串烧RPC
Posted 寒剑的码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了串烧RPC相关的知识,希望对你有一定的参考价值。
前两篇关于RPC的文章中,我们介绍了
以及相关的内容,相信大家对于RPC已经有了比较多的了解,本章我们聊聊RPC中的注册中心,因为目前注册中心用的最为普遍的就是ZooKeeper了,所以我们主要来一起了解下关于ZooKeeper的相关知识点。
先来看本章的提纲
第一部分,我们再讲一下Paxos算法的一些实现
通过前两篇文章的介绍,我们知道在解决分布式数据一致性的过程中,涌现了很多杰出的思想和协议,最开始的2PC协议虽然可以保证遵循ACID,最大限度确保了数据的一致性,但是也暴露了其整个执行过程中完全串行阻塞以及脑裂的问题。3PC创造性的将2PC的第一阶段又分成了两个阶段,解决了阻塞的问题以及单点的问题,但是同样暴露了参与者超时后自动提交事务在某些场景下会产生数据不一致的问题,所以才有了Paxos的出现,Paxos也是目前公认的解决分布式数据一致性问题最有效的方法。
关于Paxos的来源以及演变,我们不做过多介绍,大家可以自己百度上搜索,可谓一波三折,该算法是由莱斯利于1990首先提出的,经过不同的前辈抽象后,该算法可以通过三个参与方来描述。
proposer,负责发起提案
acceptor,负责接受proposer发起的提案,并决定接受哪一个提案
learner,获取被acceptor接受的提案
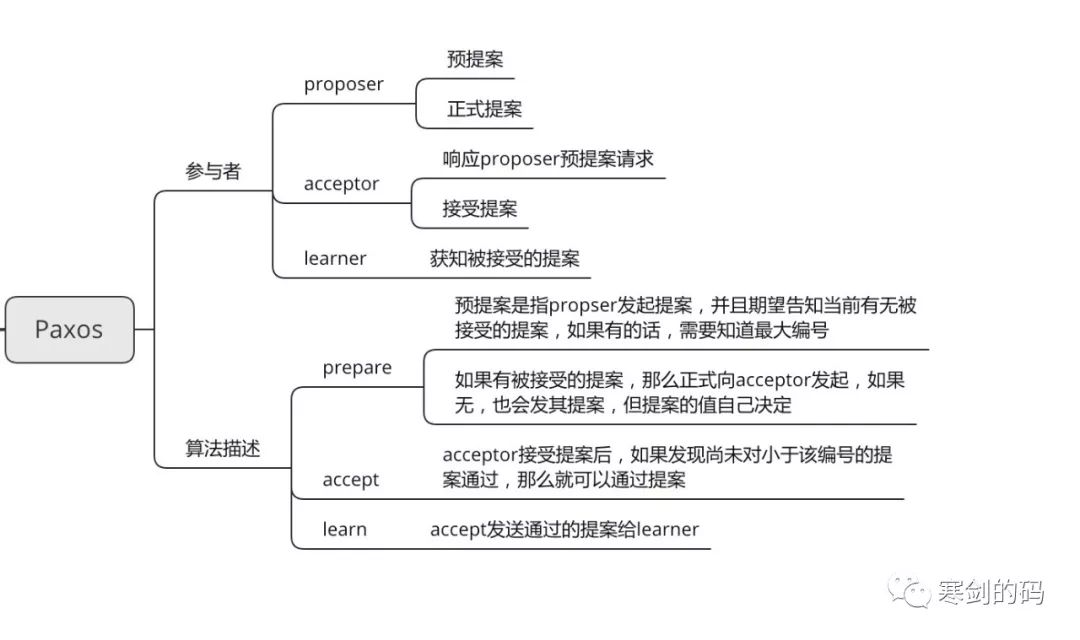
上图是关于paxos算法的一些基本概念和算法描述,大家可以了解下,关于算法描述,尝试画了一个时序图。
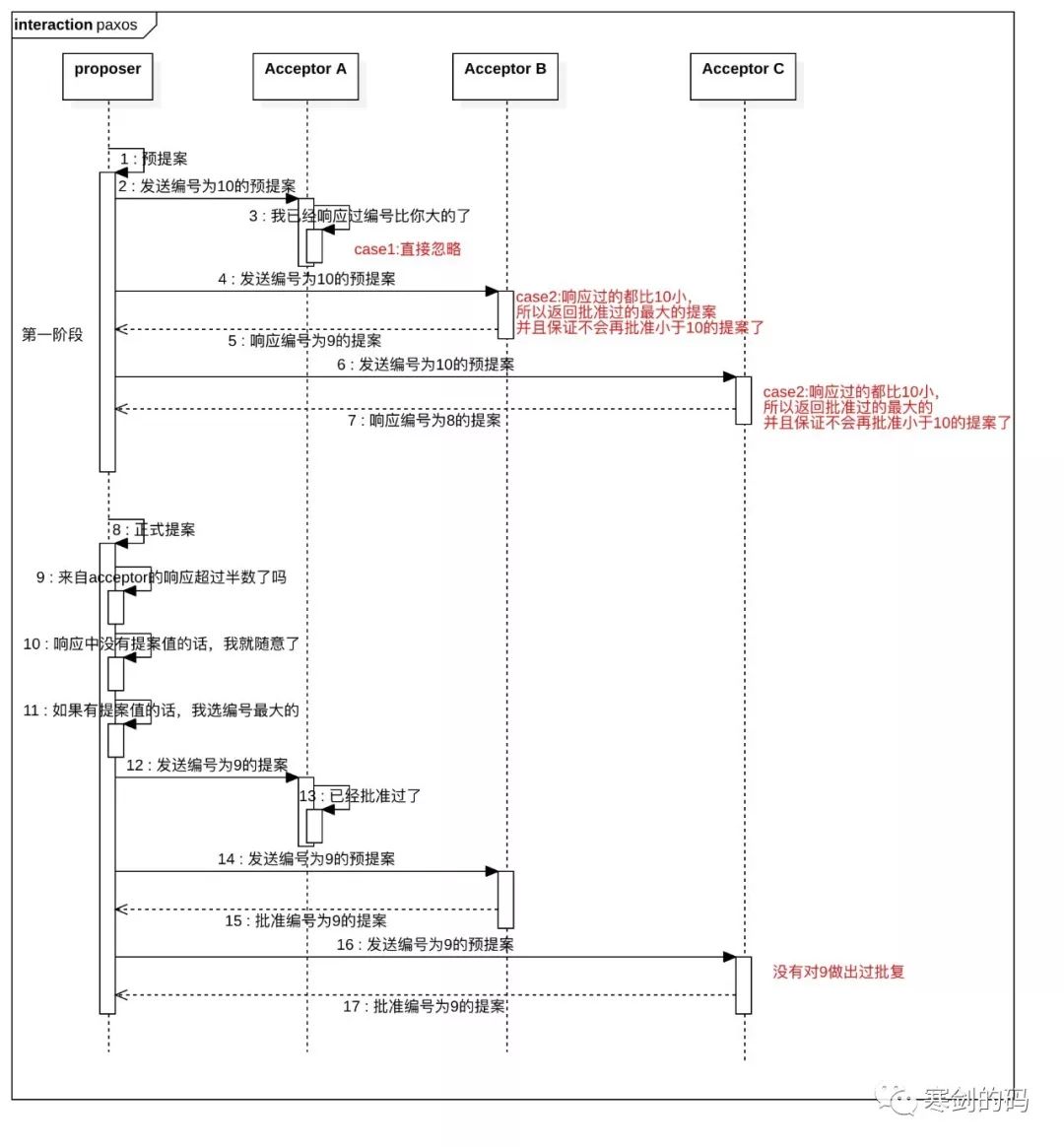
在算法内部,其复杂性远比这个图描述的要高,例如参与提案的不会只有一个proposer,同一个accepter也会接受多个提案的请求,并在多个提案中按照算法的规则选取一个进行批复,下面我们用文字的形式对算法进行描述,大家可以结合时序图进行理解。
阶段一
(1)Proposer选择一个提案编号,时序图中是10,然后向Acceptor的超过半数的子集成员发送编号为10的prepare请求,这里个人理解可以广播发送,但是并不要求每个Acceptor都做出响应,只要超过半数就可以了。
