SOFARPC 性能优化实践(上)| SOFAChannel#2 直播整理
Posted 金融级分布式架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SOFARPC 性能优化实践(上)| SOFAChannel#2 直播整理相关的知识,希望对你有一定的参考价值。
<SOFA:Channel/>,有趣实用的分布式架构频道。
本次是 SOFAChannel 第二期,主要分享 SOFARPC 在性能上做的一些优化,这个系列会分成上下两部分进行分享,今天是 SOFARPC 性能优化(上),也会对本次分享中的一些结论,提供部分代码 Demo,供大家了解验证。
欢迎加入直播互动钉钉群:23127468,不错过我们每场直播。
大家好,今天是我们 SOFAChannel 第二期。欢迎大家观看。
我是来自蚂蚁金服中间件的雷志远,花名碧远,目前在负责 SOFARPC 框架相关工作。
去年的时候,我们和外部的爱好者们一起,做了一个基于 SOFARPC 的源码解析系列,我同事已经发到群里了,大家可以保存,直播之后查看。
SOFARPC 源码解析系列:(点击【剖析 | SOFARPC 框架】即可查看)
https://www.sofastack.tech/posts
今年,基于源码解析的基础,我们来多讲讲实践,如何应用到大家的业务,来帮助大家解决实际问题。在直播过程中有相关的问题想提问,可以在钉钉群互动。
前言
在上一期中,余淮分享了《》。介绍了蚂蚁微服务的起源,以及之后服务化,单元化的情况。同时介绍了 SOFAStack 目前开源的情况。最后也分享了一下整个微服务中 SOFARPC 的设计与实现。
本期,我们主要分享 SOFARPC 在性能上做的一些优化。这个系列会分成上下两部分进行分享,今天是 SOFARPC 性能优化(上),也会对本次分享中的一些结论,提供部分代码 Demo,供大家了解验证。
我们先简要介绍一下 SOFARPC 的框架分层。这个在上次的分享中已经进行了介绍。
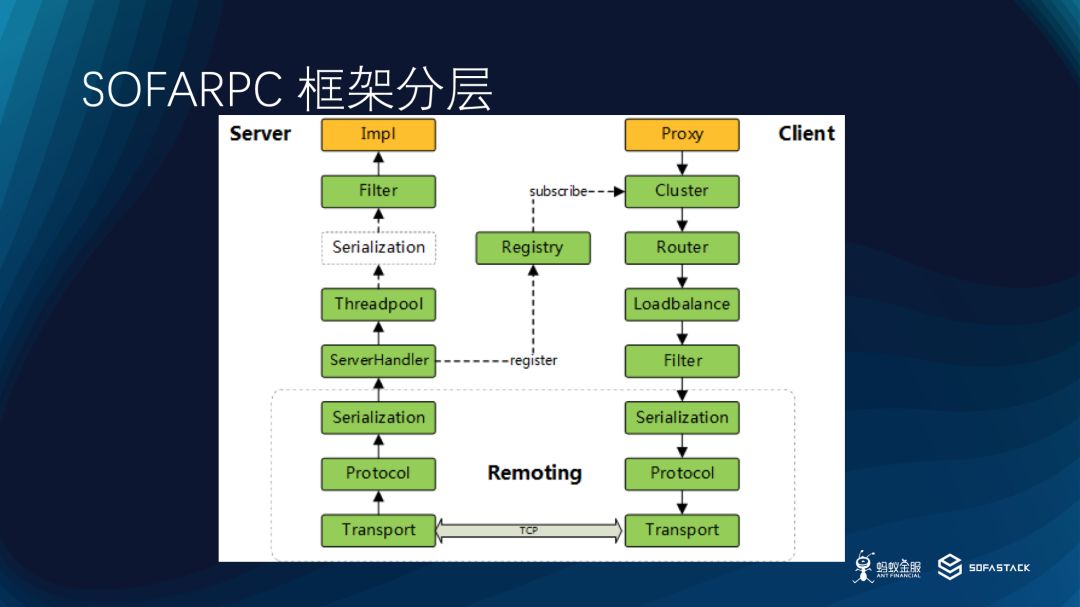
下层是网络传输层,依次是协议,序列化,服务发现和 Filter 等。
Transport 主要负责数据传输,可以是 Http2Transport,也可以是 BoltTransport,还有可能是其他。
Protocol 层是协议,是 Rest 还是 Bolt ,或是 Dubbo 。
Serialization 是序列化,对于每种协议,可以是用不同的序列化方式,比如 hessian,pb,json 等。
Filter 是通用的过滤器层,主要是为了留出一些扩展,完成一些其他扩展功能,比如 Tracer 的埋点等。
Router 是路由层,主要是做寻址,这里可能是 Zk,也可能是 LVS,也可能是直连。
Cluster 是客户端集群方式的表示。
自定义通讯协议使用
首先我想介绍一下自定义通讯协议。
在说明自定义通讯协议之前,我先简单介绍一下通讯协议。在TCP之上,RPC框架通常还需要将请求和响应数据进行一定的封装,组装成 Packet,然后发送出去。这样,服务端收到之后,才能正确识别整个 TCP 发过来的字节流中,哪一部分是我们可以进行处理的一个完整单位。反之,客户端收到服务端的TCP 数据流也是如此。
有了上面的共识之后,我们要回答下面两个问题:
为什么要自定义,不使用
Http2/Dubbo/Rest/Grpc?
