RPC 原理以及开源 RPC 协议 thrift 源码解析
Posted 小脑斧科技博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RPC 原理以及开源 RPC 协议 thrift 源码解析相关的知识,希望对你有一定的参考价值。
1. 引言
无论是什么语言、什么规模的代码项目,总是需要进行代码间的相互调用,而在企业中,大型项目通常都是多人甚至多团队合作完成的,此时,项目会被拆分为多个内聚的模块独立进行开发,但模块间的项目调用是必不可少的。
那么,如何进行多个模块间的相互调用呢?最通用和简单的模式莫过于通过 http 协议来进行调用,接口提供者与接口调用者共同协商一套规范,然后双方按照预定规范来进行独立开发即可。
在上述交互模式的开发过程中,存在哪些问题呢?
本文我们就来详细介绍一下 http 协议在实际使用中存在的问题,从而说明 rpc 存在的必要性,主页君本文先来详细说明 rpc 的一般性设计思想与构建原理,接着以跨语言的开源 RPC 协议 thrift 来说明 RPC 构建的实例。
2. http 协议作为接口协议存在的问题
2.1. 协议的表达能力
http 协议规定了正常 code 200 与一些预定义好的异常 code,然而,在实际使用过程中,接口提供者通常需要表达更为复杂的异常信息,例如参数异常、数据库异常或是网络异常等,这是原生的 http 协议规范中所不存在的信息。
同时,http 协议是基于文本的传输协议,而实际上,我们的接口在设计和使用过程中,简单的字符串通常是无法满足我们的需求的。
2.2. 序列化与反序列化
由于 http 协议表达能力的不足,我们需要将我们接口所要提供的复杂的数据结构转换成 http 协议可以传输的文本结构,这就是序列化过程,而传输到对端后,对端需要将文本进行还原,以便拿到所需要的数据结构中的各项数据,这就是反序列化过程。
那究竟应该序列化成什么样的数据交换格式呢?常用的有 json、xml 等,json 虽然结构简单,便于阅读理解,但由于 json 本身只能区分数据的字符串和数字、浮点型三种类型,其表达能力又显得不足,如果冗余类型字段用于说明数据的类型,那么他优于 xml 的轻量、结构清晰、简洁的优势又不存在了,而相比较,xml 就显得结构非常复杂了。
同时,优于各种描述信息的加入,实际传输的字符串长度增长也是十分显著的,这都是显而易见的问题所在。
2.3. 协议的规范化
有了上述 http 协议、json 或 xml 的传输解决方案,看上去已经可以解决服务间相互调用的,但实际上,这其中还存在着另外的两个重大的问题:
每一个接口提供者和每一个接口使用者都需要实现一套复杂而庞大的序列化、反序列化代码
传输协议难以被限制
显然,无论采用 json 还是 xml,我们都没有办法在通信结束前限制使用者的参数与接口提供者的返回数据。
例如,必须参数的缺失应该在通信开始前提示调用者,并且中止这次不必要的通信,而更为严重的,作为调用者,在反序列化的过程中,无法预先感知收到的字符串是否可以反序列化,反序列化后的必须字段是否有缺失,类型是否正确等,如果要实现这一系列的校验,对于调用者而言,其工作量显然是无法接受的。
2.4. 协议以外的问题
除了上述使用 http 协议进行服务间调用存在的问题之外,使用 http 协议进行通信还存在一些额外的问题,也就是在此之上后期扩展的复杂性。
2.4.1. 运维困难
http 协议通常依赖 DNS 域名转发、nginx 负载均衡等方式实现多个提供者的负载均衡工作,原生的 nginx 很难让你实现高度定制化,虽然结合 lua 脚本可以实现定制化功能,但 lua 脚本的开发和维护又产生了新的工作量,而 DNS 本身又存在被篡改和攻击的风险。
2.4.2. 可扩展性差
一些额外的功能,例如对链路的监控、灰度部署等常见场景下,依赖于 http 协议的通信架构都很难满足。
3. 什么是 RPC
针对 HTTP 协议进行服务间通信的上述种种不足,RPC 协议诞生了,他是“Implementing Remote Procedure Calls”的缩写。
他的全部内容可以参看:
http://birrell.org/andrew/papers/ImplementingRPC.pdf。
总结起来,这种通信方式具有以下特点:
简单:RPC 概念的语义十分清晰和简单,这样建立分布式计算就更容易
高效:过程调用看起来十分简单而且高效
通用:在单机计算中过程往往是不同算法部分间最重要的通信机制
他的主导思想是将远程调用转变成所有程序员都十分熟悉的本地方法调用,由中间层负责整个通信过程的各项校验、编码、解码、序列化、反序列化等工作,让开发者可以集中全部精力于自己的项目中。
4. RPC 的组成
那么,如何才能做到将一个远程服务变成一个方便调用的本地服务呢?
