虎牙直播张波:掘金Nginx日志 | OpenResty × Open Talk 全国巡回沙龙深圳站
Posted 又拍云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了虎牙直播张波:掘金Nginx日志 | OpenResty × Open Talk 全国巡回沙龙深圳站相关的知识,希望对你有一定的参考价值。
2019 年 1 月 12 日,由又拍云、OpenResty 中国社区主办的 OpenResty × Open Talk 全国巡回沙龙·深圳站圆满结束,虎牙直播运维研发架构师张波在活动上做了《 掘金nginx日志 》的分享。
OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起的,为促进 OpenResty 在技术圈的发展,增进 OpenResty 使用者的交流与学习的系列活动,活动将会陆续在深圳、北京、上海、广州、杭州、成都、武汉等地举办,欢迎大家关注。

张波,虎牙直播运维研发架构师,目前主要负责虎牙直播运维体系的建设,主要针对 Web 和后台类程序的发布、监控、运维自动化相关的运维系统设计和开发。
以下是分享全文:
大家好!我是来自虎牙直播技术保障部的张波。今天主要会从数据挖掘层面跟大家探讨一下 Nginx 的价值。OpenResty 在虎牙的应用场景主要 WAF 和流控等方面,我今天主要分享的是“ Nginx 日志”,因为这在虎牙产生过巨大的价值,简单来说,我们最终做到的效果就是每年节省数百上千万的成本。
Nginx 是现在最流行的负载均衡和反向代理服务器之一,仅 Nginx 每天就会产生上百 M 甚至数十 G 的日志文件。但又有多少人关注过它背后的价值呢?
常见故障处理场景
举个经典的 CDN 故障处理场景:
用户报障页面访问不了
开发上系统运行一切正常
开发向运维要求提供系统原始日志帮忙定位问题
运维联系 CDN 运营商排查问题
等待 CDN 厂商解决问题
这里举个简单的例子:通常一个 Web 的故障,用户报障页面访问不了,那么开发会上系统去查看监控数据,得到的结论可能是“我负责的系统没问题”。然后会要求运维去介入,比如通过原始日志帮他定位,但运维可能依然得出一个结论“我这边还是没有问题”,即服务端也没有问题。但是用户报障了,肯定存在问题,那这种问题怎么继续排查下去呢?接下来,运维要去联系 CDN 厂商,一起协助去定位问题,最后等待 CDN 厂商解决。
这个流程中,客服联系到开发可能需要 30 分钟,开发再联系运维可能要 15 分钟,这还不包含过程定位问题需要的时间。尤其是在最后一个环节,还要联系 CDN 厂商,这可能已经跨公司沟通了,这样处理下来最少需要 5 个小时,才能找到问题的真实原因,但是你的业务是否可以承担 5 个小时的等待?
