Graph-DFS 图的深度优先搜索
Posted 姑苏澄外有寒山
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Graph-DFS 图的深度优先搜索相关的知识,希望对你有一定的参考价值。
深度优先搜索和广度优先搜索一样,都是对图进行搜索的算法,目的也都是从起点开始搜索直到到达指定顶点(终点)。深度优先搜索会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条候补路径。
A 为起点,G 为终点。一开始我们在起点 A 上。
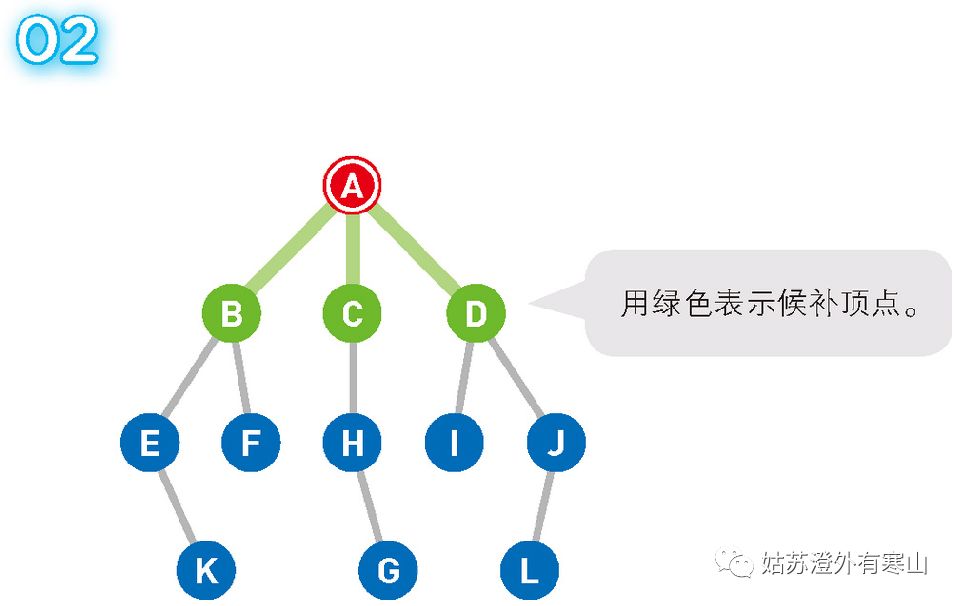 将可以从 A 直达的三个顶点 B、C、D 设为下一步的候补顶点。
将可以从 A 直达的三个顶点 B、C、D 设为下一步的候补顶点。
