从零代码爬虫到python函数式编程,不变的竟然是……
Posted 数据团学社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零代码爬虫到python函数式编程,不变的竟然是……相关的知识,希望对你有一定的参考价值。
本文约2500字,阅读需要6分钟
关键词:火车采集器 Python 函数式编程
本文为数据分析师(python)微专业学员作品~适合正在学习Python爬虫的朋友,也适合不会编程的朋友学习使用零编程爬虫神器和了解爬虫工作流
p.s.文末有逐行注释的文中示例代码文件分享~
老板最近打算添置一套“豪宅”。为了能够获取海量的房源信息,筛选出最佳选择,老板参加了。在课程老师风趣幽默,深入浅出的讲解之下,掌握了一款名为“火车采集器”的强大工具。今天,特地来向我显摆——
“你知道吗,现在有一款叫火车采集器的软件,很强力的呦,点点鼠标,就能搞到大量数据!你行吗?”
!!我竟然被老板怀疑技术能力了!今天无论如何都得秀一波! 
下面,让我来彻底揭下火车采集器神秘的面纱,还原其背后的逻辑。
先看老板的需求——
我:“老板,听说你要选购‘豪宅’”。
老板:“那是!不过我要求不高,内环以内,150平米以上就行了。预算嘛...这两年省吃俭用,存了500W。”
得到要求,我先打开某售房网站,以500W以内,150平米以上为基准,筛选出房源:
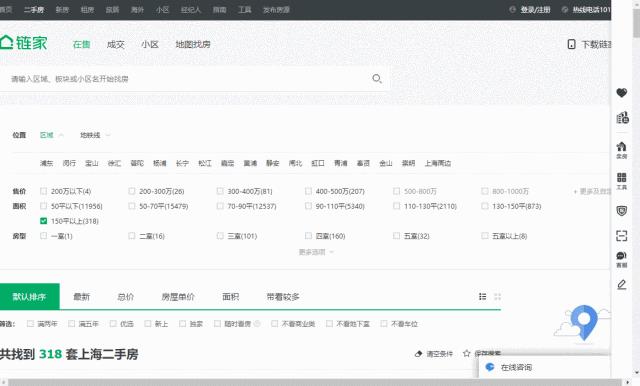
还是不少的!当需要采集的数据量比较大的时候,使用爬虫能大大提高工作效率~先看看不用写代码的火车采集器吧——
火车采集器的工作流程
1、新建任务
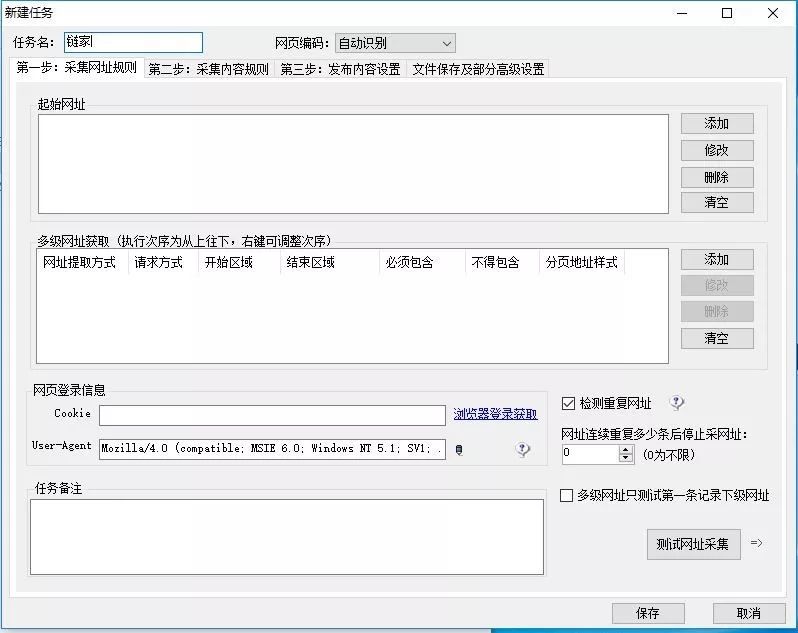
2、对特征网址,以页码为变量,设定爬取范围
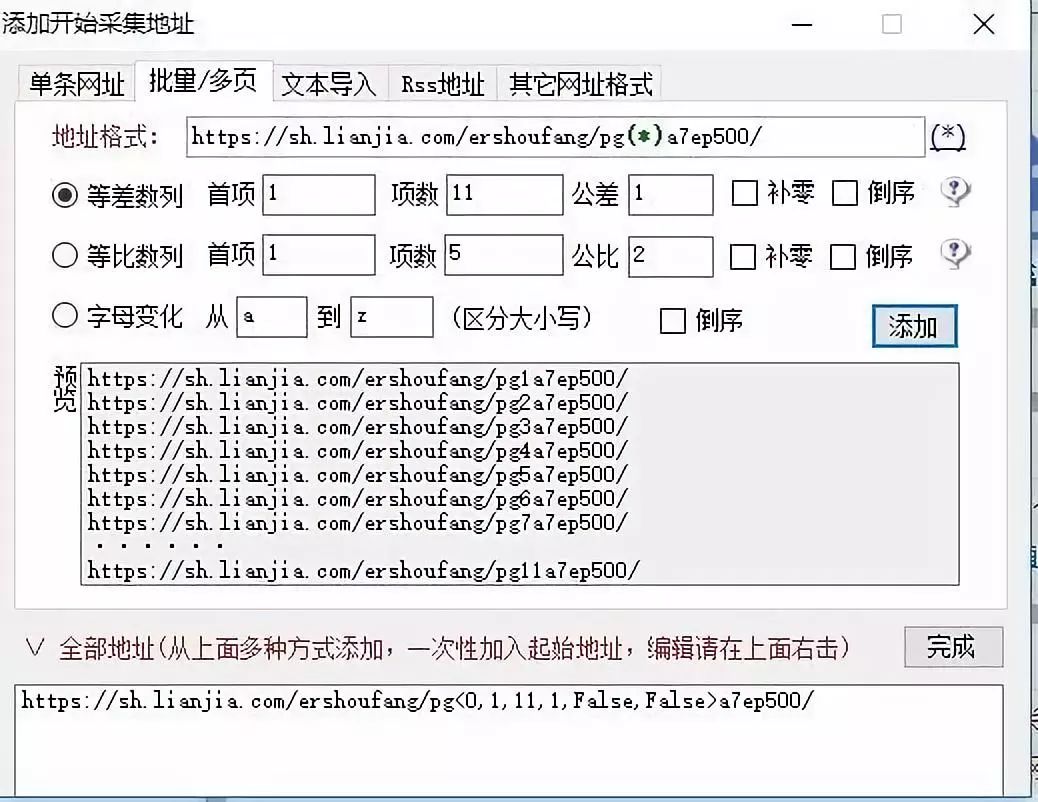
3、以同样的套路,从一级网址中,获取二级网址
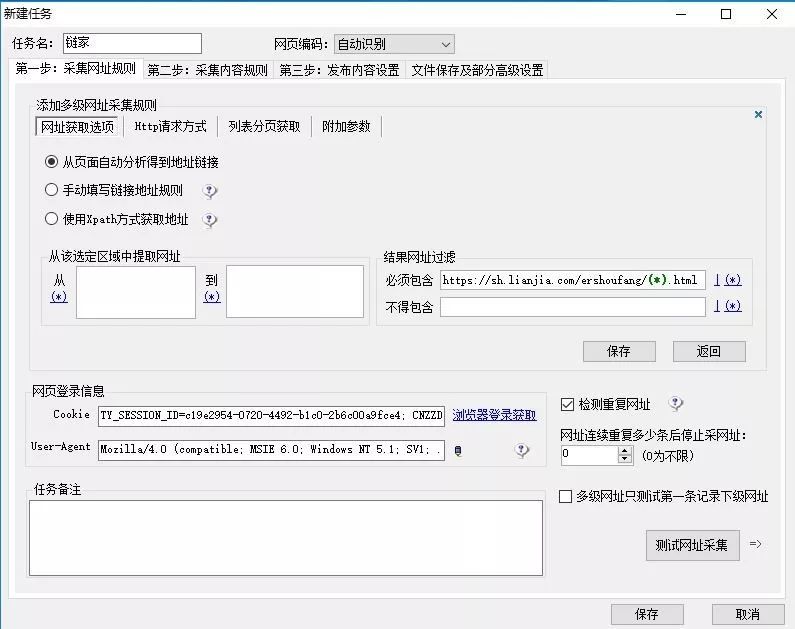