自定义之后,带来了什么好处呢?
Http2 虽然更为通用,但是一方面,出现较晚,迁移转换成本高,并且通用则意味着传输的辅助数据会变多,会有一些额外的信息需要传递或者判断。对于序列化反序列化的控制上,也不是很好扩展操作。
而 Dubbo,协议简单强大。但是一些元信息需要解析,Header 中传输的数据太少,很多都需要依赖 body 中的数据反序列化完成后才能使用,头部的信息太少。

而使用了自研的协议之后,Header 中可自定义传输更多的元信息,序列化方式,Server Fail Fast,服务端线程隔离等也都成为可能。甚至蚂蚁在 ServiceMesh 的场景下,Mesh 本身也能利用 Bolt 的协议,进行部分数据的读取,而不依赖具体的序列化实现。
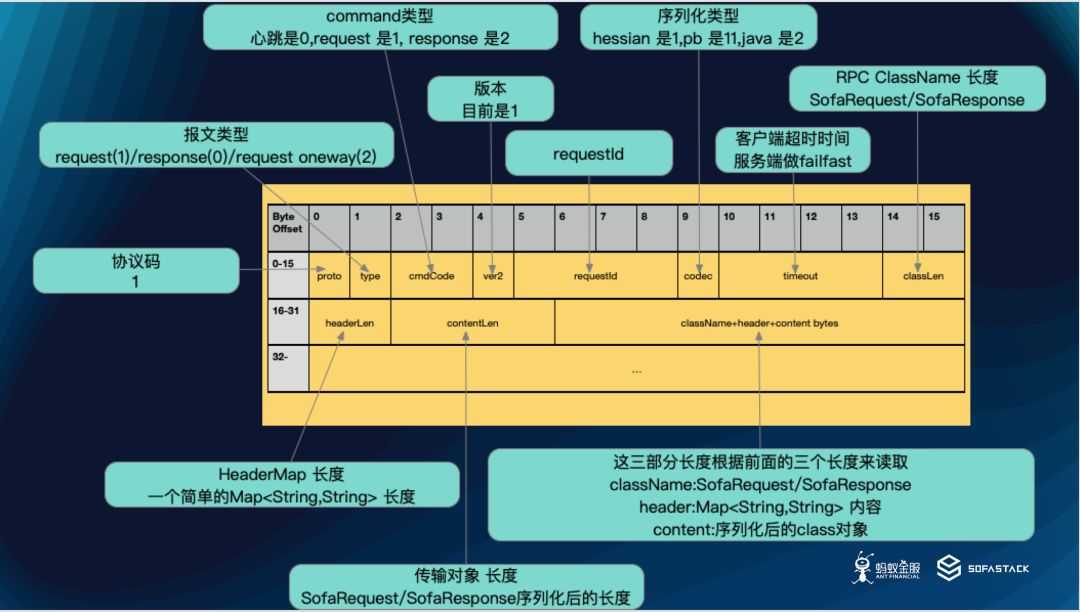
BOLT 协议图
经过我们的实践,大致来看,目前给我们带来的好处主要有以下的能力:
Server Fast 的支持
Header 和 Body 的分开序列化
Crc 校验的支持
版本的支持,预防未来可能出现更好的设计方案
多种序列化方式的支持
安全认证,Mesh 路由
如果你要自己设计一个通讯协议。可以考虑使用 BOLT 协议,或者参考进行更好的设计和优化。
关于 SOFABolt 相关的源码解析,也可以通过这个系列来了解。
SOFABolt 源码解析系列:(点击【剖析 | SOFABOLT 框架】即可查看)
https://www.sofastack.tech/posts
Netty 性能参数优化
在介绍了自定义通讯协议之后,也就是确定好了怎么封包解包之后,还需要确定传输层的开发。一个 RPC 框架从现在的情况来看,一般不太可能完全基于 JAVA 的 NIO 或者其他 IO 进行直接的开发,主要是一些 NIO 原生的问题和使用难度,而成熟的,目前可选的不多。基本上,大家都会基于 Netty 进行开发,HSF/Dubbo/Motan 等都是这样。
直接使用是比较简单的。在 Netty 的 Bootstrap 的设置中,有一些可选的优化项,有必要跟大家分享一下。
1、SO_REUSEPORT/SO_REUSEADDR - 端口复用(允许多个 socket 监听同一个IP+端口)
SOREUSEPORT 支持多个进程或者线程绑定到同一端口,提高服务器的接收链接的并发能力,由内核层面实现对端口数据的分发的负载均衡,在服务器 socket 上没有了锁的竞争。
同时 SOREUSEADDR也要打开,这样针对 time-wait 链接 ,可以确保 server 重启成功。在一些服务端启动很快的情况下,可以防止启动失败。
2、TCP_FASTOPEN - 3次握手时也用来交换数据
三次握手的过程中,当用户首次访问服务端时,发送 syn 包,server 根据客户端 IP 生成 cookie ,并与 syn+ack 一同发回客户端;客户端再次访问服务端时,在 syn 包携带 TCP cookie;如果服务端校验合法,则在用户回复 ack 前就可以直接发送数据;否则按照正常三次握手进行。也就是说,如果客户端中途断开,再建联的时候,会同时发送数据,会有一定的性能提升。