今天主要跟大家探讨一下,这类问题是否有更好的解决方案,当然也不是在所有的场景下都适合,但是大部分场景通过这些解决方法是可以做到分钟级定位根因的。
业务故障常用参数

这是一个普通的 Nginx 日志,有用户 IP、来源 IP,后端 stream IP、请求时间、状态码等信息。

这是 CDN 侧的日志信息,相比于 Nginx 日志格式,它会多几个信息,例如边缘节点IP、缓冲命中率,以及 CDN 厂商类型的一些字段,总体它跟 Nginx 字段是类似的。
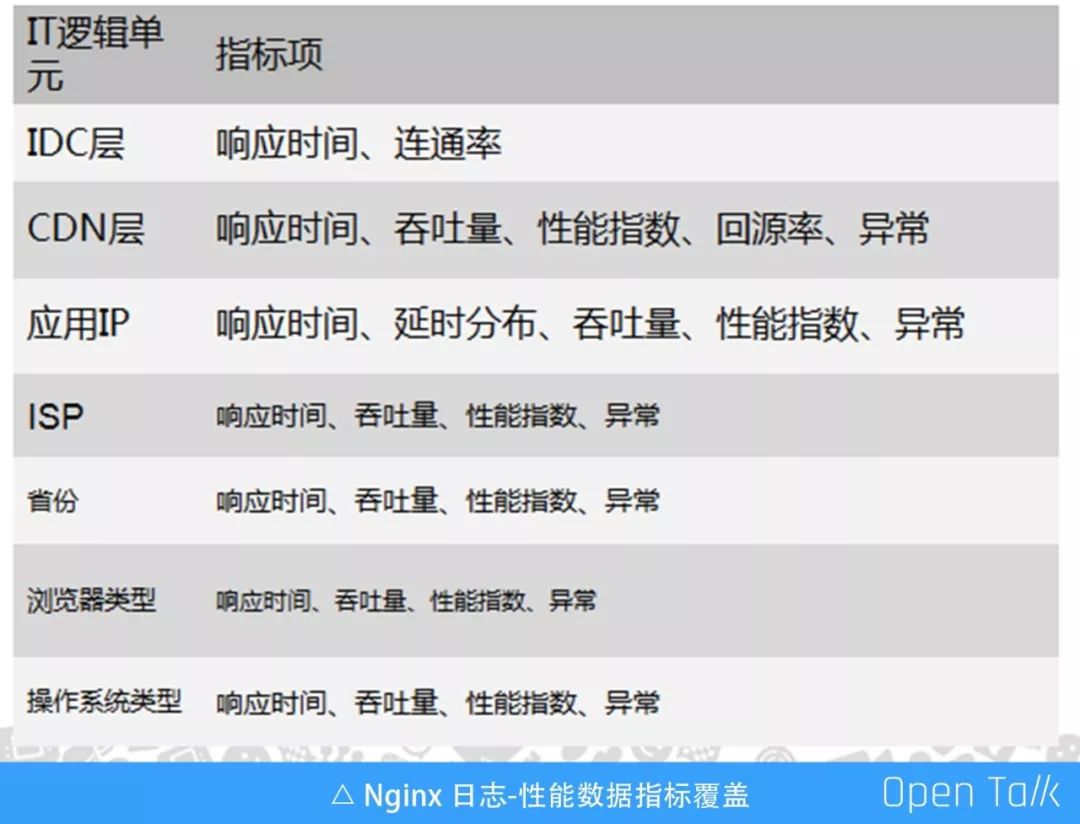
每一层关心的指标有细微差异,但基本上差不多。通过这些指数,做成一个故障定位页面,可以在各层实现快速定位。你可以定位到故障是发生在 IDC 层、CDN 层或者应用层。如果用一个页面把收集的数据统一展示,即便是客服也可以快速定位到故障原因以及产生在哪里。
这就是刚才说的 5 个小时,实际上可能可以缩减到分钟级别。比如已经定位到是某个 CDN 厂商有问题,运维可以直接把这个 CDN 的厂商的流量切走,就可以使业务恢复了。
remote_addr
通过 remote_addr 字段可以分析出来 UV 计算、ISP 分布和地域分布这几个指标,比如 UV 计算,UV 当然不能只是通过 IP,我们通常还会结合一些 UA 信息,支持更多的信息去计算 UV,但最重要的是 IP。通过 IP 可以分析出一些 ISP 分布和地域分布。因为故障有可能是在同一个 ISP 出现的,而其他 ISP 没有问题。比如某个省份有问题,当你要做流量牵引的时候,其实这些数据是非常重要的,可以帮你去决策:你这一次问题是不是要去做,做怎么样的牵引。
upstream_addr
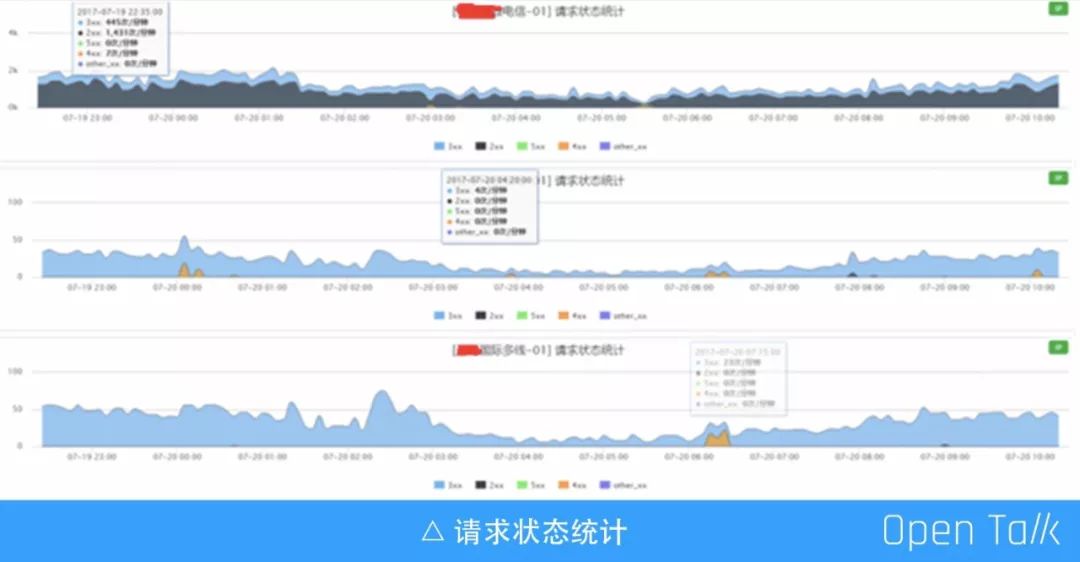
