常用分享--HASH算法解析
Posted 程序员地铁时光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用分享--HASH算法解析相关的知识,希望对你有一定的参考价值。
今日主题:hash算法的解析以及MessageDigest的使用
今日内容: 上一篇文章中主要是对一致性HASH算法进行解析,在选择HASH算法的使用,对于hash算法的选择有了很大疑惑,于是便对于所有的hash算法进行了简单的研究,并对提供信息摘要算法的MessageDigest类进行了研究
1.HASH函数介绍
加法HASH
所谓加法hash就是把输入的元素相加,标准的hash构造如下:
/*** 加法HASH** @param key hash的KEY* @param prime 任意质数* @return*/private static int additiveHash(String key, int prime) {int hash, i;for (hash = key.length(), i = 0; i < key.length(); i++) {hash += key.charAt(i);}return (hash % prime);}
该算法的值域为:[0,prime-1]
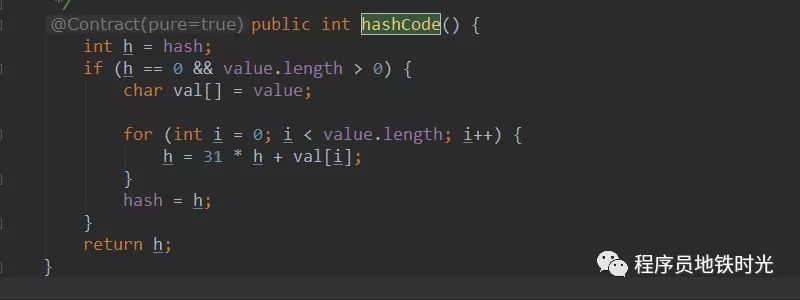
乘法HASH
在JDK 5.0中String类型的hashCode()方法使用了乘法hash如下图,乘数是31,为什么是31呢?
一般在设计哈希算法的时候,会选择一个特殊的质数,是可以降低哈希算法冲突的,31是一个不大不小的质数,是作为 hashCode 乘子的优选质数之一。另外一些相近的质数,比如37、41、43等等,也都是不错的选择。而且31可以被 JVM 优化,31 * i = (i << 5) - i 啥意思呢?即乘法运算可以被移位和减法运算取代
还有一些其他的著名的hash函数:
// 32位FNV算法private static final long OFFSET_BASIS = 2166136261L;// 32位offset basisprivate static final long PRIME = 16777619; // 32位primepublic static long hash(byte[] src) {long hash = OFFSET_BASIS;for (byte b : src) {hash ^= b;hash *= PRIME;}return hash;}//RS_HASHpublic static long RS_Hash(String str) {int a = 63689;int b = 378551;long hash = 0;for (int i = 0; i < str.length(); i++) {hash = hash * a + str.charAt(i);//System.out.println(hash);a = a * b;//System.out.println(a);}return (hash & 0x7FFFFFFF);//32位//return (hash & 0x7FFFFFFFFFFFFFFFL);//64位}
除法Hash
除法和乘法一样,同样具有表面上看起来的不相关性。不过,因为除法太慢,这种方式几乎找不到真正的应用。需要注意的是,我们在前面看到的hash的 结果除以一个prime的目的只是为了保证结果的范围。如果你不需要它限制一个范围的话,可以使用如下的代码替代hash%prime:hash = hash ^ (hash>>10) ^ (hash>>20)
位运算Hash
这类型Hash函数通过利用各种位运算(常见的是移位和异或)来充分的混合输入元素,
标准的旋转Hash的构造如下:
public static int rotatingHash(String key, int prime) {int hash, i;for (hash = key.length(), i = 0; i < key.length(); ++i) {hash = (hash << 4) ^ (hash >> 28) ^ key.charAt(i);}return (hash % prime);}
先移位,然后再进行各种位运算是这种类型Hash函数的主要特点。比如,以上的那段计算hash的代码还可以有如下几种变形
1.hash = (hash<27)^key.charAt(i);2.hash += key.charAt(i);hash += (hash << 10);hash ^= (hash >> 6);3. if((i&1) == 0){hash ^= (hash<3);}else{hash ^= ~((hash<5));}4. hash += (hash<<5) + key.charAt(i);5. hash = key.charAt(i) + (hash<16) – hash;6. hash ^= ((hash<2));
查表HASH
