PYNQ中RPC机制是如何实现的
Posted Python开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PYNQ中RPC机制是如何实现的相关的知识,希望对你有一定的参考价值。
作者|IEEE1364
https://zhuanlan.zhihu.com/p/59125477
引子
我在《PYNQ中MicroBlaze程序是如何加载的》一文中详细讲述了PYNQ中MicroBlaze的程序是如何通过python被加载到PL端的。并且在《在PYNQ中调用MicroBlaze的实现过程》中详细讲述了如何在SDK中开发MicroBlaze程序,生成bit文件在通过Python加载的过程。
但是终究来说这一过程异常复杂,开发过程繁琐。
在github.com/Xilinx/PYNQ/中有这样一段特殊代码
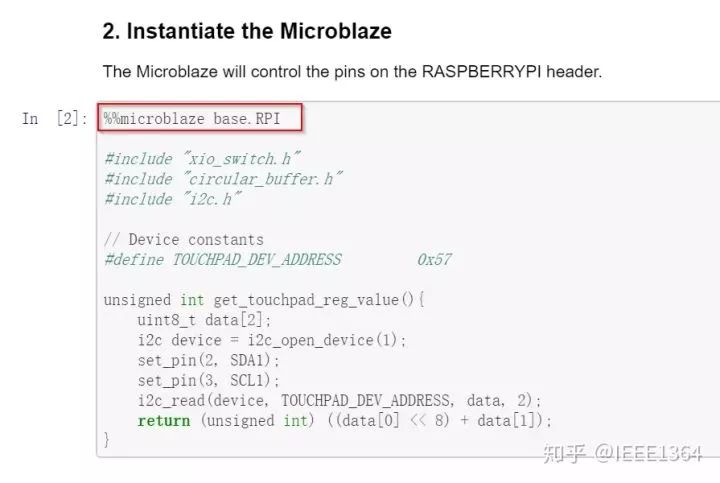
实现了在Jupyter里面直接插入Microblaze的C语言代码并执行,这个操作很骚啊。
这种操作方法异常简洁方便。这一切又是如何魔幻般地实现的呢?
 一、RPC机制
一、RPC机制
RPC(Remote Procedure Call,远程过程调用)机制在PYNQ的文档里面有简单介绍。
PYNQ的Microblaze的基础是构建在远程过程调用(RPC)层之上,RPC层负责将函数调用从Python环境转发到Microblaze并处理所有数据传输。
二、RPC的实现过程
在jupyter中可以使用魔法命令实现很多特殊功能。具体请看《Jupyter Notebook 常用魔法命令》
本文开始提到的代码中的%%就是jupyter的魔法命令,并且表示这个cell里面所有语句都属于魔法命令。
%%microblaze base.RPI
那么microblaze魔法命里到底是指什么呢?我们要看 /pynq/lib/pynqmicroblaze/magic.py 文件中MicroblazeMagics相关代码。
@magics_class
class MicroblazeMagics(Magics):
def name2obj(self, name):
_proxy = _DataHolder()
exec("_proxy.obj = {}".format(name), locals(), self.shell.user_ns)
return _proxy.obj
@cell_magic
def microblaze(self, line, cell):
mb_info = self.name2obj(line)
try:
program = MicroblazeRPC(mb_info, '#line 1 "cell_magic" ' + cell)
except RuntimeError as r:
return html("<pre>Compile FAILED " + r.args[0] + "</pre>")
for name, adapter in program.visitor.functions.items():
if adapter.filename == "cell_magic":
self.shell.user_ns.update(
{name: _FunctionWrapper(getattr(program, name), program)})
可以看到里面调用了MicroblazeRPC这个类的函数,并将整个cell里面的代码作为参数传递进去。所以我们要跳到/pynq/lib/pynqmicroblaze/rpc.py文件,去查看该函数,为了简洁,我们只提取出核心部分。
class MicroblazeRPC:
def __init__(self, iop, program_text):
preprocessed = preprocess(program_text, mb_info=iop)
try:
ast = _parser.parse(preprocessed, filename='program_text')
except ParseError as e:
raise RuntimeError("Error parsing code " + str(e))
visitor = FuncDefVisitor()
visitor.visit(ast)
main_text = _build_main(program_text, visitor.functions)
used_typedefs = _filter_typedefs(visitor.typedefs,
visitor.functions.keys())
typedef_classes = _create_typedef_classes(visitor.typedefs)
self._mb = MicroblazeProgram(iop, main_text)
self._rpc_stream = InterruptMBStream(
self._mb, read_offset=0xFC00, write_offset=0xF800)
MicroblazeRPC这个类为RPC机制提供了一个python接口。
将我们看到的C语言代码传入到preprocess这个函数,进行了一些处理,然后又将这段代码加入到一个main函数里面好像(_build_main)。然后将得到的文本传入到MicroblazeProgram这个函数。函数preprocess和MicroblazeProgram都在文件/pynqmicroblaze/compile.py里面。
我们就打开这个文件看看MicroblazeProgram这个函数:
MicroblazeProgram这个函数挺复杂的,很多细节看不懂,分析和猜测应该就是讲源码文件编译成bitstream文件,再通过InterruptMBStream函数不知道怎么搞了一下就写入了,这个类里面又启用了父类调用机制,在父类SimpleMBStream里面使用write_channel函数将bit流文件写入了到了内存里面了。
class SimpleMBStream:
def __init__(self, iop, read_offset=0xF400, write_offset=0xF000):
self.read_channel = SimpleMBChannel(iop.mmio.mem, offset=read_offset,
length=0x400)
self.write_channel = SimpleMBChannel(iop.mmio.mem, offset=write_offset,
length=0x400)
所以总结来说,RPC的实现机制就是,在jupyter里面使用魔法命里插入C语言代码,再使用Python来补齐main函数部分并编译成二进制文件,最后通过AXI总写写入到MicroBlaze的双端口RAM里面去执行。
当然RPC使用还有一些限制,请看PYNQ文档。
后记
RPC机制可以非常方便地进行MicroBlaze调试。但是其实现过程比较复杂,中间很多细节还没有搞清楚,有需要的读者可以继续研究。
推荐↓↓↓
长
按
关
注
以上是关于PYNQ中RPC机制是如何实现的的主要内容,如果未能解决你的问题,请参考以下文章