本地读写的多活数据存储架构设计要义
Posted EAWorld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本地读写的多活数据存储架构设计要义相关的知识,希望对你有一定的参考价值。
译者:白小白
原文:http://t.cn/AiKO0q4P
原题:Design Considerations in a read local write local multi-master data store
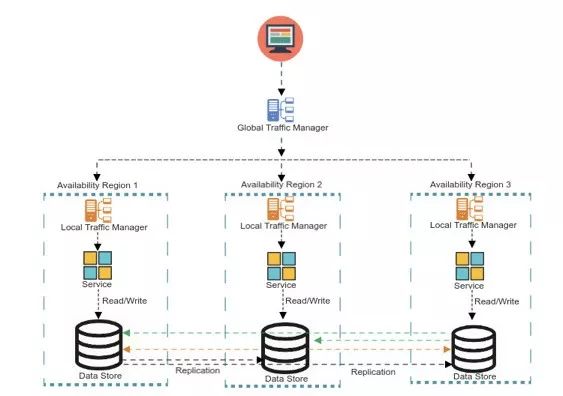
本地读写多活示例
本地读-本地写的多活数据存储架构是最难实现的数据模式之一。这一模式也常被称为“双活”或者“多主”,对于不同行业大容量低延迟的事务类应用而言,这是一种必备的能力。
系统的整体可用性取决于单独组件的可用性。用户界面层、服务层和消息层可以跨分区/跨地域进行横向扩展以提供高可用性,但对于事务性数据存储(尤其是写操作)而言,采用同样的处理方案仍旧充满挑战。无论部署在本地或者云端,很多关系型数据库和noSQL数据库都提供了这种开箱即用的能力。也有一些企业选择自己实现定制化的复制方案来达成多活的目标,对于强烈依赖低延迟的用户尤其如此。忽略方案的差异性,人们需要对一些通用的风险与权衡进行仔细考量。
首当其冲需要考虑的就是在跨可用域的数据复制过程中,是采用同步复制还是异步复制的方案。
同步复制技术需要实现多可用域/可用区间的同步写入。这将会带来很多的问题:
随着可用域的增加,写入延迟也将逐渐增加
域内的服务需要同步的访问域外资源,这通常会令域的回收和转移变得更加复杂
故障检测和恢复会变得越来越复杂。本地域的数据存储写入成功,对其他域的数据存储写入失败,这种情况该怎么处理?其他域的数据存储的不可用,是否应该影响本地域的服务可用性?
鉴于以上的这些因素,异步复制通常是首选方案,从而也引入了最终一致性的话题。
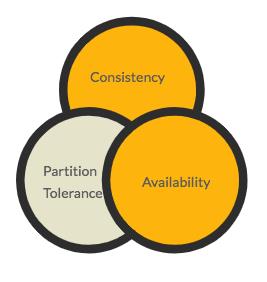
CAP定理
CAP定理指出,对于一个分布式的数据库系统而言,一致性(C)、可用性(A)和分区容忍性(P)三者仅能居其二。因为分区容忍性是现代分布式系统的必备要件,这将归结为在一致性和可用性之间取得一个平衡。PACELC定理进一步扩展了CAP的理念,并指出,即使不考虑分区的情况,仍旧需要在延迟(L)和一致性(C)之间进行一定的权衡。
译注:PACELC中的E即Else,也就是或者。对于有分区的情况,需要权衡AC,或者,在没分区的情况,需要权衡LC
在大量的用例中,最终一致性是可接受的妥协。比如审计或者遵从性日志、产品目录或者搜索索引,对于此类的应用而言,数据存储的最终一致性是完全可接受的。但对于其他一些场景,比如银行事务、航班预订或者股票市场而言,即使是毫秒级的不一致性,也将损害用户体验或者系统可信性。
在这样的情况下,值得评估一下多活的数据存储方案是否符合用户场景的需要。
本地读取-全局写入的方式提供了可用性和一致性之间的平衡,是一种可选的方案。在对某个可用域的主副本数据存储进行写入操作的同时,会在其他可用域生成只读副本。当主副本数据发生单点失败问题的时候,可以在其他可用域中选择一个新的主副本,从而实现快速的故障恢复,这种方式所提供的可用性,对于很多场景来说是可接受的。
另一种方式是分片写入或者分区写入,这将使得可用域中某一份单独的数据存储成为一部分数据的主副本。
一旦决定采用多活的数据存储方案,并且接纳了最终一致性的理念,接下来需要重点考虑的就是采用合适的技术,以缓解和减轻一致性问题所产生的影响。
在多活架构下,数据的异步复制通常采用事件流的方式实现。好处如下:
写入操作的顺序将得以保留。这对很多用户场景来说是必须的。
对于写入失败或者存储不可用的情况,事件复制器将持续的尝试对副本数据的写入操作直到成功,以保证故障可以被恢复。
这一方案的挑战在于,如何让事件复制器处于高可用的状态。这需要在顺序复制和并行复制之间做出设计上的权衡。
