数据库架构设计
Posted 架构师学习路线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库架构设计相关的知识,希望对你有一定的参考价值。
一、数据库之互联网常用架构方案
1.1 目录
一、数据库架构原则
-
高可用 -
高性能 -
一致性 -
扩展性
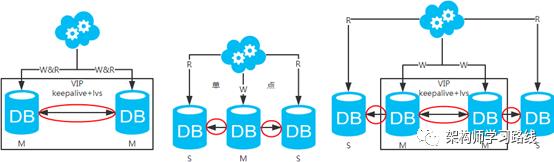
1.2 常见的架构方案
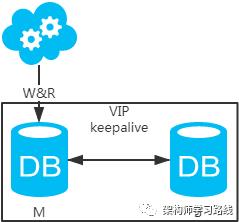
-
高可用分析:高可用,主库挂了,keepalive(只是一种工具)会自动切换到备库。这个过程对业务层是透明的,无需修改代码或配置。 -
高性能分析:读写都操作主库,很容易产生瓶颈。大部分互联网应用读多写少,读会先成为瓶颈,进而影响写性能。另外,备库只是单纯的备份,资源利用率50%,这点方案二可解决。 -
一致性分析:读写都操作主库,不存在数据一致性问题。 -
扩展性分析:无法通过加从库来扩展读性能,进而提高整体性能。 -
可落地分析:两点影响落地使用。第一,性能一般,这点可以通过建立高效的索引和引入缓存来增加读性能,进而提高性能。这也是通用的方案。第二,扩展性差,这点可以通过分库分表来扩展。
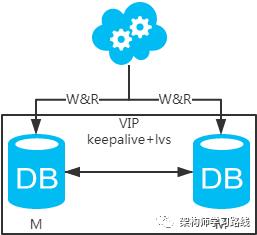
-
高可用分析:高可用,一个主库挂了,不影响另一台主库提供服务。这个过程对业务层是透明的,无需修改代码或配置。 -
高性能分析:读写性能相比于方案一都得到提升,提升一倍。 -
一致性分析:存在数据一致性问题。请看,一致性解决方案。 -
扩展性分析:当然可以扩展成三主循环,但笔者不建议(会多一层数据同步,这样同步的时间会更长)。如果非得在数据库架构层面扩展的话,扩展为方案四。 -
可落地分析:两点影响落地使用。第一,数据一致性问题,一致性解决方案可解决问题。第二,主键冲突问题,ID统一地由分布式ID生成服务来生成可解决问题。
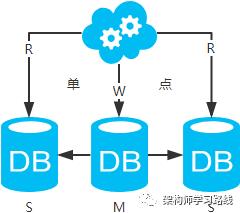
-
高可用分析:主库单点,从库高可用。一旦主库挂了,写服务也就无法提供。 -
高性能分析:大部分互联网应用读多写少,读会先成为瓶颈,进而影响整体性能。读的性能提高了,整体性能也提高了。另外,主库可以不用索引,线上从库和线下从库也可以建立不同的索引(线上从库如果有多个还是要建立相同的索引,不然得不偿失;线下从库是平时开发人员排查线上问题时查的库,可以建更多的索引)。 -
一致性分析:存在数据一致性问题。请看,一致性解决方案。 -
扩展性分析:可以通过加从库来扩展读性能,进而提高整体性能。(带来的问题是,从库越多需要从主库拉取binlog日志的端就越多,进而影响主库的性能,并且数据同步完成的时间也会更长) -
可落地分析:两点影响落地使用。第一,数据一致性问题,一致性解决方案可解决问题。第二,主库单点问题,笔者暂时没想到很好的解决方案。
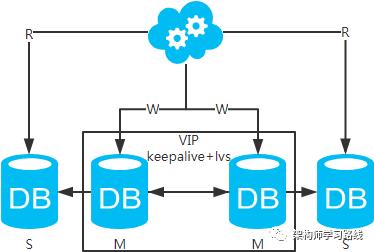
1.3 一致性解决方案
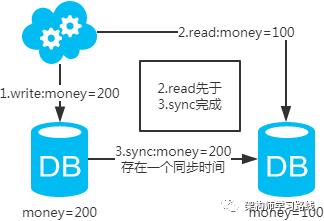
-
直接忽略,如果业务允许延时存在,那么就不去管它。 -
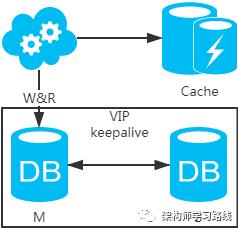
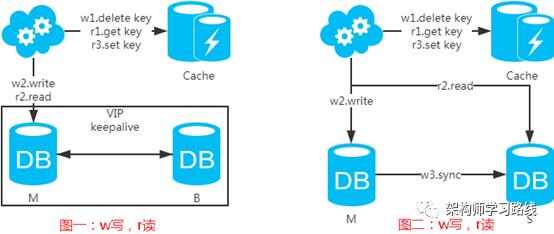
强制读主,采用主备架构方案,读写都走主库。用缓存来扩展数据库读性能 。有一点需要知道:如果缓存挂了,可能会产生雪崩现象,不过一般分布式缓存都是高可用的。
-
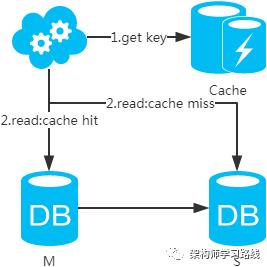
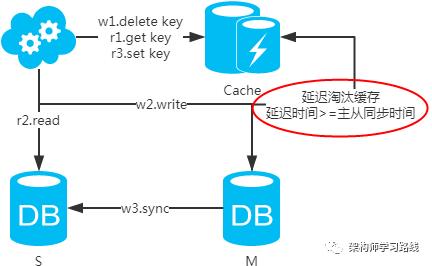
选择读主,写操作时根据库+表+业务特征生成一个key放到Cache里并设置超时时间(大于等于主从数据同步时间)。读请求时,同样的方式生成key先去查Cache,再判断是否命中。若命中,则读主库,否则读从库。代价是多了一次缓存读写,基本可以忽略。
-
半同步复制,等主从同步完成,写请求才返回。就是大家常说的“半同步复制”semi-sync。这可以利用数据库原生功能,实现比较简单。代价是写请求时延增长,吞吐量降低。 -
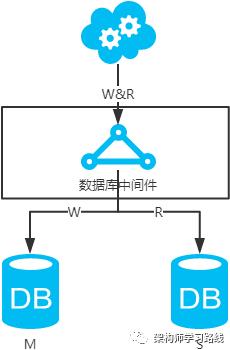
数据库中间件,引入开源(mycat等)或自研的数据库中间层。个人理解,思路同选择读主。数据库中间件的成本比较高,并且还多引入了一层。
 先来看一下常用的缓存使用方式:
先来看一下常用的缓存使用方式:
1.4 VIP(虚拟IP)
1.5 Keepalive
1.6 lvs
二、数据库之互联网常用分库分表方案
2.1 目录
2.2 数据库瓶颈
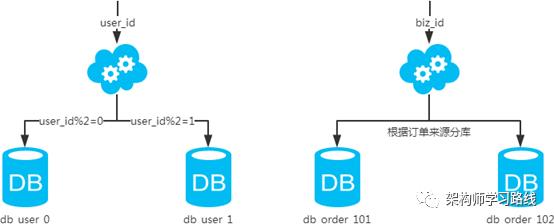
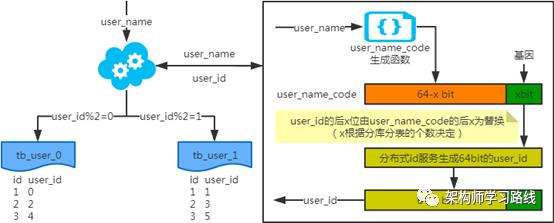
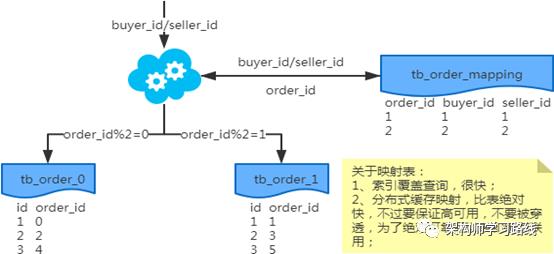
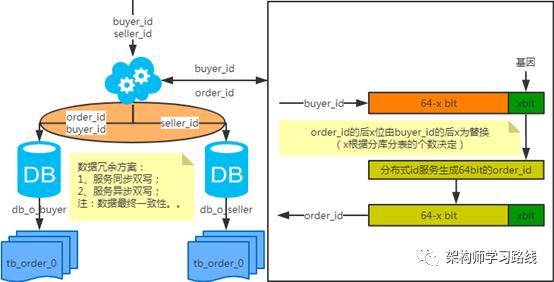
