58房产Nginx 网络调优实践
Posted 58技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了58房产Nginx 网络调优实践相关的知识,希望对你有一定的参考价值。
导语
本文讲述了 nginx 作为负载均衡组件,在应对超高并发的情况下所遇到性能问题,以及针对这些具体问题的分析、定位、并最终通过整体调优 kernel、网卡、Nginx 参数,达到 QPS 从20000+ 提高到 40000+ 的完整过程。。
背景
分析问题
A、网卡丢包(包含syn 包和数据包)
B、内核 syn 包丢失
C、中间链路丢包,比如交换机、路由器
本文章重点说明原因A和B。
解决问题
我们能从 ifconfig 命令中看到网卡的相关统计信息,其中和错误相关的有 3 个分别是 overruns、dropped 、errors。

B、dropped : 从网卡fifo 队列复制到 内核空间错误,比如内核无内存可用,不常见
C、overruns:数据进入网卡 fifo 队列时被丢弃(就是没有进入网卡)最常见的错误,常见的原因就是中断不均衡,默认内核将所有的网卡中断都绑定在 CPU core 0 ,高并发下 CPU core 0 有太多中断,当处理不过来时,fifo 队列没有被及时消费,后续数据没有进入网卡直接被丢弃。
1.1 网卡 overruns 如何解决
前分析网卡 overruns 是因为中断都默认绑定在了 CPU core 0 ,比如下图 CPU core 0 全部时间都在处理软中断,肯定有很多中断来不及响应。
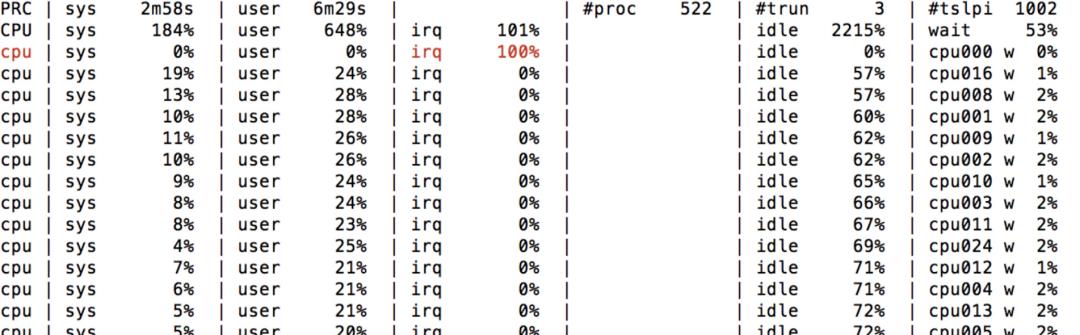
$ cat /proc/interrupts | grep eth | awk '{print $1,$NF}'77: eth0-078: eth0-179: eth0-280: eth0-381: eth0-482: eth0-583: eth0-684: eth0-7$ echo 0 > /proc/irq/77/smp_affinity_list$ echo 1 > /proc/irq/78/smp_affinity_list.....
2、解决内核 syn 包丢失的问题
通过抓包发现,基本上都是 TCP 握手的第一个 syn 包发了两次,并且间隔 1s ,这种现象很明显就是包丢弃,因为抓包能抓到,所以第一个被明确丢弃,具体如下图
