网络RPC通信之Apache Thrift
Posted 技术茶馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络RPC通信之Apache Thrift相关的知识,希望对你有一定的参考价值。
“
介绍基于RPC通信的Apache Thrift的架构设计。
主要内容如下:
1. 概述
2. RPC的概念
3. Thrift架构设计
4. 总结
”
01
—
概述
Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。它通过一个代码生成引擎联合了一个软件栈,来创建不同程度的、无缝的跨平台高效服务,可以使用C#、C++、Cappuccino、Cocoa、Delphi、Erlang、Go、Haskell、Java、Node.js、OCaml、Perl、php、Python、Ruby和Smalltalk。
本文主要介绍的是Apache Thrift架构设计相关的点,很少讲解如何使用Apache Thrift的内容,后续会出使用相关的文章。
02
—
RPC的概念
如下图所示:
Service Client:这个模块主要是封装服务端对外提供的API,让客户端像使用本地API接口一样调用远程服务。
Processor:在服务端存在很多方法,当客户端请求过来,服务端需要定位到具体对象的具体方法,然后执行该方法,这个功能就由processor模块来完成。
Protocol:协议层,这是每个RPC组件的核心技术所在。一般,协议层包括编码/解码,或者说序列化和反序列化工作;当然,有的时候编解码不仅仅是对象序列化的工作,还有一些通信相关的字节流的额外解析部分。序列化工具有:hessian,protobuf,avro,thrift,json系,xml系等等。
Transport:传输层,主要是服务端和客户端网络通信相关的功能。
Connector I/O:这个模块主要是为了提高性能可能采用不同的IO模型和线程模型。
目前主流的 RPC 框架有如下几种。
Thrift:Facebook 开源的跨语言框架
gRPC:Google 基于 HTTP/2 和 Protobuf 的能用框架
Avro:Hadoop 的子项目
本文讲述 RPC 的基本原理并以 Thrift 框架为例说明 RPC 的使用。
03
—
Thrift架构设计
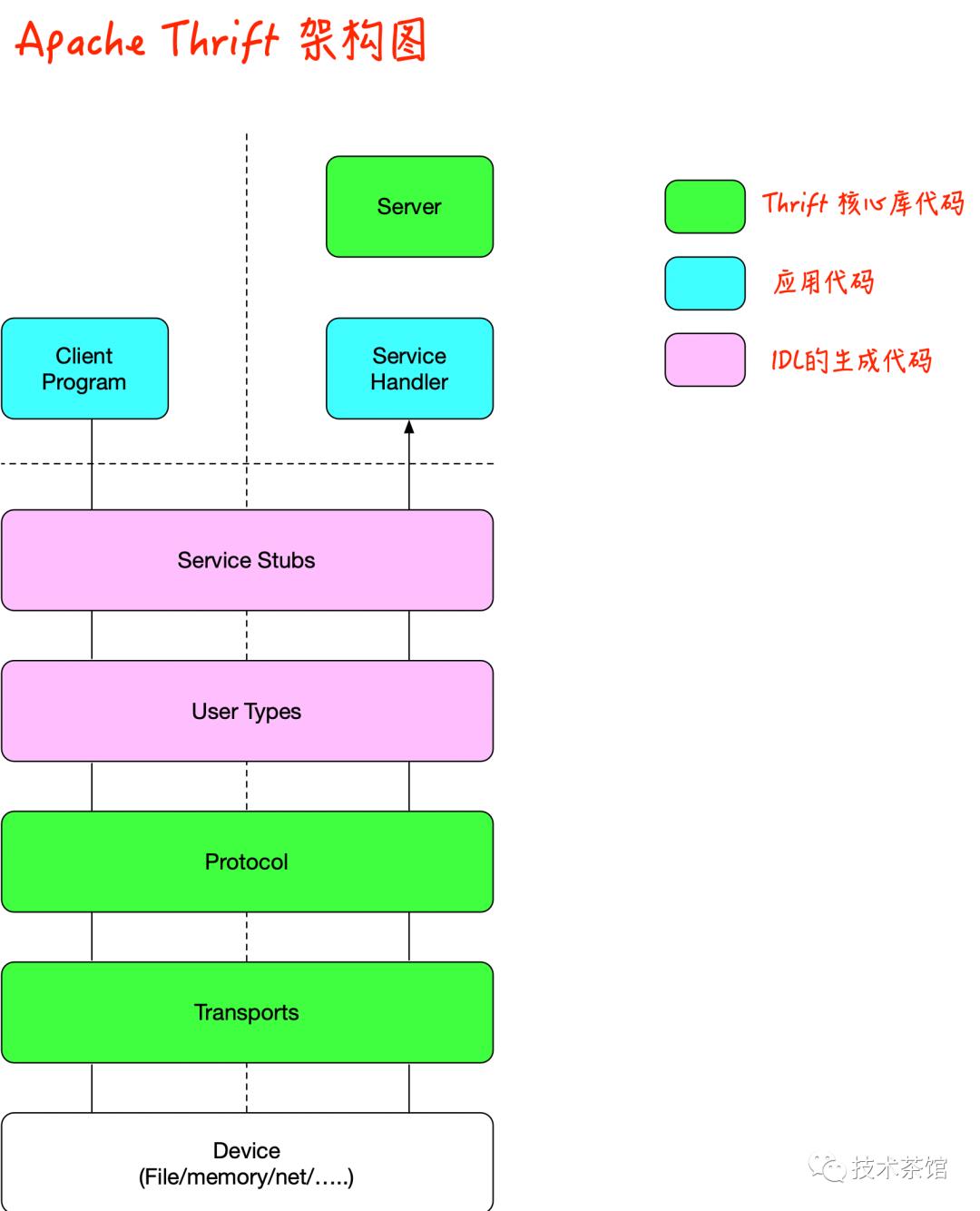
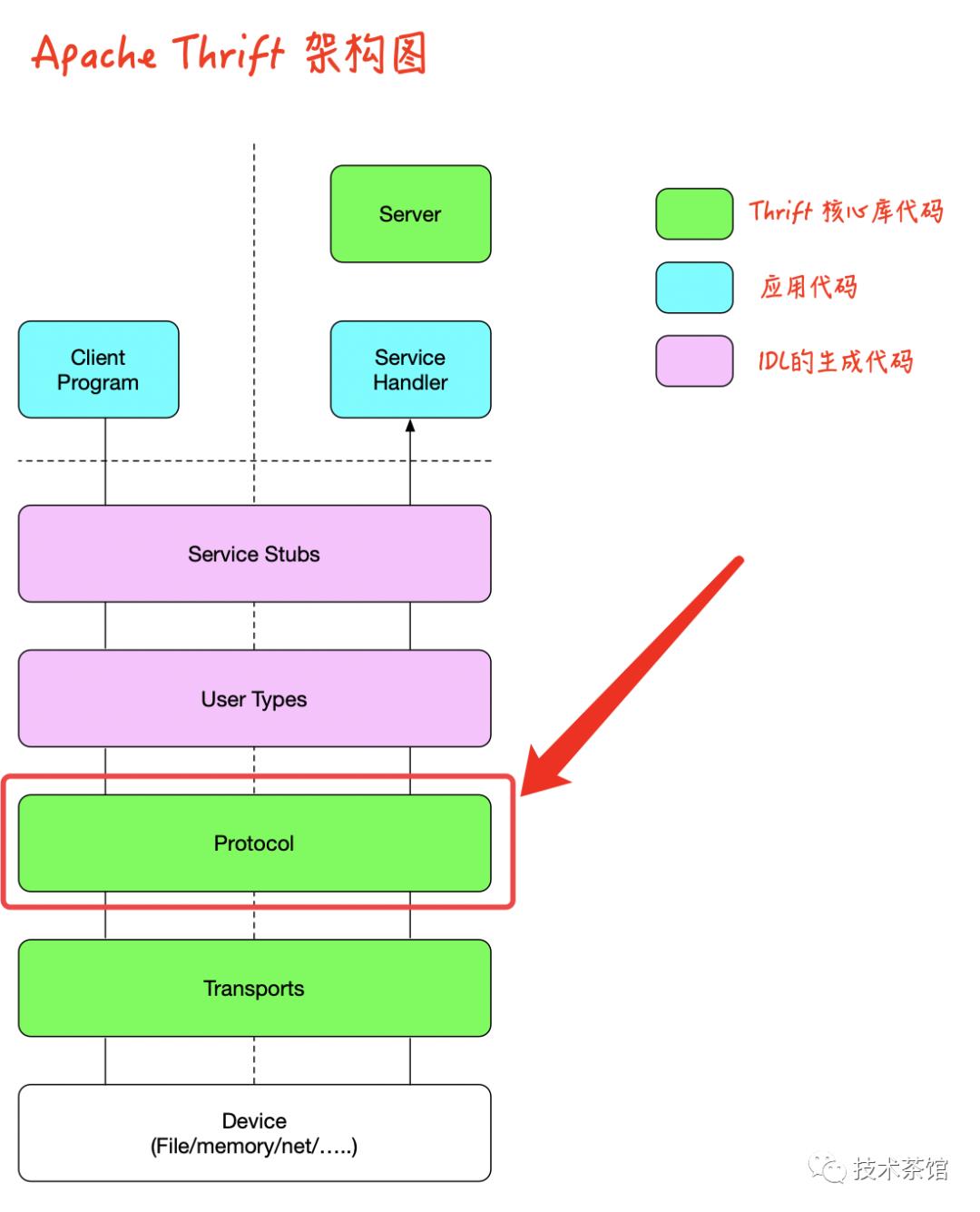
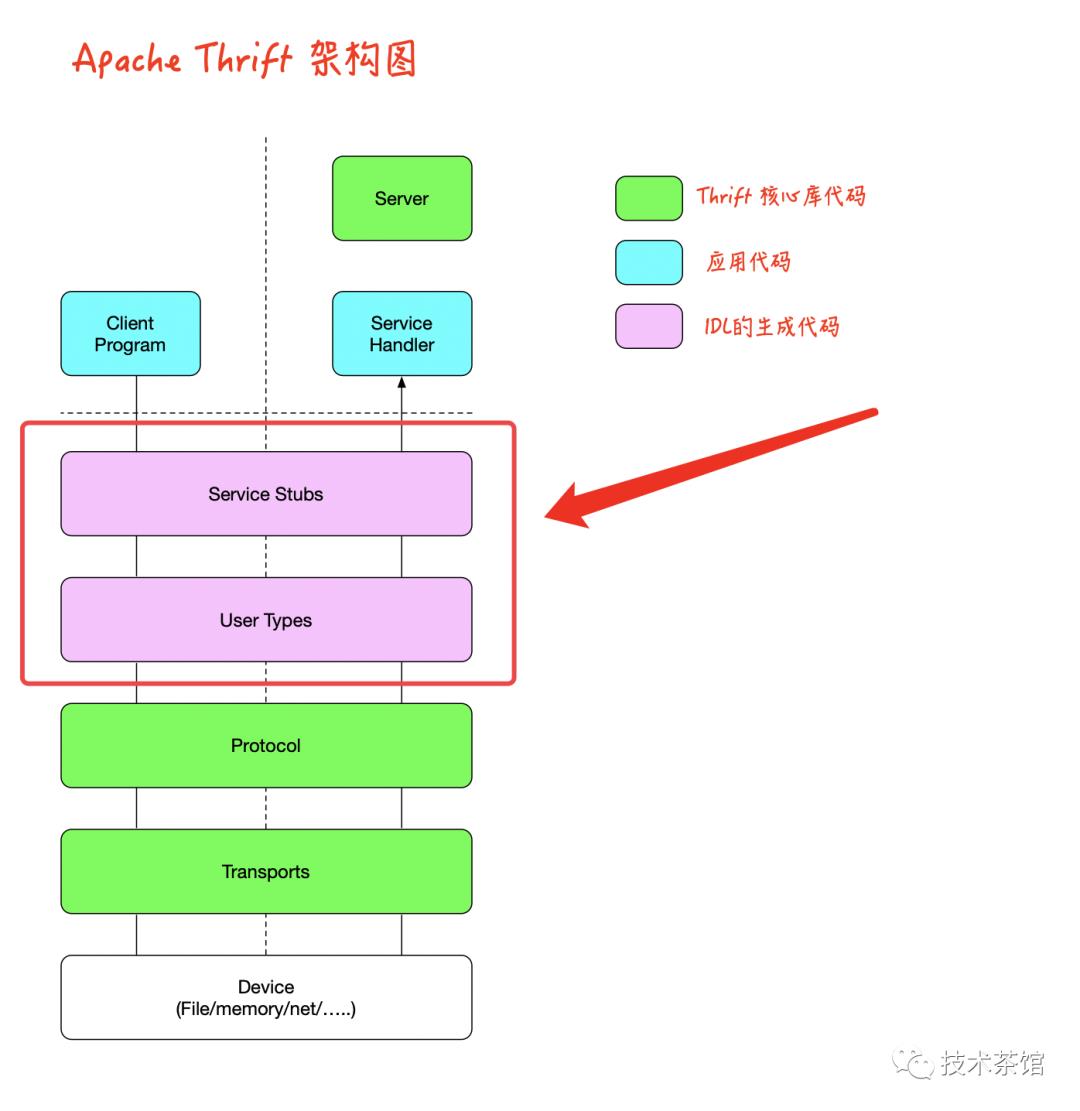
通过上图可知,Apache Thrift框架可以分为五层
The RPC Server Library
RPC Service Stubs
User Defined Type Serialization
The Serialization Protocol Library
The Transport Library
传输和序列化协议库分别提供设备抽象层和数据序列化。Apache Thrift IDL编译器增加了创建可序列化的用户定义类型的功能。需要将数据结构序列化到磁盘的通用方法的应用程序可能只需要这三个组件。
IDL编译器还支持从IDL服务定义生成RPC功能。再加上服务器库,就拥有了构建完整的RPC应用程序所需的一切。
