架构师眼中的高可用架构设计之道
Posted InsideMySQL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构师眼中的高可用架构设计之道相关的知识,希望对你有一定的参考价值。
破产码农
高可用(High Availability)是每位码农在进行系统设计和代码编写时都不得不思考的重要环节。
即便这样一个常见的问题,其实很多码农依然没有真正理解何为高可用。
大部分码农会说:高可用是指当系统或硬件发生宕机时,确保业务的连续性。
高可用的判定标准是一年内业务宕机时间。高可用99.999%(5个9),意味着一年内只允许宕机5分多钟,达到99.999%代表这个系统在高可用方面做得相当出色。
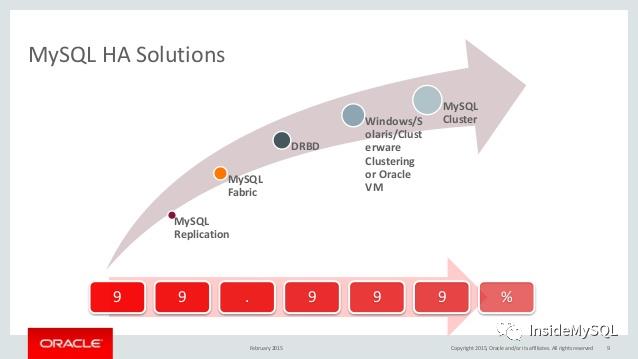
如何实现系统高可用设计呢?消除单点故障(SPOF single point of failure),实现故障转移(failover)。
业务层无状态,高可用相对简单,可以通过类似LVS、Keepalived等机制,当发现立即剔除节点或实现故障转移。
数据库有状态,相对复杂一些,在mysql数据库中可通过类似MHA机制实现高可用切换,从而保证业务的连续性。
因为数据库是有状态服务,因此高可用切换所需时间更长。不过有了MGR(MySQL Group Replication)这样的机制,数据库的高可用也成为了无(弱)状态。
从高可用设计工程实现角度看,首先建立冗余,一台机器宕机,另外的机器可以马上顶上。
接着,通过高可用实现的作用域,是机房级、同城级、跨城级,来判定自己高可用的实现级别。
最后,再结合业务是否多活多写的特性,判断这个高可用的最终架构水准。
游戏级:同机房单活高可用架构;
电商级:一地三中心同城多活高可用架构;
金融级:三地五中心跨城多活高可用架构;
可惜,上面的这些理解:以上全错。
因为他们没有抓住最为基本的关键点:何为业务的连续性?
网上大部分技术大V对高可用就停留在单一组件或数据库上,但这样的高可用设计显然是不合格的。
陈皓在他《关于高可用的系统》博客中,主要是在讲述数据库高可用的实现,而且他认为这很难,特别是对于数据一致性要求非常高的场景。
然而,对于MySQL来说,这已经是个非常easy的问题,直接上无损复制或者MGR。
还有一些大V是在讲述高可用下的缓存和数据库之间数据一致性的问题。
总之,过于纠结某个组件的高可用,是非常片面的。这不是站在架构师角度来掌控整体高可用架构的设计。
假设一台服务器宕机,高可用机制将其剔除后,若剩余的服务器撑不住业务的访问量,请问这是合格的高可用架构么?
又比如,磁盘突然发生抽风,磁盘使用率100%,导致日志写入变慢,业务的响应时间上升10倍,这是合格的高可用架构么?
若数据库发生了宕机,进行切换,但是切换完后,数据库依然顶不住压力,又发生了切换,请问这是合格的高可用架构么?
显然,这些都不是真正的高可用架构设计。
为什么这些高可用架构都有问题呢?
因为他们只考虑自身的可用性逻辑,没有考虑全链路各个高可用的环节。
所以,这样的高可用设计不具有真正的可衡量性。
有同学会说:有啊。高可用不是计算宕机时间么?几个九不就是高可用的衡量指标么?
再一次的以上全错,因为现在的高可用计算方式是不确定的。
举例来说,1台服务器1年内宕机5分钟15秒内,就符合99.999%的高可用标准。
如果1个数据库集群3台服务器,一主两从,整体宕机5分15秒算99.999%高可用,还是宕机5分15秒 × 3,16分钟内才算是99.999%的高可用标准呢?
