记一次RPC耗时调优
Posted 力扣指北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次RPC耗时调优相关的知识,希望对你有一定的参考价值。
背景
随着业务不断增长,后端各个业务的集群规模也在疯狂增长。有业务方发现,RPC客户端平均耗时比服务端内部耗时高10ms。如上图所示,如果 ,那么 约为 。
分析
不难发现, 只「统计了服务端执行处理逻辑的时间」, 还额外统计了:
-
IO线程与逻辑线程之间的排队时间 -
协议的序列化与反序列化 -
网络传输的时间
多出来的10ms大概率出在这三个环节上。
通过监控发现机器的负载非常低,大多数时间,CPU利用率维持在 20% 左右。基本排除了排队时间的影响。
继续排查序列化/反序列化带来的时延影响。抽了25个RPC调用对,发现有13个调用对 与 的差超过了10ms。
为了确定Request 和 Response 的大小与时延的关系,列了一张表。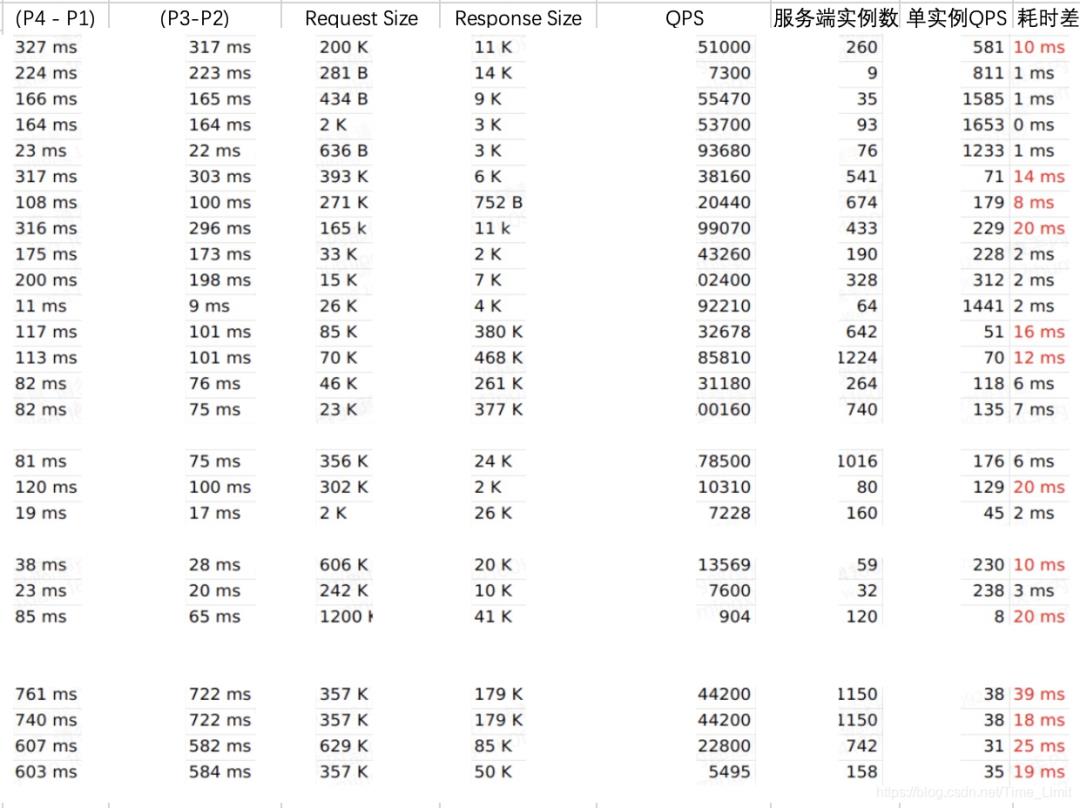 从以上数据来看,如果 Request 或者 Response 比较大,比如超过了 100K,RPC 调用耗时就容易超出 10 ms。
从以上数据来看,如果 Request 或者 Response 比较大,比如超过了 100K,RPC 调用耗时就容易超出 10 ms。
问题复现
通过前面的分析,对于 Request 和 Response 比较大的情况下,RPC 调用耗时超预期的可能性比较大。可以仿造线上的情况,来构造 CASE 尝试在线下复现问题。为了使问题极端化,这里尝试使用 Request 和 Response 都是 2M 的场景,进行测试。服务端收到请求以后,先 Sleep 300 ms,然后再返回 Response。为了排除负载的影响,客户端发送的QPS也是非常低,每 10 秒发送一个请求。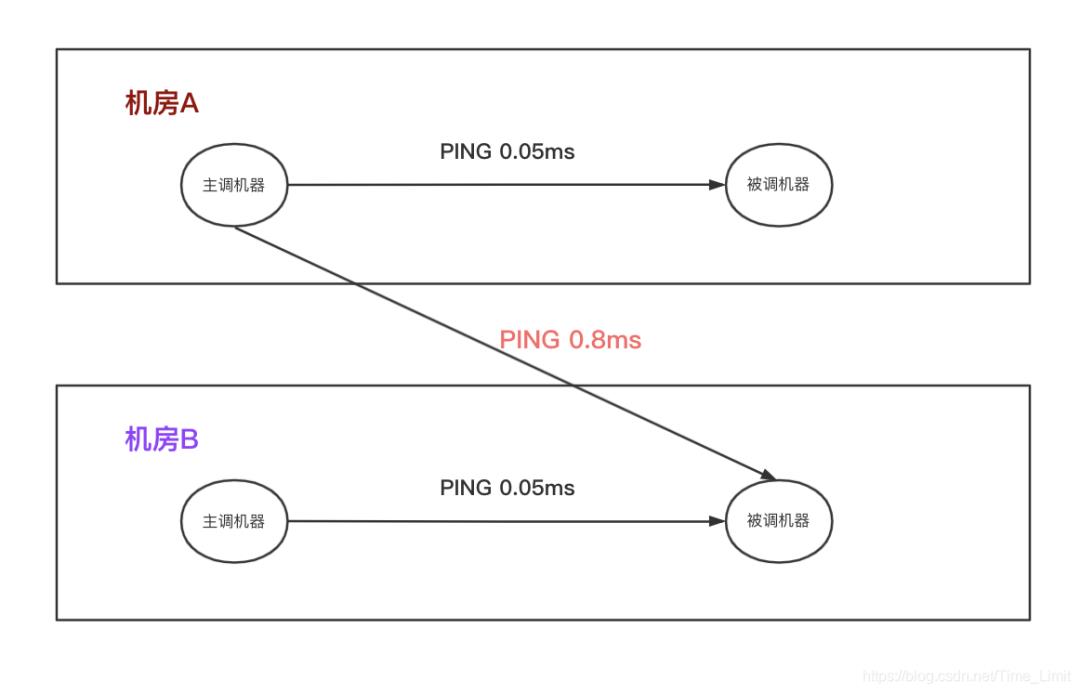 尝试使用以上测试场景可以发现:
尝试使用以上测试场景可以发现:
-
在跨机房(PING 0.8 ms)时可复现问题, 客户端耗时即 为 320 ms。 -
对于同机房调用(PING 0.05 ms)的时候,客户端耗时不到 310 ms。
