分布式缓存中的hash算法
Posted 我是IT客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式缓存中的hash算法相关的知识,希望对你有一定的参考价值。
先看一下一致性hash环的构造过程:
1、先构造一个长度为0~232的整数环(一致性Hash环)
2、根据缓存服务器节点名称的0~232个Hash值将节点放置到这个Hash环上
3、由需要缓存的数据的Key值算出hash值(范围:0~232)
4、在Hash环上顺时针寻找和上述hash值最近的缓存服务器的节点
如上步骤完成了key到缓存服务器的hash映射查找。
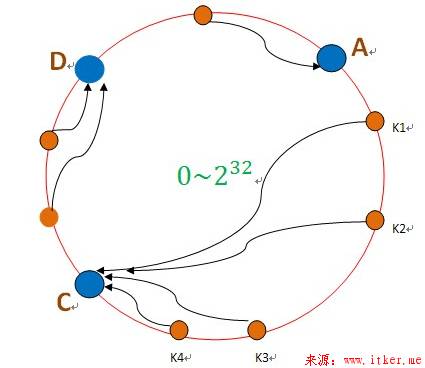
如上左图,假设k1的Hash值和C节点的Hash值接近,k1在环上顺时针查找,就可以找到最近的缓存服务器节点C。当缓存服务器集群做伸缩扩容的时候,假设新增加的节点处于Hash环B的位置,则k1顺时针查找后得到的节点就是B,由于key是顺时针查找距离最近的节点,所以新加入的节点只影响hash环的一小段,即上右图的AB之间的key。所以新加入节点B后,只有k1,k2从原来的命中节点C重新计算到了节点B,这可以保证大部分被缓存的数据不受影响而可以继续命中,且随着集群规模的扩大,继续命中原有缓存数据的概率也逐渐增大。
查找最近节点的算法一般使用二叉树实现,计算的过程实际是在二叉树上查找不小于查找数的最小值,只不过这里的二叉树左右边界的最远叶子节点是相连的,形成了环。
分析一下上述过程:新加入的节点B只影响节点C,原来访问C的缓存数据现在变成了访问B(50%的概率),节点A和节点D不受影响,换句话说节点A和节点D的缓存数据量和负载压力是节点B和节点C的2倍,意味着这种算法将导致负载不均衡。怎么破?
计算机领域有个虚拟层的概念,计算机中的任何问题都可以通过增加一个虚拟层来解决,这本身是对数学中的概率统计的很好运用,通过增加虚拟节点的数量来分散对实际物理节点的影响,使之更均衡。举个例子:两军对垒时将军和士兵谁的牺牲对战况的影响更大?众所周知,将军的战亡影响更大,这是因为将军的数量少,更容易成为重点阻击的目标,而如果把将军放到士兵中间,敌方袭击时产生的作用将大大减弱,因为士兵分散了袭击带来的影响,起到了缓冲和均衡破力的作用。放到这里可以理解成将军就是实际的缓存服务器的物理节点,士兵就是一组虚拟节点,虚拟节点均匀的放置在hash环上。key在环上找到了虚拟节点也意味着找到了物理节点。这样如果新加入一台物理服务器节点,就将一组虚拟节点加入环中,如果数目足够多,则新加入的虚拟节点将会影响同样多数目的已经在环上存在的虚拟节点,而这些虚拟节点对应不同的物理节点,最终会有这样一种结果:新加入的缓存服务器较均匀的影响原来已经存在的所有服务器,即分摊原有虚拟服务器集群中的所有服务器的负载,而总的影响范围不变。
虚拟节点越多,各个物理节点之间就会越均衡,新加入的节点就会对原节点的影响越保持一致,这也是一致性hash名称的由来。
以上是关于分布式缓存中的hash算法的主要内容,如果未能解决你的问题,请参考以下文章