TFO 提高性能的关键是省去了热请求的三次握手,这在小对象传输较多的移动应用场景中,能够极大提升性能。
Netty 中仅在 Epoll 的时候可用 Linux特性,不能在 Mac/Windows 上使用,SOFARPC 未开启。
3、TCP_NODELAY-关闭 (纳格) Nagle 算法,再小的包也发送,而不是等待
TCP/IP 协议中针对 TCP 默认开启了 Nagle 算法。Nagle 算法通过减少需要传输的数据包个数,来优化网络。但是现在的环境下,网络带宽足够,需要进行关闭。这样,对于传输数据量小的场景,能很好的提高性能,不至于出现数据包等待。
4、SO_KEEPALIVE –开启 TCP 层面的 Keep Alive 能力
这个不多说,开启一下 TCP 层面的 Keep Alive 的能力。
5、WRITE_BUFFER_WATER_MARK 设置
通过 WRITEBUFFERWATERMARK 设置某个连接上可以暂存的最大最小 Buffer 之后,如果该连接的等待发送的数据量大于设置的值时,则 isWritable 会返回不可写。这样,客户端可以不再发送,防止这个量不断的积压,最终可能让客户端挂掉。如果发生这种情况,一般是服务端处理缓慢导致。这个值可以有效的保护客户端。此时数据并没有发送出去。
6、workerGroup
worker 线程数设置处理器+1,Netty 默认是线程数*2,可以根据自己的压测情况来判断。Boss Group 用于服务端处理建立连接的请求,WorkGroup 用于处理 I/O。为了避免线程上下文切换,只要能满足要求,这个值一般越少越好。
7、ioRadio 设置
EventLoop#ioRatio 的设置(默认50), 这是 EventLoop 执行 IO 任务和非 IO 任务的一个时间比例上的控制,BOLT 最佳实践是70,表示70%的时间在执行 IO 任务。
8、SO_BACKLOG 设置
在 Linux 系统内核中维护了两个队列:syns queue 和 accept queue。第一个是半连接队列,保存收到客户端 syn 之后,进入 synrecv 状态的这些连接,默认 netty 中是128, io.netty.util.NetUtil#SOMAXCONN ,然后读取 /proc/sys/net/core/somaxconn 来继续确定,之后还有一些系统级别的覆盖逻辑。
在一些场景下,如果客户端远远多余服务端,并发建联,可能不够。这个值也不能太大,否则会无法防止 SYN-Flood 攻击。Bolt 中目前这个值修改成了1024。通过设置之后,由于自己设置的和系统的取小,所以自己设置的值相当于设置了上限。如果 Linux 系统运维某些设置错误,也能通过代码层面进行避免。
目前我们的 Linux 层面,通常设置的是 128,最终经过计算会设置为 128。
SOFARPC 连接保持
Netty 设置基本 ok,协议也确定之后,连接的保持就比较重要,否则,第一次发送或者每次发送都要走一次建联的过程。虽然有 FAST OPEN 的加持,还是有一些损失。
说到这里, 可能有些同学有疑问:
Keep Alive 不够吗?