从这里可以得到一个初步的结论:「Request 或者 Response 比较大,并且网络 RTT 高的时候,在客户端观测到耗时会显著高于服务端处理时间」。
继续分析
从线下构造的 CASE 来看,很有可能是网络问题,可以通过 Wireshark 来抓包分析。为了避免慢启动造成的影响,先让服务运行了几分钟,之后再抓包分析。通过抓包发现,Request 和 Response 的发包,并不是持续进行的,而是每发一段数据包,就会有一个大约 500us 的卡顿。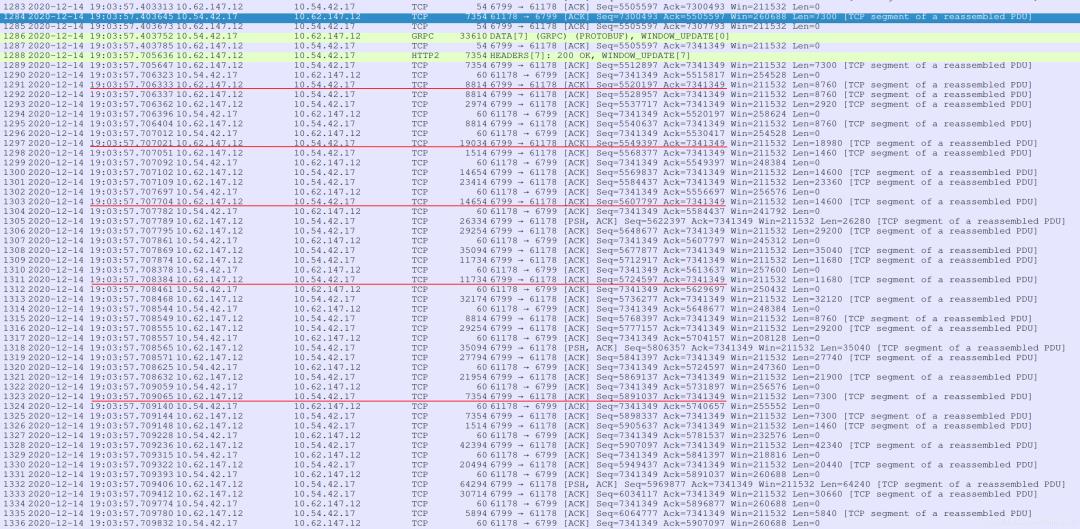 例如以上红线标注的数据包,数据的流向都是10.62.147.12:6799 -> 10.54.42.17:61178,但是和「上一次发包间隔了大约 500 us」,而且和前一个 ACK 的时间间隔很小。
例如以上红线标注的数据包,数据的流向都是10.62.147.12:6799 -> 10.54.42.17:61178,但是和「上一次发包间隔了大约 500 us」,而且和前一个 ACK 的时间间隔很小。
从这里可以联想到 TCP 的滑动窗口机制,应该是最后的这个 ACK,促使了滑动窗口继续往前滑动。这里有一个疑问,窗口的大小是多少呢?可以通过发包前的ACK来简单计算一下,每次停顿的时候,在途的字节数。而这个字节数应该就是发送端的窗口大小。
「计算方法是:当前 SEQ 减去之前的对端 ACK 的序号」
| 时间 | 在途字节数 | MSS 倍数 |
|---|---|---|
| 19:03:57.706333 | 5520197 - 5505597 = 14600 | 10 * 1460 |
| 19:03:57.707021 | 5549397 - 5520197 = 29200 | 20 * 1460 |
| 19:03:57.707704 | 5607797 - 5549397 = 58400 | 40 * 1460 |
| 19:03:57.708384 | 5724597 - 5613637 = 116800 | 80 * 1460 |
| 19:03:57.709065 | 5891037 - 5724597 = 166440 | 114 * 1460 |