4、对二级网址中所需获取的数据,根据html标签进行前后截取
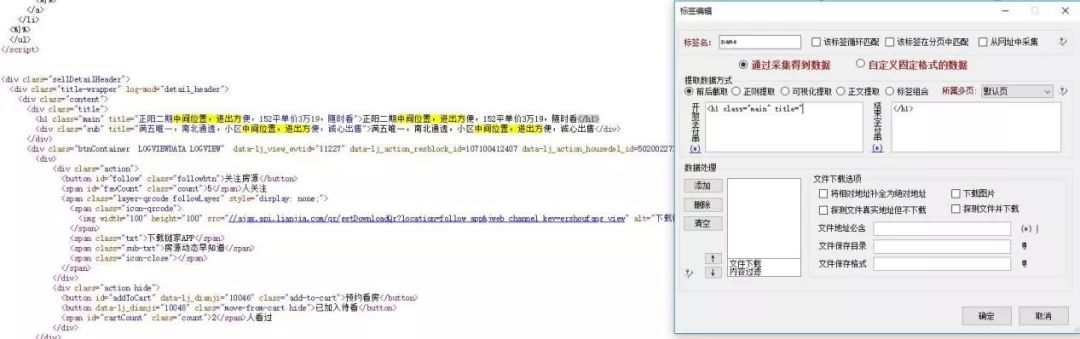
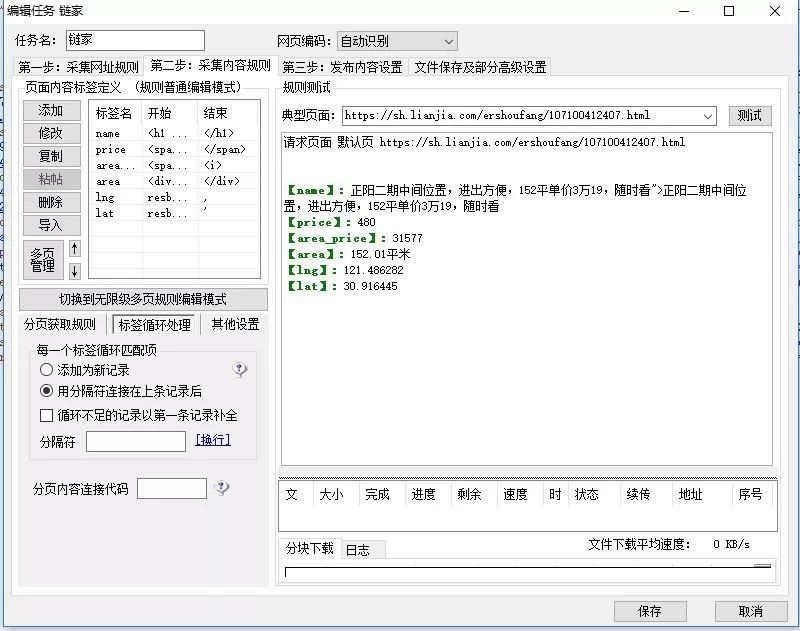
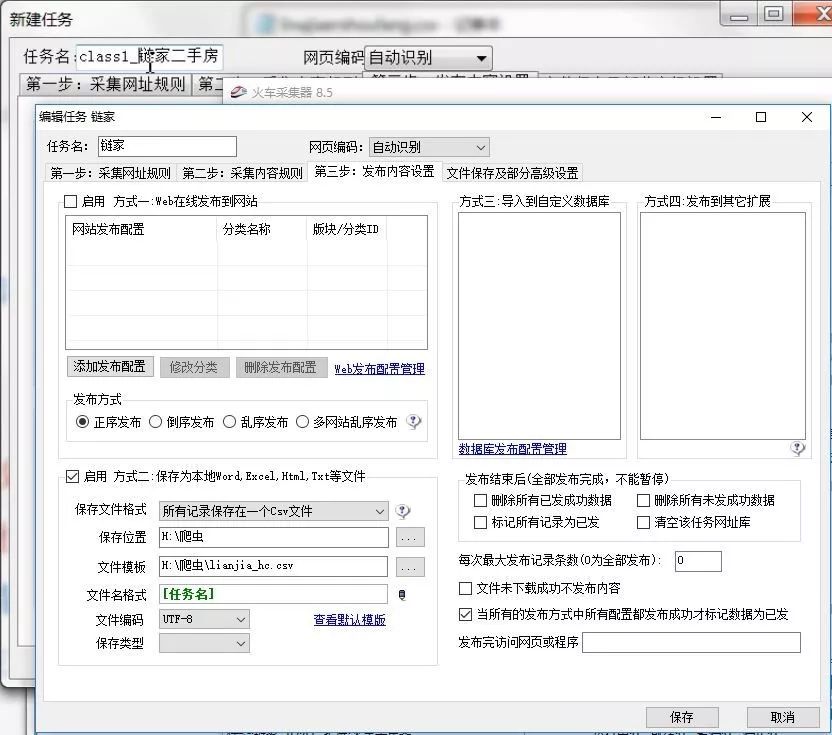
5、运用采集器的模板设置,导出数据的字段和格式

6、开始任务,成功爬取数据
哇!好厉害!看到这里,许多小伙伴都惊呆了,不禁感叹世上竟然有如此神器!
其实非也,支撑起这看似酷炫的操作和吊炸天功能的是一套最基本的爬虫逻辑:

我们称之为“爬虫工作流”。
程序语言爬取房源信息
既然老板刚学会的火车采集器这么厉害,我当然不能示弱~接下来,学习了火车头的“爬虫工作流”的我,将用Python重新演绎房源信息爬取的全过程(文末有含注释的源代码获取方式~~)。
1、打开代码编辑器,导入四个用于爬虫的库
import requests
from bs4 import BeautifulSoup
import time
import csv
分别是网页库,爬虫库,时间模块,CSV操作库。这四个库代表了组成一个完整的爬虫工程所需要的四大组件,我把其总结为“4C”模型。
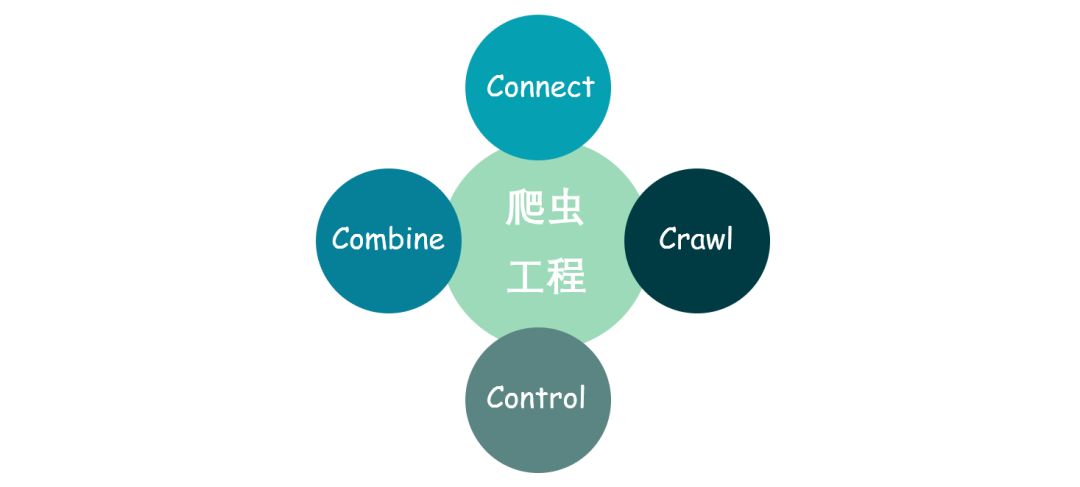
Connect:连接组件,用于通过HTTP协议,与站点进行连接。
Crawl:爬虫组件,用于抓取页面中所需要获取的具体信息。
Control:控制组件,用于对工程进行控制,包括工程的进度,效率,异常处理等。
Combine:联合组件,用于整合爬取的信息,做最终的处理。
2、代码编辑环节
设计流程化、套路化工作,推荐使用函数式编程
总共两个函数的编程思路如下:
def get_url(start_num,end_num):
url_list = []
headers={ 'UserAgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
