阿里内部是如何进行架构设计?内部参考文档流出,你该这样准备
Posted Java架构师联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里内部是如何进行架构设计?内部参考文档流出,你该这样准备相关的知识,希望对你有一定的参考价值。
作为工程师,我们一方面关注软件产品的能力和行为,这往往是一个项目的起点,另一方面我们需要关注软件的架构设计,因为我们希望设计有着弹性、易于维护、高性能、高可用的系统,更希望系统能够不断演进,而不是在未来被推倒重做。所以,回正我们的视野,当我们决心要设计一个好的架构时,我们需要明确,架构往往决定的是软件的非功能性需求。这些非功能性需求有:
易于开发:我们希望工程师一进入团队就可以立刻开始进行研发工作,我们希望代码易于阅读与理解,同时开发环境足够简单统一。
方便部署:如果系统的部署成本很高,那使用价值就不会很高了,我们很多企业都存在那种动也不敢动,改也不敢改,停也不敢停的系统,除了祈祷它别挂掉好像没有别的办法。拿到这样的系统真的跟烫手的山芋一样,但是你还没得办法。
易于运维:DevOps 的初衷是建立一种缩短运维与研发距离的文化,让出现问题后更容易处理,希望让大家将视野放在产品上而不是限定自己的工种,这并不是期望运维的同学能够成为 Java 专家,迅速的进行 heap 分析发现问题,我们强调的是运维时的闭环能力。
维护成本:随着时间的推移,给软件增加新功能就会变的越来越难,越是运行长久的项目就会陷入重写还是重构的苦恼。往往风险在于修改代码会增加破坏已有功能的风险,而且技术债也会越来越多难以偿还,即使是重写某些功能和模块,我们也很难确定是否真的覆盖到了所有的功能,简而言之,don't break anything 的确很难做到。
演进能力:良好的架构设计应该能让系统处于易于演进的状态,能够实现给飞驰的汽车换轮胎的能力,而不会被框架、底层的某种数据库、操作系统或者其他东西所绑架,但是这太难以做到了。的确,在项目进行技术选型时,因为某种数据库的特性而有倾向,但是在上层设计中,我们必须保证不依赖于数据库的特性,而将使用这些特性的地方放到底层细节中。我们也需要考虑,不使用 Spring 提供的 Dependency Injection,我们该如何组织我们的 beans,也要考虑将来系统的前端是 web 还是 mobile 还是都要支持?
所以当这一些问题我们都想兼顾的时候,在于进行架构设计的时候考虑的有多细,资源有多雄厚,那些动辄亿级流量或者超大型研发团队,确实能够解决这些问题,就像这次疫情的钉钉,虽然流量的疯狂涌入,但是,瞬间,后台阿里云开通更多的资源容纳这一部分冲击,所以,外界看来,几乎没什么影响,但是,能这样操作的企业又有几家呢?基本都是资源用在刀刃上,那该怎么办呢?互联网巨头阿里出了一份参考手册,共分为三部分
第一部分:企业架构
如果说运维是地基,那么框架就是承重墙。盖房子是先打地基,再建承重墙,最后才垒砖,所以中间件的搭建和引进是建设高可用、高性能、易扩展、可伸缩的大中型系统的前提。所以,一个好的架构设计关系到后期整个项目的稳重

第二部分:技术理解

1.集中式缓存Redis
缓存是计算机的难题之一.,分布式缓存亦是如此。Redis 看起来非常简单,但它影响系统的效率、性能和数据一致性。用好它不容易,包括缓存时长(复杂多维度的计算)、缓存失效处理(主动更新)、缓存键(Hash和方便人工干预)、缓存内容及数据结构的选择、缓存雪崩的处理、缓存穿透的处理等。Redis 除了缓存的功能,还有其他功能,比如Lua计算能力、Limit 与Session 时间窗口、分布式锁等。我们使用SericeStack.Redis做客户端,使用方法详见Demo。