从概念上讲,Apache Thrift是一种面向对象的框架,尽管它支持面向对象和非面向对象的语言。传输,协议和服务器库通常称为类库,尽管它们可以以其他方式以非面向对象的语言实现。Apache Thrift库中的类通常以大写的T命名,例如TTransport,TProtocol和TServer。
一、Transports
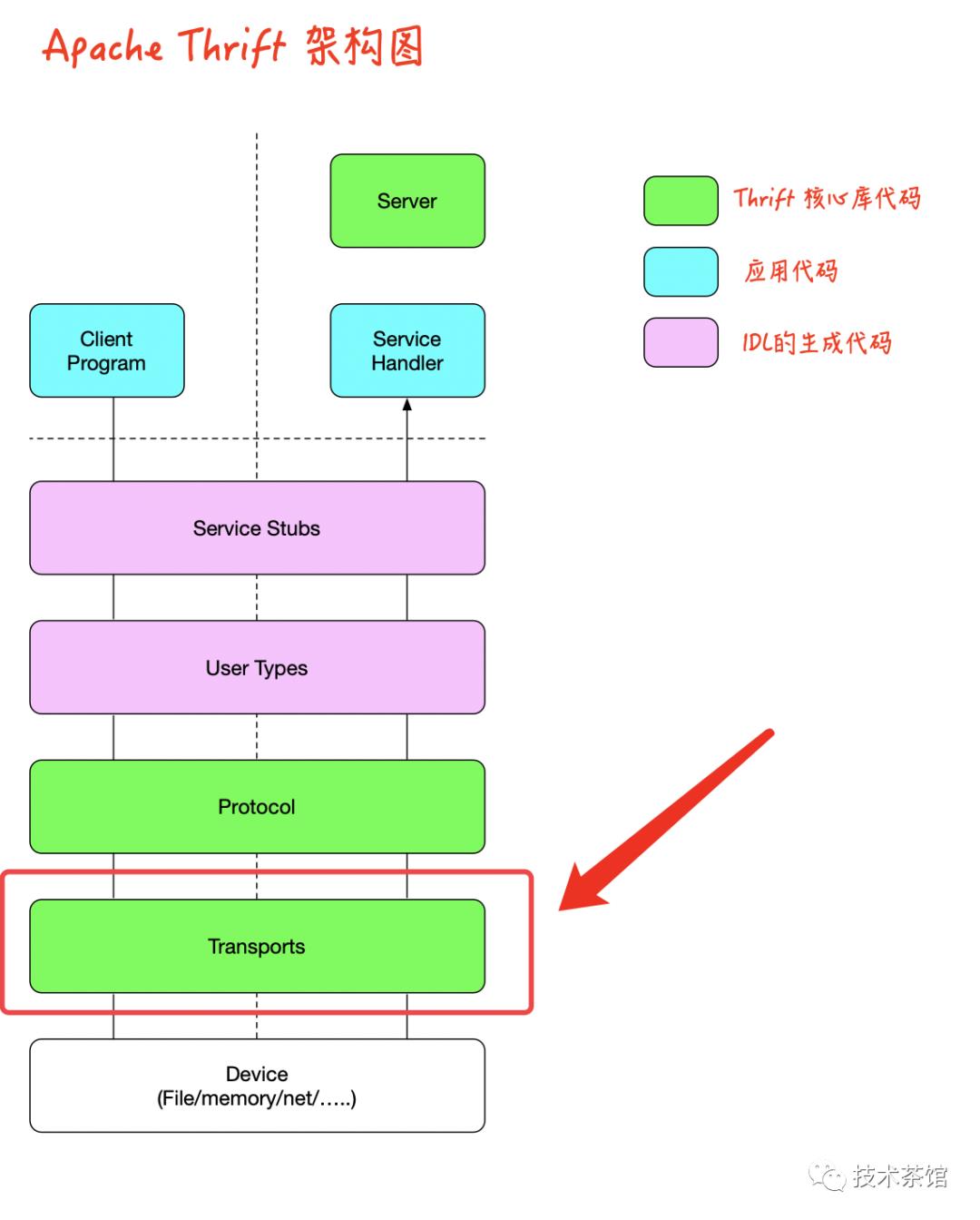
Thrift传输层提供了对物理设备的抽象。这使得Thrift可以掩盖设备的特定细节,并为需要使用物理设备的上层提供通用的API。具体来说,传输层处理与底层设备的字节级通信。通过提供这种抽象,Thrift可以支持新设备或中间件,而对其余的Thrift体系结构没有任何影响。
传输被进一步组织成称为传输堆栈的可组合层。此功能使您可以使用特定的传输来抽象物理设备,然后将该抽象与另一个逻辑传输层(例如缓冲或加密)包装在一起,而无需更改接口来传输使用者。此外,该应用程序可以在编译时或运行时自由选择或更改传输堆栈,从而可以定义适合不同需求的灵活传输堆栈。
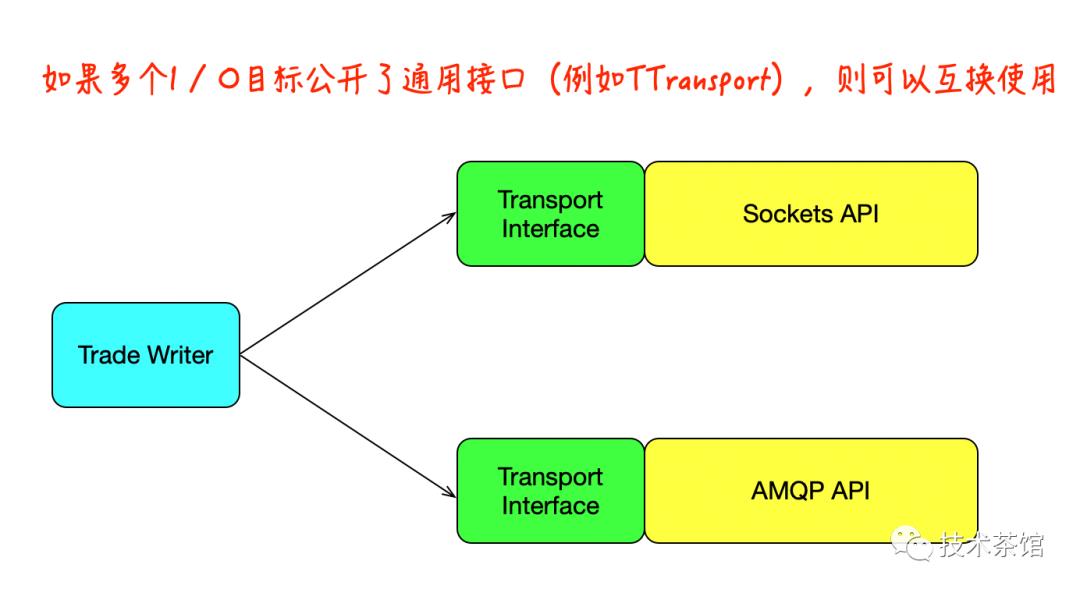
例如,假设您已经开发了一套程序,可以通过Sockets网络API移动股票价格。部署应用程序后,需求将扩大,并且要求您添加对通过AMQP(Advanced Message Queuing Protocol)消息传递系统进行的股价传输的支持。
如果在底层I / O层和代码高层之间定义了清晰的接口,则扩展的功能将非常容易实现。新的AMQP(Advanced Message Queuing Protocol)代码可以简单地实现现有的I / O接口,从而允许高层代码使用Socket解决方案或AMQP(Advanced Message Queuing Protocol)解决方案,而无需了解它们之间的区别如下图所示。
1、 Transports接口
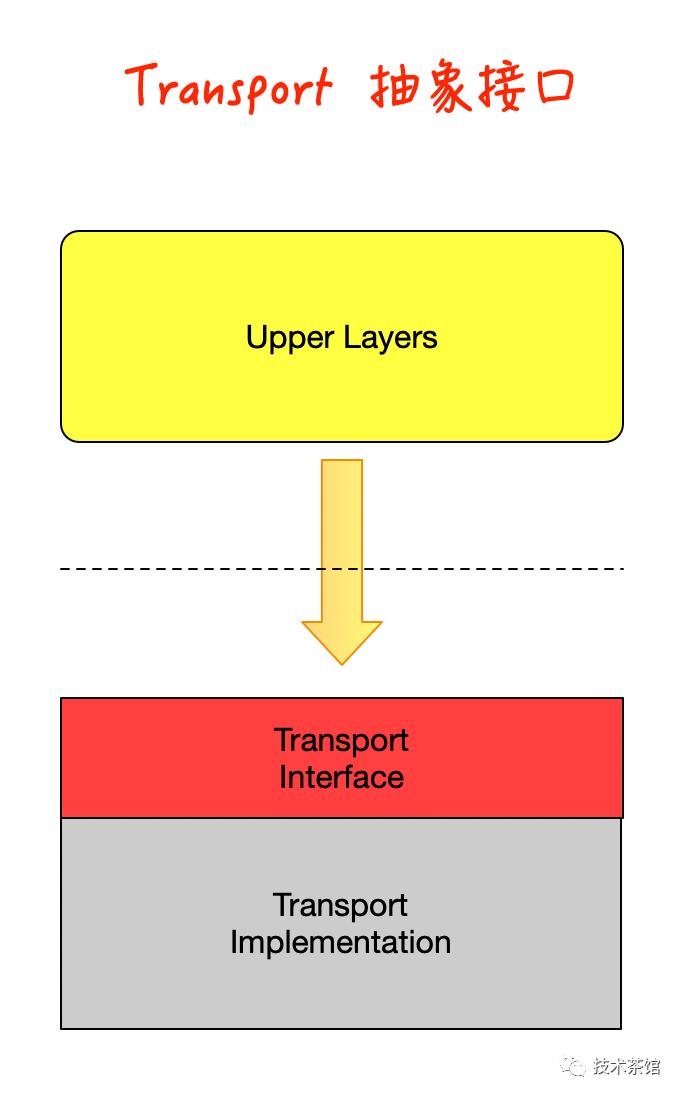
Apache Thrift传输层向上层代码公开了一个简单的面向字节的I / O接口。此接口通常在称为TTransport的抽象基类中定义。下图中描述了大多数语言实现中存在的TTransport方法。每种Apache Thrift语言实现都有其自己的微妙之处。Apache Thrift语言库的实现倾向于发挥所讨论语言的优势,使各种实现之间的某种程度的差异成为常态。

2、End Point Transports
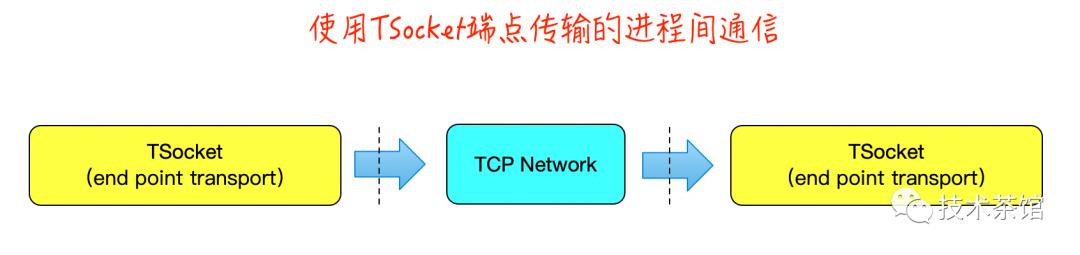
将写到物理或逻辑设备的Apache Thrift传输称为“端点传输”。端点传输始终位于Apache Thrift传输堆栈的底部,几乎所有Apache Thrift I / O操作都需要一个端点传输。
大多数Apache Thrift语言至少为内存,文件和网络设备提供了端点传输。
面向存储器的传输,例如TMemoryBuffer,通常用于收集多个小的写操作,这些写操作随后作为单个块发送。基于文件的传输(例如TSimpleFileTransport)通常用于日志记录和状态持久性。
最重要的Apache Thrift传输类型是用于支持RPC的网络传输。最常用的Apache Thrift网络传输是TSocket。TSocket传输使用Socket API通过TCP / IP传输字节。
其他设备和网络协议也可以通过传输接口公开。例如,C ++,Java和Python传输库提供Http类,以使用HTTP协议进行读写。为不受支持的网络协议或设备建立自定义传输通常并不困难,并且这样做可以使整个框架在新的端点类型上运行。