nstat -za | grep -Ei '(TcpExtListenOverflows|TcpExtListenDrops|TcpExtTCPBacklogDrop)'TcpExtListenOverflows 0 0.0TcpExtListenDrops 0 0.0TcpExtTCPBacklogDrop 0 0.0
2.1 syn 包丢失 - TcpExtListenOverflows & TcpExtListenDrops 同时增大
此案例比较简单,从 TcpExtListenOverflows 明显可以看出是溢出导致,具体就是 TCP 三次握手成功的 accept-queue 满了,nginx 还没有来得及 accept ,此时新进来的握手请求只能丢弃,具体如下图
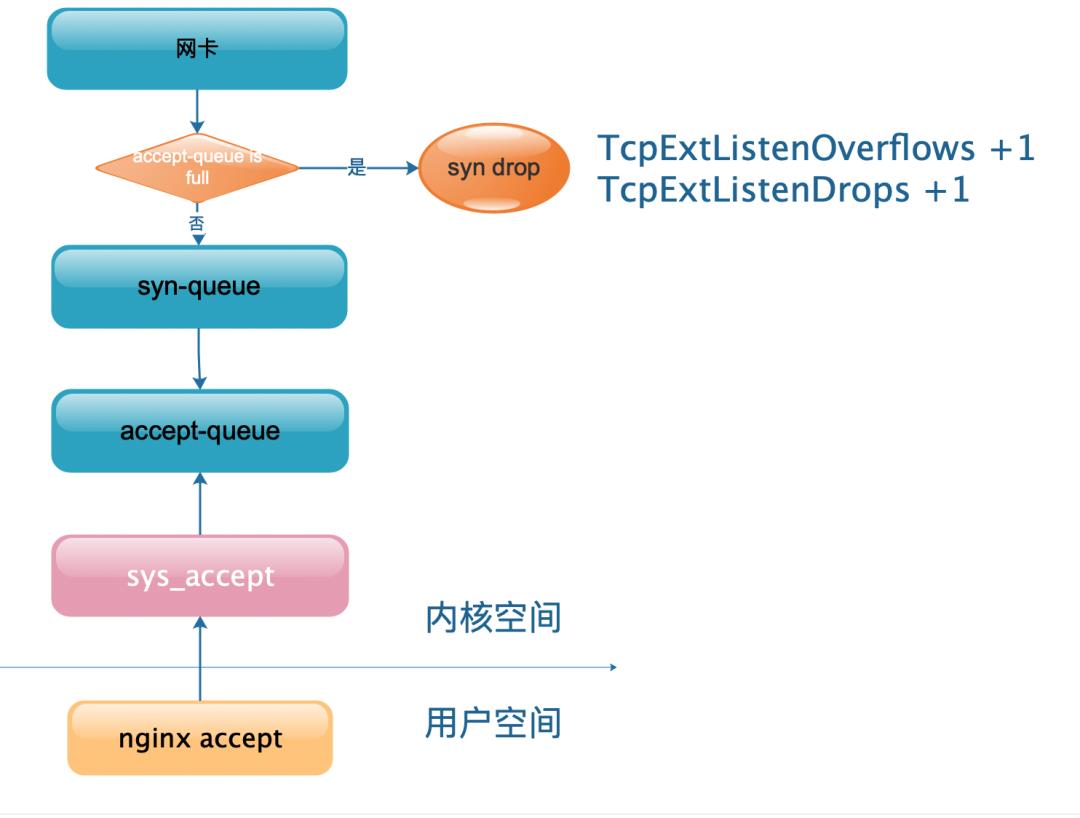
很明显这种 case 只需要适当增加 accept-queue 大小就行
acccept-queue = min(nginx backlog, net.core.somaxconn)
nginx backlog 默认 511
net.core.somaxconn 默认 128
如果系统未修改参数,那么默认 accept-queue= 128 ,这个值太小了,一般 2048 比较合适 具体调整如下,网络上介绍的文章比较多
注:nginx backlog 是全局配置 ,一个 port 只需要在一个地方添加即可
案例 2.1 解决方案
# linux kernelsysctl -w net.core.somaxconn=2048sysctl -w net.ipv4.tcp_max_syn_backlog=4096# nginxserver {listen 80 backlog=2048.....}
2.2 syn 包丢失 - TcpExtListenOverflows 不变 & TcpExtListenDrops增大
相比 3.1.1 案例,这个案例 TcpExtListenOverflows 不变,原因更加复杂。当时解决问题的时候也是偶然发现内核有错误堆栈,才分析出具体原因。
具体原因是 TCP 的内存分配采用的是 slab + buddy算法,slab 块不够时,通过buddy 内存分配算法申请内存,如果高并发情况下 buddy 分配的内存刚好用完(此时系统仍然有可用的 free 内存),此时会因为申请不到 buddy 内存而直接丢弃TCP 请求,具体堆栈如下,这个堆栈网上能搜到很多,有其他程序比如 mysql 也会出现
