视频|苏宁无人店算法架构设计
Posted 苏宁科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频|苏宁无人店算法架构设计相关的知识,希望对你有一定的参考价值。
11月11日,苏宁零售技术研究院高级技术经理刘江进行了门店数字化赋能系列课程——《无人店算法架构设计》的分享,他认为在无人店的算法设计中,最重要的是满足速度和准确率的平衡,在能满足耗时要求的情况下,根据实际的落地场景需求,选取准确率更高的模型。
以下为演讲视频:
以下为门店数字化赋能系列课程第八讲内容整理:
大家好,我是来自苏宁零售技术研究院的无人店深度学习方案负责人刘江。今天给大家带来的是我们门店数字化专项的第八期直播课程,主要是和大家分享一下关于无人店算法架构设计相关内容。
本期课程您将学习到如下内容:
1)无人店各算法模块选取方法和模块分解;
2)无人店深度学习样本采集和数据增强解决方案;
3)无人店深度学习模型训练和部署解决方案。
算法模块选取和分解
算法模块分解主要会从算法选择的合理性以及整个无人店工程中算法的处理流程和数据流两个角度来进行讲解。先从整体上来看下无人店算法有哪些模块。首先就是标定模块,从标定方法上来说大致可以分为两大类,一个是基于图像特征提取同名点匹配的方式,另一种是基于标定板的方式,两种方式各有优缺点。
先来看基于图像特征同名点匹配的方式,优点是不基于外部特有的设备,比如标定板,更不需要将外部特有设备摆设为特有的姿态,该标定方法方便、简洁,但是缺点也很明显,那就是找寻同名点时因为摄像机角度位置等原因,标定的精度较差。再来看基于标定板方式的标定方法,优缺点刚好和图像特征同名点匹配的方式相反,优点是标定精度较高,缺点是标定步骤较复杂,在两个摄像头之间需要不停的摆放不同的姿势,以期达到要求。

