解读新一代数据库转型:分布式图数据库核心架构设计
Posted 星环科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读新一代数据库转型:分布式图数据库核心架构设计相关的知识,希望对你有一定的参考价值。
2019年12月5-7日,由中国计算机学会主办,CCF大数据专家委员会承办的2019中国大数据技术大会于北京隆重举行。超过百位技术专家及行业领袖齐聚于此,聚焦大数据技术如何促进数字经济迅速发展,深入解析热门技术在行业中的实践和落地。星环科技资深架构师王志平在会上分享“分布式图数据库核心架构设计”。此为速记整理,一切以现场信息为准。
王志平:大家好!我是星环科技资深架构师,非常高兴有机会和大家在此分享分布式图数据库核心架构设计。分布式图数据库目前是比较小众领域的产品。我毕业于上海交通大学,加入星环以后一直从事图数据库的开发工作,目前担任图数据库产品组组长。
今天的介绍分为几个部分:

图数据库简介
星环图数据库StellarDB介绍
案例分享
一
图数据库简介
图数据库是比较小众的领域,但从DB-Engines的统计数据来看,图数据库在最近五年内的关注度和受欢迎程度远超其他类型的数据库,特别从2016、2017年起,机器学习和数据挖掘成为热点,知识图谱、风险发现、深度学习等技术被频繁讨论,其实这些技术的核心都是图存储和图计算。
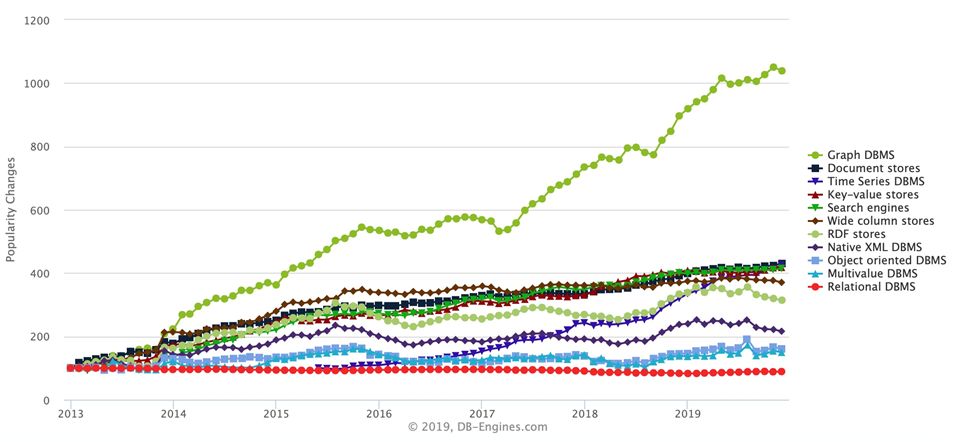
图数据库在演化过程中,在数据模型和存储模型方面发展出了多款优秀产品。按照不同的数据模型,图数据库可分为属性图数据库和RDF数据库。属性图数据库的点(实体)和边(关系)上携带不同类型属性,而RDF数据库用于学术研究和搜索引擎。在底层存储方面,部分图数据库可以同时支持KV、Document等数据模型存储,我们称之为Multi-Model类型数据库;与其对应的,是只存储图数据的Native Storage。