3、Layered Transports
由于Apache Thrift传输是由通用TTransport接口定义的,因此客户端代码独立于基础传输实现。这意味着传输可以覆盖任何内容,甚至可以覆盖其他传输。通过分层传输,Apache Thrift允许将通用传输行为分为可互操作和可重用的组件。
想象一下,您正在构建一个银行应用程序,该应用程序调用另一个公司托管的服务。您需要加密在客户端和RPC服务器之间传输的所有字节。如果创建了分层传输来提供加密,则客户端和服务器代码可以简单地在原始网络传输之上使用新的加密层。将此加密功能构建到分层传输中的好处是多方面的,其中最重要的一点是可以将其插入现有客户端代码和旧网络传输之间,而不会产生任何影响。客户端代码会将加密传输层视为另一个传输。网络端点传输将加密传输视为另一个客户端。
而且,加密传输可以在任何端点传输之上进行分层,从而使您可以对网络I / O以及文件I / O和内存I / O进行加密。分层方法允许将加密问题与设备I / O问题分开。
我们将不是端点传输的所有Apache Thrift传输称为“分层传输”。分层传输将标准Apache Thrift TTransport接口公开给客户端,并依赖于下一层的TTransport接口。这样,可以使用多个传输层来形成一个传输堆栈如下图所示。
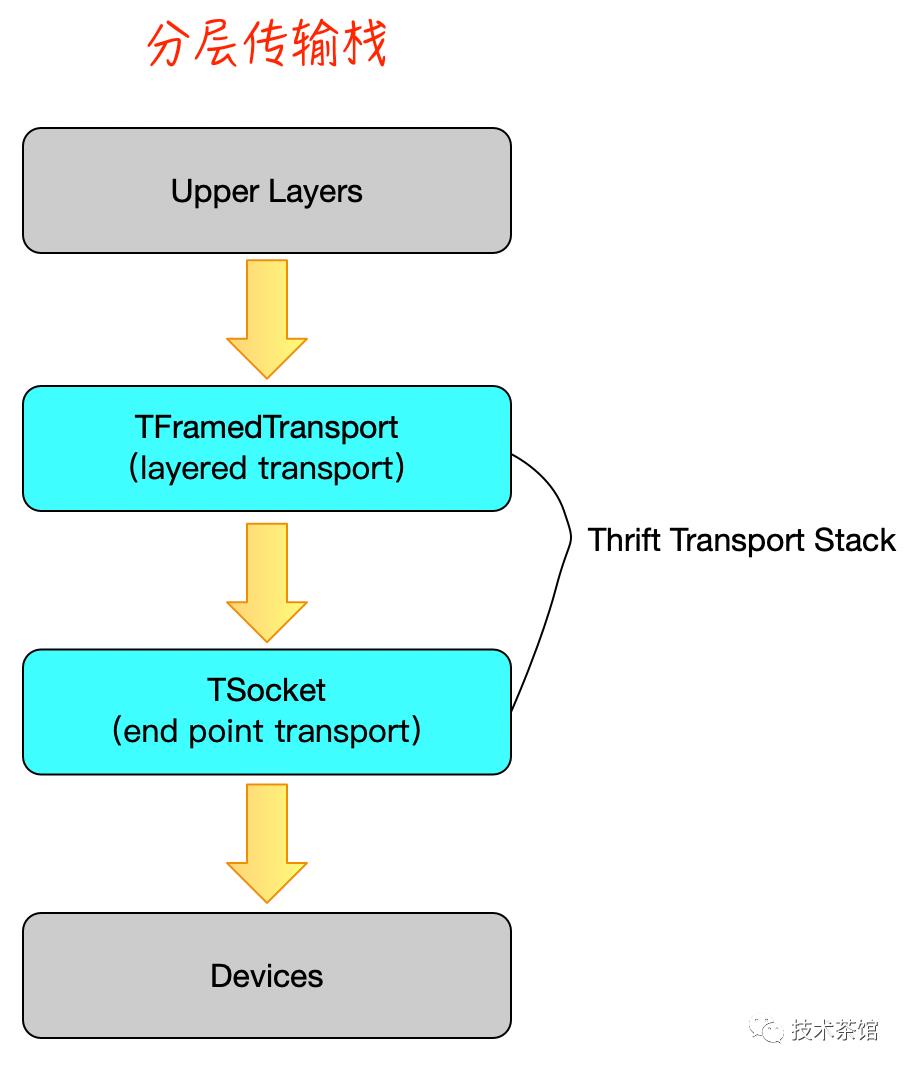
常用的Apache Thrift分层传输是成帧传输。在大多数语言库中,此传输称为TFramedTransport,它为每个Apache Thrift消息添加四字节消息大小作为前缀。在某些情况下,这可以实现更有效的消息处理,从而使接收方可以读取帧大小,然后提供帧所需的确切大小的缓冲区。
分层传输提供的另一个重要功能是缓冲。TFramedTransport隐式缓冲写入操作,直到调用flush()方法为止,此时将帧大小和数据写入下面的层。在许多I / O场景中,写缓冲都可以提高性能。例如,协议在序列化期间进行许多小的写操作,在网络情况下,这可能会导致传输许多小的数据包,从而造成不必要的系统开销。缓冲允许整个RPC消息作为一个单元发送。TBufferedTransport是TFramedTransport的替代方案,可以在不需要成帧时提供缓冲。有些语言将缓冲区构建到端点解决方案中,而不提供TBufferedTransport(Java就是一个例子)。
4、Server Transports
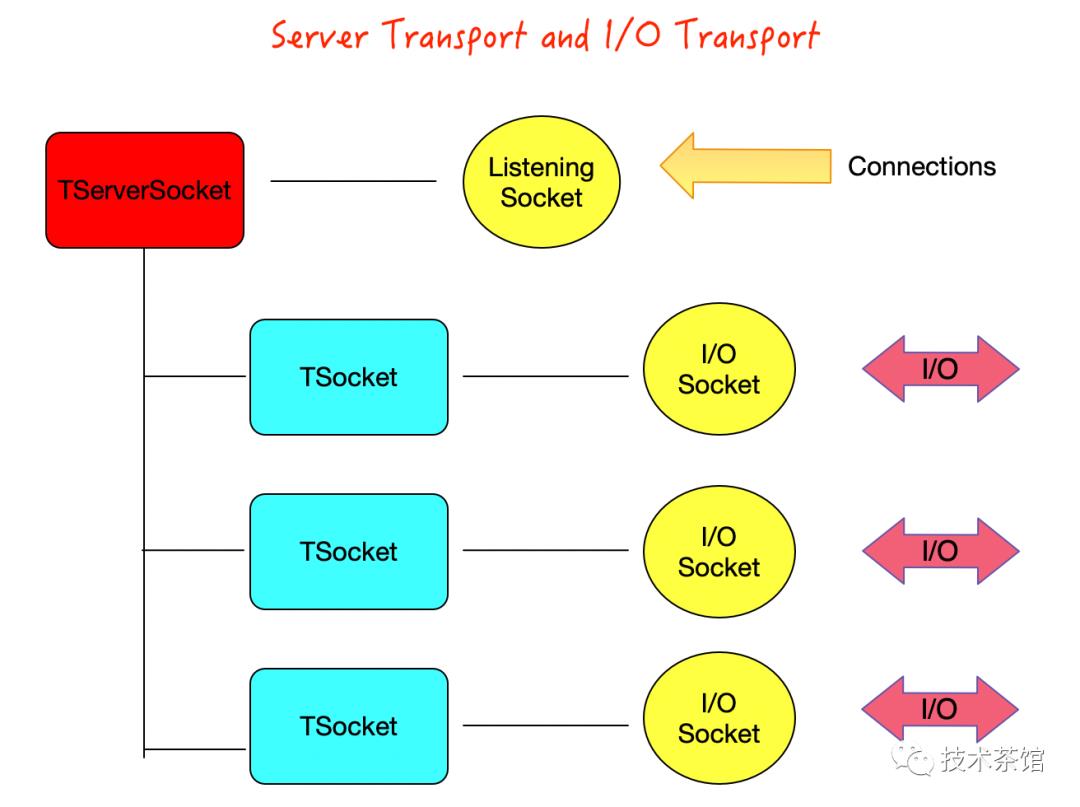
当两个进程通过网络连接的方式通信时,服务器必须侦听客户端的连接,并在新连接到达时接受它们。服务器连接接受器的抽象接口通常称为TServerTransport。TServerTransport最受欢迎的实现是用于TCP / IP网络的TServerSocket。服务器传输将每个新连接连接到TTransport实现,以处理单个连接的I / O。服务器传输遵循工厂模式,其中TServerSockets生产TSocket,TServerPipes生产TPipe,等等。
服务器传输通常只有四种方法如下图所示。listen()和close()方法准备使用服务器传输,并分别将其关闭。客户端无法在调用listen()之前进行连接。accept()方法将阻塞,直到客户端连接到达为止。当客户端启动连接时,服务器的accept()方法将返回连接到该连接的TTransport,然后该TTransport用于支持客户端的常规RPC操作。interrupt()方法使服务器传输脱离阻塞的接受调用,从而导致服务器返回。

