基本数据结构与算法
Posted 前端职场生存指南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基本数据结构与算法相关的知识,希望对你有一定的参考价值。
基本数据结构与算法
很多前端同学对 “数据结构与算法” 主题的内容望而却步,我想其中一个原因是前端的知识更新迭代很快,而且在工作中很少直接接触 “数据结构与算法” 的内容。但是这部分的内容依然是面试中非常重要的部分,在外企以及一些国内大厂的前端面试中,数据结构与算法是必考的部分。当然在大部分情况下,前端面试中只要掌握基本的数据结构与算法就足够了。
1. 什么是链表数据结构?其和数组有什么区别?
答案:
数组是最简单的内存数据结构。其由元素集合组成,分配一块连续的内存来进行存储,可以利用索引 (index) 来获取元素的值。
在 javascript中 声明数组非常简单:
let days = new Array('Monday', 'Wednesday')
days = ['Monday', 'Wednesday']
数组的好处在于:通过索引访问数组非常简单
console.log(days[1])
数组最大的缺陷在于:插入数据和删除数据效率很低。插入数据时,目标位置后面的数据在内存中都要后移,删除数据时,目标位置后面的数据在内存中都要前移。
而链表与数组不同的地方在于,其中的元素在内存中并不是连续放置的。每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(也称指针或链接)组成。
相对于数组,链表的好处在于:添加或移除元素的时候不需要移动其他元素
链表的缺陷在于:查找效率低,想访问链表中的元素时,需要从链表的起点迭代直到找到所需要的元素。
链表节点在JavaScript中的实现如下:
function ListNode(val) {
this.val = val;
this.next = null;
}
const n1 = new ListNode('1')
const n2 = new ListNode('2')
n1.next = n2
console.log(n1.next.val)
解读:
数组和列表都是线性表数据结构。除了数组和链表,另外两个常用的线性表数据结构是:栈和队列。
栈是一种遵从后进先出(LIFO)原则版本的数组,新添加或待删除的元素都保存在栈的同一端,称作栈顶,另一端就叫栈底。在栈里,新元素都靠近栈顶,旧元素都接近栈底。在开发过程中的 Error Stack、Stack Router等都是栈的实现。
队列是遵循先进先出(FIFO)原则版本的数组,如Event Loop中的消息队列 (message queue)就是队列的实现。
2. 斐波那契数列的公式定义如下
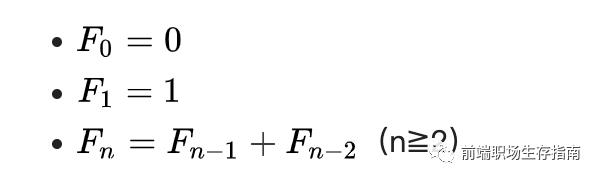
用文字来说,就是由0和1开始,之后的斐波那契数就是由之前的两数相加而得出,如:0、1、1、2、3、5、8、13、21。
请实现一个函数,传入参数为斐波那契数列的下标,而返回值为斐波那契数列对应下标的值。
答案:
迭代版本:
function fibonacciIterative(n) {
if (n < 1) return 0;
if (n <= 2) return 1;
let fibNMinus2 = 0;
let fibNMinus1 = 1;
let fibN = n;
for (let i = 2; i <= n; i++) { // n >= 2
fibN = fibNMinus1 + fibNMinus2; // f(n-1) + f(n-2)
fibNMinus2 = fibNMinus1;
fibNMinus1 = fibN;
}
return fibN;
}
递归版本:
function fibonacci(n){
if (n < 1) return 0;
if (n <= 2) return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
解读:
我们日常使用的 for,while 循环等都是迭代操作,迭代操作也是最容易想到的解法;
而这道题最重要是在考察递归操作,递归,就是自己调用自己,然后在合适的时机退出。显而易见,递归操作有代码容易理解、代码简洁等特点。
有一种有趣的描述:“为了理解递归,则必须首先理解递归。”
在一个递归函数中有三个关键点:
递归的退出条件,对应题目中
n < 1和n <= 2的情况;如何缩小问题的规模,在题目中对应:
fibonacci(n - 1) + fibonacci(n - 2),也就是说,把fibonacci(n)这个问题,转换成fibonacci(n - 1)和fibonacci(n - 2)的问题初始条件,例如斐波那契数列从0开始
题目中的递归代码虽然简洁,但是其有性能问题,如图:
可以看出,为了求fibonacci(5),fibonacci(3)被计算了两次,fibonacci(2)被计算了三次,而fibonacci(1)被计算了两次,可以使用闭包来缓存相同的计算结果从而提高性能:
// 递归性能优化版本
function fibonacciMemoization() {
const memo = [0, 1];
const fibonacci = (n) => {
if (memo[n] != null) return memo[n];
return memo[n] = fibonacci(n - 1, memo) + fibonacci(n - 2, memo);
};
return fibonacci;
}
const f = fibonacciMemoization()
f(8) // 21
另一个递归的经典题目是求阶乘,例如5的阶乘计算公式为:
5! = 5 * 4 * 3 * 2 * 1 = 120
迭代版阶乘:
function factorialIterative(number) {
if (number < 0) return undefined;
let total = 1;
for (let n = number; n > 1; n--) {
total = total * n;
}
return total;
}
递归版阶乘:
function factorial(n) {
if (n === 1 || n === 0) {
return 1
}
return n * factorial(n - 1);
}
递归是实现树相关的算法的必备工具。
3. 请写一个函数,用来验证一个传入的二叉树是不是二叉查找树 (binary search tree, BST)
BST 的定义如下:
若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
若任意节点的右子树不空,则右子树上所有节点的值均大于或等于它的根节点的值;
任意节点的左、右子树也分别为二叉查找树。
二叉树的节点定义如下:
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
答案:
const isValidBST = function(root) {
if (!root) {
return true;
}
function helper(root, min, max) {
if (!root) {
return true; // 当递归至叶子节点的子节点时,递归退出
}
if ((min !== null && root.val <= min) || (max !== null && root.val >= max)) {
return false; // 若不符合BST的定义规则,则返回false
}
// 缩小问题范围
return helper(root.left, min, root.val) && helper(root.right, root.val, max);
}
return helper(root, null, null);
};
解读:
树是一种非顺序结构,一个树结构包含一系列存在父子关系的节点。每个节点都有一个父节点(除了顶部的第一个节点)以及零个或多个子节点。位于树顶部的节点叫作根节点,树中的每个元素都叫作节点。而题目中提到的 “子树”是由一个节点和它的后代组成。
二叉树是一种特殊的树,其中的节点最多只能有两个子节点:一个是左侧子节点,另一个是右侧子节点。
二叉树结构往往和递归联系在一起,在这道题目中,我们使用递归来验证节点以及节点子树是否符合 BST 的定义。
4. 请实现二叉树的先序遍历、中序遍历和后序遍历函数,以此打印出节点的值。
二叉树节点定义如下:
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
答案:
// 前序遍历
function preTraversal(node) {
if (node) {
console.log(node.val);
preTraversal(node.left);
preTraversal(node.right);
}
}
// 中序遍历
function inTraversal(node) {
if (node) {
inTraversal(node.left);
console.log(node.val);
inTraversal(node.right);
}
}
// 后序遍历
function postTraversal(node) {
if (node) {
inTraversal(node.left);
inTraversal(node.right);
console.log(node.val);
}
}
解读:
3 种遍历方法的区别:
前序遍历:根节点 → 左侧子节点 → 右侧子节点
中序遍历:左侧子节点 → 根节点 → 右侧子节点
后序遍历:左侧子节点 → 右侧子节点 → 根节点
5. 请实现一个冒泡排序函数
答案:
function bubbleSort(array, compareFn = defaultCompare) {
const {length} = array;
for (let i = 0; i < length; i++) {
for (let j = 0; j < length - 1; j++) {
if (compareFn(array[j], array[j + 1]) === Compare.BIGGER_THAN) {
swap(array, j, j + 1);
}
}
}
return array;
}
function swap(array, a, b) {
const temp = array[a];
array[a] = array[b];
array[b] = temp;
}
function defaultCompare(a, b) {
return a < b ? -1 : 1;
}
解读:
冒泡排序比较所有相邻的项,然后根据比较结果进行交换,这种过程就像冒泡一样,这种排序方式因此得名冒泡排序。这种排序方式非常直观和容易理解,但是效率很低,时间复杂度为 O(n^2)
另一种著名的排序方法是选择排序,这是一种原址比较的排序算法,也就是说这种算法不需要再开辟新的内存来保存临时变量。这种排序的方法是找到数组中的最小值放在第一位,然后找到第二小的值放在第二位,以此类推:
function selectionSort(array, compareFn = defaultCompare) {
const {length} = array;