查表Hash最有名的例子莫过于CRC系列算法。虽然CRC系列算法本身并不是查表,但是,查表是它的一种最快的实现方式。查表Hash中有名的例子有:Universal Hashing和Zobrist Hashing。他们的表格都是随机生成的。
混合HASH
混合Hash算法利用了以上各种方式。各种常见的Hash算法,比如MD5、Tiger都属于这个范围。它们一般很少在面向查找的Hash函数里面使用
2.MessageDigest来实现数据加密
MessageDigest 类为应用程序提供信息摘要算法的功能,如 MD5 或 SHA 算法。信息摘要是安全的单向哈希函数,它接收任意大小的数据,输出固定长度的哈希值
MessageDigest 对象开始被初始化。该对象通过使用update方法处理数据。任何时候都可以调用reset 方法重置摘要。一旦所有需要更新的数据都已经被更新了,应该调用 digest 方法之一完成哈希计算。
对于给定数量的更新数据,digest 方法只能被调用一次digest 被调用后,MessageDigest 对象被重新设置成其初始状态。
/*** @Author smile7up* @createDate 2019-0905* @Description MessageDigest测试工具类*/public class MessageDigestTest {public static void main(String[] args) throws NoSuchAlgorithmException {System.out.println(getMd5("1"));}/*** 通过md5进行加密* @param source 要加密的数据* @return* @throws NoSuchAlgorithmException*/private static String getMd5(String source) throws NoSuchAlgorithmException {//1.获取MessageDigest对象MessageDigest digest = MessageDigest.getInstance("md5");//2.执行加密操作byte[] bytes = source.getBytes();//在MD5算法这,得到的目标字节数组的特点:长度固定为16byte[] targetBytes = digest.digest(bytes);//3.声明字符数组char [] characters = new char[]{'0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F'};//4.遍历targetBytesStringBuilder builder = new StringBuilder();for (byte b : targetBytes) {//5.取出b的高四位的值//先把高四位通过右移操作拽到低四位int high = (b >> 4) & 15;//6.取出b的低四位的值int low = b & 15;//7.以high为下标从characters中取出对应的十六进制字符char highChar = characters[high];//8.以low为下标从characters中取出对应的十六进制字符char lowChar = characters[low];builder.append(highChar).append(lowChar);}return builder.toString();}}
运行结果为:
另附上即将使用的一致性hash算法的hash算法事例
/*** @Author smile7up* @createDate 2019-0905* @Description hash算法*/public class HashFunction {/*** 新建*/private MessageDigest md5 = null;public long hash(String key) {if (md5 == null) {try {md5 = MessageDigest.getInstance("MD5");} catch (NoSuchAlgorithmException e) {throw new IllegalStateException("no md5 algrithm found");}}md5.reset();md5.update(key.getBytes());byte[] bKey = md5.digest();//具体的哈希函数实现细节--每个字节 & 0xFF 再移位long result = ((long) (bKey[3] & 0xFF) << 24)| ((long) (bKey[2] & 0xFF) << 16| ((long) (bKey[1] & 0xFF) << 8) | (long) (bKey[0] & 0xFF));return result & 0xffffffffL;}}
本篇文章中主要是对于hash函数进行了简单的介绍,常用的六种hash函数构成了各种hash算法,下一篇文章,主要会对一致性hash算法的实现做分享
以上是关于常用分享--HASH算法解析的主要内容,如果未能解决你的问题,请参考以下文章