为了了解服务器传输是如何工作的,假设我们构建了一个简单的web服务器。我们需要我们的服务器监听TCP端口8585上的客户端请求。随着每个新请求的到来,我们需要创建一个新线程来处理该连接上的客户端web页面请求。下图说明了如何使用TServerSocket在新的套接字连接到达时生成它们。服务器传输接受连接和处理产生的活动连接的方式取决于使用服务器传输的服务器的设计。
二、Protocol
协议提供了将数据类型序列化为字节流以供传输使用的方法。Thrift不支持每种语言的每种类型。相反,它支持一种基本类型系统,可以将其转换为每种语言的表示形式。任何有效的Thrift协议实现都必须能够读写Thrift类型系统定义的所有类型(由Thrift接口定义语言或IDL指定)。
协议层位于传输堆栈的顶部,并负责将特定于语言的数据类型序列化为与语言无关的字节流,这些字节流可以使用传输堆栈进行传输。客户端和服务器需要使用相同的序列化协议进行正确的通信。
例如,如果您想将一个整数存储到一个系统上的磁盘文件中,并使其在另一个系统上可读,则需要确保该整数以约定的字节顺序存储。最高有效字节或最低有效字节必须位于第一位。这两个选项之间的选择由序列化协议进行。传输只是按照提供的顺序将提供的字节写入磁盘。
Apache Thrift提供了几种序列化协议,每种都有其自己的目的:
The Binary Protocol – simple and fast
The Compact Protocol – smaller data size without excessive overhead
The JSON Protocol – standards based, broad interoperability
二进制协议(The Binary Protocol)是默认的Apache Thrift协议,在初始发行时,它是唯一的协议。二进制协议需要最少的CPU开销,本质上是按照字节顺序将所需类型写入字节流。使用二进制协议时,一个64位整数将占用线路上的大约64位。
紧凑协议(The Compact Protocol)旨在最小化数据的序列化表示的大小。紧凑协议相当简单,但是在将位转换为较小空间的过程中确实使用了更多的CPU。在I / O瓶颈和CPU大量存在的情况下(相当普遍的情况),这是一个不错的协议。
JSON协议(The JSON Protocol)将输入转换为JSON格式的文本。在三种常见的Apache Thrift协议中,JSON可能会在网络上产生最大的表示形式,并消耗最多的CPU。JSON的优点是广泛的互操作性和可读性。
Apache Thrift语言通常提供一个称为TProtocol的抽象协议接口,所有具体协议实现都遵守该协议接口。该接口定义用于读取和写入每种Apache Thrift类型的方法,以及用于序列化容器,用户定义的类型和消息的组合方法。
Apache Thrift类型系统允许定义结构。Apache Thrift结构是基于IDL的用户定义类型,由一组字段组成。这些字段可以是任何合法的Apache Thrift类型,包括基本类型,容器和其他结构。Apache Thrift消息是用于通过传输传递RPC调用和响应的信封。协议接口提供对序列化结构和消息的支持。