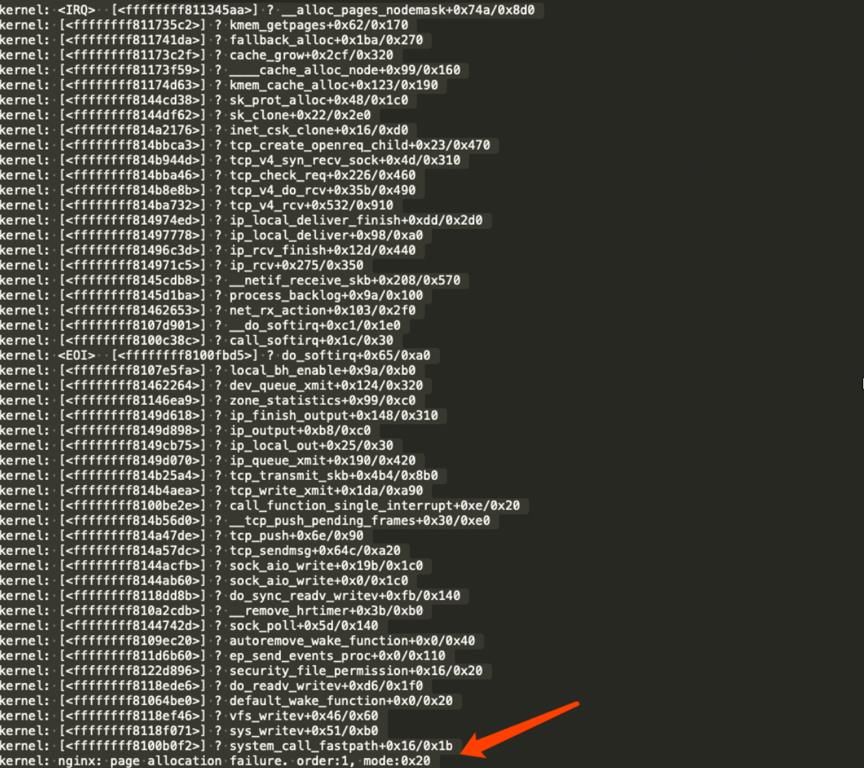
这个堆栈有几个重要的信息
A、nginx tcp_v4_syn_recv_sock (第一个syn 请求过来) 时申请内存失败
B、TCP 申请内存用的是 slab 算法 (kmem_cache_alloc)
C、kmem_cache_alloc申请失败时,通过 buddy 内存算法来补充 slab 空间
D、申请内存的 buddy order = 1 表示需要申请的内存大小是 2 * 4k = 8k
简单介绍下 buddy 内存算法
buddy 内存情况可以通过 /proc/buddyinfo 来查看

简单说明 第 3 列 556 表示 numa node 0 Normal 区域 order = 2 有 556 块,占用大小是 556 * 2 * 2 * 4K,也就是有556 个连续的16K内存
buddy 内存分配原则是高级别可以给低级别用 ,但是低级别不能给高级别用
比如 order = 1 可用,order = 0 不可用,此时如果申请 order = 0,会从 order = 1 借用1个,拆成2个,1个给申请方,另外一个划归 order = 0
buddy 内存是预分配的,可能在高并发瞬间用完,这个时候就会有内存分配失败的情况。
下面的图是出问题时 nginx 的 buddyinfo 监控

可以发现 Normal 区域 order = 0 有 174851 块,但是 order > 0 都没有可用内存,nginx 刚好要申请的 order = 1,所以申请内存失败,syn 包丢弃
针对这种情况阿里的工程师给了一个解决方案
# numa 在当前node回收内存sysctl -w vm.zone_reclaim_mode=1# 调大系统最小内存阈值=512000
真实测试下来并没有起到做大作用,只能再进行深入分析。首先发现 Nginx 机器物理内存非常大有 128G,进一步分析发现大部分内存都处于 cache 模式,此时可以联想到大部分内存都因为写巨大的 nginx 日志而处于文件 cache 模式,解决问题的关键变成为尽快释放 cache 缓存。
通过 echo 1 > /proc/sys/vm/drop_caches 释放 cache 会瞬间影响机器负载,还好 linux 有个 vm.extra_free_kbytes 参数,可以控制回收内存的时机
案例 2.2 解决方案