在上述论文中,提到了解决方案,在整个通信链路上,存在以下五个部分:
user — 发起远程调用的 client 端,他调用本地的下一个成员 — user_stub
user_stub — user_stub 负责对协议中需要传输的具体内容进行校验、序列化、编码等步骤,编码为易于传输的字节流格式,以及将服务端传输来的字节流通过解码、反序列化、校验等工作还原为易于本地使用的结构化数据
RPCRuntime — RPCRuntime 承担了整个过程中的通信和传输的任务
server_stub — 与 user_stub 类似,server_stub 位于服务提供者本地,负责将需要传输的内容进行校验、序列化、编码等步骤转换为已与传输的字节流格式,以及将客户端传输来的字节流通过解码、反序列化、校验等工作还原为本地易于使用的结构化数据
server — server 与 user 的地位是一致的,他负责代理 server_stub,实现用户易于使用的 api,提供远程接口服务
经过 30 多年的发展,RPC 的整体设计架构在上述五个组成部分的基础上进行了一定的扩充,但核心仍然是上述论文中描述的整体架构。
5. RPC 的优势与不足
5.1. 优势
通过上述介绍,RPC 最大的优势在于其使用的友好性,他将远程调用转换为本地调用,在提供强大的远程调用能力的同时不损失本地调用的语义简洁性。
让分布式系统的构建更为方便快捷,省去了业务程序员大量编解码、序列化反序列化、数据校验等的工作,让整个交互过程在业务的层面上更为可靠。
同时,上述论文中只是介绍了 RPC 的基本组成,对于通信协议、编码方式等均没有严格规定,这就给实现者以充分的自由来自定义,例如在传输数据量最小化上进行协议的优化,在安全性上增添补充协议等。
而由于整个 RPC 框架为统一实现,对于整个传输过程、编解码、序列化与反序列化、参数校验等流程都可以实现充分的定制化工作,为进一步扩展,如充分的监控、报警、动态扩容等工作预留了极大地便利性。
5.2. 不足
RPC 的不足也是显而易见的,由于其将远程调用转化为程序本地调用,因此在跨语言调用时天生存在问题,那就是如何在两个语言之间描述各自本地化的接口。
这让很多 RPC 框架都局限于单一语言内实现,这样由于接口提供方与接口调用方使用相同的语言,可以方便的使用相同的一套接口定义进行接口的描述。
其他跨语言版本的 RPC,例如 thrift、grpc 等 RPC 协议都提供了类似伪代码声明接口的 IDL 接口描述协议,但这无疑额外引入了一定的学习成本,另一方面,对于不同的语言,都要实现单独的 user、user_stub、server、server_stub、RPCRuntime 来本地化接口以及实现网络传输,开发和维护需要大量的人力,而同时,新语言被广泛使用前,也很难得到官方为他量身打造的一套 SDK。
6. thrift 简介
thrift 是 apahce 公司设计和维护的一套非常流行的开源 RPC 框架。
可以参看官方文档:
http://thrift.apache.org/
主页君下一篇文章将详细介绍了 thrift 的基本使用
本文,我们结合相关的源码,介绍一下 thrift 的工作原理。
7. thirft -gen — user & server
7.1. idl 与 thrift gen
thrift 是我们上文所提到的跨语言 RPC 协议,它是通过 IDL 接口描述协议来声明接口的。
我们首先需要定义 idl 文件,我们定义一个最为简单的 service:
service DemoService {
string say(1:string params)
}然后我们执行:
thrift -gen py demo.thrift
生成了 gen-py 目录,在 gen-py/demo 路径下,存在一个文件 — DemoService.py,这个文件就包含了 RPC 架构中 user 与 server 两个角色。
7.2. DemoService.py 源码分析
#
# Autogenerated by Thrift Compiler (0.9.1)
#
# DO NOT EDIT UNLESS YOU ARE SURE THAT YOU KNOW WHAT YOU ARE DOING
#
# options string: py
#
from thrift.Thrift import TType, TMessageType, TException, TApplicationException
from ttypes import *
from thrift.Thrift import TProcessor
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol, TProtocol
try:
from thrift.protocol import fastbinary
except:
fastbinary = None
class Iface:
def say(self, params):
"""
Parameters:
- params
"""
pass
class Client(Iface):
def __init__(self, iprot, oprot=None):
self._iprot = self._oprot = iprot
if oprot is not None:
self._oprot = oprot
self._seqid = 0
def say(self, params):
"""
Parameters:
- params
"""
self.send_say(params)
return self.recv_say()
def send_say(self, params):
self._oprot.writeMessageBegin('say', TMessageType.CALL, self._seqid)
args = say_args()
args.params = params
args.write(self._oprot)
self._oprot.writeMessageEnd()
self._oprot.trans.flush()
def recv_say(self):
(fname, mtype, rseqid) = self._iprot.readMessageBegin()
if mtype == TMessageType.EXCEPTION:
x = TApplicationException()
x.read(self._iprot)
self._iprot.readMessageEnd()
raise x
result = say_result()
result.read(self._iprot)
self._iprot.readMessageEnd()
if result.success is not None:
return result.success
raise TApplicationException(TApplicationException.MISSING_RESULT, "say failed: unknown result");
class Processor(Iface, TProcessor):
def __init__(self, handler):
self._handler = handler
self._processMap = {}
self._processMap["say"] = Processor.process_say
def process(self, iprot, oprot):
(name, type, seqid) = iprot.readMessageBegin()
if name not in self._processMap:
iprot.skip(TType.STRUCT)
iprot.readMessageEnd()
x = TApplicationException(TApplicationException.UNKNOWN_METHOD, 'Unknown function %s' % (name))
oprot.writeMessageBegin(name, TMessageType.EXCEPTION, seqid)
x.write(oprot)
oprot.writeMessageEnd()
oprot.trans.flush()
return
else:
self._processMap[name](self, seqid, iprot, oprot)
return True
def process_say(self, seqid, iprot, oprot):
args = say_args()
args.read(iprot)
iprot.readMessageEnd()
result = say_result()
result.success = self._handler.say(args.params)
oprot.writeMessageBegin("say", TMessageType.REPLY, seqid)
result.write(oprot)
oprot.writeMessageEnd()
oprot.trans.flush()
# HELPER FUNCTIONS AND STRUCTURES
class say_args:
"""
Attributes:
- params
"""
thrift_spec = (
None, # 0
(1, TType.STRING, 'params', None, None, ), # 1
)
def __init__(self, params=None,):
self.params = params
def read(self, iprot):