其实,真正的高可用标准判断应该是业务一年的影响时长。
每个(子)业务才是一个最完整的高可用计算单元。
如果细化到各个组件,那高可用计算就会复杂很多。
对于数据库来说,如果从机宕机了,哪怕宕机了几个小时,但是他对业务毫无影响,不能算可用性有问题,因为架构设计时就做了冗余处理。
但若业务的请求是主从分离设计,从机宕机,影响了业务的读取请求,那么就应该判断可用性下降。
同样的,当服务活着,但他的响应耗时是10秒,这样业务早已处于不可用的境地。
因此,可用性的判断标准不仅仅是系统活着与否,切换后数据是否丢失。
我们来看Wiki对于高可用的定义:
Wiki的表述相对是比较准确的,红色的部分是需要特别关注的重点。
若用姜老师的话归纳,高可用是指:
保障在指定响应时间内,系统能提供正常的服务。
可以发现这比传统理解的高可用更高一层,不但要求提供正常服务,确保业务连续性,还要求系统能提供稳定的响应时间。
经过上面的讨论,大家应该意识到高可用的真正定义。
因此,为了实现系统真正高可用的标准,在进行架构设计时应至少保障以下四个方面的设计和实现:模块化 + Fail-fast + 幂等重试 + 服务降级
1
模块化
模块化是指将业务拆成很多独立的小模块。
对于电商系统,有用户层、订单层、物流层、库存层。
组件有缓存、消息队列、数据库等。
作为核心有状态服务的数据库,还需要根据模块进行垂直拆分,至少拆分为不同库(database),最好能拆分成不同实例。
模块内,通过冗余和故障转移等机制,实现模块内部的可用性闭环。
模块间,理清互相之间的调用是同步调用还是异步调用。同时,应该尽可能做到一个子模块宕机,对另一个子模块无影响或有限的影响。
模块化是架构设计的基础,先要做好各个模块的拆解,理清楚各业务的调用关系链。若连这块工作先前都没准备好,未来大概率这个系统将会是灾难。
2
Fail-fast

假设经过模块化的拆解,将一个模块拆解为了服务A、服务B、数据库。
对于大型业务来说,可能还有缓存,这里就做简化处理。
接着在整体架构设计时,需要要给每次服务调用可衡量的业务目标。
例如在设计时约定服务A调用服务B必须在5ms内完成,服务B调用数据库必须在30ms完成,否则并不能真正满足业务可用性的指标。
当系统出现不能满足当初系统设计的目标时,则应该尽快地返回“错误”,也就是Fail-fast。
Fail-fast要求尽快返回错误结果,终止正在进行的操作,让潜在错误尽可能早的被发现,以此让更上层的系统去处理错误。
系统设计,特别是对于高可用设计系统来说,这个准则尤为重要。
要实现这样的机制,使用超时机制是最容易的一种方式。
将服务A调用服务B设置超时时间5ms,服务B调用数据库设置30ms,超时立即返回超时错误码。
若没有设置超时,可能发生服务A、服务B、数据库都活着,但是整个业务依然是完全不可用的状态。
数据库这一层,等待通常是因为锁竞争导致,除了使用超时机制外,还可以使用特定SQL去判断是否需要等待,这样对比超时机制,会更高效:
mysql> SELECT * FROM User WHERE userId = 2 FOR UPDATE NOWAIT;ERROR 3572 (HY000): Do not wait for lock.