# 设置更大的水位线,让 kswapd 提前启动,# 比如我们nginx 服务器内存是128G,但是由于写入的日志非常大,大量的日志# 使得内存都被划分到 cache 区域,只有 kswapd 启动后才会回收sysctl -w vm.extra_free_kbytes= 1048576# 调大系统最小内存阈值=1048576
2.3 syn 包丢失 - TcpExtTCPBacklogDrop 增大
相比前面2个 案例 3.2.1、3.2.2, 这个更加复杂也难易理解,主要是因为是在多核多进程 lock 时发生,先看下面流程图,相比 3.2.1 的图更加复杂,当某一个核 比如 CPU core 0 处于 accept ->lock 状态, 这个时候,其他 CPU core 收到的 syn 数据包不能直接进入 syn-queue ,而是进入到了 backlog-queue ,backlog-queue 的大小是sk_rcvbuf + sk_sndbuf
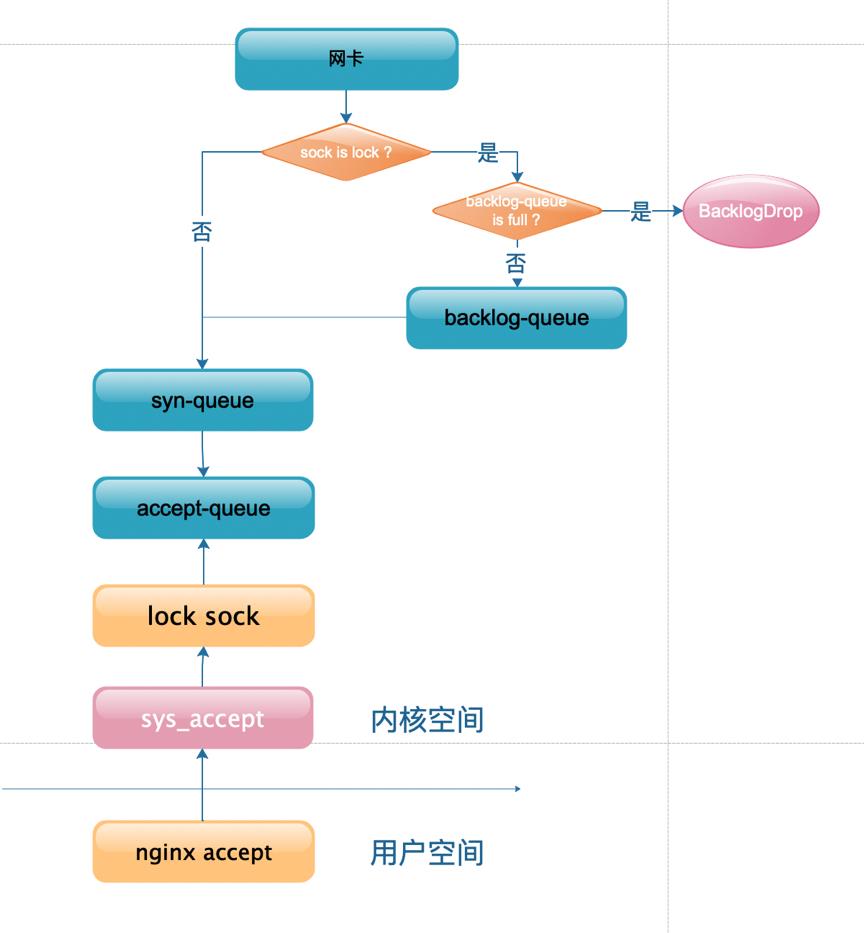
假如默认内核参数如下
net.ipv4.tcp_rmem=4096 87380 16777216
net.ipv4.tcp_wmem=4096 65536 16777216
那么默认 backlog-queue = 87380 + 65536 = 152916
看起来还挺大,但是高并发下面其实还是比较小的,backlog 每次进去的数据大小是 800 ~ 1800,不同网卡驱动有些区别,也就是lock 期间最多进入的请求为 152916/{800,1800} = 190 ~ 80,确实有些小。
2种方式增大 backlog-queue
A、调整内核参数 ,修改中间的值 net.ipv4.tcp_rmem & net.ipv4.tcp_wmem
B、nginx 提供了修改的方式,比如如下 server backlog=2048 rcvbuf=131072 sndbuf=131072
修改后的效果,可以看出增大 rcvbuf & sndbuf 还是很有效果 但是有一个机器有些问题,效果不明显
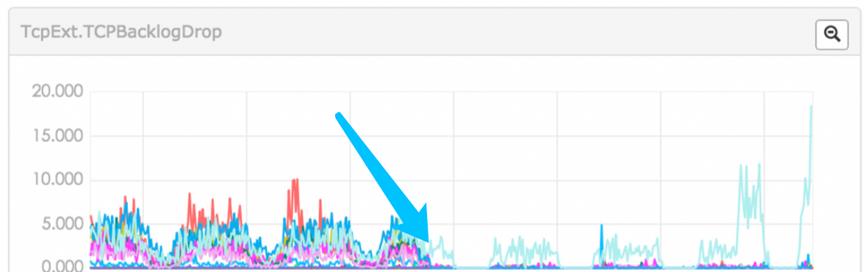
继续分析
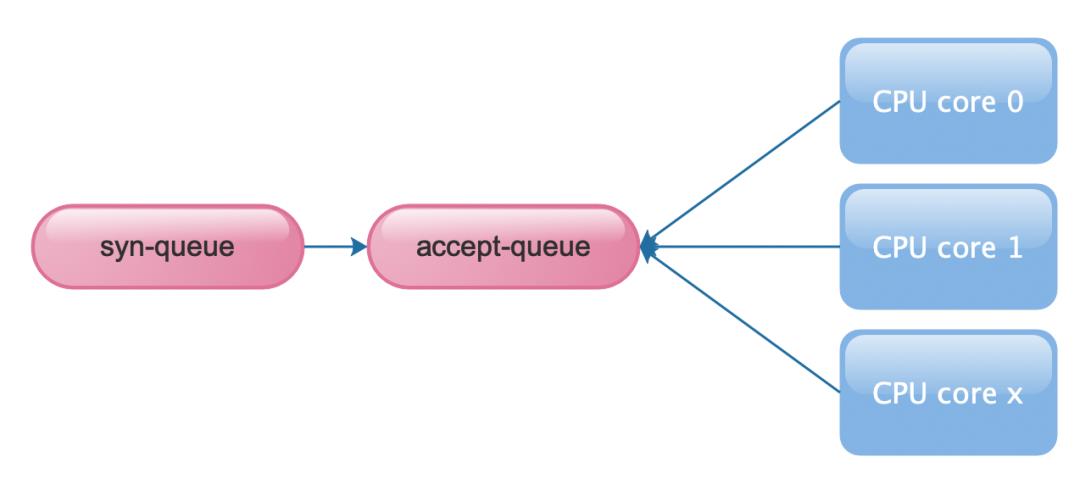
上面看到,之所以会产生 TcpExtTCPBacklogDrop 是因为多 CPU core 同时 accept,如果有 1 个 cpu core lock 了 sock,会导致其他 CPU core 收到请求后只能放到 backlog-queue,如果降低lock ,那么就从根本上解决, Nginx 提供了 reuseport 的功能(需要内核支持 SO_REUSEPORT)