 从候补顶点中选出一个顶点。优先选择最新成为候补的点,如果几个顶点同时成为候补,那么可以从中随意选择一个。
从候补顶点中选出一个顶点。优先选择最新成为候补的点,如果几个顶点同时成为候补,那么可以从中随意选择一个。
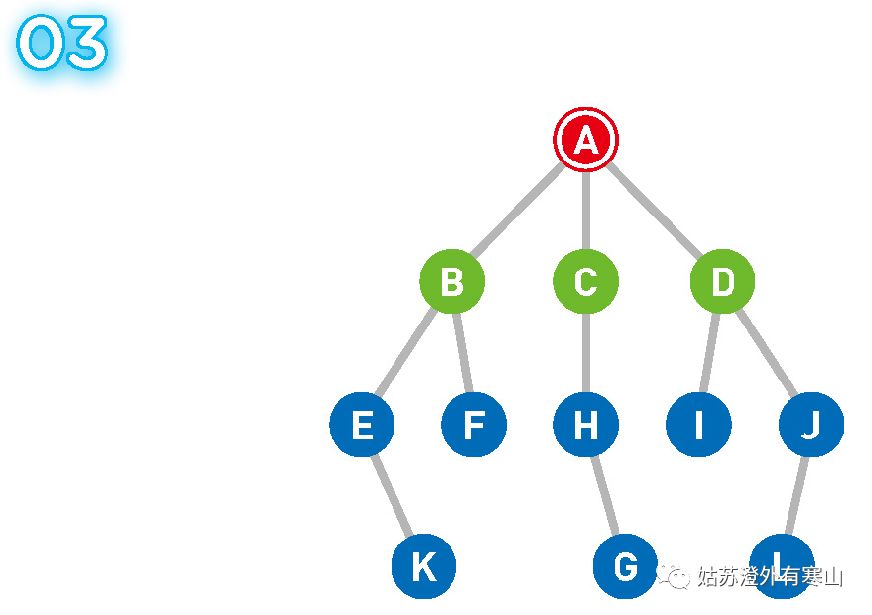
 此处 B、C、D 同时成为候补,所以我们随机选择了最左边的顶点。
此处 B、C、D 同时成为候补,所以我们随机选择了最左边的顶点。
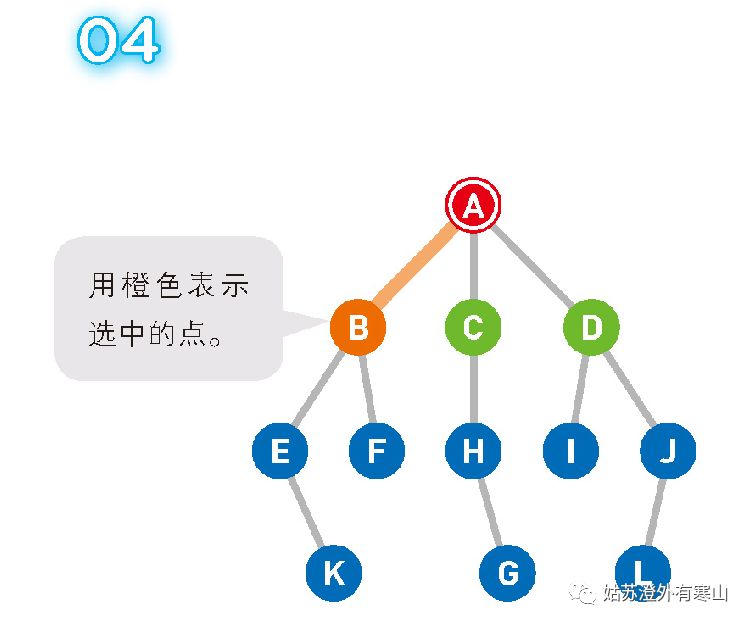
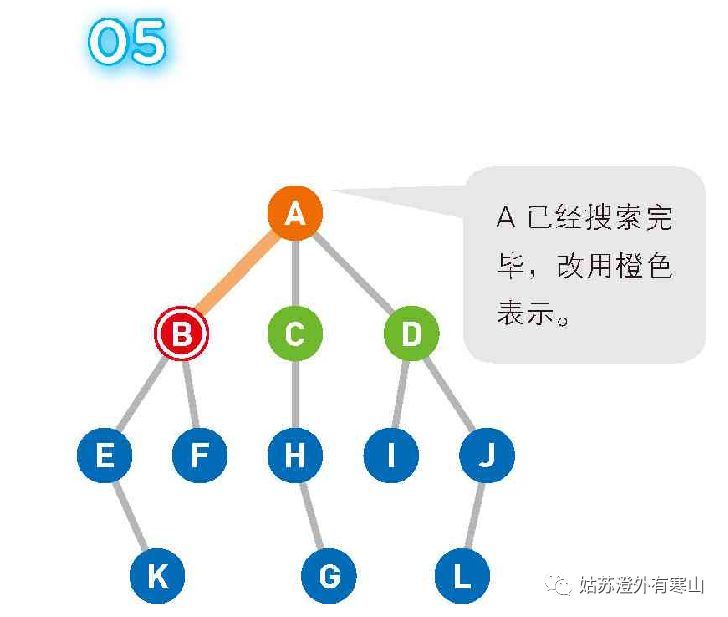 移动到选中的顶点 B。此时我们在B上,所以 B 变为红色,同时将已经搜索过的顶点变为橙色。提示 此处,候补顶点是用“后入先出”(LIFO)的方式来管理的,因此可以使用“栈”这个数据结构。