所以在实际场景使用中,我们采取的方式是初始状态下先采用标定板标定方式来保证精度,然后使用图像特征同名点匹配的方式,在使用中实时判断误差情况,当场景中有较大程度的摄像头移动时,就会触发预警,然后再来使用标定板标定方式恢复标定精度。从图中可以看出我们实际标定是结合标定板标定和图像特征同名点匹配的方式,输出是外参数以及全场景拼接点云,这两部分对于后面的整体流程都有很大的作用,比如外参数结合摄像机的内参数,就可以把检测坐标统一到视觉坐标系下,以达到跟踪统一坐标系的目的。全场景拼接点云可以使得我们在场景中实际看到用户的整体运动情况和处理流程。
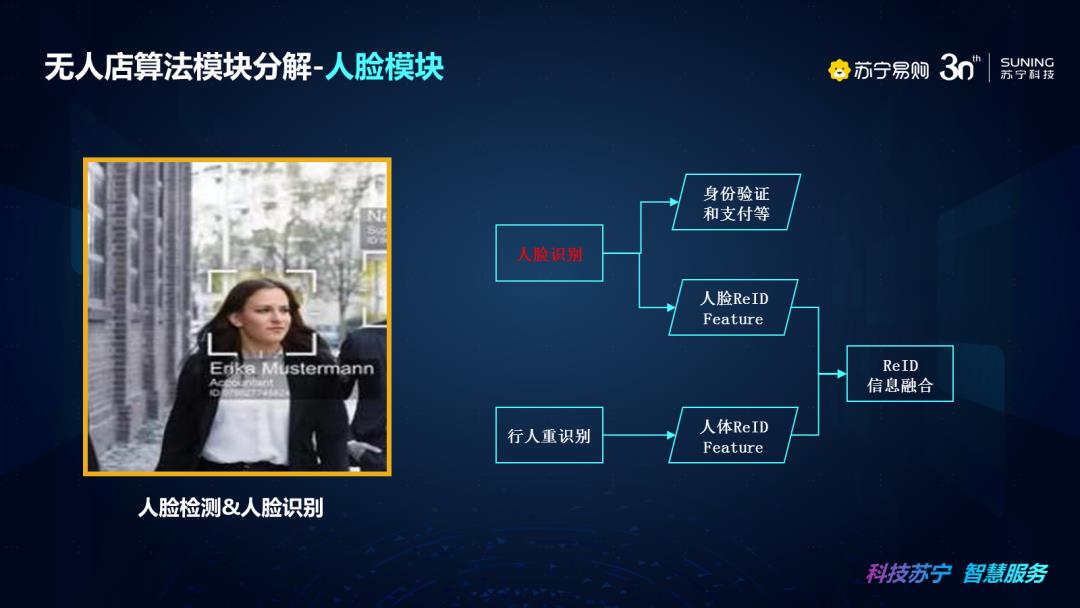
接下来无人店算法的第二个模块——人脸模块,在人脸的应用中,主要是用来做身份的认证与支付。这里把人脸的应用分为两大部分,第一部分是无人店进出店时身份的认证与支付,第二部分是将人脸的特征和行人重识别的特征进行绑定,来加强行人重识别技术的精度,我们提取的行人重识别的特征是人体ReID Feature,人脸ReID Feature的特征作为我们信息的一部分,将信息进行关联,综合得到ReID特征。这种情况主要是进出店会综合验证用户绑定情况是否正确,在店内主要还是依赖行人重识别的人体ReID Feature。
在检测模块中,苏宁无人店采用了多任务的检测模型来同时输出目标检测框、实例分割掩码以及关键点检测数据。在后面的部分还会介绍多任务输出的另一个信息,那就是用于行人重识别和商品识别的embedding信息,也可以通过我们的多任务的方式进行输出。

深度学习多任务模型的意义在于节省每个任务模块在单独计算时主干网的计算时间,但是在模型设计上面也要权衡多任务输出是否会影响各个任务输出的正确率。
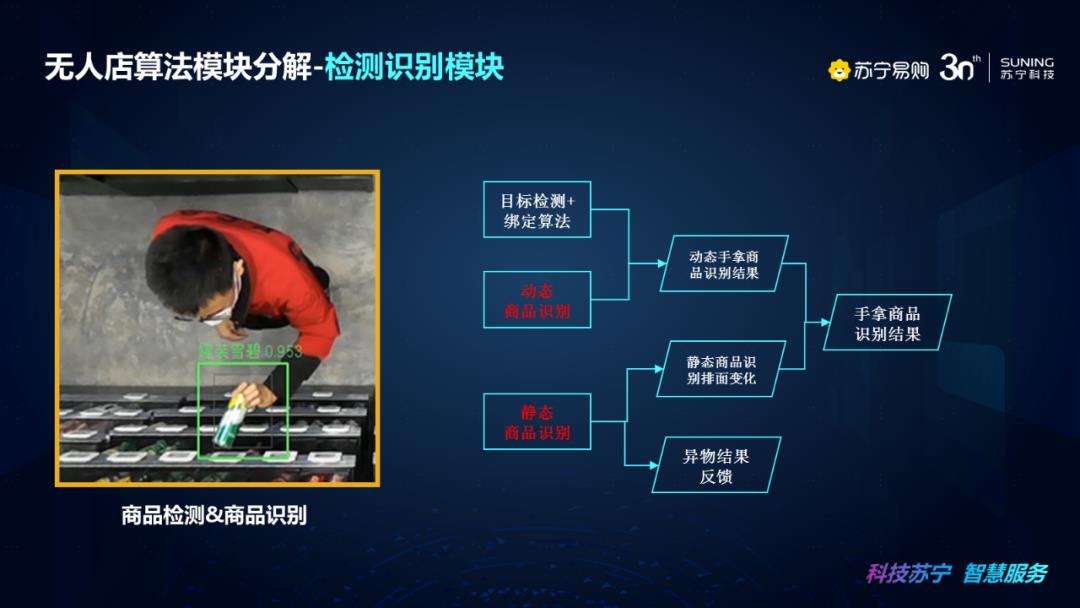
