使用 Rook Operator 快速搭建 Ceph 集群
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Rook Operator 快速搭建 Ceph 集群相关的知识,希望对你有一定的参考价值。
参考技术A Rook 是一个开源的云原生存储编排工具,提供平台、框架和对各种存储解决方案的支持,以和云原生环境进行本地集成。Rook 将存储软件转变成自我管理、自我扩展和自我修复的存储服务,通过自动化部署、启动、配置、供应、扩展、升级、迁移、灾难恢复、监控和资源管理来实现。Rook 底层使用云原生容器管理、调度和编排平台提供的能力来提供这些功能。
Rook 利用扩展功能将其深度集成到云原生环境中,并为调度、生命周期管理、资源管理、安全性、监控等提供了无缝的体验。有关 Rook 当前支持的存储解决方案的状态的更多详细信息,可以参考 Rook 仓库 的项目介绍。不过目前 Rook 已经很好地提供了对 Ceph 的支持,本文简单为大家介绍如何使用 Rook 来快速搭建 Ceph 集群。
本文试验环境:
我们这里部署 release-1.1 版本的 Rook,点击查看部署使用的部署清单文件。从上面链接中下载 common.yaml 与 operator.yaml 两个资源清单文件:
在继续操作之前,验证 rook-ceph-operator 是否处于“Running”状态:
现在 Rook Operator 处于 Running 状态,接下来我们就可以创建 Ceph 集群了。为了使集群在重启后不受影响,请确保设置的 dataDirHostPath 属性值为有效得主机路径。更多相关设置,可以查看集群配置相关文档。
创建如下的资源清单文件:(cluster.yaml)
然后直接创建即可:
我们可以通过 kubectl 来查看 rook-ceph 命名空间下面的 Pod 状态,出现类似于如下的情况,证明已经全部运行了:
OSD Pod 的数量将取决于集群中的节点数量以及配置的设备和目录的数量。如果用上面我们的资源清单,则每个节点将创建一个 OSD。rook-ceph-agent 和 rook-discover 是否存在也是依赖于我们的配置的。
要验证集群是否处于正常状态,我们可以使用 Rook 工具箱 来运行 ceph status 命令查看。
Rook 工具箱是一个用于调试和测试 Rook 的常用工具容器,该工具基于 CentOS 镜像,所以可以使用 yum 来轻松安装更多的工具包。我们这里用 Deployment 控制器来部署 Rook 工具箱,部署的资源清单文件如下所示:(toolbox.yaml)
然后直接运行这个 rook-ceph-tools pod:
一旦 toolbox 的 Pod 运行成功后,我们就可以使用下面的命令进入到工具箱内部进行操作:
工具箱中的所有可用工具命令均已准备就绪,可满足您的故障排除需求。例如:
比如现在我们要查看集群的状态,需要满足下面的条件才认为是 健康 的:
存储
对于 Rook 暴露的三种存储类型可以查看对应的文档:
Ceph 有一个 Dashboard 工具,我们可以在上面查看集群的状态,包括总体运行状态,mgr、osd 和其他 Ceph 进程的状态,查看池和 PG 状态,以及显示守护进程的日志等等。
我们可以在上面的 cluster CRD 对象中开启 dashboard,设置 dashboard.enable=true 即可,这样 Rook Operator 就会启用 ceph-mgr dashboard 模块,并将创建一个 Kubernetes Service 来暴露该服务,将启用端口 7000 进行 https 访问,如果 Ceph 集群部署成功了,我们可以使用下面的命令来查看 Dashboard 的 Service:
这里的 rook-ceph-mgr 服务用于报告 Prometheus metrics 指标数据的,而后面的的 rook-ceph-mgr-dashboard 服务就是我们的 Dashboard 服务,如果在集群内部我们可以通过 DNS 名称 http://rook-ceph-mgr-dashboard.rook-ceph:7000 或者 CluterIP http://10.109.8.98:7000 来进行访问,但是如果要在集群外部进行访问的话,我们就需要通过 Ingress 或者 NodePort 类型的 Service 来暴露了,为了方便测试我们这里创建一个新的 NodePort 类型的服务来访问 Dashboard,资源清单如下所示:(dashboard-external.yaml)
同样直接创建即可:
创建完成后我们可以查看到新创建的 rook-ceph-mgr-dashboard-external 这个 Service 服务:
现在我们需要通过 http:// :32381 就可以访问到 Dashboard 了。
但是在访问的时候需要我们登录才能够访问,Rook 创建了一个默认的用户 admin,并在运行 Rook 的命名空间中生成了一个名为 rook-ceph-dashboard-admin-password 的 Secret,要获取密码,可以运行以下命令:
用上面获得的密码和用户名 admin 就可以登录 Dashboard 了,在 Dashboard 上面可以查看到整个集群的状态:
除此之外在使用上面的 CRD 创建 ceph 集群的时候我们还可以通过如下的配置来配置 Dashboard:
每个 Rook 群集都有一些内置的指标 collectors/exporters,用于使用 Prometheus 进行监控。要了解如何为 Rook 群集设置监控,可以按照监控指南中的步骤进行操作。
Kuberntes云原生实战六 使用Rook搭建Ceph集群
大家好,我是飘渺。
今天咱们继续更新Kubernetes云原生实战系列,这是系列文章的第六篇,需要实现在Kuberetes中安装Ceph集群,系列文章,欢迎持续关注。
Rook介绍
Rook https://rook.io 是一个自管理的分布式存储编排系统,可以为Kubernetes提供便利的存储解决方案。
Rook本身并不提供存储,而是在kubernetes和存储系统之间提供适配层,简化存储系统的部署与维护工作。
目前,Rook支持的存储系统包括:Ceph、CockroachDB、Cassandra、EdgeFS、Minio、NFS。当然,Rook支持的最好的还是Ceph 和 NFS。

为什么要使用Rook?
使用Rook的其中一个主要好处在于它是通过原生的Kubernetes机制和数据存储交互。这就意味着你不再需要通过命令行手动配置Ceph。
你想要在一个集群里部署CephFS吗?只需要创建一个YAML文件就行了!
什么?你还想要部署一个支持S3 API的对象存储?行,另外再建一个YAML文件就行!
Ceph介绍
Ceph 是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。Ceph 的统一体现在可以提供文件系统、块存储和对象存储,分布式体现在可以动态扩展。
Ceph支持三种存储:
块存储(RDB):可以直接作为磁盘挂载
文件系统(CephFS):提供POSIX兼容的网络文件系统CephFS,专注于高性能、大容量存储
对象存储(RADOSGW):提供RESTful接口,也提供多种编程语言绑定。兼容S3(是AWS里的对象存储)、Swift(是openstack里的对象存储)
核心组件
Ceph 主要有三个基本进程:
OSD
用于集群中所有数据与对象的存储,处理集群数据的复制、恢复、回填、再均衡,并向其他osd守护进程发送心跳,然后向 Monitor 提供一些监控信息。Monitor
监控整个集群的状态,维护集群的 cluster MAP 二进制表,保证集群数据的一致性。MDS (可选)
为 Ceph 文件系统提供元数据计算、缓存与同步。MDS 进程并不是必须的进程,只有需要使用 CephFS 时,才需要配置 MDS 节点。
安装Ceph集群
通过rook安装ceph集群需要满足以下两个前提条件:
已部署好的Kubernetes集群 (✅)
osd节点需要有未格式化⽂件系统的磁盘(✅)
前置准备
在master1节点下载rook到本地,使用最新版本1.8.8
git clone --single-branch --branch v1.8.8 https://github.com/rook/rook.git给所有需要安装ceph的worker节点安装lvm2
yum install lvm2 -y
#检查是否安装成功
[root@sit-k8s-worker1 ~]# yum list installed | grep lvm2
lvm2.x86_64 7:2.02.187-6.el7_9.5 @iflytekdc-updates
lvm2-libs.x86_64 7:2.02.187-6.el7_9.5 @iflytekdc-updates给worker节点打上标签,保证ceph只安装在这3台worker节点上
kubectl label node k8s-worker1 role=ceph-storage
kubectl label node k8s-worker2 role=ceph-storage
kubectl label node k8s-worker3 role=ceph-storage修改完成后使用命令查看label属性
[root@k8s-master1 ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-worker1 Ready worker 3d17h v1.21.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-worker1,kubernetes.io/os=linux,node-role.kubernetes.io/worker=,role=ceph-storage