下图列出了一些定义Apache Thrift类型系统的典型TProtocol方法。此处列出的每个write方法都有一个具有相同后缀的相应read方法(例如writeBool()/ readBool())。

三、The IDL and Compiler
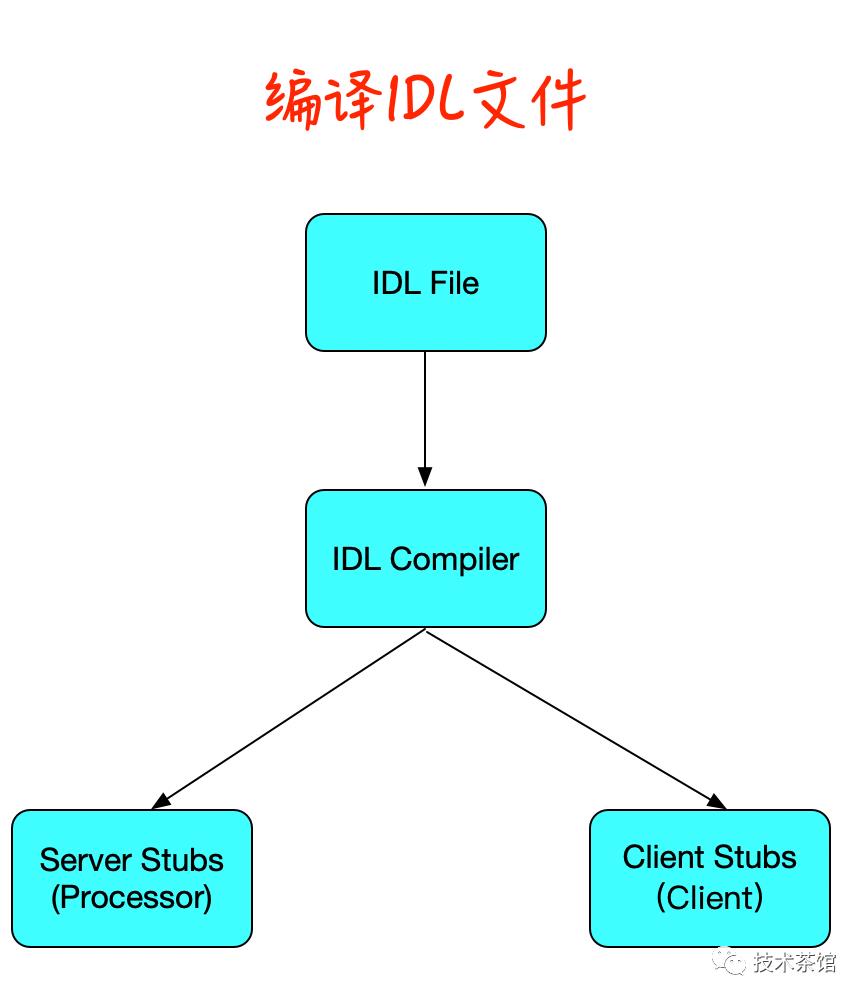
IDL旨在使描述应用程序的数据类型和接口语言独立。Thrift编译器随后使用这种独立于语言的表示形式来生成特定于语言的数据类型和接口的实现,以供用户应用程序使用。
下面有这样一个接口定义的示例
struct Date { #A1: i16 year,2: i16 month,3: i16 day,}service HalibutTracking { #Bi32 GetCatchInPoundsToday(),i32 GetCatchInPoundsByDate(1: Date d, 2: double t), #C}#A Date是Apache Thrift用户定义的类型,将为此类型生成读/写序列化代码#B HalibutTracking是一个Apache Thrift服务接口,将为此接口生成客户端和服务器RPC存根#C 用户定义的类型Date可用作参数或返回类型
上面的IDL文件中定义的服务称为HalibutTracking #B。此服务取决于用户定义的类型Date #C。为了将IDL编译为特定语言的代码,请使用指示要为其生成代码的目标语言的开关来调用IDL编译器。命令“ thrift –gen java halibut.thrift”将输出一组Java文件,这些文件旨在使用HalibutTracking服务启用Date类型和客户端/服务器RPC的序列化。其他语言的过程与此类似。
1、User-Defined Types
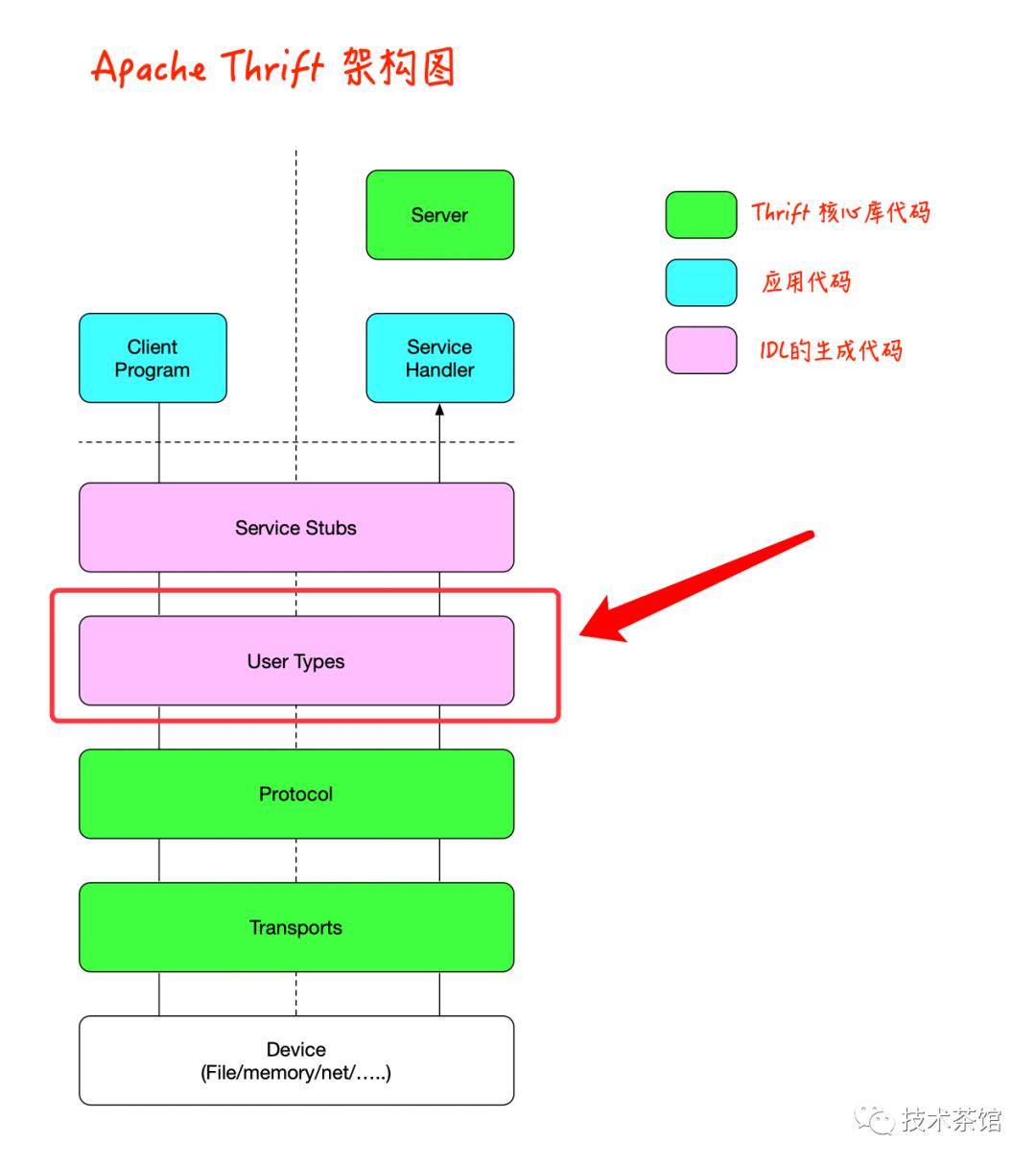
用户定义类型(UDT)是外部接口的重要方面。虽然可以使用离散的年/月/日参数来组合GetCatchInPoundsByDate()方法,但Date类型更具表现力,可重用性和简洁性。Apache Thrift IDL允许使用“ struct”关键字创建用户定义的类型。
IDL编译器根据IDL类型生成特定于语言的类型,例如,struct关键字将使IDL编译器生成C ++中的类,Erlang中的记录和Perl中的包。这些生成的类型具有内置的序列化功能,可轻松使用任何Apache Thrift协议/传输堆栈对其进行序列化。
下面是一个伪代码示例,说明IDL编译器生成的UDT可能是什么样子。
class Date {public:short year;short month;short day;read(TProtocol protocol) {...};write(TProtocol protocol) {...};};
上面用伪代码说明的普通Date类型具有IDL中描述的确切字段,并被组织成一个与我们的IDL结构同名的类。Apache Thrift编译器创建read()和write()方法,以通过Apache Thrift TProtocol接口自动进行类型序列化的过程。这使得传输复杂的数据结构就像调用以目标Apache Thrift协议为参数的结构上的读取或写入一样容易。
Apache Thrift结构在Apache Thrift框架内部用作打包所有RPC数据传输的方法。每个Apache Thrift Service方法的参数列表都在“ args”结构中定义。这使Apache Thrift可以使用相同的便捷struct read()和write()方法来发送和接收RPC参数和用户定义的类型。