url_page = ['https://sh.lianjia.com/ershoufang/pg{}a7ep500/'.format(num) for num in range(start_num,end_num+1)]
for page in url_page:
n+=1
print('正在抓取第{}页链接'.format(n))
time.sleep(2)
page_data = requests.get(page,headers=headers)
soup = BeautifulSoup(page_data.text,'lxml')
urls = soup.select('body > div.content > div.leftContent > ul > li > div.info.clear > div.title > a')
for u in urls:
url_list.append(u.get('href'))
return url_list
i. 为了模拟真实用户的网页请求,防止被站点反爬,我们先设定一个请求头。这里在游览器中按F12,打开后台,选择Network,然后刷新网页,我们就可以截取到Request Headers信息了。此处,我只添加了User-Agent参数,当然,我们也可以尝试继续添加其他参数,如cookie之类。
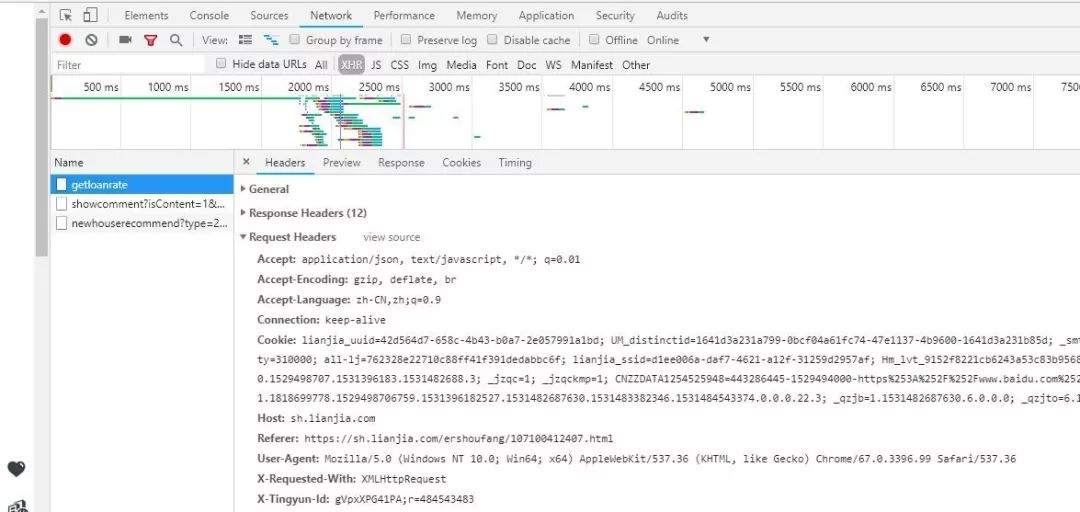
headers={ 'UserAgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
ii. 参照火车采集器的套路,我们需要根据特征网址,构建出所有需要爬取的一级网址。于是,我构造了一个列表解析式。在网址页码部分设置一个等差数列,从而获取到所有网址。这和火车采集器的做法,完全相同。
url_page = ['https://sh.lianjia.com/ershoufang/pg{}a7ep500/'.format(num) for num in range(start_num,end_num+1)]