再来看我们无人店算法的检测识别模块,主要将商品检测和商品识别进行解读,在无人店实际应用中商品识别大的分类角度来讲可以大致分为两大类,第一个是动态商品识别,它关注的是手拿商品的过程中的商品识别结果,可以结合目标检测和绑定算法来建立用户与拿取商品之间的关系,该过程商品会受到摄像机的角度以及受到人体自身、货架遮挡等影响,还有摄像机的运动模糊等因素的影响。还有一种是静态商品识别,它是触发式的采集货架上或者排面的商品信息情况,该过程很难建立用户和拿取商品之间的关系,并且无法识别到商品堆叠等场景,但是采集场景较为理想,不会受到运动模糊和人体遮挡问题的影响。
在实际场景使用中,采取目标检测与动态商品识别相结合的主路线,动态商品识别作为校验,来辅助判断拿取商品的类别是否正确以及辅助作为货架异物检测的手段。从流程图中可以看出,首先是目标检测+绑定算法和动态商品识别结合,输出动态手拿商品识别结果,静态商品识别判断出静态商品识别排面变化和异物结果反馈,如果有异物会反馈给后台,做相应的处理。最后结合动态商品识别和静态商品识别的综合结果得出手拿商品识别结果。这就是我们整个商品检测和商品识别模块的一个处理流程。
无人店算法模块的跟踪部分可抽象的分为三部分,包括目标跟踪、行人重识别和用户行为判断。其中这里的目标跟踪关注的是帧与帧之间的变化情况,相当于连续帧的序列,这里我们用到了位置和纹理特征的目标跟踪,当目标跟踪的结果不符合绑定的需求,会利用行人重识别技术来辅助进行目标跟踪,这里面目标跟踪的深度学习的纹理特征和行人重识别用到的纹理特征应用的场景是不一样的,行人重识别里面更关心的是用户特征更新和特征重新变化的情况,而目标跟踪特征主要是基于时间序列,在某些连续帧的变化时的情况,比如当前帧和之前5帧内的特征进行特征匹配,而行人重识别需要对于特征进行建库和更新,使用的特征为更新后的库特征与当前帧进行比较。用户行为判断之所以划分在跟踪模块是因为用户的行为需要连续帧的动作来进行判断,连续帧的动作就需要将目标检测和目标跟踪后的结果进行串联,来分析连续时间段内用户行为的变化情况,比如店内破坏行为就要从动作发生的整个过程来分析,比如用户跌倒异常判断,比如一些用户店内突发事故倒地,整个系统就会分析从正常站立状态到倒地的过程,然后最后倒地后一段时间不再站立的整个过程就是需要结合目标检测和目标跟踪的时间序列来决策。