k8s-worker2 Ready worker 3d17h v1.21.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-worker2,kubernetes.io/os=linux,node-role.kubernetes.io/worker=,role=ceph-storage
k8s-worker3 Ready worker 3d17h v1.21.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-worker3,kubernetes.io/os=linux,node-role.kubernetes.io/worker=,role=ceph-storage手动下载安装ceph所需镜像
rook 中ceph依赖很多都是使用国外的镜像,下载很慢,而且经常出现400,所以建议直接手动下载。注意,以下脚本在所有节点都需要运行(master 和 worker)
创建可执行文件 ceph.sh,内容如下
image_list=(
csi-node-driver-registrar:v2.5.0
csi-attacher:v3.4.0
csi-snapshotter:v5.0.1
csi-resizer:v1.4.0
csi-provisioner:v3.1.0
)
aliyuncs="registry.aliyuncs.com/it00021hot"
google_gcr="k8s.gcr.io/sig-storage"
for image in $image_list[*]
do
docker image pull $aliyuncs/$image
docker image tag $aliyuncs/$image $google_gcr/$image
docker image rm $aliyuncs/$image
echo "$aliyuncs/$image $google_gcr/$image downloaded."
done同时给其授予可执行权限
chmod +x ceph.sh检查镜像是否下载完成
[root@k8s-worker1 ~]# docker images | grep csi
k8s.gcr.io/sig-storage/csi-node-driver-registrar v2.5.0 cb03930a2bd4 4 months ago 19.6MB
k8s.gcr.io/sig-storage/csi-resizer v1.4.0 551fd931edd5 4 months ago 55.5MB
k8s.gcr.io/sig-storage/csi-snapshotter v5.0.1 53ae5b88a338 4 months ago 55.2MB
k8s.gcr.io/sig-storage/csi-provisioner v3.1.0 c3dfb4b04796 4 months ago 57.7MB
k8s.gcr.io/sig-storage/csi-attacher v3.4.0 03e115718d25 5 months ago 54.8MB修改ceph调度算法,通过节点亲和性让其运行在指定节点上,同时手动指定节点及磁盘
还记得我们之前挂载磁盘的时候给ceph预留了一个空盘吧?现在需要用到了~
先通过lsblk查看盘符,可以看到vdb2是预留给ceph的
[root@k8s-worker2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 478K 0 rom
vda 253:0 0 50G 0 disk
├─vda1 253:1 0 1G 0 part /boot
└─vda2 253:2 0 49G 0 part /
vdb 253:16 0 500G 0 disk
├─vdb1 253:17 0 100G 0 part /var/lib/docker
└─vdb2 253:18 0 400G 0 part然后修改ceph集群配置
vim /root/rook/deploy/examples/cluster.yaml#原始位置大概在138行
# 第一处修改节点亲和性 ,设置为安装ceph的机器节点的标签(本文档worker节点标签role=ceph-storage)
placement:
all:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph-storage
#原始位置大概在215行起,
# Individual nodes and their config can be specified as well, but 'useAllNodes' above must be set to false. Then, only the named
# nodes below will be used as storage resources. Each node's 'name' field should match their 'kubernetes.io/hostname' label.
