海量数据去重之SimHash算法简介和应用
Posted 我是攻城师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海量数据去重之SimHash算法简介和应用相关的知识,希望对你有一定的参考价值。
SimHash是什么
SimHash是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling 》中提到的一种指纹生成算法或者叫指纹提取算法,被Google广泛应用在亿级的网页去重的Job中,作为locality sensitive hash(局部敏感哈希)的一种,其主要思想是降维,什么是降维? 举个通俗点的例子,一篇若干数量的文本内容,经过simhash降维后,可能仅仅得到一个长度为32或64位的二进制由01组成的字符串,这一点非常相似我们的身份证,试想一下,如果你要在中国13亿+的茫茫人海中寻找一个人,如果你不知道这个人的身份证,你可能要提供姓名 ,住址, 身高,体重,性别,等等维度的因素来确定是否为某个人,从这个例子已经能看出来,如果有一个一维的核心条件身份证,那么查询则是非常快速的,如果没有一维的身份证条件,可能综合其他几个非核心的维度,也能确定一个人,但是这种查询则就比较慢了,而通过我们的SimHash算法,则就像是给每个人生成了一个身份证,使复杂的事物,能够通过降维来简化。
SimHash的工作原理
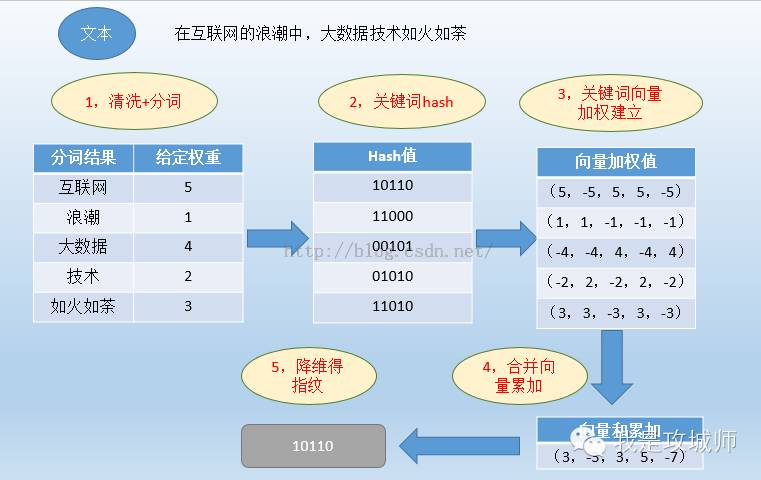
SimHash算法工作流程图:

解释下上图:
(1)准备一篇文本
(2)过滤清洗,提取n个特征关键词,这步一般用分词的方法实现,关于分词,比较常用的有IK,mmseg4j,ansj
(3)特征加权,这一步如果有自己针对某个行业的定义的语料库时候可以使用,没有的话,就用分词后的词频即可
(4)对关键词进行hash降维01组成的签名(上述是6位)
(5)然后向量加权,对于每一个6位的签名的每一位,如果是1,hash和权重正相乘,如果为0,则hash和权重负相乘,至此就能得到每个特征值的向量。
(6)合并所有的特征向量相加,得到一个最终的向量,然后降维,对于最终的向量的每一位如果大于0则为1,否则为0,这样就能得到最终的simhash的指纹签名
一个例子如下:
SimHash的应用
通过上面的步骤,我们可以利用SimHash算法为每一个网页生成一个向量指纹,那么问题来了,如何判断2篇文本的相似性?
这里面主要应用到是海明距离。
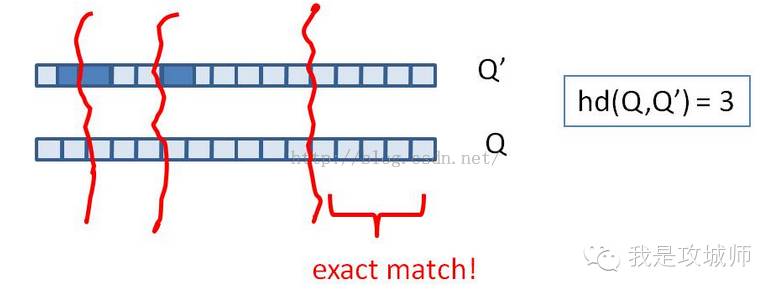
(1)什么是海明距离
两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。在一个有效编码集中,任意两个码字的海明距离的最小值称为该编码集的海明距离。举例如下:10101和00110从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。
(2)海明距离的几何意义
n位的码字可以用n维空间的超立方体的一个顶点来表示。两个码字之间的海明距离就是超立方体两个顶点之间的一条边,而且是这两个顶点之间的最短距离。
(3)海明距离的应用场景
用于编码的检错和纠错
经过SimHash算法提取来的指纹(Simhash对长文本500字+比较适用,短文本可能偏差较大,具体需要根据实际场景测试),最后使用海明距离,求相似,在google的论文给出的数据中,64位的签名,在海明距离为3的情况下,可认为两篇文档是相似的或者是重复的,当然这个值只是参考值,针对自己的应用可能又不同的测试取值
到这里相似度问题基本解决,但是按这个思路,在海量数据几百亿的数量下,效率问题还是没有解决的,因为数据是不断添加进来的,不可能每来一条数据,都要和全库的数据做一次比较,按照这种思路,处理速度会越来越慢,线性增长。
针对这个问题在Google的论文中也提出了对应的思路,根据鸽巢原理(也称抽屉原理):
桌上有十个苹果,要把这十个苹果放到九个抽屉里,无论怎样放,我们会发现至少会有一个抽屉里面至少放两个苹果。这一现象就是我们所说的“抽屉原理”。 抽屉原理的一般含义为:“如果每个抽屉代表一个集合,每一个苹果就可以代表一个元素,假如有n+1个元素放到n个集合中去,其中必定有一个集合里至少有两个元素。” 抽屉原理有时也被称为鸽巢原理。它是组合数学中一个重要的原理。[1]
道理很简单,但在把这应用到现实问题中,可是能发挥巨大作用的,这也就是数学的奥妙之处。
针对海量数据的去重效率,我们可以将64位指纹,切分为4份16位的数据块,根据抽屉原理在海明距离为3的情况,如果两个文档相似,那么它必有一个块的数据是相等的,如图:
然后将4份数据通过K-V数据库或倒排索引存储起来K为16位截断指纹,V为K相等时剩余的48位指纹集合,查询时候,精确匹配这个指纹的4个16位截断,如图所示:
如此,假设样本库,有2^34条数据(171亿数据),假设数据均匀分布,则每个16位(16个01数字随机组成的组合为2^16个)倒排返回的最大数量为
2^34/2^16=2^(34-16)=262144个候选结果,4个16位截断索引,总的结果为:4*262144=1048576,约为100多万,通过
这样一来的降维处理,原来需要比较171亿次,现在只需要比较100万次即可得到结果,这样以来大大提升了计算效率。
参考文章:
http://www.lanceyan.com/tech/arch/simhash_hamming_distance_similarity.html
http://taop.marchtea.com/06.03.html
http://yanyiwu.com/work/2014/01/30/simhash-shi-xian-xiang-jie.html
http://www.cnblogs.com/colorfulkoala/archive/2012/07/29/2614382.html
http://en.wikipedia.org/wiki/Locality_sensitive_hashing
http://grunt1223.iteye.com/blog/964564
以上是关于海量数据去重之SimHash算法简介和应用的主要内容,如果未能解决你的问题,请参考以下文章