下面我们来关注一下行人重识别模块的技术细节点。左图中可以看到基于Anchor方式的目标检测框的输出,可以看出除了我们想要关注的目标以外,还有另一个目标以及背景信息在框内。对于密集人群的特殊场景,基于这种方式下如果直接训练和使用目标检测和行人重识别技术就会带来很大的困难,模型训练学习中无法知道我们关注的目标到底是框内的什么信息,只能概况的认为整个框内的信息都是目标特征,可想而知,最终训练和使用的效果也不会很好。那么如何解决这个问题呢?基本的原则就是需要关注到需要检测和识别的目标上来。
右图中可以看出使用Anchor-Free的目标检测方式最终回归到的是目标的热力分布和中心位置,可有效的解决密集人群检测问题,在实际落地场景使用中,除去结合上述信息外,更重要的是还加入注意力机制来辅助行人重识别进行加强,从而整体提升检测和识别准确率。

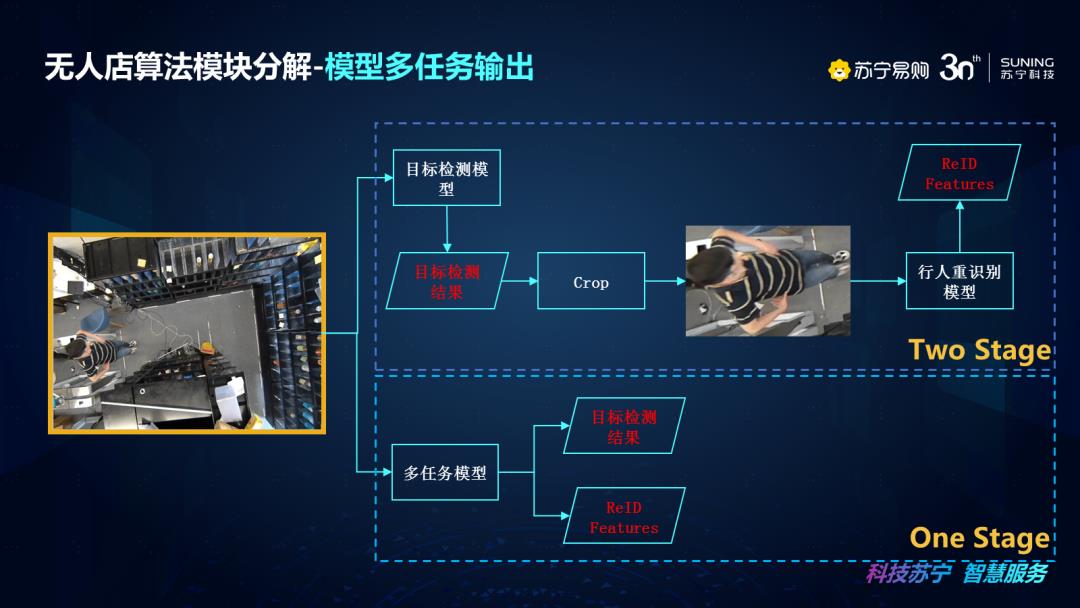
这里我们谈下模型多任务输出,如果进行目标检测+行人重识别,比如说我们要进行检测行人,然后对行人进行识别,这一过程中其实会有两种方法,一个是两阶段法,一个是一阶段法。两阶段就是先做目标检测,得到目标检测框信息,然后将目标检测框内的信息进行裁剪送入到识别网络进行识别处理。两阶段可以带来稳定的目标检测和识别准确率,但是对于项目部署方式以及模型复杂度和处理效率上来说都是不太友好的。那么我们就靠考虑是否有一步法,也就是多任务输出的方式来一起输出目标检测和ReID的结果。
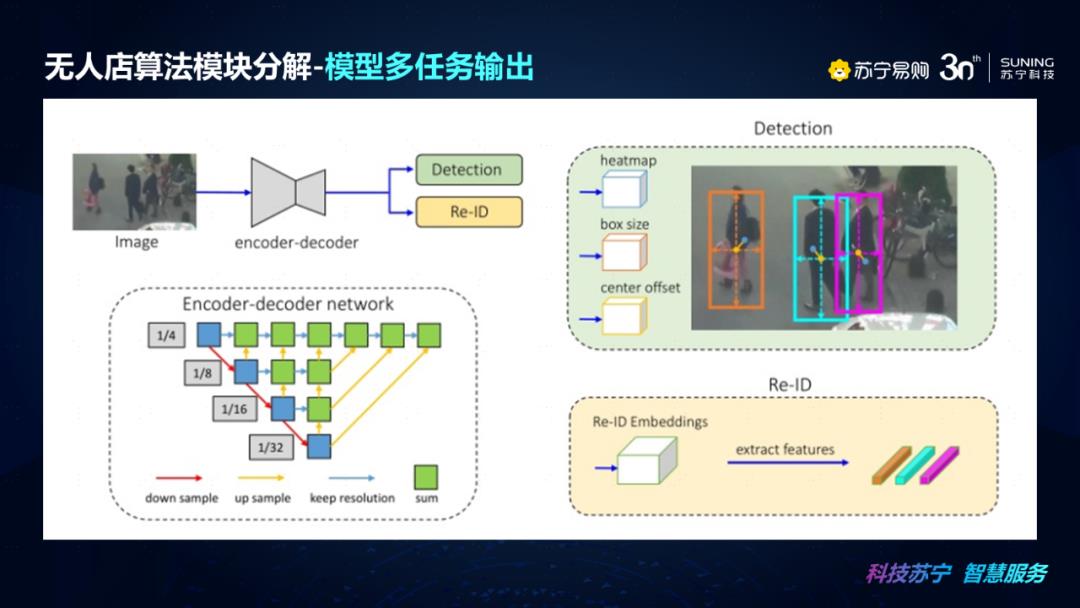