结构的write方法的实现是对适当的TProtocol方法的简单顺序调用。这是Date结构的write方法的伪代码。
// Thrift generated struct write() methodDate::write(TProtocol protocol) {protocol.writeStructBegin("Date");protocol.writeFieldBegin("year", T_I16, 1); protocol.writeI16(this.year);protocol.writeFieldEnd();protocol.writeFieldBegin("month", T_I16, 2); protocol.writeI16(this.month);protocol.writeFieldEnd();protocol.writeFieldBegin("day", T_I16, 3);protocol.writeI16(this.day);protocol.writeFieldEnd();protocol.writeFieldStop();protocol.writeStructEnd();}
构成可序列化,与语言无关的类型的能力是Apache Thrift IDL的一项关键功能。此功能允许任何Apache Thrift支持的编程语言协作地读写对象。例如,Haskell程序可以将基于IDL的记录序列化为一个文件,然后Ruby程序可以使用Apache Thrift读取记录。这种类型的跨语言序列化是商业应用程序使用的关键Apache Thrift功能之一。
2、Service Stubs
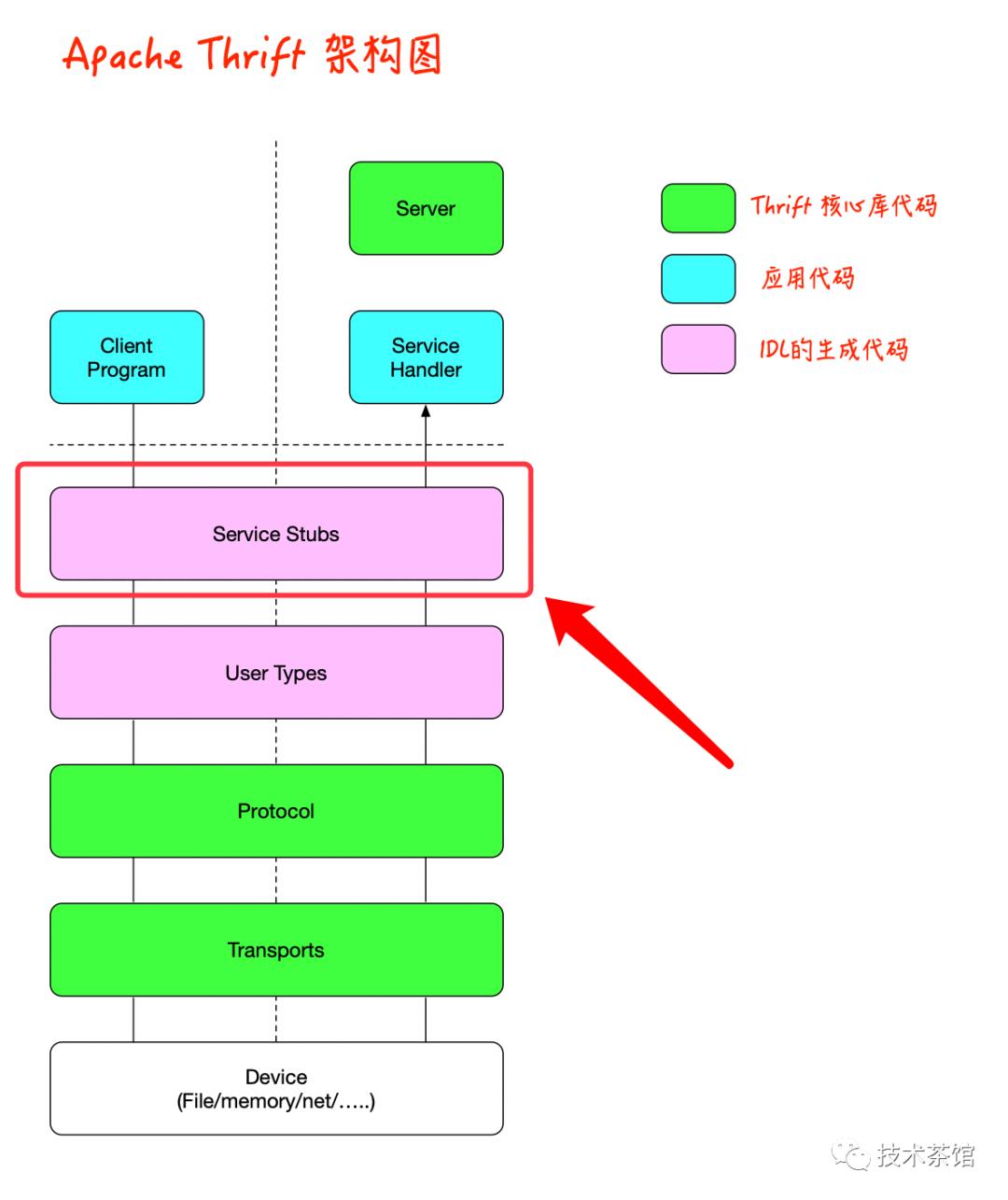
对于许多程序员而言,构建跨语言RPC服务是使用Apache Thrift的主要原因。在Apache Thrift IDL中定义服务允许IDL编译器生成客户端和服务器存根,这些存根提供了远程调用函数所需的所有管道。在我们之前的示例中,IDL编译器将需要生成客户端和服务器存根代码以支持HalibutTracking服务。
这是编译器的HalibutTracking服务界面的伪代码。
// Thrift generated Service interfaceinterface HalibutTracking {int32 GetCatchInPoundsToday();int32 GetCatchInPoundsByDate(Date d, double t);};
此服务有两个方法都返回一个32位整数,并且其中一种采用Date结构作为输入。除了使用目标语言定义接口外,IDL编译器还将生成一对类,以在该接口上支持RPC。在客户端进程中使用的客户端存根,在服务器进程中使用的称为处理器的服务器存根。Client类用作远程服务的代理。处理器用于代表远程客户端调用用户定义的服务实现。
Client Stubs
对调用远程服务器中的服务方法感兴趣的客户机进程可以简单地调用由客户机代理对象提供的所需方法。客户机必须向服务器发送一条消息,包括有关要调用的方法和任何参数的信息。通常,客户端必须等待从服务器接收调用的结果。使用生成的客户机使得开发利用RPC服务的软件就像编写本地函数一样自然。
下面是IDL编译器生成的HalibutTracking服务getCatchInBoundsToDay()方法的客户端实现的伪代码列表。
