以太坊源代码 - ethash算法介绍
Posted 星想法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了以太坊源代码 - ethash算法介绍相关的知识,希望对你有一定的参考价值。
Ethash算法是以太坊挖矿算法,是在Dagger-Hashimoto的基础实现的。基本的算法流程如下:
*)生成种子数据(和区块信息相关) *)生成cache数据 *)生成DAG数据 *)寻找nonce,计算区块头的hash,保证hash的结果小于区块头中指定的难度。
具体代码在consensus/algorithm.go。
0)定义的常量
DAG的初始大小是1G,cache的初始大小是16M,一个世纪是30000个区块。cache以及DAG是随着世纪在增长。
1)cache大小以及数据生成
cache大小计算,在初始大小的基础上,每过一个世纪,增加128k。最靠近这个的质数(以2*hashBytes)减少。

目前的世纪数是185,也就是cache的大小接近:16M+185*128k = 39.1M。
cache数据的生成逻辑在generateCache函数中,逻辑如下图:
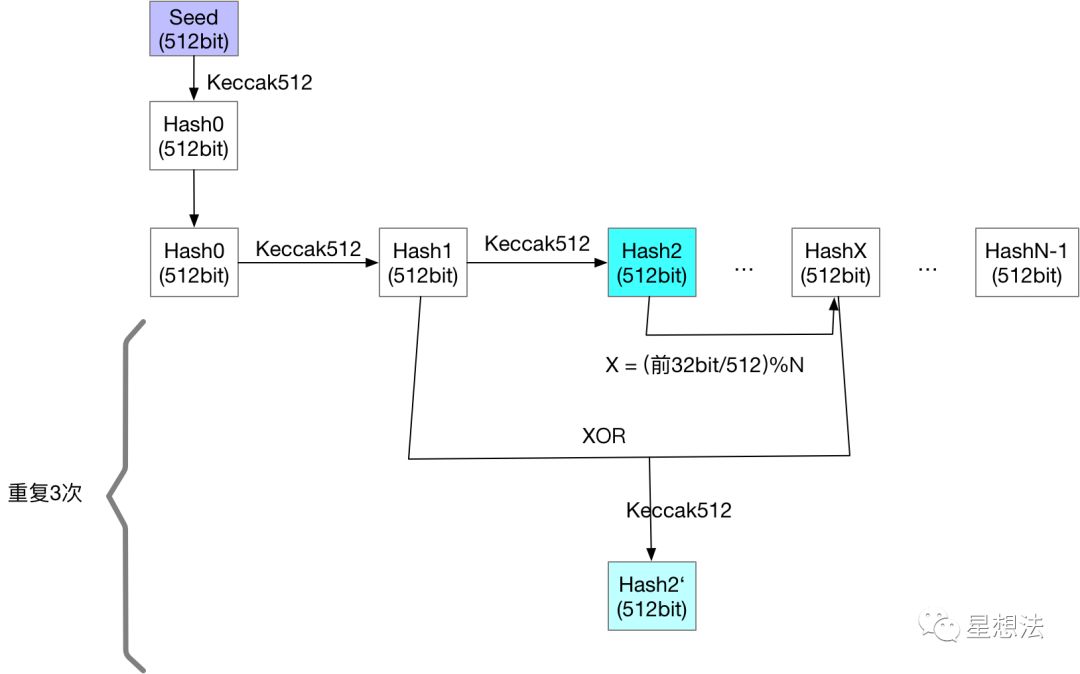
其中seed的计算
2)DAG大小以及数据生成
DAG的大小的计算和cache大小的计算类似:

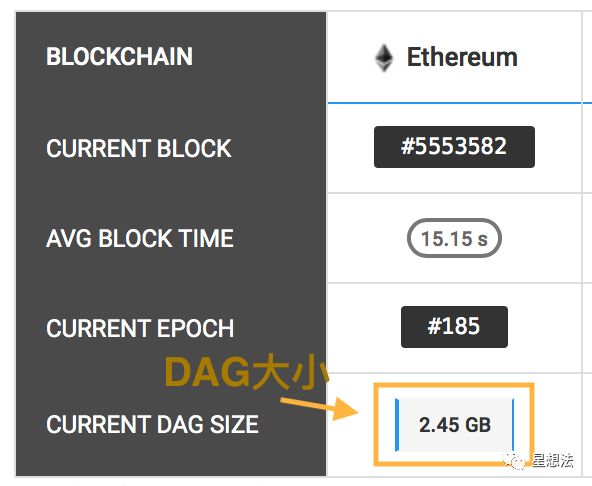
目前以太区块高度5553582,epoch是185,DAG大小是2.45G。