接下来我们以MOT框架下的FairMot网络模型来说明一下模型多任务输出的问题以及行人重识别在实际应用场景的应用问题。FairMot是一个基于CenterNet的联合检测和跟踪的框架。网络的作者通过实验,选取了DLA作为主干网,并且选取Anchor-free的框架是更适合多任务的目标检测和ReID结果的输出。感兴趣的小伙伴可以去关注一下我们这篇文章的相关内容。
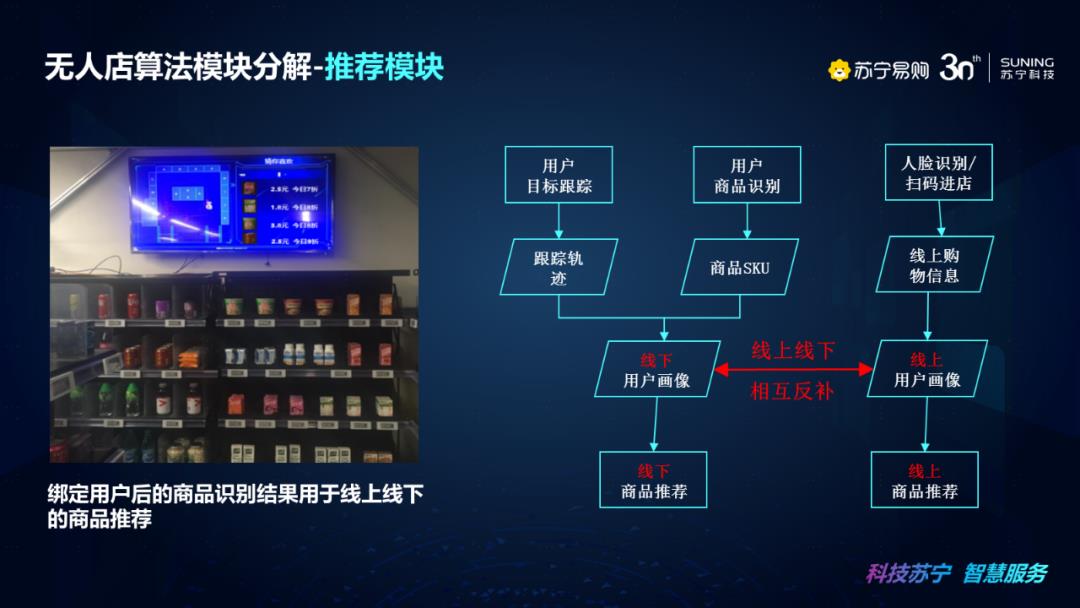
推荐模块主要应用在苏宁的线上场景中,但是推荐模块也是数字化门店和无人店非常重要的一块内容,这里我们结合了用户信息和线上线下的购物情况,完成对线上线下商品推荐的补充和增强。线下商品推荐可以结合用户线上线下购物情况,使用店内互动大屏对于用户进行精准商品推荐以及和绑定APP相结合;并且线下的购物也可以反哺线上商品推荐。这里我们看下线上线下相互反哺的流程,首先通过用户目标跟踪,来实现跟踪轨迹的数据结构,然后用户根据商品识别可以得到相关商品SKU情况,这样综合线下用户画像情况,包括购买商品的列表以及相关用户习惯等,从而完成线下商品识别和推荐。当然这一部分还需要根据线上的信息综合得到线下商品的推荐情况,就是通过进店的人脸识别,得到用户线上的购物信息,其实就是用户的线上画像情况,然后进行线上线下相互反哺,这样就可以大大扩充我们对用户行为的识别,从而进行精准的商品推荐。线下用户的非购买信息,都可以作为用户线上画像的辅助,判断用户购买行为习惯。
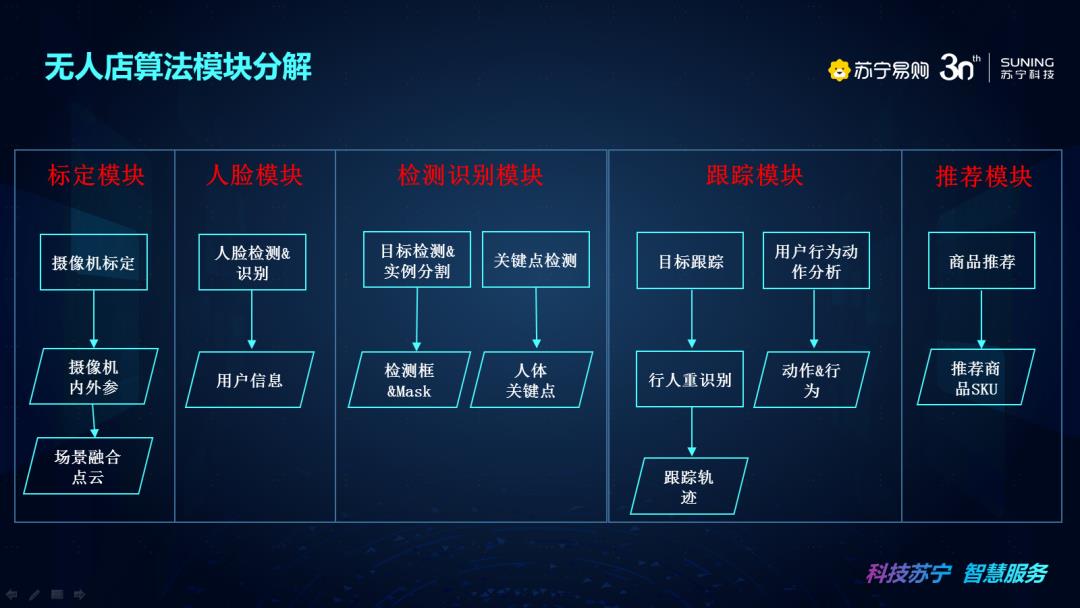
我们来总体说明一下无人店算法模块分解情况,来分析我们的架构整体设计以及模块之间的衔接问题。第一个是标定模块,它通过摄像机标定后生成摄像机内外参和场景融合点云,主要用于统一全场景多摄像机坐标系关系。在人脸模块里面通过人脸检测&识别获取用户信息,用于绑定用户信息和识别校验。检测识别模块里面目标检测&实例分割主要输出的是检测框&Mask,关键点检测输出的是人体关键点情况,所有的检测模块输出的结果也是用来辅助我们的跟踪模块和推荐模块,用于目标的检测和商品的识别。