基于GeoHash算法的地理位置检索
Posted 录信数软
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于GeoHash算法的地理位置检索相关的知识,希望对你有一定的参考价值。
认识GeoHash
GeoHash算法本质上是空间索引的一种方式。我们可以将整个地球设想为一个二维平面,将地球上所有区域展开平铺之后通过递归分解将该平面切分为32个模块。之后再将其中的模块再进行分块,随着范围不断缩小,位置精度也越来越高。每个分块都由一定的标识来表示该块。而地球上所有经纬度坐标都会通过GeoHash算法转变为一个唯一的base32标识,该标识对应上述分块的标识,一层一层的确定分块位置,最终便可通过标识找到具体的地理位置。
首先贴出base32编码表:

GeoHash算法
1)区间[-90,0),[0,90],39.928167在右区间内,取1;
2)区间 [0,45),[45,90],39.928167在左区间内,取0;
3)区间 [0,22.5),[22.5,45],39.928167在右区间内,取1;
4)不断递归进行二分拆解,慢慢缩小范围(最多缩小13次)...
5)最终纬度编码为1 1 0 1 0 0 1 0 1 1 0 0 0 1 0;
对经度116.389550做上述操作,可得经度编码1 0 1 1 1 0 0 0 1 1 0 0 0 1 1。
得到经纬度的二进制位后需要对其进行合并。奇数位取纬度,偶数位取经度,每次取其二进制位的一位(不足为取0),最终合并成一个新的二进制串:
11100 11101 00100 01111 0000 01101
每5位为一个10进制数,换算过来为28、29、4、15,0,13。通过换算过来的5个十进制数便可对照上面的base32表得到该经纬度对应的encode标识:wx4g0e。将标识编码转换为经纬度的decode算法与之相反。
经过以上过程,便可将一长串经纬度数据简化为一段短小的url标识——wx4g0e。
在得到标识之后,便可以只通过标识在地图上寻找对应的具体位置了。首先现在已分好的板块中找到W。找到W块后,再将W块进行分块,从子块之中找到X块。随后继续将X块细分,从X块的子块中找到4块。以此类推...随着不断地细分,直至找到wx4g0e对应的子块。
GeoHash优势
GeoHash缺陷
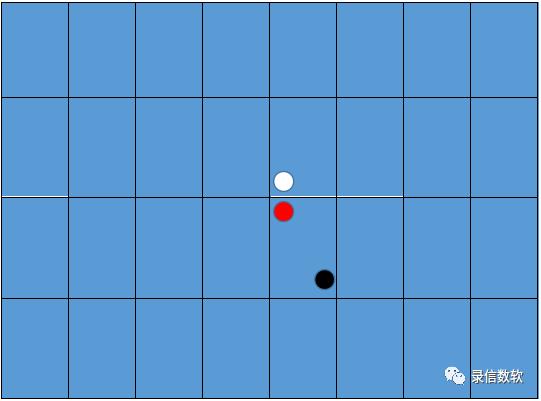
Morton码替代
Morton码可以将多维数据转化为一维数据编码,根据一维编码位数可确定多维数据保留精度,是一种比较常用的压缩编码方法,尤其是作为哈希表的映射算法等,加速了树结构数据的存储和访问速度。