通过 upstream_addr 结合 send db 信息,可以知道服务分布在哪些机房,以及机房的哪些 IP 有问题,就可以结合自建机房或公有云机房去定位问题:这是不是在某个机房出现的问题,或者在某个机房转发给另外一个机房出现的问题,都可以在这一侧去定位。
body_bytes_sent
body_bytes_sent 是一个用户接收的字节,通过这你可以判断到几个点:一是机房的带宽,二是用户的平均下载速率。
通常来说,带宽不是我们最关心的,但如果业务出现异常,异常流量特别大。比如域名被攻击,或者服务出现异常,用户端重复请求,导致机房流量接近崩溃,此时必须要去定位到突发流量来自于哪个域名,才能真正做到出问题迅速解决。
http_referer
http_referer 这个字段可以分析出流量来源、转化率和 SEO 优化。比如请求来源于百度、谷歌或其它导流的网站,那么用户来自于哪里都可以通过这个分析出来。
http_user_agent
在 UA 这一层,可以分析出用户的浏览器、操作系统分布以及对爬虫的识别。
比如,比较良好的爬虫他通常会带上自己的 UA,你可以把这些 UA 的用户指定到生产环境的备用集群,而不是让爬虫在生长环境的主服务器任意爬取。
request_time(upstream_response_time)
请求时间通常可以分析出来延时分布和平均延时这两个指标。基于此,后续可以深化另外一个指标,因为平均延时实际上作用并不大,可能有一些少量的错误请求把延时拉高,导致很容易误报,误报的情况下就会导致监控是失效的。
request
request 通常会有返回码的信息,比如你可以监控到 URI 的分布,服务是全部请求用户还是某个 URI 异常,通过这是可以分析并定位到具体原因。
业务故障快速定位