iii. 遍历每个一级网址,爬取二级网址。这里使用requests库的get方法访问网页。
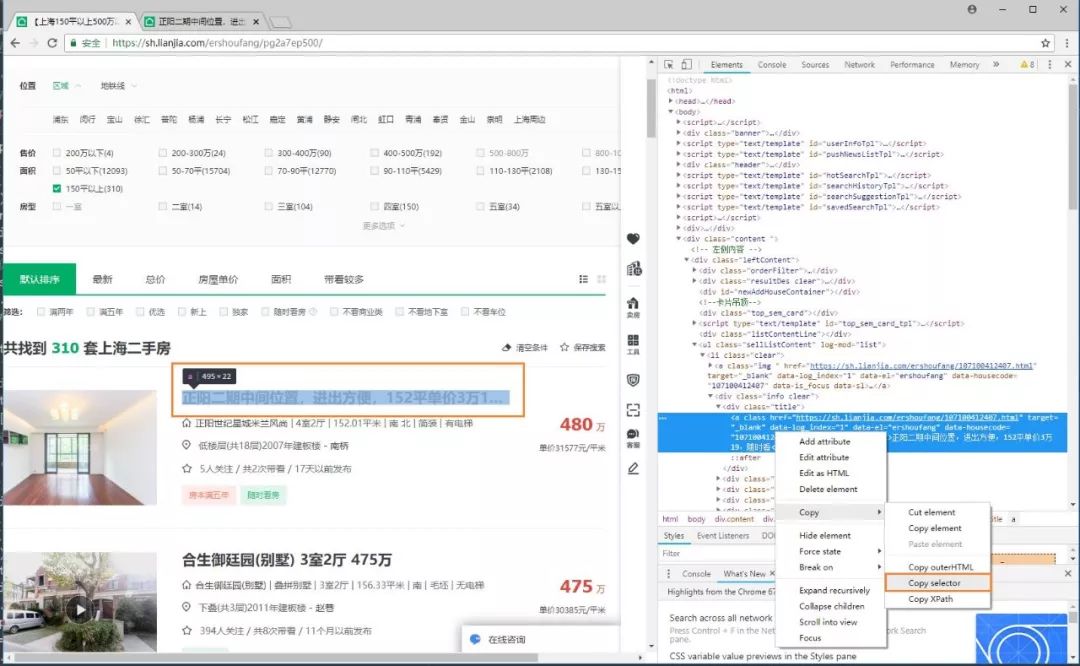
page_data = requests.get(page,headers=headers)
soup = BeautifulSoup(page_data.text,'lxml')
urls = soup.select('body > div.content > div.leftContent > ul > li > div.info.clear > div.title > a')
v. 最后,提取url存入列表中,待用。
for u in urls:
url_list.append(u.get('href'))
return url_list
第一个函数就设计完毕了!看吧,还是挺简单的!
之后,我们进入第二个函数设计。方法类似~
2.2 建立第二个函数,用于爬取二级页面中所需信息
def craw_inf(url_list):
file = open('./lianjia_python.csv','a+',encoding='gbk')
writer = csv.writer(file)
writer.writerow(['name','price','area_price','area','lng','lat'])
inf_all = []
headers={ 'UserAgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
n = 0
for url in url_list:
n+=1
print('正在抓取第{}个房源'.format(n))
time.sleep(3)
web = requests.get(url,headers=headers)
soup = BeautifulSoup(web.text,'lxml')