2.3 分库分表
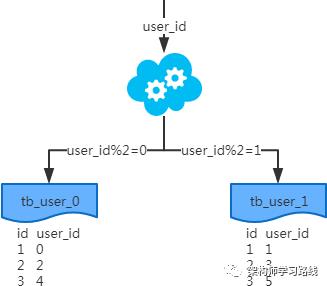
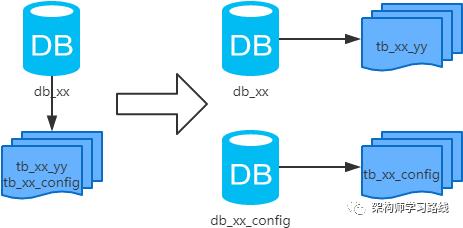
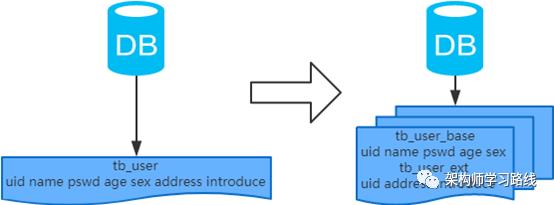
2.4 分库分表工具
2.5 分库分表步骤
2.6 分库分表问题
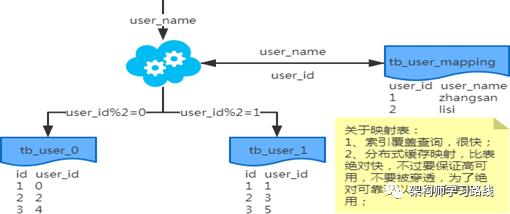
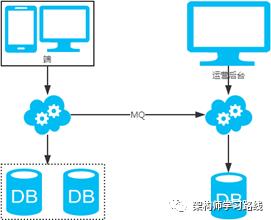
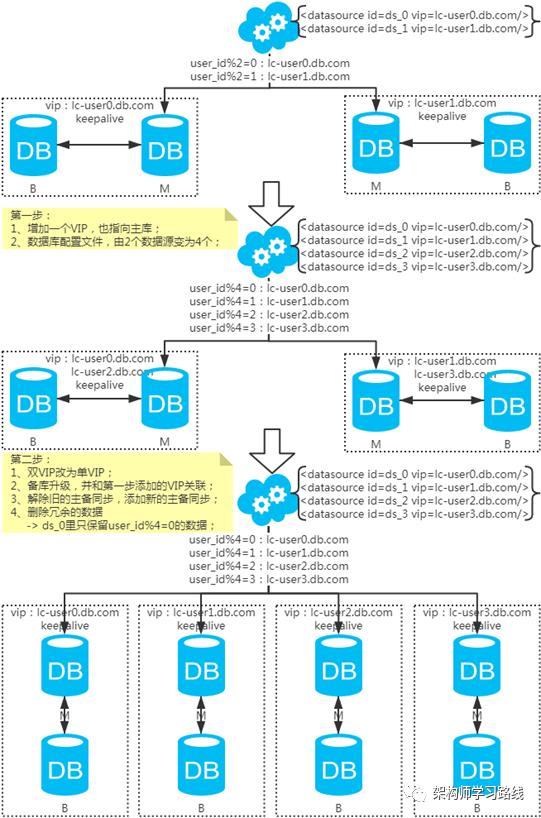
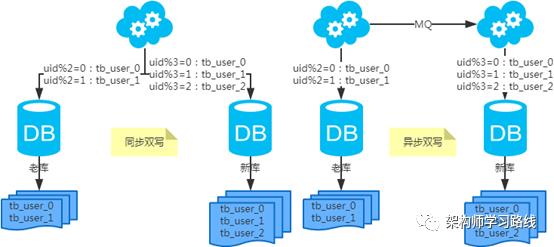
2.7 分库分表总结
三、 数据库规范
3.1 数据库设计框架思维
3.2 命名规范
3.3 字段数据类型设计规范
3.4 整数型字段选择规范
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.5 根据业务选择字段类型规范、默认值规范
3.6 默认建表存在的字段规范
3.7 数据加密规范
3.8 表字段顺序规范
3.9 主键ID规范
3.10 索引设计规范
3.11 数据库容量设计规范
3.12 防止全表扫描规范做法
3.13 如何有效遍历
五、双主架构实现方法
六、主从架构实现方法
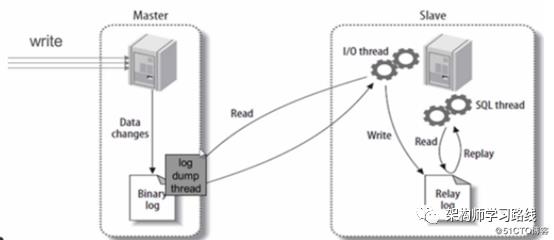
6.1 MySQL主从架构实现
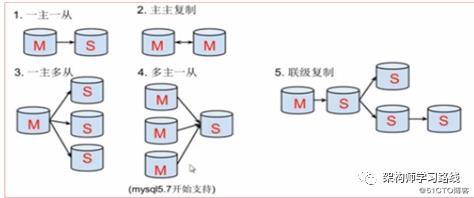
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
环境准备关闭防火墙以SELINUX[root@yanyinglai ~]# systemctl stop firewalld[root@yanyinglai ~]# systemctl disable firewalld[root@yanyinglai ~]# sed -ri 's/(SELINUX=).*/1disabled/g' /etc/selinux/config[root@yanyinglai ~]# setenforce 0安装mysql安装依赖包[root@yanyinglai ~]# yum -y install ncurses-devel openssl-devel openssl cmake mariadb-devel创建用户和组[root@yanyinglai ~]# groupadd -r -g 306 mysql[root@yanyinglai ~]# useradd -M -s /sbin/nologin -g 306 -u 306 mysql下载二进制格式的mysql软件包[root@yanyinglai ~]# cd /usr/src/[root@yanyinglai src]#wget https://downloads.mysql.com/archives/get/file/mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz解压软件至/usr/local/[root@yanyinglai src]# lsdebug kernels mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz[root@yanyinglai src]# tar xf mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz -C /usr/local/[root@yanyinglai src]# ls /usr/local/bin etc games include lib lib64 libexec mysql-5.7.22-linux-glibc2.12-x86_64 sbin share src[root@yanyinglai src]# cd /usr/local/[root@yanyinglai local]# ln -sv mysql-5.7.22-linux-glibc2.12-x86_64/ mysql"mysql" -> "mysql-5.7.22-linux-glibc2.12-x86_64/"[root@yanyinglai local]# ll总用量 0drwxr-xr-x. 2 root root 6 11月 5 2016 bindrwxr-xr-x. 2 root root 6 11月 5 2016 etcdrwxr-xr-x. 2 root root 6 11月 5 2016 gamesdrwxr-xr-x. 2 root root 6 11月 5 2016 includedrwxr-xr-x. 2 root root 6 11月 5 2016 libdrwxr-xr-x. 2 root root 6 11月 5 2016 lib64drwxr-xr-x. 2 root root 6 11月 5 2016 libexeclrwxrwxrwx. 