(2)如果一个Acceptor收到请求后,发现编号是10的请求比之前响应过的请求编号都大,那么它就会将已批准过的(千万注意,是已批准过的)最大编号提案作为响应反馈给Proposer,同时保证它自己不再批准任何小于编号为10的提案,这里还需要注意,算法的提案的结构,可以理解为一个kv格式,这里编号是key,但是value的话,可以为空,表示广大acceptor还没有作出决定,打个比方,领导让组内成员提议团建干什么,有的人提议去KTV,有的人提议去聚餐,但是具体到哪里唱歌,到哪里聚餐,可以下一步再定。这个例子可能不太恰当,paxos算法理解起来确实有些困难。
阶段二
(1)Proposer收到来自半数以上的响应时,那么就会发送一个kv请求给acceptor,value的值就是来自所有响应中编号最大的值,如果没有的话,那就是proposer自己定,就比如第一阶段,如果我们定了去聚餐,但是acceptor还没有定具体去哪里时,我们自己就可以选一个地方作为建议
(2)acceptor收到accept请求后,如果它自己还没有对编号大于10的请求作出响应,那它就可以通过这个提案。
上面的时序中,我们少画了learner的指责,对于一个一致性算法来说,需要保证当结果确定后,进程可以获取到,所以learner的指责就在于获取被通过的提案。
讲到这里,大家对于paxos算法会有一个比较形象的了解了,对于该算法,其实我们不必太深究内部实现,我们可以通过开源的实践来了解。
那么第二部分,我们就了解下Zookeeper的知识点
Zookeeper是Apache Hadoop下的顶级项目,其为分布式应用提供了可靠的分布式协调服务,例如一些RPC和MQ就选择ZK作为服务治理的中间件,需要知道的是ZK没有直接使用paxos算法,而是采用了被称为ZAB的一致性协议。
先说一个比较有意思的,ZooKeeper名字的由来。zk最早起源于雅虎研究院的一个研究小组,在项目立项之初,大家发现很多项目都是用动物的名字命名的,例如著名的pig项目等,这时候有人就说这样下去,我们这里就成动物园了,而恰好ZK的设计目标就是为各个组件提供分布式服务,所以索性就叫动物管理员-Zookeeper。
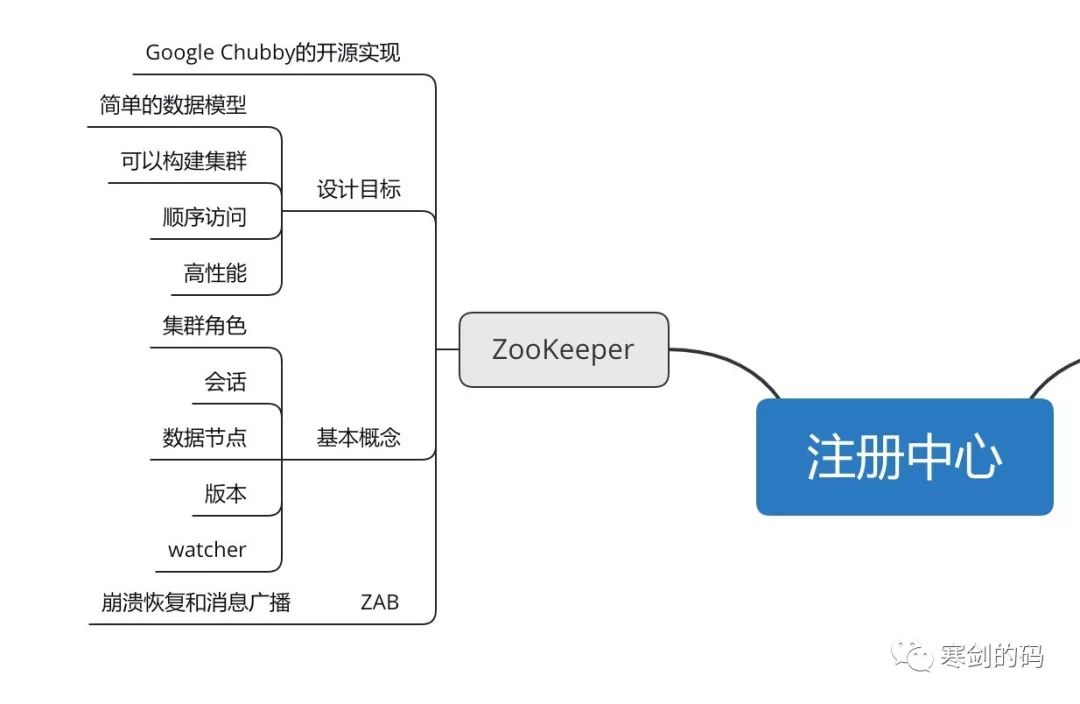
对于ZAB协议,我们不计划在此做介绍,大家有兴趣的话,可以自行找资料学习,我们着重对其他知识点进行介绍。
ZK安装与使用
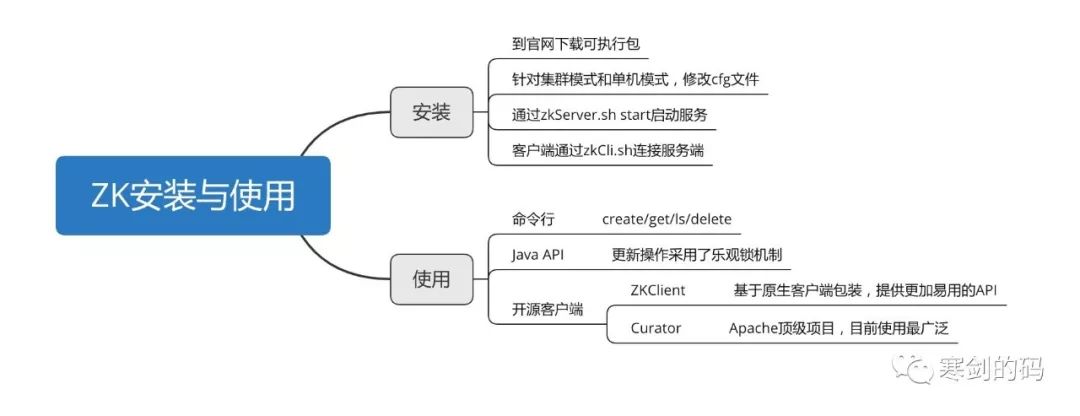
安装过程,我们不做过多介绍,需要注意的一点是注意区分源码文件和可执行文件,我们需要下载的是可执行文件,这样解压后,才可以直接用自带sh工具进行start和stop,否则会报错。