再往下是跟踪模块,通过目标跟踪和行人重识别,实现输出跟踪轨迹的目的,还通过用户行为动作分析,来识别用户动作&行为,最终辅助终端来判断用户行为和商品推荐信息。推荐模块结合了线上线下的用户信息和商品识别,最终得到商品推荐列表的信息,以上就是无人店算法模块分解的情况。
在这里强调下无人店算法模块选取的一些要素,因为无人店整体算法都是实时处理的,所以对于一些大的模块选取的时候,都是要求能够达到实时,“实时”的定义和摄像机帧率以及处理的频次进行关联的,大家可以根据实际情况应用到自己的场景中。另外比较关注的就是准确率,准确率的选取就是一定要选取符合我们能够上线发布的要求,选取适合我们的模块或者多模块融合的方式,来达到最终处理闭环的目的。最后就是无人店算法选取的整体部署,需要每个模块能够达到相应的需求,比如标定模块一定要快捷方便。
深度学习样本采集和数据增强
无人店深度学习样本的采集使用了场景中的安防摄像机、深度摄像机以及人脸抓拍摄像机等设备,采用到的样本进行自有设计的采样方式得到待标注样本集,然后使用苏宁AI标注平台对于样本集进行标注,最后使用苏宁机器学习平台进行训练和评价。这个通路是全自动打通的,除了自有的采集设备进行筛选以外,从采集到标注到训练,是完全不通过人工操作完成的,这套步骤可以大大提高整体链路提速的目的。

模型训练结果的好坏有很多决定因素,数据增强方法是很重要的一环,如果样本的多样性泛化能力不足,那么在实际使用时就会出现准确率下降的问题,除了传统的数据增强方法外,我们使用了多角度点云投影方法和GAN技术来对于数据进行增强处理。
深度学习模型训练和部署解决方案
结合上述的样本采集和数据增强技术,我们来看一下无人店深度学习模型训练的方法。首先当刚开始训练模型时,由于采集场景样本过少,先采用公开数据集标注数据和自有标注数据集结合的方式训练模型;得到初始化模型后,再使用初始化模型推理采样场景未标注数据得到样本推理结果,然后使用苏宁AI标注平台快速修正标注结果,最后将所有修正的标注结果加入训练集,对于模型进行优化更新,不断迭代此步骤,最终得到最优模型输出。