1 root root 36 9月 7 22:20 mysql -> mysql-5.7.22-linux-glibc2.12-x86_64/drwxr-xr-x. 9 root root 129 9月 7 22:19 mysql-5.7.22-linux-glibc2.12-x86_64drwxr-xr-x. 2 root root 6 11月 5 2016 sbindrwxr-xr-x. 5 root root 49 9月 3 23:02 sharedrwxr-xr-x. 2 root root 6 11月 5 2016 src修改目录/usr/locaal/mysql的属主属组[root@yanyinglai local]# chown -R mysql.mysql /usr/local/mysql[root@yanyinglai local]# ll /usr/local/mysql -dlrwxrwxrwx. 1 mysql mysql 36 9月 7 22:20 /usr/local/mysql -> mysql-5.7.22-linux-glibc2.12-x86_64/添加环境变量[root@yanyinglai local]# ls /usr/local/mysqlbin COPYING docs include lib man README share support-files[root@yanyinglai local]# cd[root@yanyinglai ~]# echo 'export PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh[root@yanyinglai ~]# . /etc/profile.d/mysql.sh[root@yanyinglai ~]# echo $PATH/usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin建立数据存放目录[root@yanyinglai ~]# cd /usr/local/mysql[root@yanyinglai mysql]# mkdir /opt/data[root@yanyinglai mysql]# chown -R mysql.mysql /opt/data/[root@yanyinglai mysql]# ll /opt/总用量 0drwxr-xr-x. 2 mysql mysql 6 9月 7 22:25 data初始化数据库[root@yanyinglai mysql]# /usr/local/mysql/bin/mysqld --initialize --user=mysql --datadir=/opt/data///这个命令的最后会生成一个临时密码,此处密码是1EbNA-k*BtKo配置mysql[root@yanyinglai ~]# ln -sv /usr/local/mysql/include/ /usr/local/include/mysql"/usr/local/include/mysql" -> "/usr/local/mysql/include/"[root@yanyinglai ~]# echo '/usr/local/mysql/lib' > /etc/ld.so.conf.d/mysql.conf[root@yanyinglai ~]# ldconfig -v生成配置文件[root@yanyinglai ~]# cat > /etc/my.cnf <<EOF> [mysqld]> basedir = /usr/local/mysql> datadir = /opt/data> socket = /tmp/mysql.sock> port = 3306> pid-file = /opt/data/mysql.pid> user = mysql> skip-name-resolve> EOF配置服务启动脚本[root@yanyinglai ~]# cp -a /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld[root@yanyinglai ~]# sed -ri 's#^(basedir=).*#1/usr/local/mysql#g' /etc/init.d/mysqld[root@yanyinglai ~]# sed -ri 's#^(datadir=).