当正确安装与启动后,我们在服务端会看到如下的状态。
通过客户端连接后,会看到如下状态。
然后我们就可以在客户端模式下,对ZK进行操作了。
关于Java客户端的使用,在此也不做过多介绍,毕竟我们日常工作中,直接使用原生Java客户端进行ZK操作的场景也是不多的,有一个细节是使用Java原生客户端进行ZK节点更新时,其实是使用了类似乐观锁的version机制,来保证数据一致性的。
而在开源的ZK客户端中,目前Curator是最流行的框架,其提供Fluent风格的API极大方便了我们对zk的操作。
package com.jing.learn.zk;import org.apache.curator.RetryPolicy;import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.retry.ExponentialBackoffRetry;import org.apache.zookeeper.CreateMode;import org.apache.zookeeper.data.Stat;/*** @author wangjingjing* Curator 基础使用*/public class CreateSample {static String path = "/rpc/order_";public static void main(String[] args) {try {/*** 创建重试策略* baseSleepTimeMs 最大sleep时间,内部维护每次重试的sleep时间,* 如果在最大休眠时间内,则使用计算值* 如果不在最大休眠时间内,则使用最大休眠值** maxRetries 最大重试次数*/RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3);/*** 自带Fluent风格,方便使用*/CuratorFramework client = CuratorFrameworkFactory.builder().connectString("localhost:2181").connectionTimeoutMs(3000).sessionTimeoutMs(5000).retryPolicy(retryPolicy).namespace("zk-study").build();client.start();//创建节点client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path,"init".getBytes());Stat