Bolt 的连接管理怎么做的?
如何解决初次建联的问题?
心跳是单向还是双向?
前面我们说过了,Keep Alive 已经打开了。不过,Keep Alive 还不够,主要是经过很多网络设备之后,Keep Alive可能失效,另外 Keep Alive 是一个 Linux 层面的设置,有时候整个系统并未打开。这些不可控的因素都会导致我们的连接管理失效。
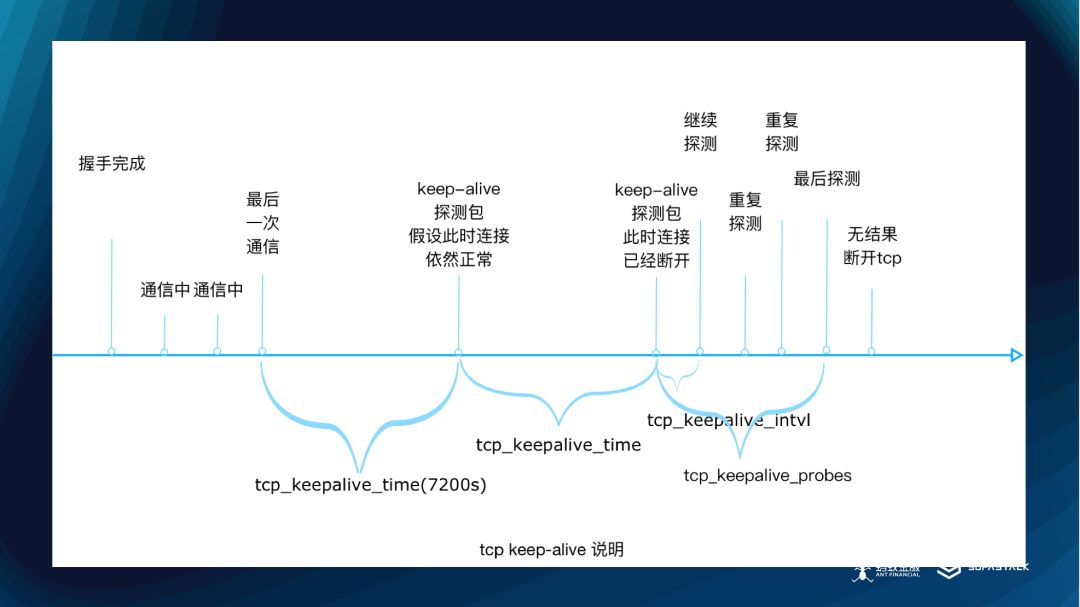
Keep Alive 图
上面是 Keep Alive 的处理,主要是在没有读写事件一段时间后,进行数据包的发送来保活。
但是这里要注意,如果你的场景是有大量的服务端,那么这个数据不建议进行扩大。因为 tcp 连接会成倍增长,反而带来性能下降。目前蚂蚁这边大部分也多为1。

RPC 连接管理
在 BOLT 连接管理的基础上,RPC 为了避免第一次用户请求,进行建联并发送的延迟,RPC 还有一个连接管理的线程,会异步的进行连接初始化。这样,当真正的请求发起的时候,连接已经准备好了,可以减少一次建联的耗时对业务的影响。
对于 LVS 和 VIP 的场景下,由于长连接的特性,即使后端有 100个 IP,对客户端来说,也只能和一个 IP 进行通信,因为这些设备是建联层面的,并非通信层面的。所以对这种情况,一个 RPC 框架也要考虑支持定时断链和重连。
序列化选择
以上都准备好了之后,序列化方式的选择决定了业务传输对象能够有多小,也决定了在传输之前,序列化和反序列化的时候能有多快或者有多占用 CPU 。

序列化图
蚂蚁这边长期使用 hessian 作为序列化方式,在出现跨语言需求后,同时支持 pb 。如果你还有考虑其他的序列化方式,可以参考附录中的序列化框架性能测试套件来进行选择。
需要注意的是,在 RPC 场景的序列化中,一定要考虑接口变更,字段新增的兼容性。因为一旦一个接口被客户 A 和 B 引用,此时 C 要升级 facade 接口,能否兼容 A 和 B 的情况就很重要。
基于我们自己的情况,在序列化方式的选择上:
如果很长时间内,不存在跨语言的情况,hessian 是兼容性和性能的综合考虑
如果考虑跨语言,并且对性能要求很高,Pb 可作为跨语言的情况下的选择。
在选型时也要考虑序列化框架的社区情况。切勿选择看上去性能高,但是已经不再维护的库,或者用户量非常少的库,一旦出现问题,比较难解决。
IO 线程池批量解包
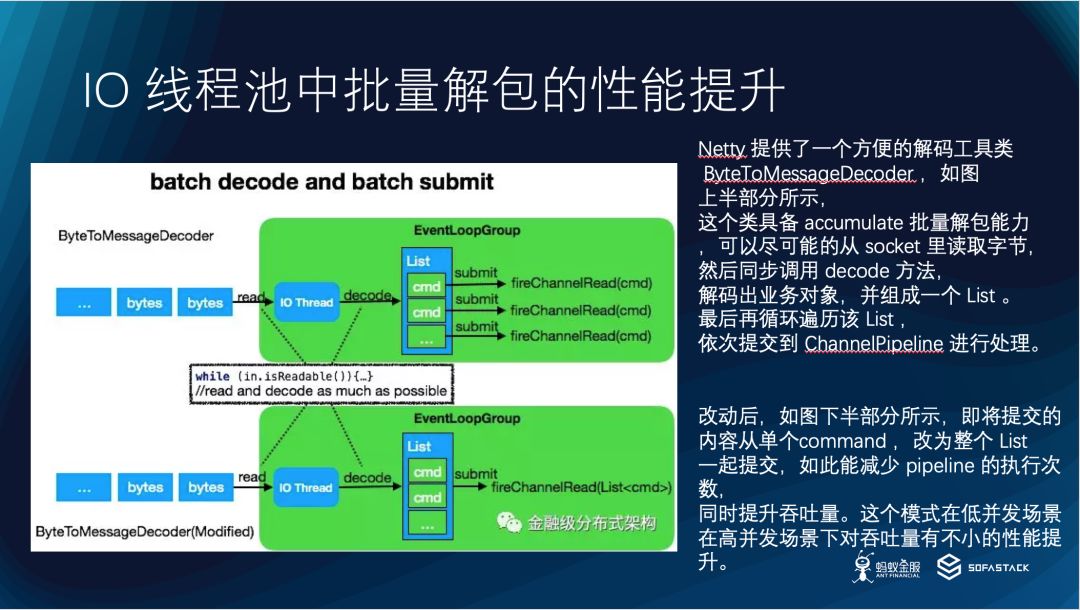