namel = soup.select('body > div.sellDetailHeader > div > div > div.title > h1')
pricel = soup.select('body > div.overview > div.content > div.price > span.total')
area_pricel = soup.select('body > div.overview > div.content > div.price > div.text > div.unitPrice > span')
areal = soup.select('body > div.overview > div.content > div.houseInfo > div.area > div.mainInfo')
lng = soup.get_text().split("resblockPosition:'")[1].split(',')[0]
lat = soup.get_text().split("resblockPosition:'")[1].split(',')[1].split("'")[0]
for name,price,area_price,area in zip(namel,pricel,area_pricel,areal):
data_list = [name.get_text(),price.get_text(),area_price.get_text(),area.get_text(),lng,lat]
inf_all.append(data_list)
file = open('./lianjia_python.csv','a+',encoding='gbk')
writer = csv.writer(file) for row in inf_all:
writer.writerow(row)
inf_all = []
i. 首先,我们先创建一个工作表,设置好表头,用于接下来存放爬取的信息。话说,上回我们尝试了pandas对于数据存储的方法,其实,python中处理类似问题的方法有很多,这回我们试着用CSV库去解决这个问题。
file = open('./lianjia_python.csv','a+',encoding='gbk')
writer = csv.writer(file)
writer.writerow(['name','price','area_price','area','lng','lat'])
inf_all = []
ii. 然后,重复同样的套路,使用Selector选择器,定位内容。
for url in url_list: n+=1 print('正在抓取第{}个房源'.format(n)) time.sleep(3) web = requests.get(url,headers=headers) soup = BeautifulSoup(web.text,'lxml') namel = soup.select('body > div.sellDetailHeader > div > div > div.title > h1') pricel = soup.select('body > div.overview > div.content > div.price > span.total') area_pricel = soup.select('body > div.overview > div.content > div.price > div.text > div.unitPrice > span') areal = soup.select('body > div.overview > div.content > div.houseInfo > div.area > div.mainInfo')
iii. 这里再提一下经纬度的获取,因为经纬度并不在标签中,而处于页面JS代码部分,我们这里仿照火车采集器的方法,对于文本进行前后截取,同样也能得到想要的结果。