stat = new Stat();//读取数据,传入version,类似乐观锁机制System.out.println(new String(client.getData().storingStatIn(stat).forPath(path)));//更新数据client.setData().withVersion(stat.getVersion()).forPath(path);//删除节点client.getData().storingStatIn(stat).forPath(path);client.delete().deletingChildrenIfNeeded().withVersion(stat.getVersion()).forPath(path);} catch (Exception e){e.printStackTrace();}}}
此外,Curator还提供了诸如异步,节点监听,master选举,分布式锁,分布式Barrier等多种有意思的工具,大家有兴趣的话,可以看看Curator的源码,很有借鉴意义。
下面,我们从实际场景出发,介绍几种通过ZK解决的问题。
我们都知道ZK是一个典型的发布/订阅模式的分布式数据管理与协调框架,pub/sub其实是相对于另一种模式-点对点而言的,所以一方面可以用来做分布式数据的发布与订阅。另一方面,ZK作为数据管理框架,配合watcher事件通知机制,可以构建一系列分布式场景中的核心功能,例如软负载/namespace服务/分布式协调通知/集群管理/分布式锁/分布式队列等。
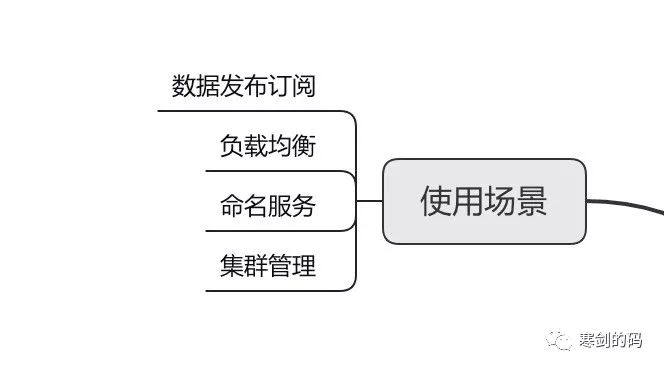
数据发布订阅
ZK作为发布/订阅模型的分布式框架,可以将数据发送到一个或一系列节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和数据的动态更新。需要注意的是ZK采取的推拉结合的方式,push和pull这两种方式各有利弊,例如Kafka的客户端就是采用pull模式的,而ZK则是客户端向服务端注册自己需要关注的节点,一旦该节点的数据发生变更,服务端就会发送watcher事件通知,客户端接到通知后,需要主动去服务端获取最新的数据。
如果将配置信息放到ZK上进行管理,那么通常情况下,应用在启动初始化的时候,就会主动到ZK上进行一次配置信息的获取,同时在指定节点上注册一个watch监听。