从现象上看每经过一个RTT,都会经历一次卡顿;而每经过一个RTT,窗口大小似乎在按照慢启动的方式逐步增大。
原因初步定位为:「每个 RPC 请求和响应,都要经历慢启动的过程,导致耗时增加。」
解决方案
通过网上搜索,可以发现有个 TCP 的内核参数 「net.ipv4.tcp_slow_start_after_idle」可以控制 TCP 连接在空闲一段时间后,是否进入慢启动。其默认值为 1。如下图所示:当 RPC 调用的 QPS 比较低时:
-
如果 net.ipv4.tcp_slow_start_after_idle 为 1 ,每个 RPC 调用的数据包,都要经历慢启动过程。 -
如果 net.ipv4.tcp_slow_start_after_idle 为 0,只有最初的几个数据包需要慢启动,后续的RPC调用,不再需要慢启动,从而优化耗时。
因为在我司的 RPC 调用场景下很多时候主调和被调实例的个数都很多,比如主调有 500 个实例,被调有 500 个实例,总的 QPS 加起来为 5W QPS。看起来总的 QPS 很高,但是总共有 500×500 = 25W 个 TCP 链路,实际上每个主调实例和被调实例之间的 TCP 连接上,平均每 5 秒才能有一个请求,非常符合这种情况。
关闭的方法如下:
# 不会持久化,机器重启后失效,如果需持久化,需要修改配置文件。
sudo sysctl -w net.ipv4.tcp_slow_start_after_idle=0
线上验证
灰度了少量机器发现,各个调用对的耗时下降 5% 到 20% 不等,主要取决于QPS 和实例数量。因为涉及一些敏感信息,就不放截图啦~
总结
如果能在内网机器上推全配置,就能充分发挥 TCP 长连接的优势,对于 TCP 长连接上的非持续数据流,降低传输延迟。不仅适用于 RPC 等场景,只要是基于 TCP 连接的服务都有可能受益,比如 HTTP,Redis,MQ 等。而且不限制编程语言,Java/C++/Go/Python 也能从中获得收益。对于在线类业务,比如从 API 开始,RPC 调用的每一跳都能降低延迟(可能有的多,有的少),只要内网带宽足够,就没有负面影响,关键路径的延迟优化累加到一起,进而从整体上优化用户的访问延迟。
以上是关于记一次RPC耗时调优的主要内容,如果未能解决你的问题,请参考以下文章