lng = soup.get_text().split("resblockPosition:'")[1].split(',')[0]
lat = soup.get_text().split("resblockPosition:'")[1].split(',')[1].split("'")[0]
iv. 最后,提取具体内容,写入工作表中。
for name,price,area_price,area in zip(namel,pricel,area_pricel,areal): data_list = [name.get_text(),price.get_text(),area_price.get_text(),area.get_text(),lng,lat] inf_all.append(data_list) file = open('./lianjia_python.csv','a+',encoding='gbk') writer = csv.writer(file) for row in inf_all: writer.writerow(row) inf_all = []
v. 两个函数均编写完毕,我们对函数进行整合
def main():
url_list = get_url(1,11)
craw_inf(url_list)
if __name__ == '__main__':
main()
好了,整个工程设计完成,激动人心的时候终于到了!我怀着虔诚的心情,按下了F5,运行代码!
看!是不是和火车采集器很像啊!
哦~~这里再提一句,为了控制爬虫的频率,防着被封IP,我设定了较长的爬虫间隔时间,想要提高效率可以更改time.sleep()中的参数,数字单位为“秒”。

经历了为时不多的等待,所有数据均采集完毕了,让我们看看结果!
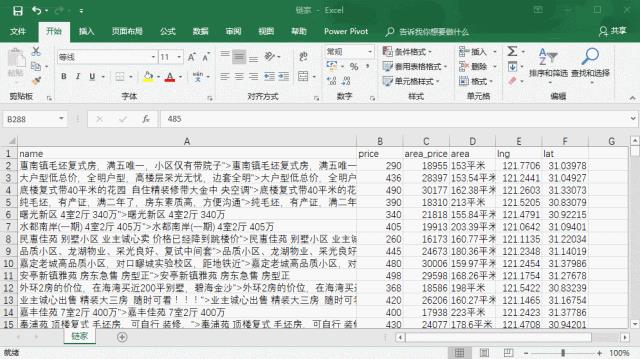
棒不棒!如果你也想要添置“豪宅”,它将是你不二的选择!(完整代码和注释请看文末福利!)