移动到选中的顶点 B。此时我们在B上,所以 B 变为红色,同时将已经搜索过的顶点变为橙色。提示 此处,候补顶点是用“后入先出”(LIFO)的方式来管理的,因此可以使用“栈”这个数据结构。
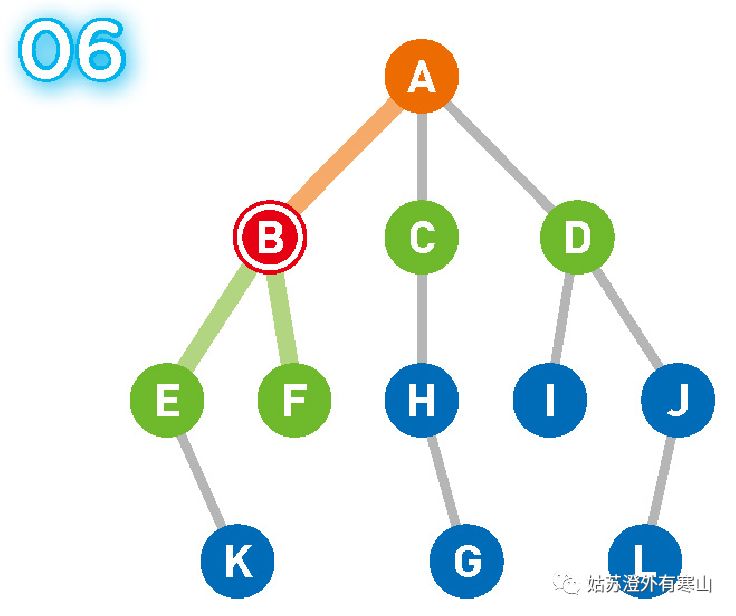 将可以从 B 直达的两个顶点 E 和 F 设为候补顶点。
将可以从 B 直达的两个顶点 E 和 F 设为候补顶点。
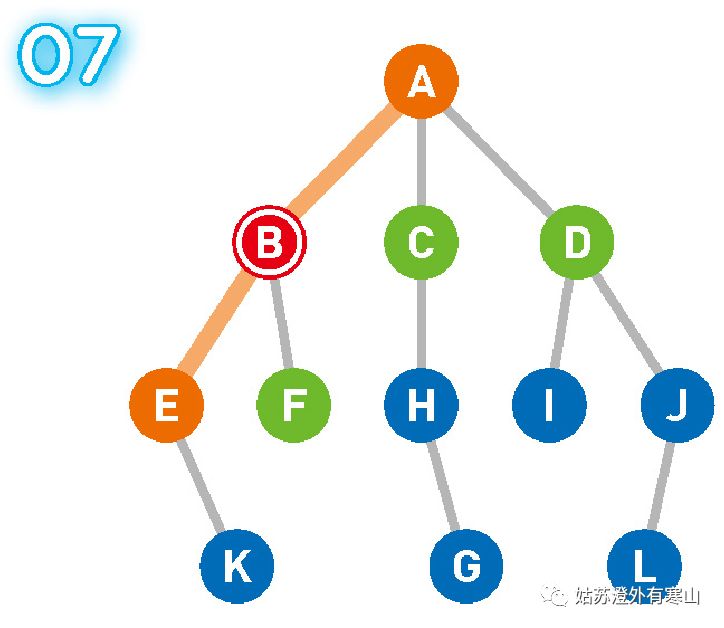 此时,最新成为候补顶点的是 E 和 F,我们选择了左边的顶点 E。
此时,最新成为候补顶点的是 E 和 F,我们选择了左边的顶点 E。
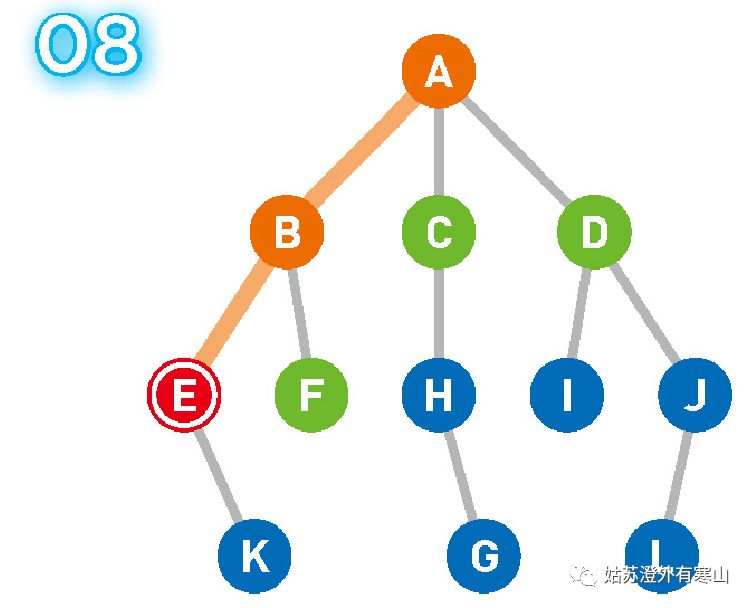 移动到选中的顶点 E 上。
