MySQL中间件性能测试 I
Posted 爱可生云数据库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL中间件性能测试 I相关的知识,希望对你有一定的参考价值。
本文根据黄炎在2018年7月7日【mysql技术沙龙 · 成都站】现场演讲内容整理而成。
黄炎
爱可生研发总监,深入钻研分布式数据库相关技术,擅长业界相关MySQL中间件产品和开发,以及分布式中间件在企业内部的应用实践。
MySQL中间件性能测试 I
摘要:我今天代表我的团队向大家来介绍一下MySQL中间件性能的测试,为大家带来一些不太一样的故事,包括我们在做性能测试的时候一些不太一样的视角。
分享大纲:
1.性能测试的常见的(错误)方法 * 3
2.性能测试的一些(我们用的)方法 * 2
3.分布式事务相关 * 1
我今天代表我的团队向大家来介绍一下MySQL中间件性能的测试,之所以讲选这个主题是因为我注意到大家都是高级的DBA,我们也有很多的高级的DBA,跟大家聊天的时候都会注意到,大家对于性能测试的第一印象:
性能 = sysbench
测试 = run
结果 = tps
数值要高大上
性能就是sysbench,然后测试就是跑一下,这就叫性能测试了,结果就是要TPS或者QPS,数值一定要高大上,这是大家对性能测试测试的第一印象也可能是唯一的印象。我们公司是属于乙方的技术服务提供商,我们对业界的很多产品进行过性能测试,所以今天想为大家带来一些不太一样的故事,以及我们在做性能测试的时候一些视角。
我今天大概会向大家介绍三件事情:
第一件事情是我们观察到,大家在做性能测试的时候,在针对数据库的中间件做性能测试的时候会有一些常见的方法,我们会介绍其中的三种方法和相关的场景以及可能产生的一些错误。
第二件事情是在性能测试中我们在实际中使用了几年的一些方法,这些方法可能跟大家平常见的不太一样。
第三件事情是一个关于分布式事务相关的章节。
一.性能测试的常见的(错误)方法
首先看我们的常见方法,其中我想讨论三件事情,
测试中间件性能的观测对象是中间件 ?
性能测试指标选取: 吞吐 or 延迟 ?
性能测试报告的结论 是要得到绝对数值 ?
1.测试中间件性能的观测对象是中间件 ?
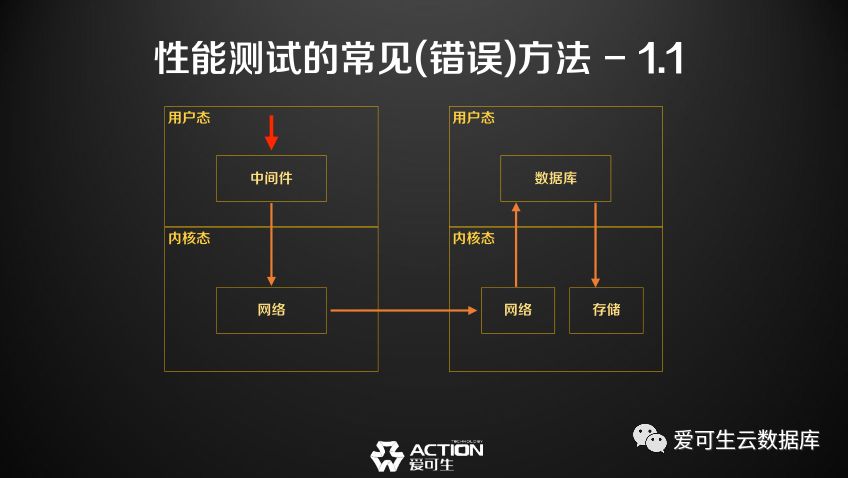
在这个压力流向图中,红色的箭头是大家做性能测试时的观察点,可以看到: 我们在观察这个压力时, 观察的不是中间件的压力, 而是后面多个系统产生的一个综合的压力,在这种观测视角下我们很难评估一个中间件到底是好还是不好。
l 测试中间件的观察对象是中间件+连接属性+?
这是一个真实的故事,有一天我们的测试同事找到我,让我解释一下这个图是怎么来的?