if iprot.__class__ == TBinaryProtocol.TBinaryProtocolAccelerated and isinstance(iprot.trans, TTransport.CReadableTransport) and self.thrift_spec is not None and fastbinary is not None:
fastbinary.decode_binary(self, iprot.trans, (self.__class__, self.thrift_spec))
return
iprot.readStructBegin()
while True:
(fname, ftype, fid) = iprot.readFieldBegin()
if ftype == TType.STOP:
break
if fid == 1:
if ftype == TType.STRING:
self.params = iprot.readString();
else:
iprot.skip(ftype)
else:
iprot.skip(ftype)
iprot.readFieldEnd()
iprot.readStructEnd()
def write(self, oprot):
if oprot.__class__ == TBinaryProtocol.TBinaryProtocolAccelerated and self.thrift_spec is not None and fastbinary is not None:
oprot.trans.write(fastbinary.encode_binary(self, (self.__class__, self.thrift_spec)))
return
oprot.writeStructBegin('say_args')
if self.params is not None:
oprot.writeFieldBegin('params', TType.STRING, 1)
oprot.writeString(self.params)
oprot.writeFieldEnd()
oprot.writeFieldStop()
oprot.writeStructEnd()
def validate(self):
return
def __repr__(self):
L = ['%s=%r' % (key, value)
for key, value in self.__dict__.iteritems()]
return '%s(%s)' % (self.__class__.__name__, ', '.join(L))
def __eq__(self, other):
return isinstance(other, self.__class__) and self.__dict__ == other.__dict__
def __ne__(self, other):
return not (self == other)
class say_result:
"""
Attributes:
- success
"""
thrift_spec = (
(0, TType.STRING, 'success', None, None, ), # 0
)
def __init__(self, success=None,):
self.success = success
def read(self, iprot):
if iprot.__class__ == TBinaryProtocol.TBinaryProtocolAccelerated and isinstance(iprot.trans, TTransport.CReadableTransport) and self.thrift_spec is not None and fastbinary is not None:
fastbinary.decode_binary(self, iprot.trans, (self.__class__, self.thrift_spec))
return
iprot.readStructBegin()
while True:
(fname, ftype, fid) = iprot.readFieldBegin()
if ftype == TType.STOP:
break
if fid == 0:
if ftype == TType.STRING:
self.success = iprot.readString();
else:
iprot.skip(ftype)
else:
iprot.skip(ftype)
iprot.readFieldEnd()
iprot.readStructEnd()
def write(self, oprot):
if oprot.__class__ == TBinaryProtocol.TBinaryProtocolAccelerated and self.thrift_spec is not None and fastbinary is not None:
oprot.trans.write(fastbinary.encode_binary(self, (self.__class__, self.thrift_spec)))
return
oprot.writeStructBegin('say_result')
if self.success is not None:
oprot.writeFieldBegin('success', TType.STRING, 0)
oprot.writeString(self.success)
oprot.writeFieldEnd()
oprot.writeFieldStop()
oprot.writeStructEnd()
def validate(self):
return
def __repr__(self):
L = ['%s=%r' % (key, value)
for key, value in self.__dict__.iteritems()]
return '%s(%s)' % (self.__class__.__name__, ', '.join(L))
def __eq__(self, other):
return isinstance(other, self.__class__) and self.__dict__ == other.__dict__
def __ne__(self, other):
return not (self == other)我们看到,这个文件中定义了以下五个类:
Iface — 类似于其他面向对象语言中的 abstract 类,定义了未被实现的接口,对于 server 端来说,需要创建该类的子类并实现所有方法,从而实现接口的完整实现,这就是上述 RPC 架构中的 server 角色
Client — Iface 的子类,RPC 框架中的 user 角色,客户端直接调用该类中的对应方法就可以实现对远程接口的调用,可以看到 Client 中对应接口的方法 say 实际是对 send_say 与 recv_say 两个成员方法的封装,而这两个成员方法实际上调用了 Protocol 类中的相应方法,至于 Protocol 又是什么,别急,下文我们就会详细来介绍了
Processor — RPC 架构中 server 角色的一个组成部分,用于将以实现 Iface 中全部接口的 Handler 类注册到 RPC 执行过程中,他所具备的 process 方法通过调用 Protocol 类中相应的方法实现数据的获取
say_args — Processer 中 process_say 调用的用来对参数进行编码、解码的方法,他是通过封装调用 TBinaryProtocol 中的各个方法实现的
say_result — 与 say_args 非常类似,也是通过调用 TBinaryProtocol 中各方法实现了对返回参数编码与解码工作
8. Protocol — user_stub & server_stub
通过上文的讲解,我们已经看到,thrift 通过 thrift 命令的 -gen 参数自动生成了各语言本地的 user 与 server 模块的代码。
在 user 与 server 中,分别调用了 Protocol 类中的 read 和 write 系列方法,实现了本地结构化数据的读写。
Protocol 就是扮演了 RPC 框架中的 user-stub 与 server-stub 层的角色,write 系列操作负责将数据通过序列化、编码等操作转换为便于传输的数据格式,而与之相对的,read 系列方法则负责将接收到的数据还原为语言本地结构化数据。
thrift 规范中定义了下面几种编码协议的 Protocol 实现:
TBinaryProtocol — 编码为二进制编码格式数据进行传输
TCompactProtocol — 编码为高效率的、密集的二进制编码格式进行数据传输
TJSONProtocol — 编码为 Json 数据编码协议进行传输
他们的 python 实现源码可以参看:
https://github.com/apache/thrift/tree/master/lib/py/src/protocol。
他们都继承自 TProtocolBase 类,实现了 TProtocolBase 类中定义的一系列方法 — 主要包含 readXXX 系列方法与 writeXXX 系列方法,其中 XXX 包含了 Bool、Byte、I16、I32、Double、String 等 thrift 所支持的固定长度或可推断长度的类型。
而对于 List、Map、Struct、Message 等非固定长度的类型则定义了 readXXXBegin、readXXXEnd 与 writeXXXBegin、writeXXXEnd 系列方法用来在整个结构读写开始和完成的时候进行一些必要的工作,但正如我们上面在源码中看到的,在 user-stub 与 server-stub 中。