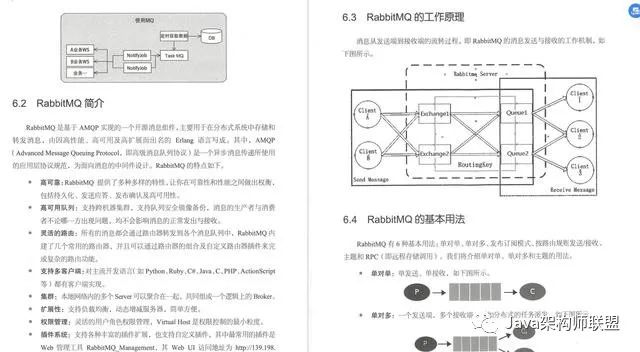
2.消息队列RabbitMQ
消息队列好比葛洲坝,有大量数据的堆积能力,再可靠地进行异步输出。它是EDA事件驱动架构的核心,也是CQRS同步数据的关键。为什么选择RabbitMQ而没有选择Kafka?是因为业务系统对消息有高可靠性要求,以及对复杂功能(如消息确认)的要求。
3.集中式日志ELK
日志主要分为系统日志和应用日志两类。试想一下,如何在- -个具有几百 台服务器的集群中定位问题?如何追踪每天产生的几GB甚至几TB的数据?集中式日志就是此类问题的解决方案。早期我们使用自主研发的Log4Net+MongoDB来收集和检索日志信息,但随着数据量的增加,查询速度却变得越来越慢。后期改为开源的ELK,虽然易用性有所下降,但它支持海量数据及与编程语言无关的特征。

4.任务调度Job
任务调度Job如同数据库作业或Windows计划任务,是分布式系统中异步和批处理的关键。我们的Job分为WinJob和HttpJob: WinJob 是操作系统级别的定时任务,使用开源的框架Quartz.NET实现;而HttpJpob则是自主研发实现的,采用URL方式可定时调

5.应用监控Metrics
“没有度量就没有提升”,度量是改进优化的基础,是做好一个系统的前置条件。
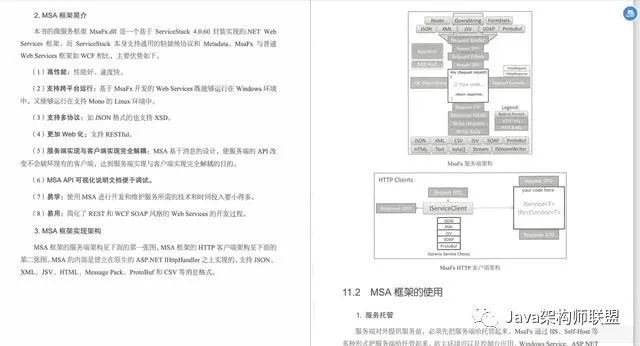
6.微服务框架MSA
微服务是细粒度业务行为的重用,需要与业务能力及业务阶段相匹配。微服务框架是实现微服务及分布式架构的关键组件
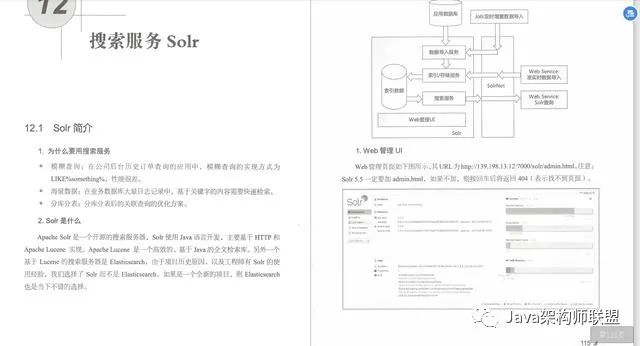
7.搜索服务Solr
分库分表后的关联查询,大段文本的模糊查询,这些要如何实现呢?显然传统的数据库没有很好的解决办法,这时可以借助专业的检索工具。全文检索工具Solr 不仅简单、易用、性能好,而且支持海量数据高并发,只需实现系统两边数据的准实时或定时同步即可。
8.更多工具
分布式协调器 ZooKeeper:工作原理、配置中心、Master 选举、Demo。
ORM 框架: Dapper.NET 语法简单、运行速度快,与数据库无关,SQL自主编写可控,是一款适合互联网系统的数据库访问工具。
对象映射工具 EmitMapper和AutoMapper: EmitMapper的性能较高, AutoMapper的易用性较好。
IoC 框架:控制反转( IoC )轻量级框架Autofac。
DLL 包管理:公司内部DLL包管理工具NuGet,可解决DLL集中存储、更新、引用、依赖的问题。
发布工具Jenkins: -键编译、发布、自动化测试、- -键回滚,高效、便捷、故障率低。
zookeeper