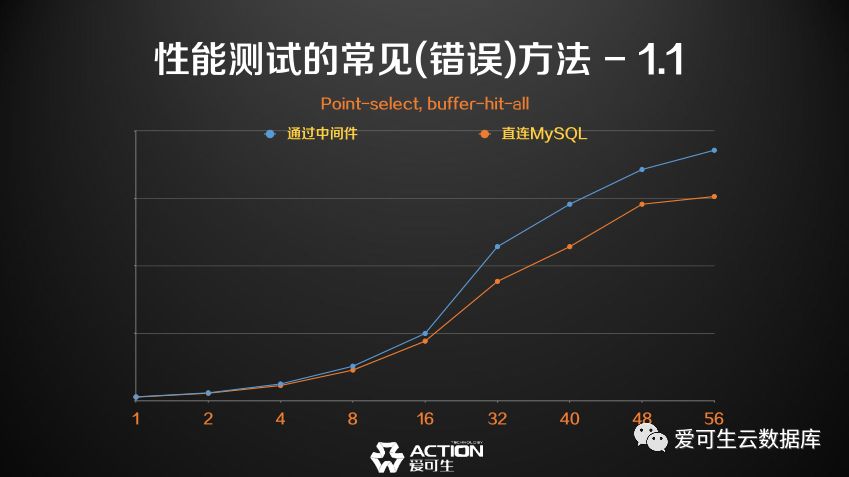
如图所示,这个中间件是一个简单的流量转发类的中间件,后端只有一台数据库, 压力类型是Point-select,就是做简单的命中主键的select,并且压力是全部命中缓存的,可以验证数据库没有任何磁盘IO. 横轴是并发,纵轴是QPS,蓝色的这根线是中间件的性能线, 橙色的这根线是直连MySQL的性能线。
为什么通过中间件的性能会比通过MySQL的性能要高?
当时拿到这个结果的时候,我去验证了所有的环境,我认为环境没有问题,压力没有问题,那么这可能是我这一生中离诺贝尔奖最近的一次,如果说这个现象成了,那么就相当于我在这个网线造了一个黑洞出来,信息通过这根网线的速度比光速要快, 因为大家知道网线上跑的是电子, 电子的最高速度是光速,或者说我换用一根光纤, 它的最高速度也就是光速,我们的数据库SQL跑的速度要比光速快,才能做出刚才的性能图。
当然最后我是没有拿到诺贝尔奖的,是因为连接MySQL 5.7时,直连数据库和连接中间件的两根连接的类型不同,其中一端是默认开启的TLS的,直接用客户端去连数据库的时候默认会开启TLS,而连接中间件时则不通,因为一般的中间件实现都会比较懒,它不会去做TLS, 所以这两根连接的条件不对称,直接导致了中间件的性能要比直连数据库的性能要好。这是我想带来的第一个场景。
这个场景就扩大了我们的观察对象,对中间件的性能测试,除了中间件以外还需要观察它的连接属性的不同。
我们来看一下第二个故事。大家来考虑一下这个SQL:
prepare ps from ‘…’;
select * from a limit 1;
select * from b limit 1;
如果我将这三句话发往一个中间件和发往一个数据库到底有什么区别?
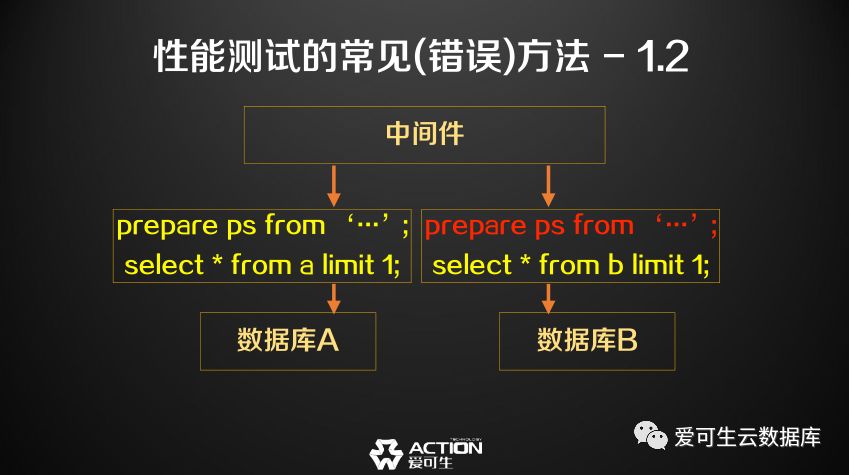
中间件的情况如图所示,后面有两个数据库,将第一个prepare发往A库,然后第二个select可能发往任意一个库,我们假设它发往A库, 那一切正常,如果第三个select发往了B库,那么prepare会被带到B库上去做。在目前的语句下, 其实prepare是可以不需要带到B库上的,因为它后面的select跟prepare没有关系. 但如果我下面发一个Exec, prepare就一定要带到B库上。
这个场景中, 发到中间件的压力和中间件实际下发到数据库的压力可能会变多,之所以变多, 是为了中间件要维持一个特性,这个特性叫中间件的上下文转移。大家如果用过开源的中间件,这个术语应该就比较熟悉。
l 中间件的上下文转移
· 事务级别 (同一事务一定发到同一节点)
