ...]
示例:
-- 批量获取键a、b、c、d的值
mget a b c d
使用批量操作命令可以提高开发效率,减少 redis client 与 server 通信的次数(网络延迟的消耗)。
计数
incr key
incr命令用于对值做自增操作,返回结果分为三种情况:
值不是整数,返回错误
值是整数,返回自增后的结果
键不存在,按照值为0自增,返回结果为1
相关的命令:decr(自减)、incrby(自增指定数字)、 decrby(自减指定数字)、incrbyfloat(自增浮点数)。
另外 redis 计数操作不存在线程安全问题(redis 单线程架构),因此无需像 java 语言需要引入同步锁或者CAS机制。
内部编码
字符串类型内部的编码有3种:
int:8个字节的长整型
embstr:小于等于39个字节的字符串
raw:大于39个字节的字符串
通过 object encoding key 可以查看 key 的内部编码。
示例1:
127.0.0.1:6379> set intkey 1234
OK
127.0.0.1:6379> object encoding intkey
"int"
示例2:
127.0.0.1:6379> set shortstringkey abc
OK
127.0.0.1:6379> object encoding shortstringkey
"embstr"
示例3:
127.0.0.1:6379> set longstringkey ......一个长度大于 39 字节的字符串
OK
127.0.0.1:6379> object encoding longstringkey
"raw"
使用场景
缓存功能
将热数据缓存在内存当中,加速读写,降低后端压力,另外设置合理的键名,有利于防止键冲突和项目的可维护性。
Tips:比较推荐的方式是使用『业务名:对象名:id:【属性】』作为键名,也可以适当减少键名的长度,减少内存浪费。
计数
许多应用都会使用Redis作为计数的基础工具,它可以实现快速计数、 查询缓存的功能,同时数据可以异步落地到其他数据源,例如社交应用中的点赞数。
共享 session
分布式Web服务将用户的 Session 信息放在 redis 中统一管理。
限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。
哈希
几乎所有的编程语言都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组。在Redis中,哈希类型是指键值本身又是一个键值对结构,形如value={{field1,value1},…{fieldN,valueN}}
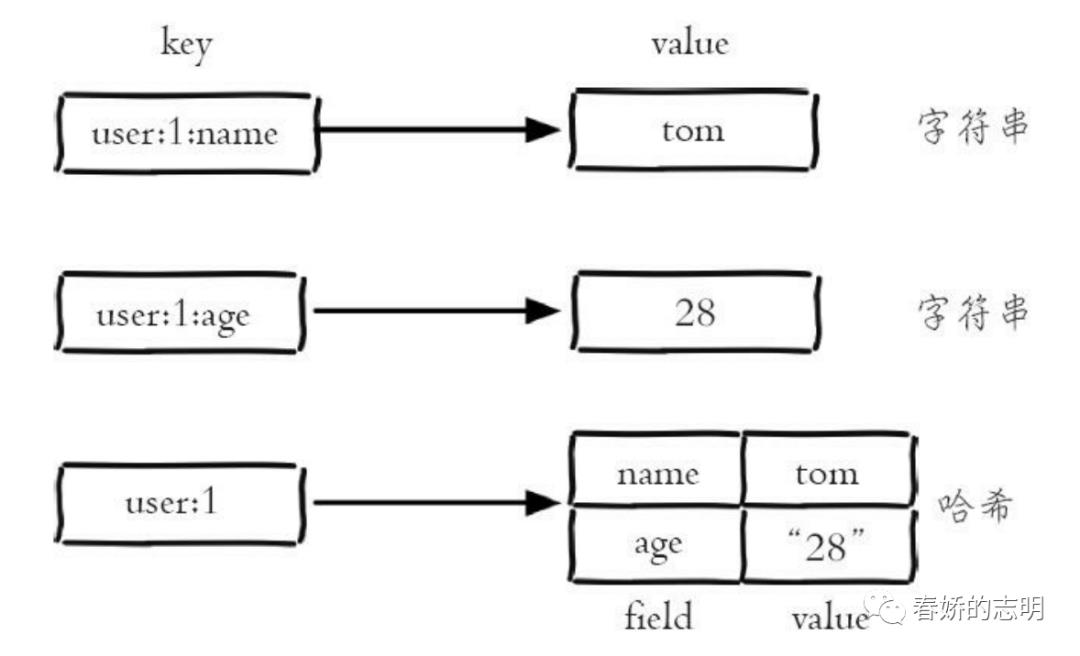
注意:哈希类型中的映射关系叫作field-value,注意这里的value是指field对应
的值,不是键对应的值,请注意value在不同上下文的作用
命令
设置值
hset key field value
示例:
127.0.0.1:6379> hset user name zm
(integer) 1
如果设置成功会返回1,反之会返回0。此外Redis提供了hsetnx命令,它们的关系就像set和setnx命令一样,只不过作用域由键变为field。
获取值
hget key field
示例:
127.0.0.1:6379> hget user name
"zm"
如果键或field不存在,会返回nil。
删除field
hdel key field [field ...]