// Thrift generated Client codeint32 HalibutTrackingClient::GetCatchInPoundsByDate(Date d, double t){send_GetCatchInPoundsByDate(d, t);return recv_GetCatchInPoundsByDate();}void HalibutTrackingClient::send_GetCatchInPoundsByDate(Date d, double t){protocol.writeMessageBegin("GetCatchInPoundsByDate", T_CALL, 0);HalibutTracking_GetCatchInPoundsByDate_args args;args.d = d;args.t = t;args.write(protocol);protocol.writeMessageEnd();protocol.getTransport().flush();}
在此示例中,GetCatchInPoundsByDate()的客户端实现调用内部“ send_”方法#A将消息发送到服务器。接下来是对第二个“ recv_”方法#B的调用以接收结果。这是Apache Thrift RPC协议的基础。客户端向服务器发送消息以调用方法,服务器将结果发送回去。
第二种方法是send方法的伪代码。send方法创建一条消息以发送到服务器。该消息以协议writeMessageBegin()调用#C开头。这将序列化T_CALL常量,该常量通知服务器这是“ RPC调用”类型的消息。字符串“ GetCatchInPoundsByDate”已序列化以指示我们要调用的方法。此处传递的零表示我们将不使用序列号。消息序列号在某些应用程序中很有用,但在普通的Apache Thrift RPC中不使用。
Apache Thrift IDL编译器可以为IDL中定义的任何结构生成read()和write()序列化方法。Apache Thrift不会重新发明轮子,而是为每个方法的参数列表(称为args)生成一个内部结构。为了将方法的参数添加到字节流中,实例化args结构并使用方法调用的参数进行初始化。使用协议调用args对象的write()方法会序列化调用GetCatchInPoundsByDate()方法所需的所有参数。
生成的客户端代码通过调用writeMessageEnd()来完成对writeMessageBegin()的调用,从而完成了消息的序列化。消息完全序列化之后,要求传输堆栈将字节刷新()到网络(如果它们已被缓冲) )#E。
Service Processors
RPC调用的服务器端由两个代码元素组成。第一个是处理器,它是服务器端存根,与客户端类相对应。Thrift编译器为每个IDL定义的服务生成一个客户端和处理器对。处理器使用协议栈反序列化服务方法调用请求,从而调用适当的本地功能。本地函数调用的结果由处理器打包到结果结构中,并发送回客户端。处理器本质上是一个调度程序,它从客户端接收请求,然后将它们调度到适当的内部功能。
Service Handlers
处理器依靠服务处理程序来实现服务接口。IDL编译器为定义的每个IDL服务生成特定语言的接口定义。用户可以创建带有服务功能实现的处理程序类。然后将此实现提供给处理器,以完成RPC支持链。
下面给出一个完整的Thrift请求响应生命周期图如下:
四、Servers