最后我们来看下无人店深度学习模型部署情况,因为无人店是线下零售场景落地的完整解决方案,在应用过程中就不能将算法模型以及模块等直接应用到场景中,效率和部署难度可能都会相应增加。
我们下面结合深度学习模型,来说明模型部署的方法。这里我们以英伟达GPU平台为例来说明一下无人店深度学习模型部署和加速的问题。第一个是模型部署和加速,通常我们在训练模型的时候使用的框架都会不尽相同,比如pytorch、tensorflow等,那么在最后训练好模型进行部署的时候,就需要转换成通用的模型文件方式ONNX,最后英伟达平台提供了模型加速引擎TensorRT,如果需要模型加速就需要再将通用ONNX转换为TensorRT模型文件来进行部署和加速。这样就可以提升模型的速度以及通用性。第二部分是预处理部署和加速,就是在模型进行推理的时候,比如进来一张图或者进来一组图,需要对图像进行一些变换,比如仿射变换或者归一化,普通变换都是在CPU上处理,效率上可能较低,更适合在GPU下完成,这部分我们是使用CUDA仿射变换能力和CUDA归一化能力,直接部署在我们的GPU上进行计算。在后处理部署和加速部分,还是使用CUDA编程将原有在CPU上完成的NMS和解码等操作转换为在GPU上进行。
结合以上方式,我们来说明一下,为什么我们都将这些方式放在GPU上,因为在模型的每个部分中,比如预处理、推理、后处理过程等,数据的AO比较耗时,整个搬运的AO比较耗时,我们将整个的过程从进入以后都完整的放在GPU端去处理,节省的时间是很可观的,大家可以结合整体的项目情况,选择合适的整体部署方法。
以上就是本期无人店算法架构设计课程的主要内容。
谢谢大家。
以上是关于视频|苏宁无人店算法架构设计的主要内容,如果未能解决你的问题,请参考以下文章