在图数据库早期发展时,开发者使用关系型数据库来描述图模型。举个简单的例子,客户购买商品产生的订单,可以通过用户表、商品表、订单表的join得到完整的客户、订单和商品信息。当数据量比较多的时候,就很难通过这种方式得到查询结果,而这就是图数据库相较于关系型数据库的优势。和SQL类似,图数据库拥有自己的查询语言,如Cypher、Gremlin、PGQL、SPARQL等。
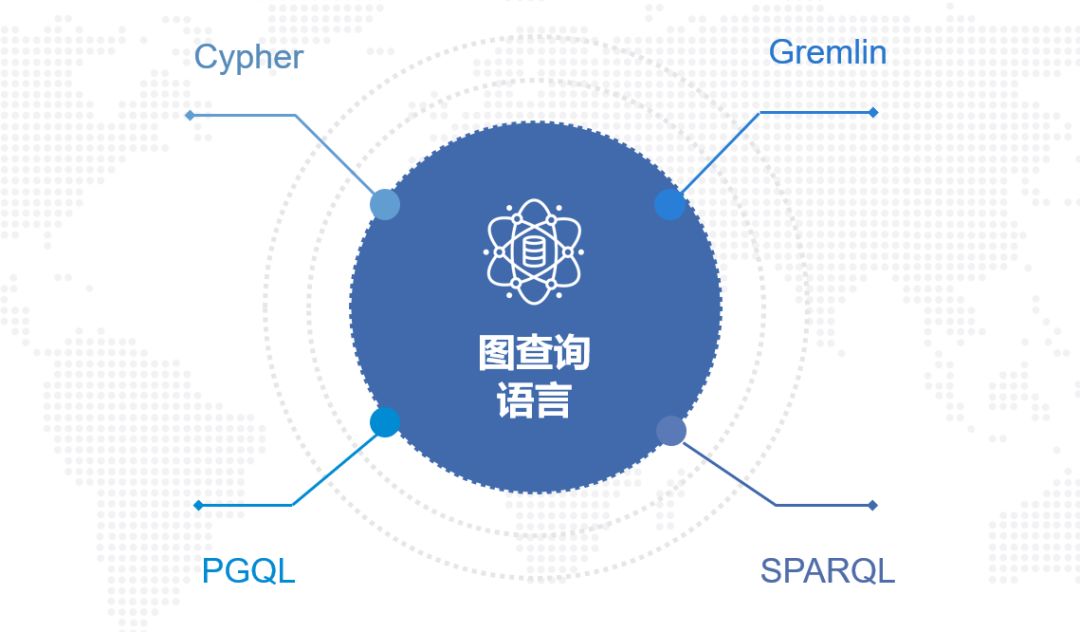
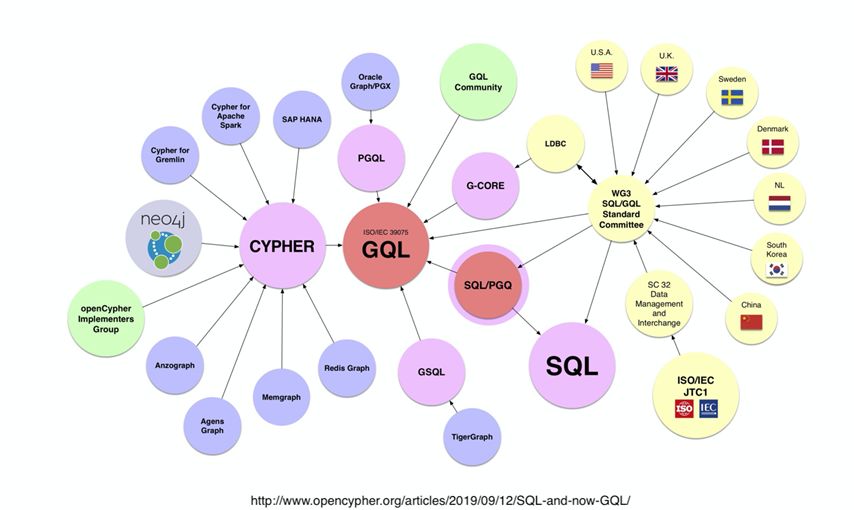
随着图数据库语言的发展,从开始的百家争鸣逐渐趋向于形成统一的标准。目前ISO标准组织正在制定一套像SQL一样的图数据库标准GQL,预计将于明年底发布。
二
StellarDB功能简介
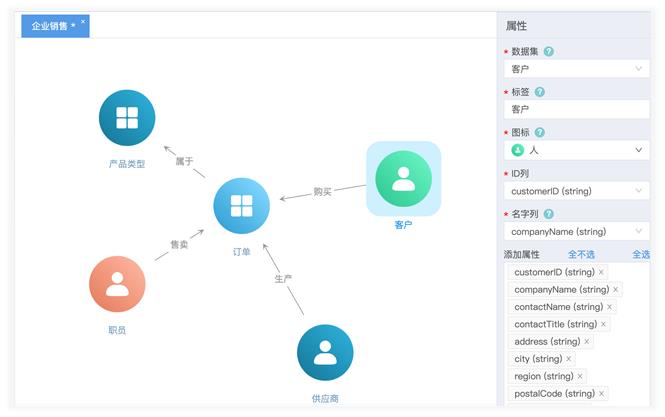
星环图数据库StellarDB功能分五类:图建模、图存储、图分析、图查询、图展示,基本囊括图的各种业务场景。下图是交互式平台的建模示例,用户可以通过拖拽方式定义图中点、边的类型,并可以关联数据源表。
StellarDB依托星环大数据平台运行,我们通过自研的文件存储结构,基于分布式存储平台,为上层图查询和图分析提供有力支撑。
StellarDB的分布式计算层在优化后,可以同时兼容SQL和图数据库的分布式执行,以及图数据库查询的分布式执行,实现对于海量图数据的查询和图算法运行。
StellarDB扩展了openCypher语法,作为图数据库查询语言,同时以Java API和Spark RDD方式允许用户获取图数据。对于数据分析人员,可以通过SophonKG的可视化交互页面,来探索挖掘图的隐含价值。
StellarDB的系统模型是Master跟Worker主从的结构;数据模型是属性图,点跟边上都会带有不同的属性跟类型。StellarDB总体而言可以存储很多张图,就像SQL里的多张表一样。