无 reuseport 的情况如下图,多个 cpu core 竞争 一个 sock->accept-queue,
使用 reuseport 后如下图,每个cpu core 都分配 1 个一套资源,避免了竞争
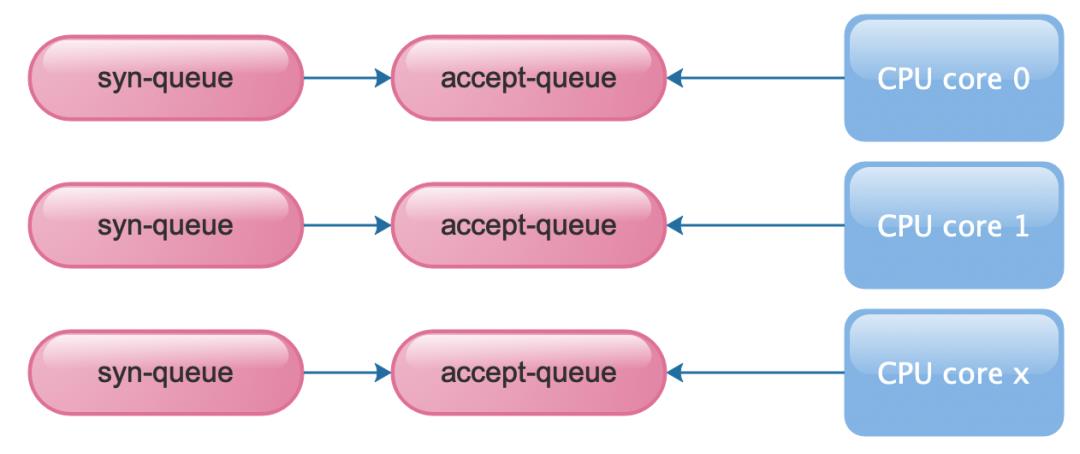
开启 reuseport 后,nginx 同一个监听端口会出现多条记录,也就对应多个内核 sock,并且多个 accept-queue,syn-queue,backlog-queue。

效果如下图
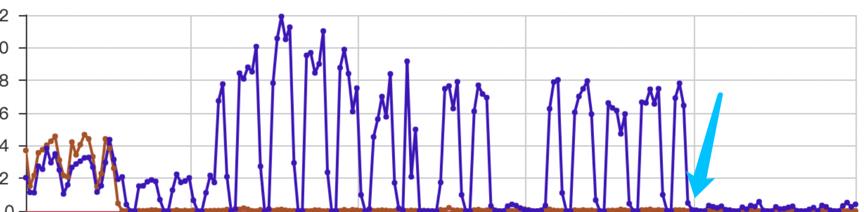
2.3 解决方案总结
增加 reuseport 选项
# nginxserver {listen 80 backlog=2048 rcvbuf=131072 sndbuf=131072 reuseport;.....}
3、优化总结
1. 通过绑定网卡中断号到 CPU core ,解决网卡 overruns2. 调整 backlog 来解决 TcpExtListenOverflows++ & TcpExtListenDrops++3. 调整 vm.extra_free_kbytes && vm.min_free_kbytes 解决 buddy memory 分配失败的问题导致的 TcpExtListenDrops++4. nginx 增大 rcvbuf & sndbuf ,并且开启 reuseport 来解决 TcpExtTCPBacklogDrop++
4、内存说明
4.1 backlog 每次进去的数据大小是 800 ~ 1800
backlog 进入的是一个数据包,也就是 1 个 sk_buff,1个 sk_buff会包含 (sizeof sk_buff)+ data (比如 1500 以太包最大值),此时并没有进入 TCP 栈处理。
4.2 申请内存的 buddy order = 1 表示需要申请的内存大小是 2 * 4k = 8k
内核内存的特点就是大小固定(因为结构体都是固定大小),针对这种场景内核设计了 slab 内存算法,将大块内存分割成固定的小块,大块内存采用 buddy 算法,小块内存采用 slab 算法,比如固定申请大小为 2600 大小的内存,就可以采用 2个连续的4K内存 2700 * 3 = 8100 ,这样可以分成3个小块,实际其实更加复杂,可以参考后面的参考文献,slab 的情况可以查看 /proc/slabinfo