Morton编码也叫z-order code ,因为其编码顺序按照空间z序,编码结果展现为一种Z形的填充曲线。
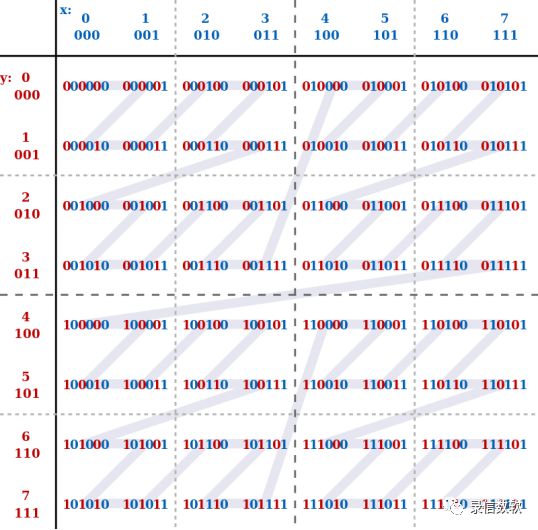
MortonGeo地理位置检索
同理,反之也可通过一个Morton编码反算出对应的一组经纬度坐标。
LSQL的这种做法和上述的GeoHash算法思想类似,都是通过对一组长经纬度坐标进行转化,转化为一个较短的编码标识。通过对该编码标识创建索引,可以极大的加快查询的性能。后续可以用于距离计算,轨迹匹配,区域碰撞等功能。但在实现原理上又与GeoHash存在本质上的不同。GeoHash通过对地球区域的分块,实现了经纬度坐标和geohash编码标识的对应,易受到地球不规则性和纬度梯度变化的影响;而LSQL的Morton编码仅仅只需通过经纬度坐标mortonhash为morton值,不受上述影响。
使用样例
下面介绍一些LSQL基于morton的地理位置检索功能的使用语法样例:
1.建表语法:
create table geopoint_example(lon y_tdouble_id,lat y_tdouble_id,geodata y_geopoint_idm);
2.数据导入:
insert into table s_y_s_t_loadjsonselect 'geopoint_example', 'xxx', '',CL_JSON('lon',LON,'lat',LAT,'geodata',concat(LON,',',LAT))from (select * from geopoint) tmp;
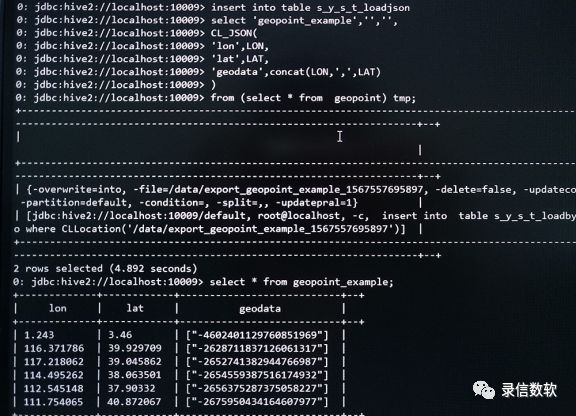
除此之外还有一些常用函数的用法,可以很方便的用于地理位置计算:
3.必备函数:
CL_GEO_DISTANCE(tmp.geodata,6.1,8.3) as distance //计算两点之间的距离CL_GEO_UNHASH(tmp.geodata ) //用于将morton值解析出经纬度CL_GEO_HASH(lon,lat) //用于将经纬度数据解析成morton值
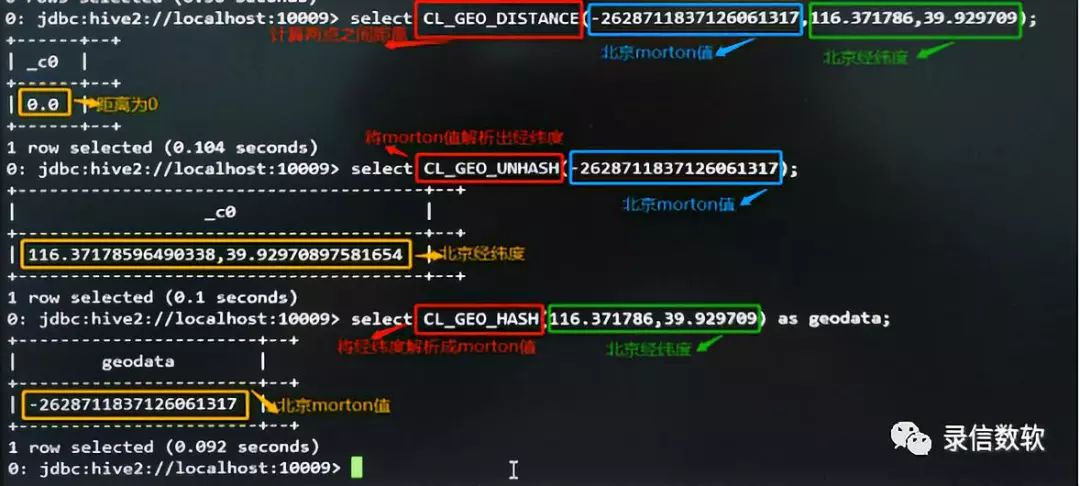
由上述操作过程可了解到其使用的快捷简便。尤其是基于Morton的算法弥补了GeoHash的缺陷,还和后者拥有同样的高性能,在业内solr、ES都采用GeoHash方式的情况下是一个极大的改进。
研发方向