# 第二处修改
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
config:
journalSizeMB: "4096"
nodes:
- name: "k8s-worker1"
devices:
- name: "vdb2" # 可以通过lsblk查看磁盘信息
config:
storeType: bluestore
- name: "k8s-worker2"
devices:
- name: "vdb2" # 可以通过lsblk查看磁盘信息
config:
storeType: bluestore
- name: "k8s-worker3"
devices:
- name: "vdb2" # 可以通过lsblk查看磁盘信息
config:
storeType: bluestore注意,name 不能够配置为IP,而应该是标签 kubernetes.io/hostname 的内容
修改operator.yaml,让CSI守护进程可以调度到主节点
默认情况下master节点是不允许调度的,但是ceph有些守护进程是需要调度到master去。这一步是为了解决后面出现的问题,如果此时不修改也可以在后面出现问题的时候再改。这些都是经验教训,网上的安装手册不会告诉你有这一步。
先查看一下master节点的污点设置
[root@k8s-master1 ~]# kubectl describe no/sit-k8s-master1 | grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule然后修改rook operator的配置
vim /root/rook/deploy/examples/operator.yaml#原始位置在127行 原有注释去掉后,再往前缩进一格否则报错
CSI_PLUGIN_TOLERATIONS: |
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Exists安装ceph集群
ceph 相关镜像较大,创建集群过程中可能会存在镜像拉取失败问题,可以在worker节点提前下载。所需镜像:rook/ceph:v1.8.8 quay.io/ceph/ceph: v16.2.7 quay.io/cephcsi/cephcsi:v3.5.1
创建ceph所需要的资源
cd /root/rook/deploy/examples
kubectl apply -f crds.yaml -f common.yaml -f operator.yaml执行完成后等待容器启动,只有完全启动后才能执行进行下一步操作。
[root@k8s-master1 examples]# kubectl -n rook-ceph get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rook-ceph-operator-84985d69d4-z5bkq 1/1 Running 0 18m 109.233.110.2 dev-k8s-worker3 <none> <none>
#此处注意是否启动成功,如果没有启动成功使用 kubectl describe pod rook-ceph-operator-84985d69d4-z5bkq -n -n rook-ceph 检查安装ceph集群
需要先修改一下集群osd的资源限制,否则osd的内存使用率会无限增长(同样是经验教训)
cd /root/rook/deploy/examples
vim cluster.yaml在186行处加入资源限制,建议内存设置4G以上,同时需要注意yaml文件的格式。
resources:
osd:
limits:
cpu: "2"
memory: "8000Mi"
requests:
cpu: "2"
memory: "8000Mi"修改保存后执行以下命令安装ceph集群
kubectl apply -f cluster.yaml创建完成后,可以查看pod的状态:
[root@k8s-master1 examples]# kubectl -n rook-ceph get pod
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-gjmhv 3/3 Running 0 8m7s
csi-cephfsplugin-l2vz6 3/3 Running 0 8m7s
csi-cephfsplugin-provisioner-6f54f6c477-rnql9 6/6 Running 0 8m7s
csi-cephfsplugin-provisioner-6f54f6c477-vgvnj 6/6 Running 0 8m7s
csi-cephfsplugin-zplbg 3/3 Running 0 8m7s
csi-rbdplugin-54cgx 3/3 Running 0 8m7s
csi-rbdplugin-7795w 3/3 Running 0 8m7s
