其实前两条数据是on的,后面的数据是zh的,要想看出区别,可在结果列中加上姓名参考技术Aselect day,sal,sum(sal) over(order by day) sumsaltoyesterday from A参考技术Bselect day,sal,sum(sal) over(partition by day order by sal) sumsaltoyesterday from A;参考技术Cselect day,sal,sum(sal) over(partition by null order by day rows between unbounded preceding and current row) as sumsaltoyesterday from a;
(一)、分析函数语法: FUNCTION_NAME(<argument>,<argument>...) OVER (<Partition-Clause><Order-by-Clause><Windowing Clause>)
例:(在oracle示例库中演示,用户scott) select ename,sum(sal) over (partition by deptno order by ename) new_alias from emp; a、sum就是函数名(FUNCTION_NAME) b、(sal)是分析函数的参数,每个函数有0~3个参数,参数可以是表达式,例如:sum(sal+comm) c、over 是一个关键字,用于标识分析函数,否则查询分析器不能区别sum()聚集函数和sum()分析函数 d、partition by deptno (按相应的值(deptno)进行分组统计)是可选的分区子句,如果不存在任何分区子句,则全部的结果集可看作一个单一的大区 e、order by ename 是可选的order by 子句,有些函数需要它,有些则不需要.依靠已排序数据的那些函数。
即:分析函数带有一个开窗函数over(),包含三个分析子句:
分组(partition by)
排序(order by)
窗口(rows)
示例1:
SELECT empno,ename,job,deptno, ----查询基础字段
COUNT(*) over(PARTITION BY deptno) cnt_dept_man, --- 查询部门人员数量 (等同于用部门deptno进行分组查询)
COUNT(*) over (PARTITION BY deptno ORDER BY empno) AS sum_dept_add, --- 查询出的部门人员数依次为前一行的求和数加上当前行的行数(若未sum则会是逐行累加的数据)
COUNT(*) over(PARTITION BY job) cnt_job_man , ---查询岗位的的人员数量 (等同于用岗位job进行分组查询)
COUNT(*) over (PARTITION BY job ORDER BY empno) AS sum_job_add ---查询出岗位人员(依次为前一行的求和数加上当前行的行数(若未sum则会是逐行累加的数据)
FROM emp;
-- 一般的写法:
SELECT E.ENAME, E.JOB, E.SAL MAXSAL , E.DEPTNO
FROM SCOTT.EMP E,
(SELECT E.DEPTNO, MAX(E.SAL) SAL FROM SCOTT.EMP E GROUP BY E.DEPTNO) ME
WHERE E.DEPTNO = ME.DEPTNO
AND E.SAL = ME.SAL;
-- 分析函数OVER (使用count函数用order by将相应数据分组,获取分组编号)
SELECT ENAME,JOB,MAXSAL,DEPTNO FROM
(SELECT ENAME,JOB,MAX(SAL) OVER (PARTITION BY DEPTNO) AS MAXSAL,DEPTNO,
COUNT(*) OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS NUM FROM EMP)
WHERE NUM = 1;
--析函数OVER (使用rank函数用order by将相应数据分组,获取分组编号)
SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM
(SELECT ENAME,JOB,SAL,RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E
WHERE E.RANK = 1 AND NOT deptno IS NULL;
--分析函数OVER (使用dense_rank函数用order by将相应数据分组,获取分组编号)
SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM
(SELECT ENAME,JOB,SAL,dense_RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E
WHERE E.RANK = 1 AND NOT deptno IS NULL;
--分析函数OVER (使用row_number函数用order by将相应数据分组,获取分组编号)
SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM
(SELECT ENAME,JOB,SAL,row_number() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E
WHERE E.RANK = 1 AND NOT deptno IS NULL;
--CREATE TEST TABLE AND INSERT TEST DATA.