对于数据的读取,实际调用的是 Protocol 类中的 skip 方法,下面是在 TProtocolBase 类中 skip 方法的实现:
def skip(self, ttype):
if ttype == TType.BOOL:
self.readBool()
elif ttype == TType.BYTE:
self.readByte()
elif ttype == TType.I16:
self.readI16()
elif ttype == TType.I32:
self.readI32()
elif ttype == TType.I64:
self.readI64()
elif ttype == TType.DOUBLE:
self.readDouble()
elif ttype == TType.STRING:
self.readString()
elif ttype == TType.STRUCT:
name = self.readStructBegin()
while True:
(name, ttype, id) = self.readFieldBegin()
if ttype == TType.STOP:
break
self.skip(ttype)
self.readFieldEnd()
self.readStructEnd()
elif ttype == TType.MAP:
(ktype, vtype, size) = self.readMapBegin()
for i in range(size):
self.skip(ktype)
self.skip(vtype)
self.readMapEnd()
elif ttype == TType.SET:
(etype, size) = self.readSetBegin()
for i in range(size):
self.skip(etype)
self.readSetEnd()
elif ttype == TType.LIST:
(etype, size) = self.readListBegin()
for i in range(size):
self.skip(etype)
self.readListEnd()
else:
raise TProtocolException(
TProtocolException.INVALID_DATA,
"invalid TType")这个方法通过传入的数据类型调用了不同的数据解码方法对数据进行解码操作,从而实现数据的读取。
9. RPCRuntime — transport
RPC 最重要的一环就是数据的传输了,他是连接接口提供者与接口调用者两端最重要的环节。
thrift 协议中定义了以下几种需要实现的传输层协议:
TSocket — 最基本的传输协议,通过 TCP 协议进行传输
TFileTransport – 基于文件的传输协议
TMemoryTransport — 使用共享内存实现的传输协议
TFramedTransport — 通过将数据分块实现非阻塞式传输
THttpClient — 基于 Http 协议的传输协议
python 语言的具体实现可以参看:
https://github.com/apache/thrift/tree/master/lib/py/src/transport。
他们都继承自 TTransportBase 类,它定义了通用的连接的建立、中断以及数据读写方法:
isOpen — 返回连接是否处于打开状态
open — 建立连接
close — 断开连接并清理
read — 读取 size 长度数据
readAll — 分块读取 size 长度数据
write — 将 buffer 中内容写入连接进行传输
flush — 刷新数据
10. Thrift 交互的完整过程
10.1. server 端交互时序图
下图展示了 server 端从初始化、启动到连接建立、传输的完整交互过程。
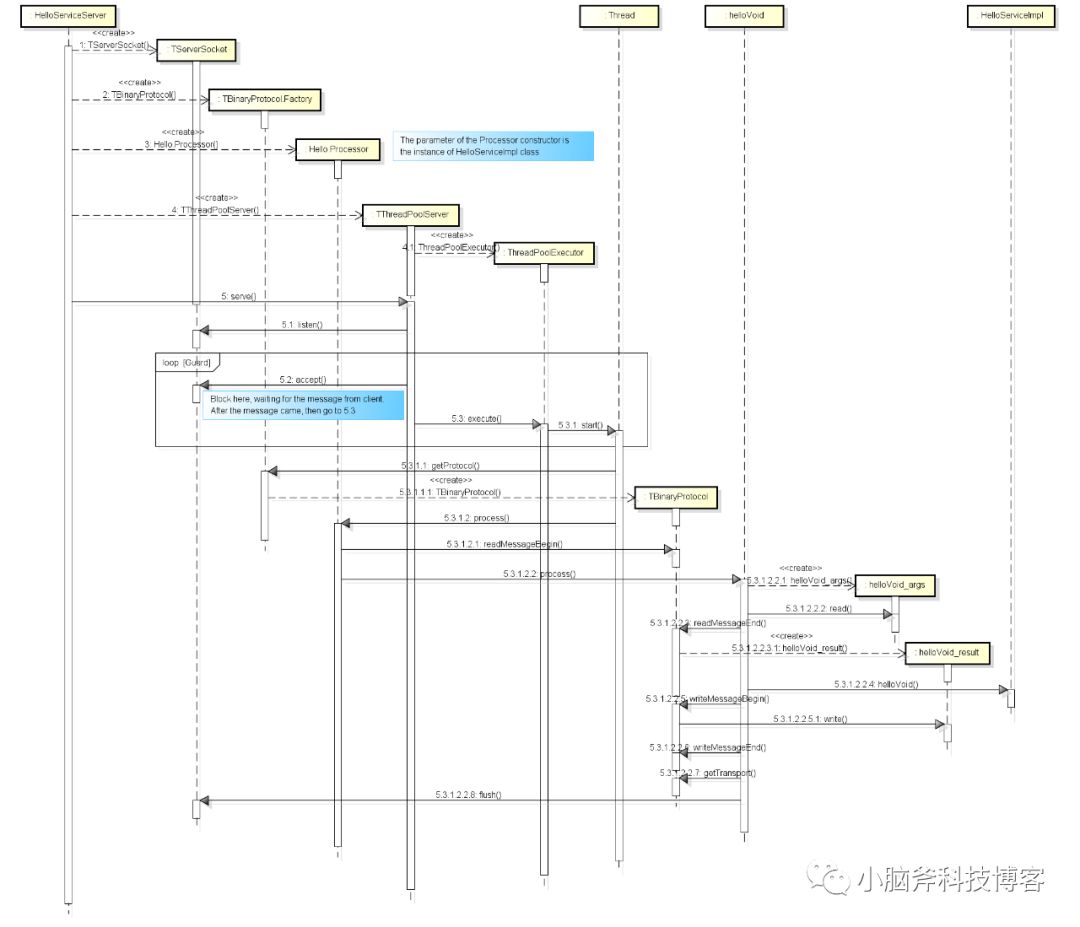
10.2. client 端交互时序图
下图展示了 client 端从初始化、启动到连接建立、传输的完整交互过程。
11. 微信公众号
12. 参考资料
http://birrell.org/andrew/papers/ImplementingRPC.pdf。
https://zh.wikipedia.org/wiki/%E9%81%A0%E7%A8%8B%E9%81%8E%E7%A8%8B%E8%AA%BF%E7%94%A8。
http://thrift.apache.org/docs/HowToNewLanguage。
https://github.com/apache/thrift/tree/master/lib/py/src。
https://zh.wikipedia.org/wiki/Thrift。
以上是关于RPC 原理以及开源 RPC 协议 thrift 源码解析的主要内容,如果未能解决你的问题,请参考以下文章