3
幂等重试
当启用超时机制后,业务这里可能会收到大量的超时错误码。
错误码可以区分为业务错误码和系统错误码。超时应该算是一种业务错误码。
开发同学应该意识到超时并不一定是问题。可能是这时网络发生了抖动,导致业务请求发生了抖动。亦或是是SSD硬盘在进行GC,性能急剧退化所致。当然,也可能是下层数据库组件当前正在发生切换等等。
因此,当捕获超时时,业务层应该进行重试。
但是每个服务层需要保证每一次重试都是幂等的,即多次重放的结果都是一样的。这就是系统设计中的Idempotent Retry。
用户不会因为多次重试导致重复下单,重复扣款等行为出现。
当幂等重试多次依然有问题,则这时应该触发服务降级,而不是无限的继续重试。
4
服务降级
服务降级可以有:限流、熔断两种处理方式。其实,从本质上看,两者是一样的。
限流(flow control)是指当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的可用性。
例如服务A是一个电商用户下单业务,设计时服务A的访问上限为3000笔/秒,整体请求控制在50ms内。
服务A可以做水平扩展,扩展为100个节点,则可以支撑30W笔/秒的请求,这可能是双11的要求。
限流是指当发现服务A请求大于3000笔/秒时,应该对其进行限流,保证即便是双11大促场景下用户依然能有很好的交易体验,而不是让用户进行没有必要的等待。
另一种限流情况更为精细,假设服务A是商户库存服务。1个商户的某次促销导致某个产品热销,产生热点竞争,从而影响其他商户的库存服务。
因此服务A除了设定3000笔/秒,50ms的总体目标,还可以细化到业务中每件商品库存每秒的交易量,比如300笔/秒。超过这个阈值需要对特定商品库存进行限流。
熔断是根据业务的整体失败量、失败率、响应耗时达到某一阈值时,触发熔断机制,不再提供服务。用户需尽快排除内部具体问题后,再恢复业务。
在产品层面,可以通过公告的形式告知用户,用户本身无需感知熔断机制的触发。