slab 情况查看如下
总结
因为篇幅原因每个案例只能简单介绍,继续深挖还可以写很多内容,比如 backlog 为啥 511 有点小。Nginx 调优的地方有很多,本文章只介绍了网络的部分,其中部分是网络上已经很成熟的方案,其他的都是自己通过实践总结的,并且起到作用。调优本身是一个实践的过程,本文讲述的内容都是实践过并且有用的,但是不一定在其他场景100%适用,不过分析过程可以作为参考。
Linux内核分析:页回收导致的cpu load瞬间飙高的问题分析与思考 :http://www.mamicode.com/info-detail-1420432.html
伙伴系统之避免碎片--Linux内存管理(十六) :https://blog.csdn.net/gatieme/article/details/52694362
Linux page allocation failure 的问题处理 - zonereclaimmode :https://yq.aliyun.com/articles/228285/
Linux服务器Cache占用过多内存导致系统内存不足问题的排查解决(续):https://www.cnblogs.com/panfeng412/p/drop-caches-under-linux-system-2.html
如何释放Linux的cache :https://blog.csdn.net/william_m999/article/details/94898565
tcp的半连接与完全连接队列:https://www.jianshu.com/p/ff26312e67a9
tcp sk_backlog(后备队列分析): https://www.cnblogs.com/alreadyskb/p/4386565.html
TCP套接口的skbacklog接收队列: https://blog.csdn.net/sinat20184565/article/details/88861077
kernel 3.10内核源码分析--slab原理及相关代码 : http://blog.chinaunix.net/uid-20671208-id-4655765.html
END
阅读推荐
以上是关于58房产Nginx 网络调优实践的主要内容,如果未能解决你的问题,请参考以下文章