csi-rbdplugin-dtnqk 3/3 Running 0 8m7s
csi-rbdplugin-provisioner-6d765b47d5-g2lzc 6/6 Running 0 8m7s
csi-rbdplugin-provisioner-6d765b47d5-klk9n 6/6 Running 0 8m7s
rook-ceph-crashcollector-k8s-worker1-7598585c9b-49czg 1/1 Running 0 5m23s
rook-ceph-crashcollector-k8s-worker2-675d7c66f-lzw4n 1/1 Running 0 5m11s
rook-ceph-crashcollector-k8s-worker3-656f47985d-k4h96 1/1 Running 0 5m35s
rook-ceph-mgr-a-c9bf8bb54-kvgbw 1/1 Running 0 5m40s
rook-ceph-mon-a-55b778d66d-dl8h6 1/1 Running 0 8m1s
rook-ceph-mon-b-65f6d54689-zxblk 1/1 Running 0 7m26s
rook-ceph-mon-c-dc947478f-2jt2r 1/1 Running 0 5m53s
rook-ceph-operator-84985d69d4-z5bkq 1/1 Running 0 18h
rook-ceph-osd-0-d77bf645f-mk9j7 1/1 Running 0 5m12s
rook-ceph-osd-1-b7d7c47d-2kz5p 1/1 Running 0 5m11s
rook-ceph-osd-2-78fbd4bdc7-zbjsz 1/1 Running 0 5m11s
rook-ceph-osd-prepare-k8s-worker1-hzq7l 0/1 Completed 0 5m19s
rook-ceph-osd-prepare-k8s-worker2-8pqlk 0/1 Completed 0 5m19s
rook-ceph-osd-prepare-k8s-worker3-kb2q9 0/1 Completed 0 5m19s以上是所有组件的 pod 完成后的状态,以rook-ceph-osd-prepare 开头的 pod 用于自动感知集群新挂载硬盘,只不过我们前面手动指定了节点,所以这个不起作用。osd-0、osd-1、osd-2容器必须是存在且正常的,如果上述pod均正常运行成功,则视为集群安装成功。
安装ceph dashboard
Ceph Dashboard 是一个内置的基于 Web 的管理和监视应用程序,它是开源 Ceph 发行版的一部分。通过 Dashboard 可以获取 Ceph 集群的各种基本状态信息。
默认的 ceph 已经安装的 ceph-dashboard,其 SVC 地址是 service clusterIP,并不能被外部访问,需要创建 service 服务
kubectl apply -f dashboard-external-https.yaml创建NodePort类型就可以被外部访问了
[root@k8s-master1 ~]# kubectl get svc -n rook-ceph|grep dashboard
rook-ceph-mgr-dashboard ClusterIP 109.233.40.229 <none> 8443/TCP 8m28s
rook-ceph-mgr-dashboard-external-https NodePort 109.233.34.181 <none> 8443:32234/TCP 29s浏览器访问(master1-ip换成自己的集群ip):https://master1-ip:32234/
用户名默认是admin,至于密码可以通过以下代码获取:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="['data']['password']"|base64 --decode && echo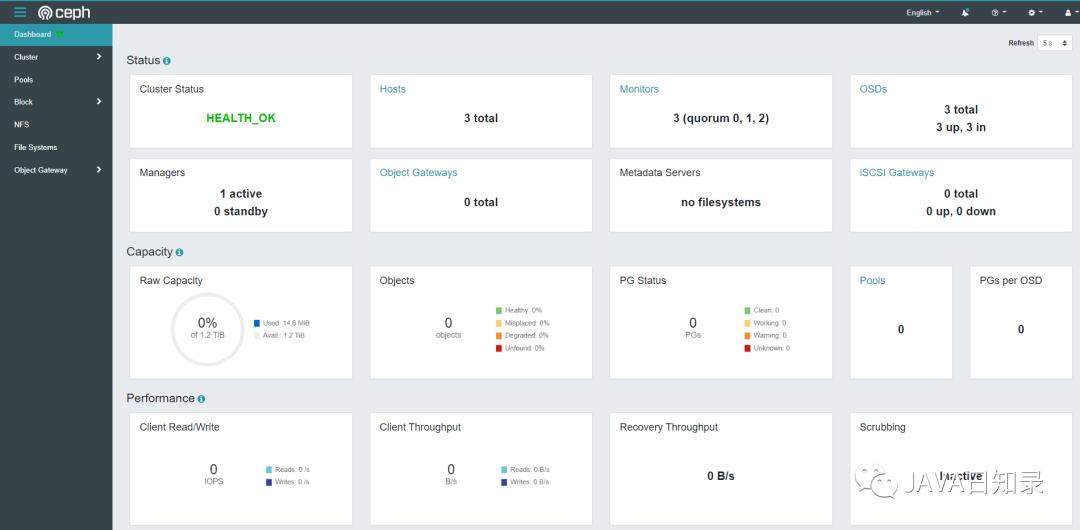
安装rook工具箱
Rook 工具箱是一个包含用于 Rook 调试和测试的常用工具的容器,安装很简单
cd /root/rook/deploy/examples
kubectl apply -f toolbox.yaml -n rook-ceph待容器Running后,即可执行相关命令:
[root@k8s-master1 ~]# kubectl get po -n rook-ceph | grep tools
rook-ceph-tools-775f4f4468-dcg4x 1/1 Running 0 2m12s
[root@k8s-master1 ~]# kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='.items[0].metadata.name') -- bash