DAG数据的生成逻辑在generateDateset以及generateDatesetItem函数中,逻辑如下图:
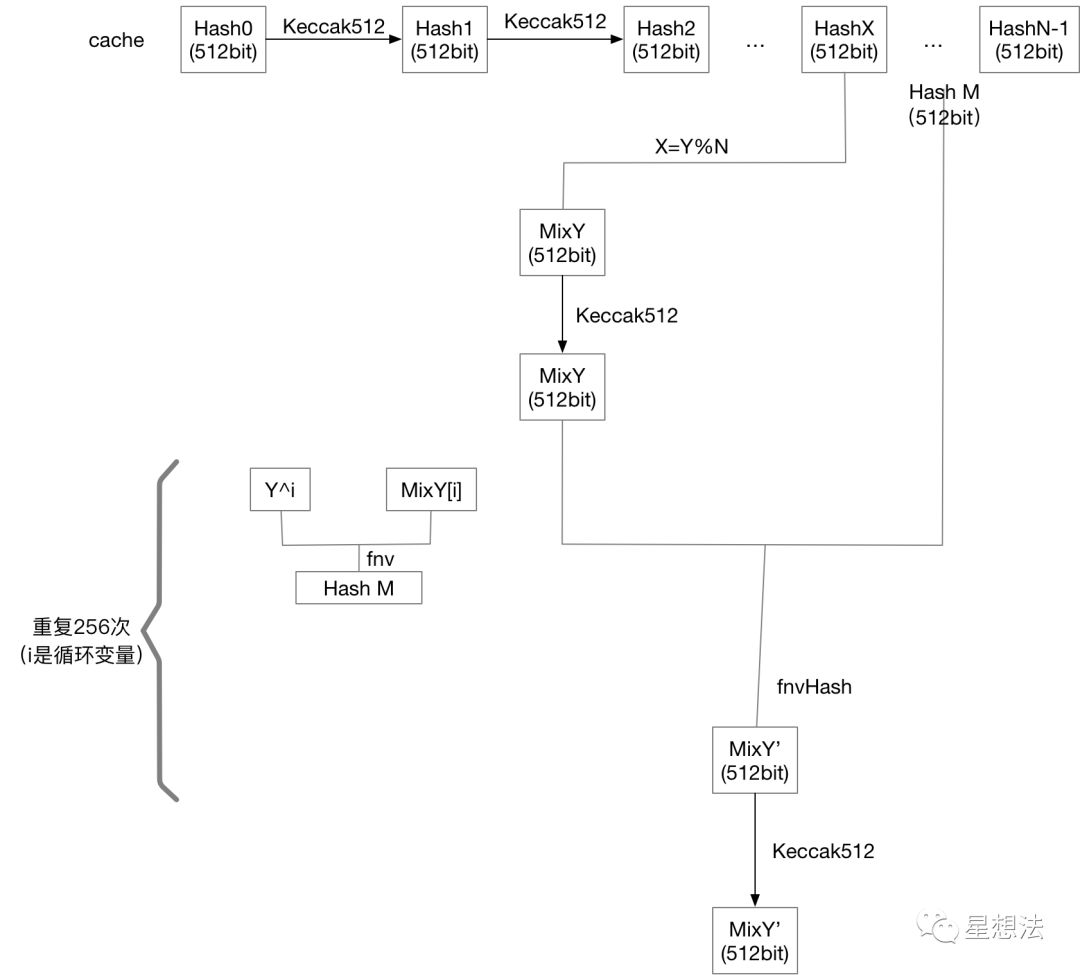
简单的说,每生成一个Mix需要找到256个parent的Hash块,这些块需要做fnvHash叠加。parent的Hash 块的编号和循环变量以及Mix中的内容相关。也就是说,一个Mix依赖256个cache块,逻辑上,Mix的生成像有向无环图,这个也是为什么取名DAG的原因。
3)ethash计算
DAG数据准备好后,给定一个区块头,开始枚举nonce,寻找满足难度的nonce。
计算实现在hashimoto函数中,逻辑如下图:(图片摘自:https://docs.google.com/drawings/d/12yaGlsb5cz7IlWXcwgT6xXympFDVf84C6UrYkqHRipQ/edit)
从已知的Header以及估算的nonce,循环(64次)计算出Mix(128字节)。根据循环编号以及Mix的内容,从DAG中查找对应的数据,生成新的Mix。最后会通过Keccak512生成Mix Digest,如果小于Target难度,该nonce就是需要寻找的nonce值。
很清楚,需要寻找一个64位nonce,计算量很大,只能采用枚举法,从0开始。而且计算的瓶颈在数据访问带宽。然而,验证一个nonce相对简单,因为只需要一次计算。
以上是关于以太坊源代码 - ethash算法介绍的主要内容,如果未能解决你的问题,请参考以下文章