create table students
(id number(15,0),
area varchar2(10),
stu_type varchar2(2),
score number(20,2));
insert into students values(1, \'111\', \'g\', 80 );
insert into students values(1, \'111\', \'j\', 80 );
insert into students values(1, \'222\', \'g\', 89 );
insert into students values(1, \'222\', \'g\', 68 );
insert into students values(2, \'111\', \'g\', 80 );
insert into students values(2, \'111\', \'j\', 70 );
insert into students values(2, \'222\', \'g\', 60 );
insert into students values(2, \'222\', \'j\', 65 );
insert into students values(3, \'111\', \'g\', 75 );
insert into students values(3, \'111\', \'j\', 58 );
insert into students values(3, \'222\', \'g\', 58 );
insert into students values(3, \'222\', \'j\', 90 );
insert into students values(4, \'111\', \'g\', 89 );
insert into students values(4, \'111\', \'j\', 90 );
insert into students values(4, \'222\', \'g\', 90 );
insert into students values(4, \'222\', \'j\', 89 );
commit;
--A、GROUPING SETS
select id,area,stu_type,sum(score) score
from students
group by grouping sets((id,area,stu_type),(id,area),id)
order by id,area,stu_type;
/*--------理解grouping sets
select a, b, c, sum( d ) from t
group by grouping sets ( a, b, c )
等效于
select * from (
select a, null, null, sum( d ) from t group by a
union all
select null, b, null, sum( d ) from t group by b
union all
select null, null, c, sum( d ) from t group by c
)
*/
--B、ROLLUP
select id,area,stu_type,sum(score) score
from students
group by rollup(id,area,stu_type)
order by id,area,stu_type;
/*--------理解rollup
select a, b, c, sum( d )
from t
group by rollup(a, b, c);
等效于
select * from (
select a, b, c, sum( d ) from t group by a, b, c
union all
select a, b, null, sum( d ) from t group by a, b
union all
select a, null, null, sum( d ) from t group by a
union all
select null, null, null, sum( d ) from t
)
*/
--C、CUBE
select id,area,stu_type,sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type;
/*--------理解cube
select a, b, c, sum( d ) from t
group by cube( a, b, c)
等效于
select a, b, c, sum( d ) from t
group by grouping sets(
( a, b, c ),
( a, b ), ( a ), ( b, c ),
( b ), ( a, c ), ( c ),
() )
*/
select decode(grouping(id),1,\'all id\',id) id,
decode(grouping(area),1,\'all area\',to_char(area)) area,
decode(grouping(stu_type),1,\'all_stu_type\',stu_type) stu_type,
sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type;
break on id skip 1
select id,area,score from students order by id,area,score desc;
select id,rank() over(partition by id order by score desc) rk,score from students;
--允许并列名次、名次不间断
select id,dense_rank() over(partition by id order by score desc) rk,score from students;
--即使SCORE相同,ROW_NUMBER()结果也是不同
select id,row_number() over(partition by ID order by SCORE desc) rn,score from students;
select cume_dist() over(order by id) a, --该组最大row_number/所有记录row_number
row_number() over (order by id) rn,id,area,score from students;
select id,max(score) over(partition by id order by score desc) as mx,score from students;
select id,area,avg(score) over(partition by id order by area) as avg,score from students; --注意有无order by的区别
--按照ID求AVG
select id,avg(score) over(partition by id order by score desc rows between unbounded preceding
and unbounded following ) as ag,score from students;
--2、SUM()
select id,area,score from students order by id,area,score desc;
select id,area,score,
sum(score) over (order by id,area) 连续求和, --按照OVER后边内容汇总求和
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;
select id,area,score,
sum(score) over (partition by id order by area ) 连id续求和, --按照id内容汇总求和
sum(score) over (partition by id) id总和, --各id的分数总和
100*round(score/sum(score) over (partition by id),4) "id份额(%)",
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;
--------------------------------------------答案及分析 ACE A:ntile 作为统计分析函数可以创建登高直方分布图 语法 B:NTILE(expr) OVER ([ query_partition_clause ] order_by_clause) width_bucket 和ntile类似,是创建一个封闭口的分布,WIDTH_BUCKET (expr, min_value, max_value, num_buckets),B错误的原因是10是结束口,大于10就会显示成num_buckets+1 ,下面是官网的解释: WIDTH_BUCKET lets you construct equiwidth histograms, in which the histogram range is divided into intervals that have identical size. (Compare this function with NTILE, which creates equiheight histograms.) Ideally each bucket is a closed-open interval of the real number line. For example, a bucket can be assigned to scores between 10.00 and 19.999... to indicate that 10 is included in the interval and 20 is excluded. This is sometimes denoted [10, 20). C:见B解释 D:mod 顺序有问题 E:ceil 这个行,因为是ceil是求大于或等于当前数据的最小整数,比如ceil(3.123),会是4,
--------------------------------- A: ntile分析函数,这个创建的是等高直方图, order by integer_value 每个桶分2个整数,推荐 B: width_bucket 这个是构建等宽直方图函数,并且范围取值min和max 是半闭半开区间,即 [min,max), 所以要将1-10分到5个桶,参数传入范围应该是1,11 C: 纠正B的写法 D: mod也可以分桶,但这里放入同一桶中的不是连续的,比如,1和6都被放入的2号桶 E: 利用ceil函数也可以达到目的,这个方法适用于较早的数据库版本
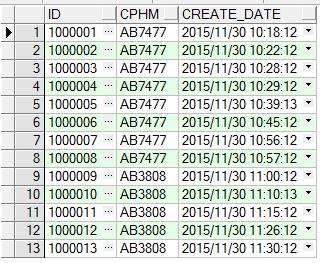
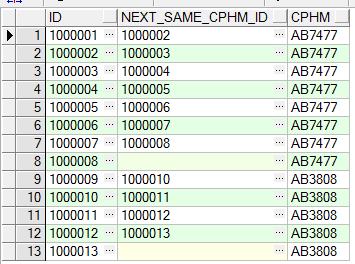
1 select cphm, count(1) total from
2 (
3 select t.id,
4 t.create_date t1,
5 lead(t.create_date,1, null) over( partition by cphm order by create_date asc ) t2,
6 ( lead(t.create_date,1, null) over( partition by cphm order by create_date asc ) - t.create_date ) * 86400 as itvtime,
7 t.cphm
8 from tb_test t
9 order by t.cphm, t.create_date asc
10 ) tt
11 where tt.itvtime >= 600 or tt.itvtime is null
12 group by tt.cphm