Apdex 量化应用性能
通过请求时间其实并不能很好地反馈应用的真实情况,Apdex 就是应用不良的一个指标。它的模型非常简单,通常有三个样本:失望、容忍和满意。
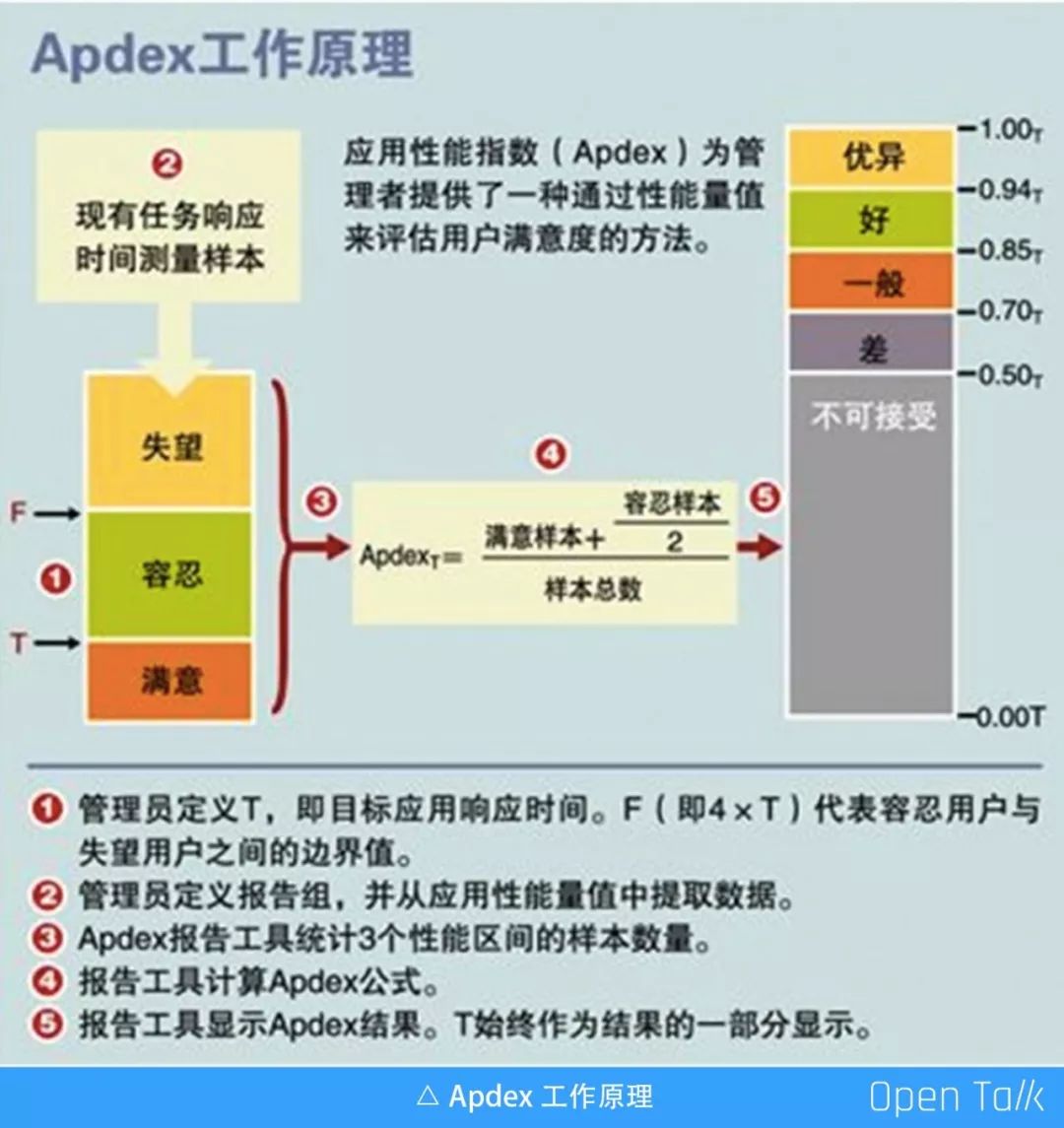
通过上图公式可以计算出来 0-1 的值,比如服务的平均延时是 50ms,用户达到满意 500ms 已经够了,那满意样本平均延时可以设在 500ms 以下;用户如果等待 1s 已经不能接受了,那么容忍样本可以设在 1s 以下;1s 以上,你的用户是不能接受的,可以定义成失望样本。
这个指标可以反馈用户的真实体验,而平均延时并不能解决这个问题。这个指标只要出现问题,服务一定是有问题的。比如可用性要求到 99.99%,万分之一的用户受到影响,就应该处理了。
刚才定义的只是一个指标,比如请求延时,实际上还可以升华其它的指标跟它绑定,比如返回码,返回延时、链接延时等一系列指标,只需要定义出业务真实受影响的一个值,以及它的条件,就可以定义出来三个样本。通过这三个样本,可以算出一个 0-1 的值,然后告警规则就可以在 0-1 去设置,比如 99%、98% 之类的就应该告警。这个可以真实反馈服务指标,相比于按延时或返回码单纯去告警会准确很多。
同时还有另一个应用场景,就是系统化定位。如果反馈指标很多,我们既要参考返回码,又要参考请求延时,还要参考链接延时等一系列指标,将所有指标都深化成 0-1 的值,就很容易去做定位。我们可以把所有设计的端都做染色,染色后就很容易把异常的颜色挑出来,这时再去定位根因,通过颜色就可以直接判断哪一层出问题。