*#1/opt/data#g' /etc/init.d/mysqld启动mysql[root@yanyinglai ~]# service mysqld startStarting MySQL.Logging to '/opt/data/yanyinglai.err'... SUCCESS![root@yanyinglai ~]# ps -ef|grep mysqlroot 4897 1 0 22:38 pts/2 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir=/opt/data --pid-file=/opt/data/mysql.pidmysql 5075 4897 6 22:38 pts/2 00:00:01 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/opt/data --plugin-dir=/usr/local/mysql/lib/plugin --user=mysql --log-error=yanyinglai.err --pid-file=/opt/data/mysql.pid --socket=/tmp/mysql.sock --port=3306root 5109 4668 0 22:38 pts/2 00:00:00 grep --color=auto mysql[root@yanyinglai ~]# ss -antlState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 0 128 *:22 *:*LISTEN 0 100 127.0.0.1:25 *:*LISTEN 0 128 :::22 :::*LISTEN 0 100 ::1:25 :::*LISTEN 0 80 :::3306 :::*修改密码使用临时密码修改[root@yanyinglai ~]# mysql -uroot -pEnter password:Welcome to the MySQL monitor. Commands end with ; or g.Your MySQL connection id is 2Server version: 5.7.22Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.mysql> set password = password('123456');Query OK, 0 rows affected, 1 warning (0.00 sec)mysql> quitByemysql主从配置确保从数据库与主数据库的数据一样先在主数据库创建所需要同步的库和表[root@yanyinglai ~]# mysql -uroot -pEnter password:Welcome to the MySQL monitor. Commands end with ; or g.Your MySQL connection id is 4Server version: 5.7.22 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle and/or its affiliates. AlOracle is a registered trademark of Oracle Corporation andaffiliates. Other names may be trademarks of their respectowners.Type 'help;' or 'h' for help. Type 'c' to clear the currmysql> create database yan;Query OK, 1 row affected (0.00 sec)mysql> create database lisi;Query OK, 1 row affected (0.00 sec)mysql> create database wangwu;Query OK, 1 row affected (0.00 sec)mysql> use yan;Database changedmysql> create table tom (id int not null,name varchar(100)not null ,age tinyint);Query OK, 0 rows affected (11.83 sec)mysql> insert tom (id,name,age) values(1,'zhangshan',20),(2,'wangwu',7),(3,'lisi',23);Query OK, 3 rows affected (0.07 sec)Records: 3 Duplicates: 0 Warnings: 0mysql> select * from tom;+----+-----------+------+| id | name | age |+----+-----------+------+| 1 | zhangshan | 20 || 2 | wangwu | 7 || 3 | lisi | 23 |+----+-----------+------+3 rows in set (0.00 sec)备份主库备份主库时需要另开一个终端,给数据库上读锁,避免在备份期间有其他人在写入导致数据同步的不一致[root@yanyinglai ~]# mysql -uroot -pEnter password:Welcome to the MySQL monitor. Commands end with ; or g.Your MySQL