由于LSQL基于lucene研发,自然也同原生lucene一样支持一个列存储多个值,即多值列。多值列里一般用来存储一系列同类标签信息。说到这里可能会有些小伙伴不了解多值列,多值列具体是什么呢?假设在用户画像场景下,数据里的一条记录代表一个人,里面存储了这个人的一系列行为信息,某一个多值列字段[北京 上海 杭州]就正好就可以存储这个人去旅游过的城市,多值列实现了用一个字段来存储包含多个值的属性。
但是假设某一记录存在多个多值列字段,该记录所描述的人有如下行为:在7月,北京,看球赛;在8月,上海,看电影。这两条行为就需要三个多值列[7月 8月]、[北京 上海]、[看球赛 看电影]来存储。但开源lucene能真正做到将这三个多值列关联,使多值列中存储的“7月” “北京” “看球赛”获得关联吗?答案是不能的。开源lucene目前并未实现识别多值列的之间的关联。而这也正是录信数据库LSQL后续的研发方向之一,旨在建立多值列之间的关联,实现基于多值列的在高维数据搜索与碰撞功能,以满足更高性能的数据检索和碰撞分析。
LSQL本身支持多列联合索引,正好可以将这种多列联合索引应用在多值列里,通过多列联合索引建立多个不同多值列之间的联系,并保存这种关联关系。在实现了这点之后,就可以通过多个多值列中的单个值之间的组合进行检索了,如“9月9日,在南京,吃盐水鸭”的用户。即便是“9月9日” “南京” “吃盐水鸭”这三个值存储在三个不同的多值列里,我们也能通过它们彼此之间的联系将其组合检索,最终获取到我们想要的信息。
创建多值列之间的关联的应用可不仅于此,在不同的场景下能完成不同的应用需求。如本文所探讨的地理位置检索场景。若想在该场景下进行轨迹匹配,默认的lucene只支持经纬度匹配,无法满足轨迹匹配需求。但若借助上面提到的建立多值列之前的关联,就很容易实现精准的轨迹匹配了。
一个物体的运动轨迹总是由一系列经纬度点组成,在这条轨迹上的点总是具有各自运动到该点的即刻时间和先后顺序、该点的运动方向。于是对于这三种属性,便可以用三个多值列字段来存储。一个多值列用来存储经纬度点经过mortonhash之后的morton值,一个用来存储时间先后顺序,一个用来存储运动轨迹方向。利用LSQL多列联合索引,建立这三个多值列之间的关联,实现带有运动时间先后与方向的多维度的轨迹匹配功能。不仅可以进行本文中提到的地理位置快速检索过滤,结合morton值和时间还方便进行大范围range扫描,运动的点位、时间顺序、运动方向三者结合就可以进行精确的多维轨迹匹配了。
基于多值列的在高维数据搜索与碰撞功能和带有运动时间先后与方向的多维度的轨迹匹配功能我们仍在探索,LSQL的研发之路未来可期。
以上是关于基于GeoHash算法的地理位置检索的主要内容,如果未能解决你的问题,请参考以下文章