代码优化和学习建议
对于数据写入部分,最好还是再建立一个函数,待数据采集完成后一次性写入,这样效率更高,更能体现“4C模型”的真谛,但是考虑到爬虫过程中可能发生的意外,从而导致前功尽弃,又不想加入太多代码,这里采取爬一条存一条的策略。
如果采集的数据量比较大,建议使用数据库,运用SQL在数据库中做最后的数据筛选和提取,这能大大提高整理数据的效率和灵活性。像火车采集器,对于采集后的数据,其实先是存入自带的sqllite关系型数据库中的。
CSV库对于Windows系统支持上总会有一点小问题,所以,建议大家使用pandas中的方法对数据进行存储,或者买一台苹果电脑。
结果呈现
数据统统采集下来了,好人做到底,我来给老板先看看,有没有符合要求的房源。我把房源根据经纬度放入地图中,同时,根据上海市中心点,画了一个半径为10公里的圈,大致模拟内环范围。
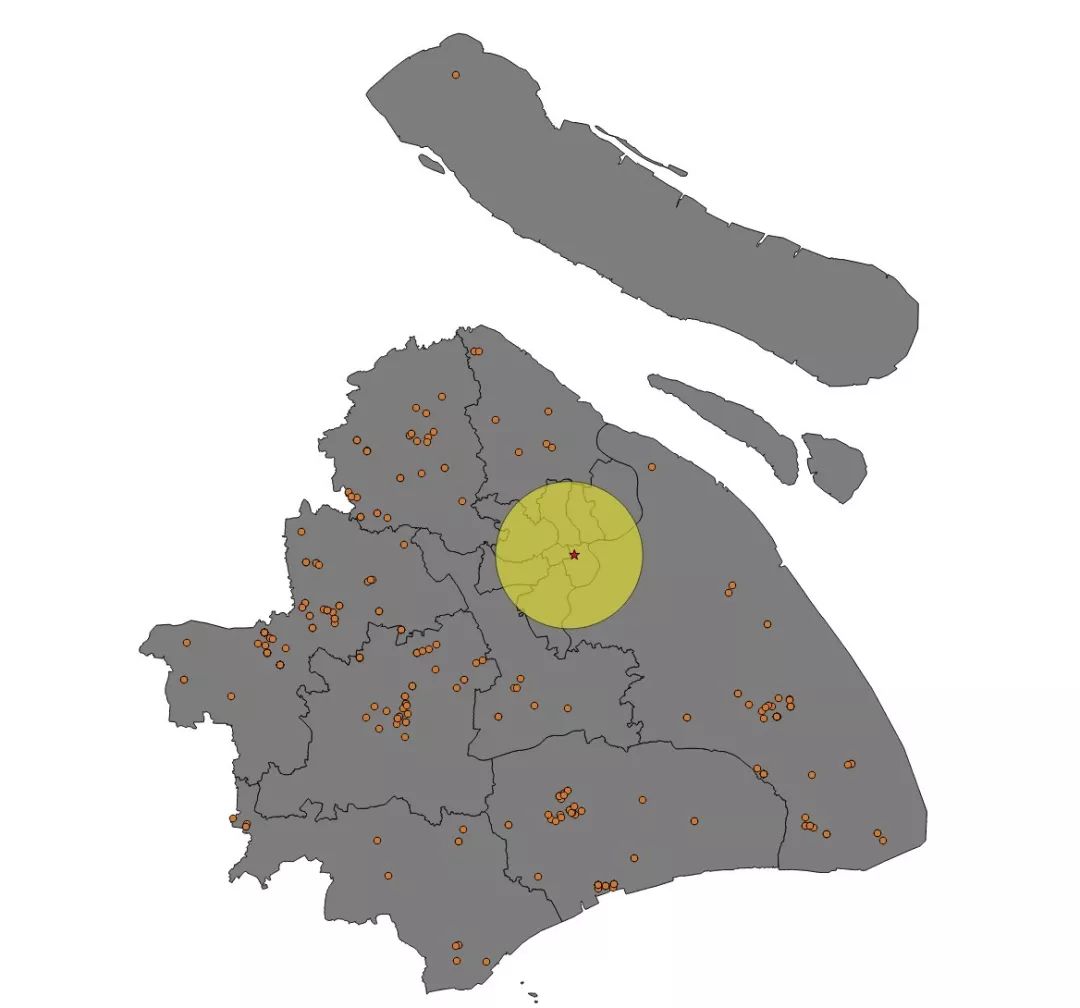
结果真的是……如此毫无悬念,我一定要把这个振奋人心的结论告诉老板,她一定会高兴的!
老板足足看了一分钟——
“嗯!分析得相当靠谱,鉴于你卓越的工作能力,我决定奖励奖励!”
“好呀好呀!”(我揣摩着老板到底会奖励什么?升职?加薪?共进晚餐?)
“加班!!! ”

这个故事告诉我们三个道理:
1、面对一些看似牛X的东西,不要畏惧尝试,其实,并没有想象的那么困难,那么高不可攀。学习亦如此。
2、华丽的外表形形色色,背后的套路如出一辙。我们要善于发现事物背后的共同点,形成解决问题的工作流,这样才能事半功倍。
3、生命中有许多可望而不可即的东西,比如,哪怕你拥有500万,也买不起一套“豪宅”,努力工作才是生活的常态。
关注“数据团学社”
并在后台回复【08】
即可免费获取火车采集器安装包和逐行注释的文中示例代码~
了解数据分析师(python)微专业,请点击文末蓝字“阅读原文”~
以上是关于从零代码爬虫到python函数式编程,不变的竟然是……的主要内容,如果未能解决你的问题,请参考以下文章