[rook@rook-ceph-tools-775f4f4468-dcg4x /]$ ceph -s
cluster:
id: cea16e6d-ef51-4cfd-aa15-3a0e13075071
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 28m)
mgr: a(active, since 27m)
osd: 3 osds: 3 up (since 28m), 3 in (since 28m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 15 MiB used, 1.2 TiB / 1.2 TiB avail
pgs:
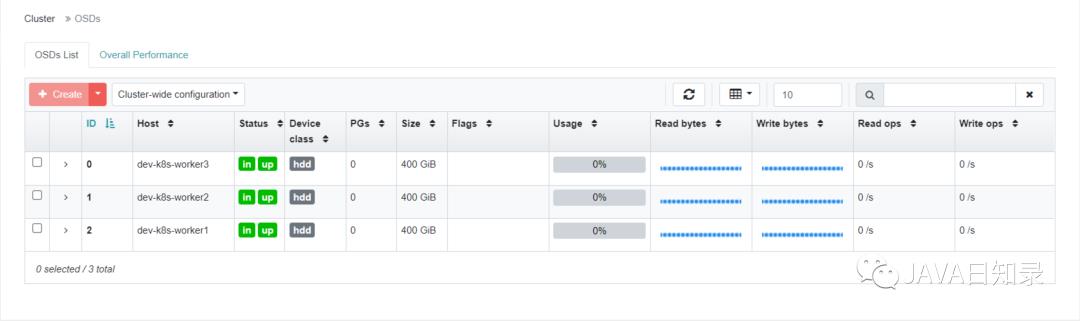
[rook@rook-ceph-tools-775f4f4468-dcg4x /]$ ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 dev-k8s-worker3 4976k 399G 0 0 0 0 exists,up
1 dev-k8s-worker2 4976k 399G 0 0 0 0 exists,up
2 dev-k8s-worker1 4976k 399G 0 0 0 0 exists,up工具箱相关查询命令
ceph status
ceph osd status
ceph df
rados df部署 RBD StorageClass
Ceph 可以同时提供对象存储 RADOSGW、块存储 RBD、文件系统存储 Ceph FS。RBD 即 RADOS Block Device 的简称,RBD 块存储是最稳定且最常用的存储类型。RBD 块设备类似磁盘可以被挂载。RBD 块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在 Ceph 集群的多个 OSD 中。注意:RBD只支持ReadWriteOnce存储类型
创建 StorageClass
cd /root/rook/deploy/examples/csi/rbd
kubectl apply -f storageclass.yaml校验pool安装情况
[root@k8s-master1 ~]# kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='.items[0].metadata.name') -- bash
[root@rook-ceph-tools-775f4f4468-dcg4x /]# ceph osd lspools
1 device_health_metrics
2 replicapool查看StorageClass
[root@k8s-master1 rbd]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 43s将Ceph设置为默认存储卷
[root@k8s-master1 ~]# kubectl patch storageclass rook-ceph-block -p '"metadata": "annotations":"storageclass.kubernetes.io/is-default-class":"true"'修改完成后再查看StorageClass状态(有个default标识)
[root@k8s-master1 rbd]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block (default) rook-ceph.rbd.csi.ceph.com Delete Immediate true 108s小结
通过上面的步骤我们已经给Kubernetes集群安装了Ceph存储,至此我们的高可用集群就已经搭建完毕,甚至可以直接在生产环境使用了。同时也可以看到使用Rook安装Ceph还是很简单的,只需要执行对应的yaml文件即可。
不过要注意的是我们目前给集群安装的StorageClass是基于RBD的块存储,只支持ReadWriteOnce存储类型,如果你要使用ReadWriteMany存储类型,还需要安装CephFs存储。
好了,今天的文章到这里就结束了,如果你喜欢这个系列,请不要吝啬你的一键三连。同时也欢迎你把这个系列分享给你的朋友,我们一起进步。。。我们下期再见。
最后说一句(别白嫖,求关注)
新开了一个纯技术交流群(一群已满),群里氛围还不错,无广告,无套路,单纯的吹牛逼,侃人生,想进的可以通过下方二维码加我微信,备注进群!

以上是关于使用 Rook Operator 快速搭建 Ceph 集群的主要内容,如果未能解决你的问题,请参考以下文章
Kuberntes云原生实战六 使用Rook搭建Ceph集群
Kuberntes云原生实战六 使用Rook搭建Ceph集群