在数据复制的过程中,复制器没有办法知道写入的发起者是谁,但写入本身可能存在不一致性或者错误的参数。为了避免写入的过程对业务逻辑造成不可挽回的错误(尤其是在事件的顺序至关重要的场合),复制过程将被阻塞,直到当前的事件已经成功处理,才会继续进行下一项操作。
因此,在写入前进行足够的业务验证是十分必要的,这将避免情况变得难以收拾。一些与网络或者与系统的不可用有关的问题,都是可恢复的,复制器可以用重试的方式对此类情况进行处理。
考虑如下的业务场景:顾客在建立订单后进行了更新或者取消操作。
步骤1:生成订单
步骤2:更新订单
在这种情况下,对于第2步操作来说,应用通常需要获取订单的信息(读),并且更新订单的状态(写)。这是所有订单系统的通用场景,如订票、生产制造、贸易或者零售。
在最终一致性的架构下,如果步骤1和步骤2分属于不同的可用域,这通常会引发一些问题。比如,当步骤1没能及时的复制到步骤2所在的可用域的时候,步骤2的更新操作就可能失败。
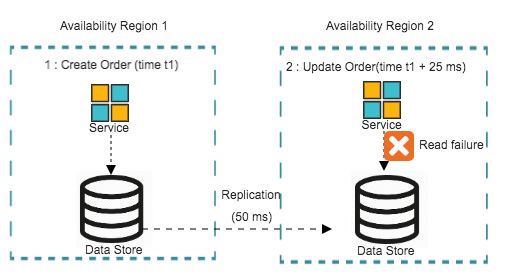
更新操作带来的问题示意
以上的场景带来的不只是用户体验的不理想,更重要的是分引发数据不一致的问题:一种情况是,步骤2的更新的操作可能基于一份过时的数据,甚至步骤1的复制操作覆盖了步骤2的更新操作。
在上面的例子中,考虑了两个事件:订单生成和订单更新。假定接下来又发生了两个事件:订单更新和订单取消。
大多数的数据存储方案会将所有这些事件存储在一个历史实体、审计实体或者细节实体中,用以表征单独的事件。我们称之为“事件实体”。
在很多情况下,订单的当前状态也会被记录,如“已取消”。我们称之为“状态实体”。
对于每一个新的事件而言,有两个必不可少的操作,对事件实体的插入操作,和对状态实体的更新操作。
订单事件示意
没有状态实体,我们就需要去汇总所有的事件或者获取最新的事件来获知订单的状态。
在有些情况下,数据存储仅支持插入而不支持更新。这样就只有事件实体而没有状态实体。这是否有助于补救更新操作所产生的问题呢?完全不会。尤其是在上文提到的读取过时数据的情形下。当然,当复制器之间或者服务写入之间发生冲突的时候,这确实有助于确保数据不会被覆盖。
在此情形下,写入操作的“只插”策略,或者事件溯源的设计方法将很实用。
在上文所提到的更新问题中,插入、读取和更新操作分属于不同的可用域,但却共享一个相同的上下文(如订单ID),只有在这种情况才会发生问题。虽然在理想情况下,服务请求应该是无状态的,但如果与某一个上下文(如用户或者订单)有关的状态可以用Session、Cookie或规则的方式保存在流量管理器中,就可以确保在多数情况下,与某一个特定的上下文有关的一组事件可以被路由到一个共同的可用域。这种程度的会话粘滞或者会话亲和性可以极大的改善数据过时的问题。
作为预防性措施,业务验证、会话粘滞或者事件溯源可以在很大程度上缓解相关的风险,让本地读写多活方案的实现更加健壮。然而,冲突是不可避免的。对于一些场景,尤其是高频的副本复制的场景下,需要认真考虑冲突的解决方案。
一些冲突解决方案包括:
基于时间戳的解决方案:比如,以最新写入的为准
基于规则的解决方案:比如,在进行副本复制的过程中,如果符合某种特定条件,则忽略事件的写入。
虽然多数冲突解决方案可以自动执行,对于一些特定的场景,我们仍旧需要建立一个可视化的用户界面来手动的解决冲突问题。
跨可用域的本地读写的多活实现是一项复杂的的任务,通常需要在应用的数据层以外解决很多问题。这是一种很难实现和治理的模型,仅在低延迟和高可用性不可或缺的场景下才需要考虑。仔细的分析和规划相关的设计考量、妥协和治理要素,将有助于达成最优的解决方案。同时,也需要考虑采用节流方法来理解延迟和可用性之间的平衡。
译注:节流方法(throttled approach):类似机场或者地铁的安检方式,当流量较大的时候,一部分人会被滞留在一个等待区内,直到前面的一批已经安全顺利通过。
推荐阅读
关于EAWorld:微服务,DevOps,数据治理,移动架构原创技术分享,长按二维码关注
以上是关于本地读写的多活数据存储架构设计要义的主要内容,如果未能解决你的问题,请参考以下文章