前面说的是每一层涉及的指标,分完层以后,可以按每一层的需要、指标去进行染色。服务在哪些机房,在哪些 CDN,通过故障定位的页面就能看到所有指标,颜色也做了标记,任何一个人都可以定位到根因。虽然能够定位到根因,也不一定能解决,但可以做到一个客服直接反馈给用户是什么原因导致的,这样用户体验会好很多,可以给客户点小建议,让他去尝试一下切换网络或者其他的一些操作等。
服务拓扑健康染色
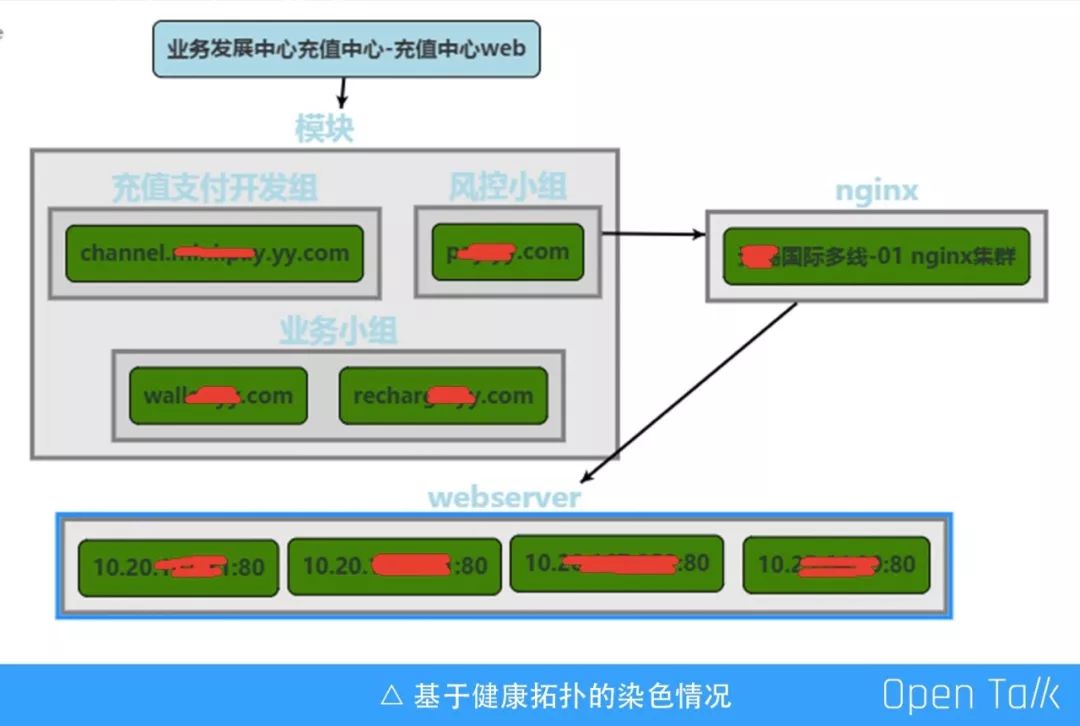
上图是基于健康拓扑的染色情况,其实这是一个充值业务,充值业务通常会由多个域名组成,每个域名、机房以及机器是否有问题,可以在这上面直接看到每一层的问题。
这个场景相对简单,有些更复杂的可能几十个域名在上面。网络可能没有问题,可能依赖的服务出现了问题,但是只要在这个地方,就可以全部找到。
业务数据跟踪
账单计算手段
我们通过日志挖掘了更大的价值,每年节省了数百上千万的成本。我们做了跟 CDN 厂商的对账,这个前提是虎牙大量使用了 CDN,这个 CDN 的成本可能占我们 IT 运营成本 50% 以上。
起初,我们对账的方式是带宽与业务指标的关联,对账精度通常是 3%-8% 之间。因为 UA 不是真实的带宽,即使指标出现异常,也没办法跟 CDN 厂商说“你这个带宽数据有问题”,而在我们做监控时经常会发现超过 8% 的数据。
后来,我们做了另一个方案,可以看到不同的厂商计费手段不同,某些厂商可能不是基于日志的,而是基于交换机端口的流量。于是我们让所有服务的 CDN 厂商统一切换到基于日志的计费方式,把所有日志传回我们的服务器,进行数据的复算。
数据的确定方式还有另一个手段就是拨测。我们会模拟用户的请求,通过对请求的跟踪,最终算出来真实下载跟 CDN 统计值的误差,拨测误差小于 1%,基于 CDN 计算出来的总误差小于 1%,我认为是可以接受的。实际我们做到的拨测误差平均在 0.6% 左右,总带宽误差通常在 0.25% 左右。