let indexMin;
for (let i = 0; i < length - 1; i++) {
indexMin = i;
for (let j = i; j < length; j++) {
if (compareFn(array[indexMin], array[j]) === Compare.BIGGER_THAN) {
indexMin = j;
}
}
if (i !== indexMin) {
swap(array, i, indexMin);
}
}
return array;
}
选择排序的时间复杂度也是 O(n^2)
另一个性能稍好的排序算法是归并排序,Mozilla Firefox 就是用它对Array.prototype.sort进行实现的。
function mergeSort(array, compareFn = defaultCompare) {
if (array.length > 1) {
const {length} = array;
// 定义主元,在这里是数组的中间位置
const middle = Math.floor(length / 2);
// 从中间位置切割,递归拆分数组,结合上面的array.length > 1这句退出条件,可以知道大数组最后将被切割成长度为1的数组
const left = mergeSort(array.slice(0, middle), compareFn);
const right = mergeSort(array.slice(middle, length), compareFn);
// 切割的过程中将左数组与右数组进行排序
array = merge(left, right, compareFn);
}
return array;
}
// 将两个排好序的小数组合并成一个排好序的大数组
function merge(left, right, compareFn) {
let i = 0;
let j = 0;
const result = [];
while (i < left.length && j < right.length) {
result.push(
// 两个小数组的指针同步往前走,同步进行比较,按照顺序push进result数组中
compareFn(left[i], right[j]) === Compare.LESS_THAN ? left[i++] : right[j++]
);
}
// 如果两个小数组长度不一样,将较长数组剩下的一节concat到result的末尾
return result.concat(i < left.length ? left.slice(i) : right.slice(j));
}
归并排序采用了分治法的策略,也就是说使用递归来简化问题。其递归的将数组分割成长度为 1 的小数组,然后将数组排序合并,最终合并为排序好的数组。其排序过程可以见归并排序动画版:https://visualgo.net/zh/sorting。其时间复杂度为 O(nlog(n))。
最后要介绍一个最常用的排序算法:快速排序。其时间复杂度为:O(nlog(n))
function quickSort(array, compareFn = defaultCompare) {
return quick(array, 0, array.length - 1, compareFn);
};
function quick(array, left, right, compareFn) {
let index;
if (array.length > 1) {
// 对数组进行 "大致" 排序,以数组中间值为主元,最终使得主元左边小于主元,主元右边大于主元
index = partition(array, left, right, compareFn);
if (left < index - 1) {
// 递归
quick(array, left, index - 1, compareFn);
}
if (index < right) {
// 递归
quick(array, index, right, compareFn);
}
}
return array;
};
// 对数组进行 "大致" 排序,以数组中间值为主元,最终使得主元左边小于主元,主元右边大于主元
function partition(array, left, right, compareFn) {
// 定义主元,在这里是数组的中间位置
const pivot = array[Math.floor((right + left) / 2)];
// i 为左指针,j 为右指针
let i = left;
let j = right;
// 当左指针超过右指针时,停止
while (i <= j) {
// 寻找主元左边比主元大的值
while (compareFn(array[i], pivot) === Compare.LESS_THAN) {
i++;
}
// 寻找主元右边比主元小的值
while (compareFn(array[j], pivot) === Compare.BIGGER_THAN) {
j--;
}
// 把上面找到的两个值交换,继续寻找并交换
if (i <= j) {
swap(array, i, j);
i++;
j--;
}
}
// 最后主元左边全是比它小的值,右边全是比它大的值
return i;
}
总结:
本节的题目提到了数组、栈、链表、队列、递归、二叉树、排序等前端面试中最常考的知识,尤其是二叉树和快速排序,由于其难度适中且非常实用,在前端面试中出现的概率很高,而且两者都应用到了递归,足见递归的重要性。
以上是关于基本数据结构与算法的主要内容,如果未能解决你的问题,请参考以下文章