示例:
127.0.0.1:6379> hdel user name
(integer) 1
127.0.0.1:6379> hget user name
(nil)
计算 field 个数
hlen key
返回 key 中 field-value 对的个数。
批量设置或获取 field-value
-- 批量设置
hmget key field [field ...]
-- 批量获取
hmset key field value [field value ...]
示例:
127.0.0.1:6379> hmget user name age
1) "zm"
2) "25"
判断 field 是否存在
hexists key field
存在返回 1,不存在返回 0。
获取所有 field
hkeys key
示例:
127.0.0.1:6379> hkeys user
1) "age"
2) "name"
获取所有 value
hvals key
示例:
127.0.0.1:6379> hvals user
1) "25"
2) "zm"
获取所有的 field-value
hgetall key
示例:
127.0.0.1:6379> hgetall user
1) "age"
2) "25"
3) "name"
4) "zm"
注意:在使用hgetall时,如果哈希元素个数比较多,会存在阻塞Redis的可能。如果开发人员只需要获取部分field,可以使用hmget,如果一定要获取全部 field-value,可以使用hscan命令。
内部编码
哈希类型的内部编码有两种,ziplist(压缩列表),hashtable(哈希表)。
ziplist
当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的
结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable
当哈希类型无法满足 ziplist 的条件时,Redis会使用 hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度为O(1)。
使用场景
很典型的一个使用场景:用来存储对象,因为对象的属性本身就是 field-value 形式的。
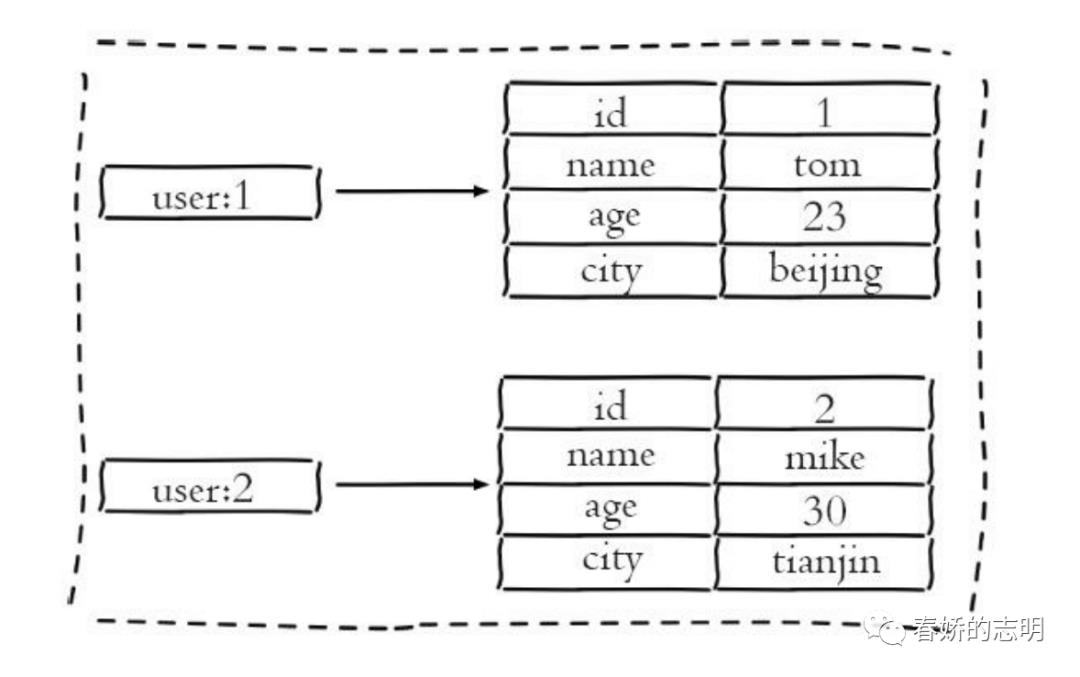
当然不使用哈希也能存储对象信息,也可以使用字符串。
原生字符串类型:每个属性一个键
示例:
set user:1:name zm
set user:1:age 25
set user:1:city 上海
缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,一般不推荐使用这种方式存储。
序列化字符串类型:将用户信息序列化后用一个键保存
示例:
set user:1 serialize(userInfo)
缺点:虽然节省了内存的开销,但是序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中。
哈希类型:每个用户属性使用一对field-value,但是只用一个键保存
示例:
hmset user:1 name zm age 25 city zhiming
哈希如果使用合理的话,不仅优化了内存使用,也省去了序列化反序列化的开销。
注意:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
总结
通过这篇文章,我们了解了:
redis 有哪些基础数据结构?
字符串类型的常用命令,内部编码,使用场景
哈希类型的常用命令,内部编码,使用场景
在下一篇文章中继续补充剩下的数据结构——列表,集合,有序集合。如果觉得文章对你有帮助,欢迎留言点赞。
长按扫码可关注
以上是关于redis-基础数据结构一的主要内容,如果未能解决你的问题,请参考以下文章