批量解包图
Netty 提供了一个方便的解码工具类 ByteToMessageDecoder ,如图上半部分所示,这个类具备 accumulate 批量解包能力,可以尽可能的从 socket 里读取字节,然后同步调用 decode 方法,解码出业务对象,并组成一个 List 。最后再循环遍历该 List ,依次提交到 ChannelPipeline 进行处理。改动后,如图下半部分所示,即将提交的内容从单个 command ,改为整个 List 一起提交,如此能减少 pipeline 的执行次数,同时提升吞吐量。这个模式在低并发场景下不明显,但是在高并发场景下对吞吐量有不小的性能提升。
这一段是我改成开关方式的,方便大家理解改动点。
if (batchSwitch) {
ArrayList<Object> ret = new ArrayList<Object>(size);
for (int i = 0; i < size; i++) {
ret.add(out.get(i)); }
ctx.fireChannelRead(ret); }else{
for (int i = 0; i < size; i++) {
ctx.fireChannelRead(out.get(i)); } }
我们的 DEMO 提供了一个验证的方式,如果有相关的压测环境,可以参考进行多并发的验证。
DEMO 链接:
https://github.com/leizhiyuan/rpcchannel
客户端 Proxy 的性能优化
作为一个 RPC 框架,最后,我们还有给用户的接口生成代理。目前一般大家都是要用动态代理来做。动态代理的性能有不同,使用上也有一定的差别。各个版本之间,也会有一定的差异。在选择上,需要大家根据实际情况,进行测试验证。
我们自己的测试数据显示 Javassist Bytecode 的方式是除了 Asm 之外,性能最好的。Asm 由于使用写法非常反人类,所以我们目前还是使用的 Javassist Bytecode 的方式。
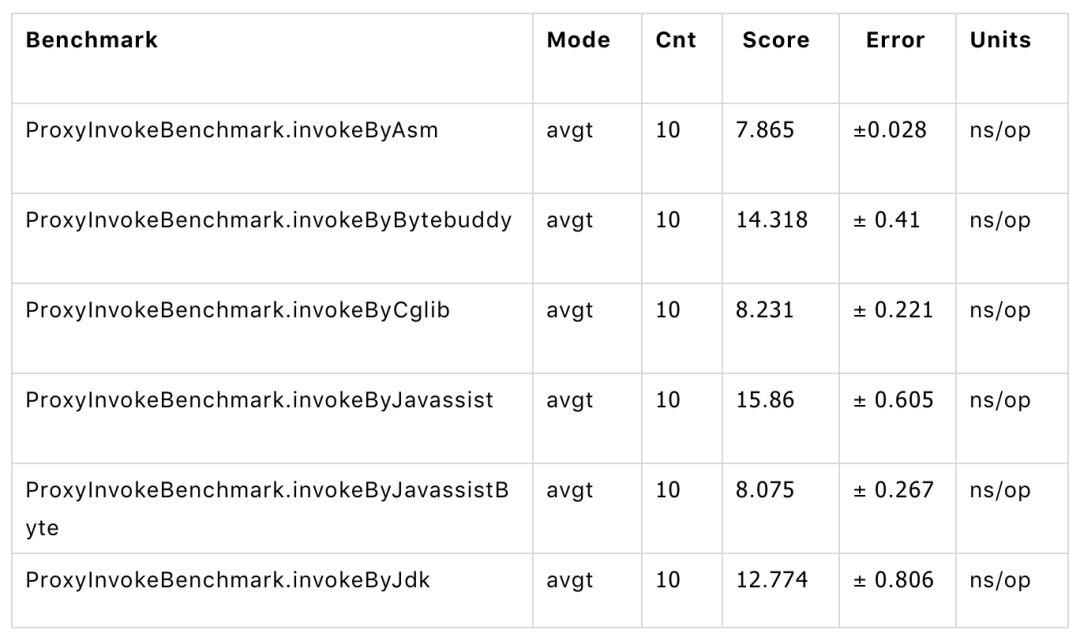
可优先选择 javassist bytecode,有一定的性能优势,性能测试可以根据自己的情况,使用 JMH 进行测试。测试代码和版本在 DEMO 中提供。
总结