移动到选中的顶点 E 上。
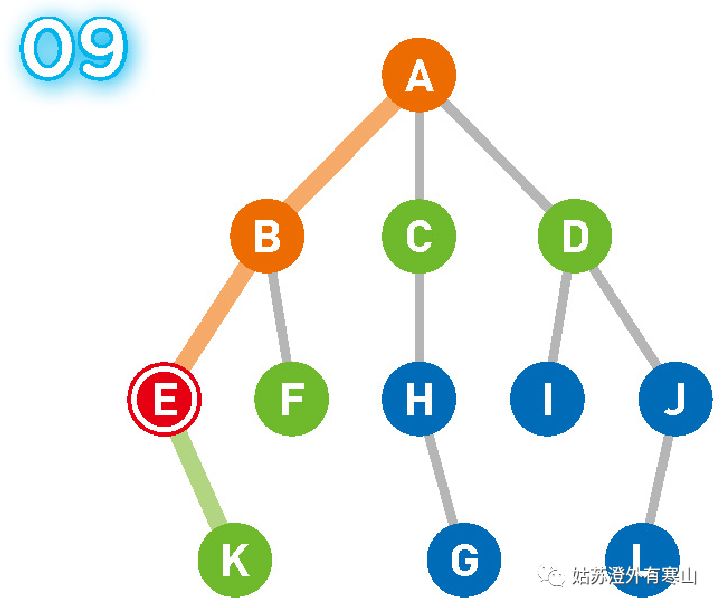 将可以从 E 直达的顶点 K 设为候补顶点。
将可以从 E 直达的顶点 K 设为候补顶点。
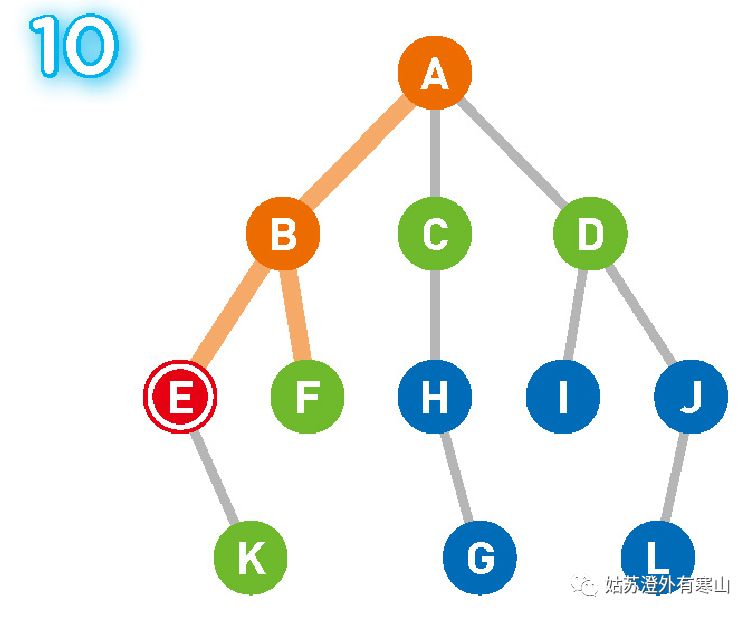 重复上述操作直到到达终点,或者所有顶点都被遍历为止。
重复上述操作直到到达终点,或者所有顶点都被遍历为止。
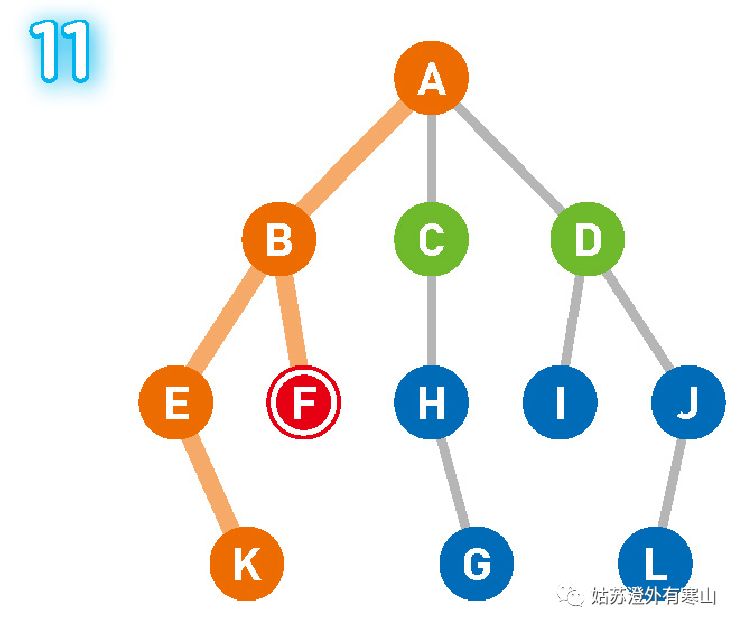 这个示例的搜索顺序为 A、B、E、K、F、C、H。
这个示例的搜索顺序为 A、B、E、K、F、C、H。
现在我们搜索到了顶点 C。
到达终点 G,搜索结束。
解说 深度优先搜索的特征为沿着一条路径不断往下,进行深度搜索。虽然广度优先搜索和深度优先搜索在搜索顺序上有很大的差异,但是在操作步骤上却只有一点不同,那就是选择哪一个候补顶点作为下一个顶点的基准不同。 广度优先搜索选择的是最早成为候补的顶点,因为顶点离起点越近就越早成为候补,所以会从离起点近的地方开始按顺序搜索;而深度优先搜索选择的则是最新成为候补的顶点,所以会一路往下,沿着新发现的路径不断深入搜索。
原文:https://github.com/kafka-soda/Algorithm-C/blob/master/Graph-DFS/graph_dfs.md
算法的解释来自《我的第一本算法书》
代码实现:https://github.com/kafka-soda/Algorithm-C/blob/master/Graph-DFS/graph_dfs.c
以上是关于Graph-DFS 图的深度优先搜索的主要内容,如果未能解决你的问题,请参考以下文章