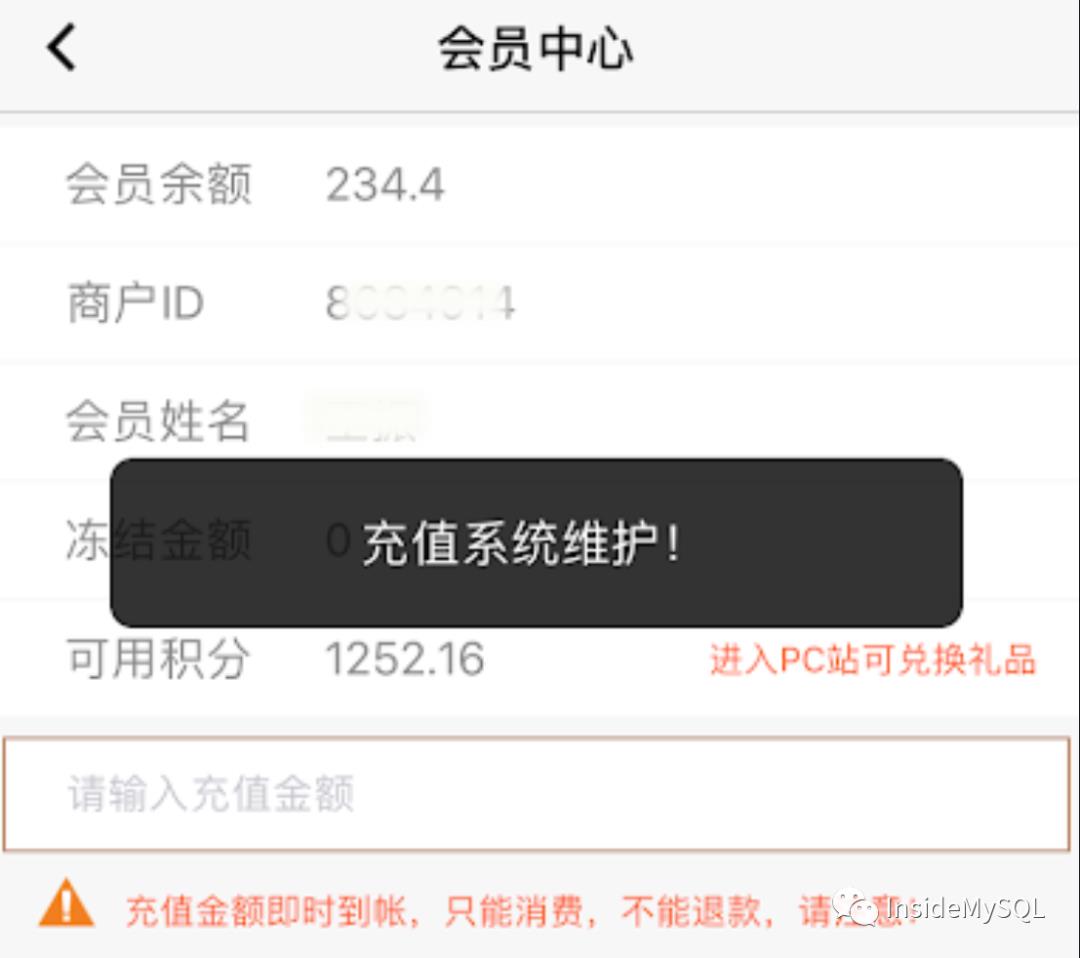
如上图所示,当充值系统可能存在问题时,这时当用户有新请求时,可告诉用户系统正在维护中,稍后将继续提供服务。
上述的降级方案,无论是限流还是熔断,都要求服务层监控数据的收集,因此需要引入类似健康度平台来进行全链路地监控、调度和管理相关服务。
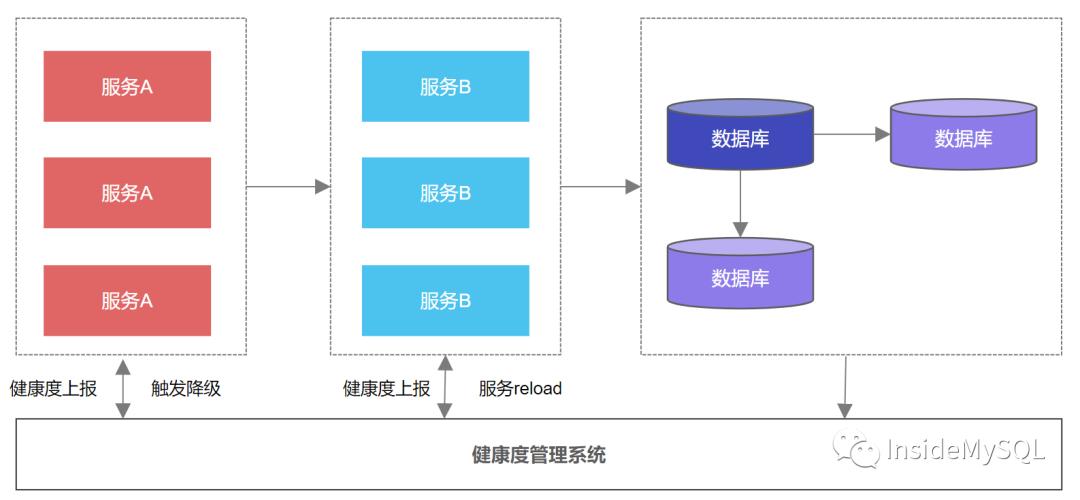
在上图中,由于各组件需要高可用,因此服务A、服务B、数据库都有各自的高可用机制。
每个组件应该上报自己服务的状态到健康度管理平台,不论是采用服务发现还是心跳机制,这样健康度平台才能精细化做好各组件的降级工作。
若由于硬件问题导致单个服务A或服务B的耗时不达标或错误率上升,则应该尽快剔除相应的服务。
若服务A整体耗时或者超时错误率达到一定的阈值,那么健康度管系统应尽快的启动公告机制。防止更多的请求进入系统,造成雪崩。
若数据库发生了切换,名字服务对应的IP变更了,则可能还需要健康度系统通知服务B去reload服务,获取新的IP。
上面这些都只是抛砖引玉,真正工程上的高可用架构设计会更复杂。
因为在海量并发的互联网业务中,还需要进行分布式架构的设计。这时高可用设计的层级会进一步提升。
分布式拆分完后,会衍生出同城容灾、跨城容灾、多活多写、单元化访问等设计和问题。每个行业还有自己所特有的问题,如游戏、电商、金融等。
一个大型系统架构设计想要一步到位几乎是不可能的,若翻看最早的代码,大部分都是一地鸡毛。
然而,随着业务的不断发展,用户请求的不断增大,对技术的要求也会不断提升,这时会倒逼架构地不断发展和演进。
对架构师来说,高可用架构设计是没有终点的,每年都需要解决新问题。这些又依赖每年业务不断的发展而又有新的感悟。
但模块化、Fail-fast、幂等设计、服务降级,这些都是基础。意识并能解决好这些问题,相信已经是一个很不错的架构师了。
以上。
以上是关于架构师眼中的高可用架构设计之道的主要内容,如果未能解决你的问题,请参考以下文章