目前市面上配置中心的框架是比较多的,阿里内部有Diamond,另外Spring也提供了自己的配置中心,其他的像XDiamond,就是利用ZK的发布订阅模式来处理数据的,关于配置中心的知识点,我们后面会专门展开讨论。
负载均衡
负载均衡这个词,我们听了无数遍,本质上是通过一定的算法,进行资源访问优化的网络技术,通常分为硬件负载和软件负载,使用zk可以实现软负载的功能。
上面的方式是服务消费方的SDK实现负载均衡策略,再优化一点可以将负载均衡的策略与消费方SDK剥离,专门提供对接ZK的客户端,然后在这个中间层做负载均衡策略,而消费方的SDK只需要关注寻址就可以了。
生成全局唯一ID
在Zookeeper中,每一个数据节点都能够维护一份字节点的顺序序列,当客户端对其创建一个顺序子节点的时候ZK会自动以后缀的形式在其子节点上添加一个序号。
可以参考我们前面贴出的利用Curator创建节点的例子,在调用create方法后,我们通过客户端命令行,可以看到最终会创建order_*格式的节点。
集群管理
利用ZK的watcher监控,可以通过Agent+ZK的模式,对集群内主机进行上下线监控和日常监控。将Agent部署在各个服务器上,然后服务器启动时,通过Agent向ZK中创建节点,然后对这些节点添加监控。当服务器下线或者健康状态变更时,Agent可以操作ZK上的节点,进而通过ZK动态的体现整个集群的信息。
除此之外,ZK还可以用作分布式锁,分布式队列,就不再详细介绍了,大家可以在网上搜索相关的使用方法,或者在工作中针对具体的案例去case by case的使用ZK,总之ZK通过ZAB协议,提供了数据一致性的解决方案,同时由于其在分布式数据管理以及发布订阅方面的特性,我们就可以利用这两个特性来解决我们的实际问题,后续我们会专门针对ZK讨论每个场景的使用方法。
通过上面的一些介绍,大家就可以理解为什么RPC框架中的注册中心,会选择ZK作为中间件了,因为其可以提供诸如负载均衡,命名服务,状态通知等功能,最为关键的,可以保证数据一致性。
好了,以上就是一些关于ZooKeeper的知识点,写的比较粗,因为涉及到ZooKeeper的知识点实在太多了,除去我们前面介绍的知识,ZooKeeper在实现上的一些细节,我们还没有讲到,这个也会在后续补上,欢迎大家持续关注。
下一篇中,我们将一起聊聊RPC中负载均衡的一些相关知识点。
以上是关于串烧RPC的主要内容,如果未能解决你的问题,请参考以下文章