connection id is 5Server version: 5.7.22 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.mysql> flush tables with read lock;Query OK, 0 rows affected (0.76 sec)//此锁表的终端必须在备份完成以后才能退出(退出锁表失效)备份主库并将备份文件传送到从库[root@yanyinglai ~]# mysqldump -uroot -p123456 --all-databases > /opt/all-20180907.sqlmysqldump: [Warning] Using a password on the command line interface can be insecure.[root@yanyinglai ~]# ls /opt/all-20180907.sql data[root@yanyinglai ~]# scp /opt/all-20180907.sql root@192.168.55.129:/opt/The authenticity of host '192.168.55.129 (192.168.55.129)' can't be established.ECDSA key fingerprint is SHA256:7mLj77SFk7sPkhjpMPfdK3nZ98hOuyP4OKzjXeijSJ0.ECDSA key fingerprint is MD5:a0:1b:eb:7f:f0:b6:7b:73:97:91:4c:f3:b1:89:d8:ea.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '192.168.55.129' (ECDSA) to the list of known hosts.root@192.168.55.129's password:all-20180907.sql 100% 784KB 783.3KB/s 00:01解除主库的锁表状态,直接退出交互式界面即可mysql> quitBye在从库上恢复主库的备份并查看是否与主库的数据保持一致[root@yanyinglai ~]# mysql -uroot -p123456 < /opt/all-20180907.sqlmysql: [Warning] Using a password on the command line interface can be insecure.[root@yanyinglai ~]# mysql -uroot -p123456mysql: [Warning] Using a password on the command line interface can be insecure.Welcome to the MySQL monitor. Commands end with ; or g.Your MySQL connection id is 4Server version: 5.7.22 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.mysql> show databases;+--------------------+| Database |+--------------------+| information_schema || lisi || mysql || performance_schema || sys || wangwu || yan |+--------------------+7 rows in set (0.18 sec)mysql> use yan;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> select * from tom;+----+-----------+------+| id | name | age |+----+-----------+------+| 1 | zhangshan | 20 || 2 | wangwu | 7 || 3 | lisi | 23 |+----+-----------+------+3 rows in set (0.06 sec)在主数据库创建一个同步账户授权给从数据使用[root@yanyinglai ~]# mysql -uroot -pEnter password:Welcome to the MySQL monitor. Commands end with ; or g.Your MySQL connection id is 7Server version: 5.7.22 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.mysql> create user 'repl'@'192.168.55.129' identified by '123456';Query OK, 0 rows affected (5.50 sec)mysql> grant replication slave on *.