jenkins

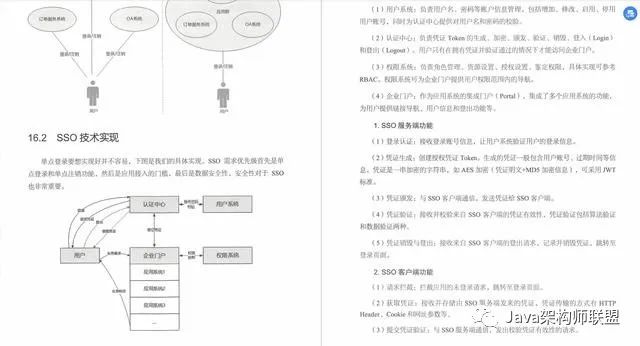
单点登录
企业支付网关
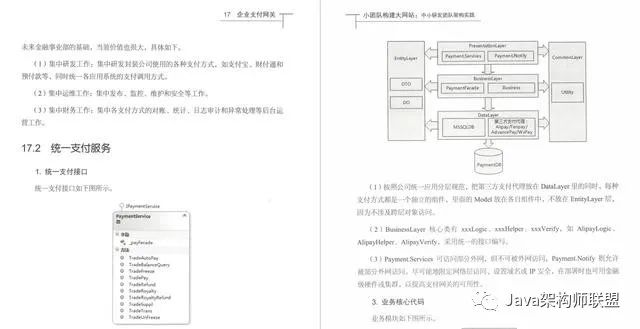
第三部分:技术升级

单体问题
●单体应用,该合并的没有合并,该拆分的没有拆分,单个体量不合理,主平台体量太大,其他又过小。
●技术过旧: 使用7年以前的技术,主平台因采用单体式架构,且体量过大,无法整体更新维护。
●多版本共存: 版本混乱,只敢添加,不敢修改。
●整个系统非常脆弱, 问题多,访问量一大就“挂”。
●管理问题: 发布困难,测试困难,修改困难,排错困难。
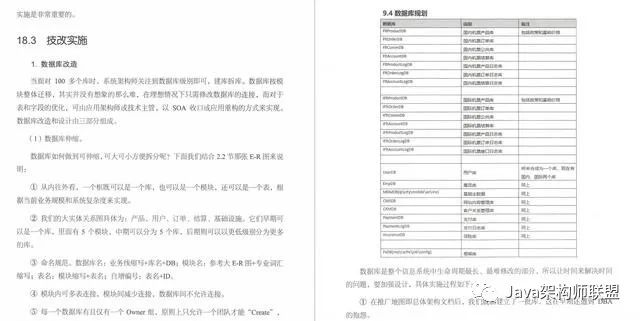
技术改造:从单体应用到微服务
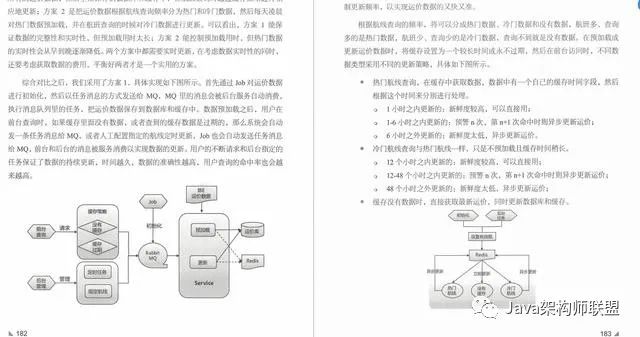
性能优化
上云纪要
技术与业务的匹配和融合
研发团队的发展
感谢大家的阅读,文中可能存在不足或遗漏之处,欢迎批评指正。
部分资料已经上传到我的git仓库中:有需要的可以下载
https://gitee.com/biwangsheng/mxq
以上是关于阿里内部是如何进行架构设计?内部参考文档流出,你该这样准备的主要内容,如果未能解决你的问题,请参考以下文章
阿里巴巴内部流出《Python入门基础教程》,小白到大神最良心的学习资料!