三
案例分享
接下来简单介绍两个案例:

第一个案例是群体关系查找,此案例的特点是数据量极大。增量数据是日增10亿,底量数据是95亿点,6485亿边。业务场景分为三种,首先是是查询单人多层关联关系,第二种是查询两人K层内关联关系,第三种是查询N人间相互关系。客户原来的使用方案是Hive+HBase,用Hive作多层的数据加工,把加工结果写到HBase里,查询时直接查Hbase。这种做法的缺点是在一开始数据加工时间太长,100台节点正常加工一次的话需要4个小时,对于客户日常的生产集群压力非常大,所以希望星环科技可以对原方案进行改进。
StellarDB的方案上线成功以后,只用了10个节点,数据加工时长缩短为20分钟。StellarDB替代了原来Hive+Hbase的多次join表关联,在减少集群规模的情况下,导入效率还实现了极大提升。
第二个案例是金融行业的反洗钱监控分析,由于每家银行的数据类型不同,数据源不一,有核心业务、资金帐号、第三方存管等,因此,我们首先会对数据做清洗和存储,把这一系列的数据导到对应的数据库里。之后,指定某些指标对数据进行加工,基于规则处理出对应的报表和模型,然后再融入现有银行客户的反洗钱监控系统,加上人工判别,实现规则补全和模型修正的双向核查。
反洗钱案例使用了数据挖掘技术,对原始数据做特征工程,把数据特征挖掘出来后存到图数据库里。带有丰富特征的图方便用户在交互式平台上把感兴趣或者可疑的帐号都找出来,之后运用图算法,对相应特征进行聚合、发现、链路等分析,帮助用户对原有规则模型进行补充,从而降低可疑交易误报、漏报率,更加直观地识别可疑团伙、账号或交易模式。

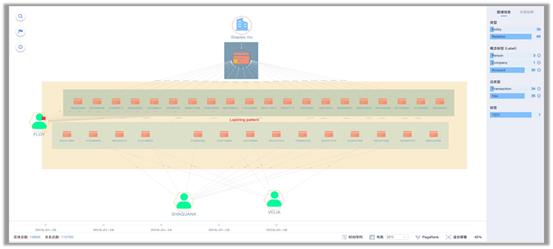
图数据库在跟数据挖掘或者传统的报表方式结合后,会发觉出非常大的潜在价值。这是反洗钱案例的分析界面,可以看到这里有帐户和转帐关系,帐户用图标表示,转帐关系用两两之间的线表示。这种呈现方式在用SQL查询时无法做到,无法直观地看到当前的图长什么样,这也是图数据库的魅力所在,因为所见即所得,它跟我们生活很像,很容易能够理解。
四
扩展工作
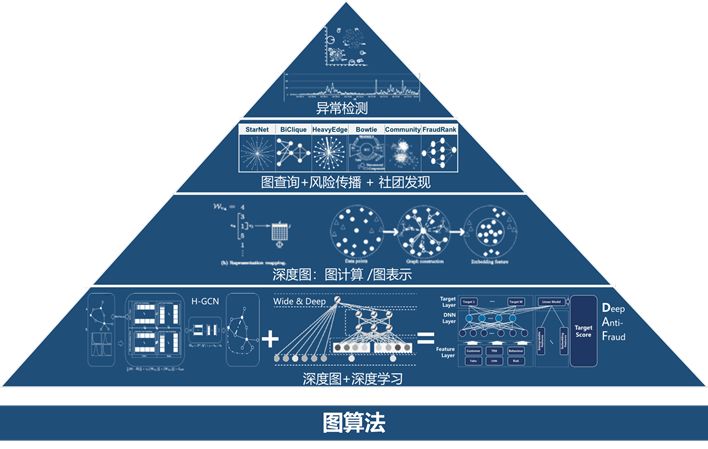
简单介绍一下图数据库产品上的扩展工作。这两年神经网络很火,我们在图数据库方面看到了应用前景,目前StellarDB在深度学习领域实现了多种Graph Embedding算法。对于图数据库的使用,我们希望给用户提供一个完整的平台,同时支持数据查询和算法分析,允许用户将算法结果写回图数据库,并从可视化界面中获得分析结果。
我的分享就到这里,谢谢大家。




以上是关于解读新一代数据库转型:分布式图数据库核心架构设计的主要内容,如果未能解决你的问题,请参考以下文章