得益于 Java 社区的发展以及前辈们的贡献,目前写一个 RPC 框架并不是很难。但是作为一个 RPC 框架,需要在可维护性的基础上,尽可能提高自身性能,将在实际过程中遇到的一些场景和异常情况进行修复和优化,并进行更好的代码设计和实现。对于性能上的数据,可以多使用 JMH 并结合实际业务场景,进行相应的测试。
最后感谢大家,今天的 SOFA Channel 直播到此结束。下期我们将在本月28号与大家见面, SOFARPC 性能优化(下),我们会带来关于线程池隔离,Server Fail Fast,内存操作优化,用户可调节参数等方面的介绍。
大家可以点击阅读原文或者链接进行报名。
https://tech.antfin.com/activities/245?chInfo=wx
相关链接
视频回放也给你准备好啦:
https://tech.antfin.com/activities/244
相关参考链接:
DEMO 链接:
https://github.com/leizhiyuan/rpcchannel
SOFARPC:
https://github.com/alipay/sofa-rpc
SOFARPC 源码解析系列 (点击【剖析 | SOFARPC 框架】即可查看)
https://www.sofastack.tech/posts
SOFABolt 源码解析系列 (点击【剖析 | SOFABOLT 框架】即可查看)
https://www.sofastack.tech/posts
TCP man:
https://linux.die.net/man/7/tcp
FAST OPEN :
https://tools.ietf.org/html/rfc7413
netty :
https://netty.io/news/2015/09/30/4-0-32-Final.html
jvm-serializers:
https://github.com/eishay/jvm-serializers/wiki
半连接 :
https://www.cnxct.com/something-about-phpfpm-s-backlog/
SYN Flood :
https://zh.wikipedia.org/wiki/SYN_flood
讲师观点
长按关注,不错过每一场技术直播
欢迎大家共同打造 SOFAStack https://github.com/alipay
以上是关于SOFARPC 性能优化实践(上)| SOFAChannel#2 直播整理的主要内容,如果未能解决你的问题,请参考以下文章
开源 | SOFARPC 集成 ZooKeeper 注册中心