在Apache Thrift的上下文中,服务器是专门设计用来托管一个或多个Apache Thrift服务的程序。事实证明,服务器的工作是相当规范的。服务器侦听客户端连接,将呼叫调度到服务,并且仅在偶尔被管理员关闭。
常见服务器设计的允许Thrift提供具有多种功能的特定语言的服务器类库。不同的语言库支持不同的服务器类。例如,Java提供单线程和多线程服务器以及使用专用客户端线程的服务器和使用线程池处理请求的服务器。
大多数生产服务器进程可以围绕Apache Thrift库服务器之一进行设计。Apache Thrift是开源的,因此通过定制现有服务器甚至可以满足自定义要求。让我们看一个简化的Java程序,该程序利用Apache Thrift库服务器来支持HalibutTracking服务。
public class JavaServer {public static void main(String[] args) {TServerTransport svrTransport = new TServerSocket(8585);HalibutTrackingHandler handler = new HalibutTrackingHandler();HalibutTrackingHandlerbutTracking.Processor<HalibutTrackingHandler> processor =new HalibutTracking.Processor<>(handler);TServer server = new TSimpleServer( new Args(svrTransport).processor(processor));server.serve();}}
这个简单的Java服务器首先创建一个TServerSocket服务器传输#A,它将在端口8585上侦听新的客户端请求。#B创建一个HalibutTrackingHandler对象以实现服务。此类必须由用户创建,并将包含服务实现所需的任何逻辑。接下来,我们创建一个处理器#C来管理RPC调用调度。TSimpleServer类是大多数语言中最基本的Apache Thrift服务器。在这里,使用服务器传输和处理器/处理器对作为输入#D构造TSimpleServer对象。我们未指定任何协议,因此将使用默认的二进制协议。最后一步,我们调用服务器的serve()方法,此时服务器开始接受连接并处理对HalibutTracking服务的调用。
使用Apache Thrift Java语言库中的TSimpleServer类,我们可以用大约五行代码创建功能齐全的服务器。复杂的服务可能需要很多行Handler代码,但是服务器外壳不会比您在上面看到的复杂得多。多线程异步服务器可以在大约相同的空间内实现。
04
—
总结
通信相关的技术是C/S或者B/S架构不可或缺的知识,上文中主要讲述了关于Apache Thrift的架构设计,方便我们理解和使用Apache Thrift。在使用的过程中,如果出现相应的问题也能快速的定位。
上文中部分内容是翻译<<the programmer's guide to apache thrift>>一书的内容,如果想深入理解Apache Thrift,可以参考下这本书。
参考资料
1. https://thrift.apache.org/docs/idl
2. <<the programmer's guide to apache thrift>>
以上是关于网络RPC通信之Apache Thrift的主要内容,如果未能解决你的问题,请参考以下文章