独立复算逻辑
1. 拨测实际下载带宽 VS CDN 日志记录带宽
覆盖 90%+ 流量
拨测时间段凌晨 3 点到下午 3 点
拨测带宽保证一定的量
2. CDN 日志复算总带宽 VS CDN API 计费带宽
次日 6 点以后下载全部日志后计算
API 获取全部域名带宽数据统计
3. 网卡流量 VS CDN 日志计算带宽
复算带宽系数
以上是我们的独立复算逻辑,实测的下载带宽跟用户记录的带宽,会覆盖 90%流量的场景。比如流量来自于哪些业务,我们会覆盖 90% 以上的业务。业务的低峰时间段会去拨测,其实这个服务并不会占用我们的带宽成本,比如在凌晨 3 点到下午 3 点持续对带宽进行拨测,保证测试的样本数是足够的。通过 CDN 的复算总带宽跟 CDN API 计费带宽进行对比,最终算出它们的误差,
三线路码率偏差对比
虎牙用的主要使用的是 CDN 视频流,我们对不同码率和误差也做了监控,曾今出现过一个 CDN 厂商,我们要求的是 2M,那单个用户调度进来就应该是 2M,但是有厂商设到 2.25,即用户调到他那边去,凭空就多了 10%。后来我们及时沟通修复了。
最终我们去做结费,最终会得出几个值,一是拨测的误差,二是计费的总误差,以及计费的具体误差值,通过这些值计算来复查核算成本。
最后分享下开源工具,能更好的去做数据分析。
1.ELK
2.Druid.io,Kylin
3.Storm,Spark
快 来 找 又 小 拍
推 荐 阅 读
关于技术
•大家好看才是真的好看 •
给个「好看」呗
以上是关于虎牙直播张波:掘金Nginx日志 | OpenResty × Open Talk 全国巡回沙龙深圳站的主要内容,如果未能解决你的问题,请参考以下文章
问下像YY直播那样给的RTMP推流地址建的是啥服务器 怎样搭建这样的服务器