* to 'repl'@'192.168.55.129';Query OK, 0 rows affected (0.04 sec)mysql> flush privileges;Query OK, 0 rows affected (0.09 sec)配置主数据库编辑配置文件[root@yanyinglai ~]# vim /etc/my.cnf[root@yanyinglai ~]# cat /etc/my.cnf[mysqld]basedir = /usr/local/mysqldatadir = /opt/datasocket = /tmp/mysql.sockport = 3306pid-file = /opt/data/mysql.piduser = mysqlskip-name-resolve//添加以下内容log-bin=mysql-bin //启用binlog日志server-id=1 //主数据库服务器唯一标识符 主的必须必从大log-error=/opt/data/mysql.log重启mysql服务[root@yanyinglai ~]# service mysqld restartShutting down MySQL..... SUCCESS!Starting MySQL.Logging to '/opt/data/mysql.log'................................ SUCCESS![root@yanyinglai ~]# ss -antlState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 0 128 *:22 *:*LISTEN 0 100 127.0.0.1:25 *:*LISTEN 0 128 :::22 :::*LISTEN 0 100 ::1:25 :::*LISTEN 0 80 :::3306 :::*查看主库的状态mysql> show master status;+------------------+----------+--------------+------------------+-------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+------------------+----------+--------------+------------------+-------------------+| mysql-bin.000001 | 154 | | | |+------------------+----------+--------------+------------------+-------------------+1 row in set (0.00 sec)配置从数据库编辑配置文件[root@yanyinglai ~]# cat /etc/my.cnf[mysqld]basedir = /usr/local/mysqldatadir = /opt/datasocket = /tmp/mysql.sockport = 3306pid-file = /opt/data/mysql.piduser = mysqlskip-name-resolve//添加以下内容:server-id=2 //设置从库的唯一标识符 从的必须比主小relay-log=mysql-relay-bin //启用中继日志relay logerror-log=/opt/data/mysql.log重启从库的mysql服务[root@yanyinglai ~]# service mysqld restartShutting down MySQL.. SUCCESS!Starting MySQL.. SUCCESS![root@yanyinglai ~]# ss -antlState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 0 128 *:22 *:*LISTEN 0 100 127.0.0.1:25 *:*LISTEN 0 128 :::22 :::*LISTEN 0 100 ::1:25 :::*LISTEN 0 80 :::3306 :::*配置并启动主从复制mysql> change master to-> master_host='192.168.55.130',-> master_user='repl',-> master_password='123456',-> master_log_file='mysql-bin.000001',-> master_log_pos=154;Query OK, 0 rows affected, 2 warnings (0.28 sec)查看从服务器状态mysql> show slave statusG;*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.55.130Master_User: replMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000001Read_Master_Log_Pos: 154Relay_Log_File: mysql-relay-bin.000003Relay_Log_Pos: 320Relay_Master_Log_File: mysql-bin.000001Slave_IO_Running: Yes //此处必须是yesSlave_SQL_Running: Yes //此处必须是yesReplicate_Do_DB:Replicate_Ignore_DB:Replicate_Do_Table:Replicate_Ignore_Table:Replicate_Wild_Do_Table:Replicate_Wild_Ignore_Table:Last_Errno: 0Last_Error:Skip_Counter: 0Exec_Master_Log_Pos: 154Relay_Log_Space: 527Until_Condition: NoneUntil_Log_File:Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File:Master_SSL_CA_Path:Master_SSL_Cert:Master_SSL_Cipher:Master_SSL_Key:Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error:Last_SQL_Errno: 0Last_SQL_Error:Replicate_Ignore_Server_Ids:Master_Server_Id: 1Master_UUID: 5abf1791-b2af-11e8-b6ad-000c2980fbb4Master_Info_File: /opt/data/master.infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for more updatesMaster_Retry_Count: 86400Master_Bind:Last_IO_Error_Timestamp:Last_SQL_Error_Timestamp:Master_SSL_Crl:Master_SSL_Crlpath:Retrieved_Gtid_Set:Executed_Gtid_Set:Auto_Position: 0Replicate_Rewrite_DB:Channel_Name:Master_TLS_Version:1 row in set (0.00 sec)ERROR:No query specified测试验证在主服务器的yan库的tom表插入数据:mysql> use yan;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> select * from tom;+----+-----------+------+| id | name | age |+----+-----------+------+| 1 | zhangshan | 20 || 2 | wangwu | 7 || 3 | lisi | 23 |+----+-----------+------+3 rows in set (0.09 sec)mysql> insert tom(id,name,age) value (4,"yyl",18);Query OK, 1 row affected (0.14 sec)mysql> select * from tom;+----+-----------+------+| id | name | age |+----+-----------+------+| 1 | zhangshan | 20 || 2 | wangwu | 7 || 3 | lisi | 23 || 4 | yyl | 18 |+----+-----------+------+4 rows in set (0.00 sec)在从数据库查看是否数据同步mysql> use yan;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> select * from tom;+----+-----------+------+| id | name | age |+----+-----------+------+| 1 | zhangshan | 20 || 2 | wangwu | 7 || 3 | lisi | 23 || 4 | yyl | 18 |+----+-----------+------+4 rows in set (0.00 sec)
原文:https://www.cnblogs.com/zhangchao0515/p/11493236.html


想要获取学习实战、高并发、架构 、笔试面试资料 请扫码咨询+薇薇微信
以上是关于数据库架构设计的主要内容,如果未能解决你的问题,请参考以下文章