· 会话级别 (上下文迁移)
- 系统变量
- Prepare Statement
- 临时表
- 用户变量
- 与会话相关的特殊函数
- LAST_INSERT_ID/ROW_COUNT
- Default schema
事务级别的上下文转移, 指的是对于简单转发类中间件, 同一个事务的SQL要发往同一个后端的数据库。
除了事务级别, 常见的中间件还会做一些会话级别的上下迁移,比如系统变量,如果把binlog关掉,意味着之后的语句不计入binlog,那么后面的语句不管发到哪台数据库一定要把这个系统变量带到后面的数据库里边去。然后比如说Default Schema,这个是常见的中间件需要实现的部分。
我们来看后面,还有一些常见的中间件不一定会实现,比如会话级别的上下文迁移还包括prepare statement、临时表、用户变量以及特殊函数。特殊函数其实正常的情况下人为使用的并不多,但是大家使用的各个driver都会依赖于这些特殊函数来做,比如说分页、筛选都会依赖于这些特殊函数来做,所以一个好的中间件会对于这些绘画级别的,上下文转移的行为要么支持,要么有明确的文档说明不支持,要么加以限制,这个是中间件的上下文转移带来的在性能测试中的差别。
所以我们再次修正我们中间件的观察对象,中间件的观察对象是除了中间件,还有连接属性,还有必须要观察实际下发的SQL。
l 同一环境下, 中间件损耗越小是否QPS一定越高?
第三个故事,我们来考虑一下,在同一个测试环境下,两款中间件中损耗比较小的那款是不是得到的QPS一定会更高?正常的情况下我们认为一个系统里边如果某一个环节损耗小了,整体的损耗就小, 得到的延迟更低,QPS一定会更高。
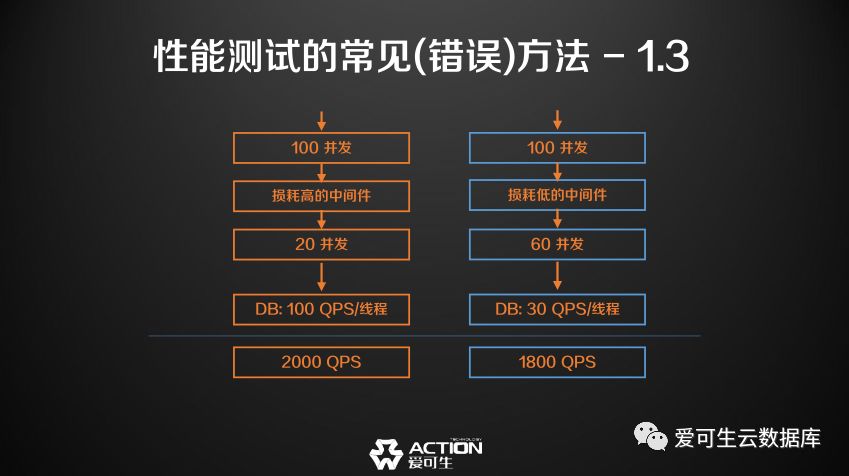
但实际上, 请大家考虑这样一个场景,我列举了左右两款中间件,左边是损耗比较高的中间件,右边是损耗比较低的中间件,都用同一个压力测试场景,打了一百个并发下去。
左边的中间件因为它的损耗比较高, 相当于下发了20个并发,另外的80个并发在损耗的过程中,右边的中间件稍微好一点,它下发到数据库的并发是60个并发,那么数据库在不同的并发下,因为有资源竞争, 单线程的QPS就会变。20并发下竞争会比较低,所以每一个线程,它的QPS比较高,可能是100 QPS。而60并发下, 每个线程的QPS可能只有30,20个并发乘以100个QPS和30个并发乘以60个QPS,算下来:损耗比较高的中间件,有可能它的QPS会更高。
这是性能测试中的一个常见错误,如果只是简单的观测,那么我选择的应该选那款比较慢的中间件。
这是我的第三个场景,平常我们在实践的时候会去计算中间件的一个指标,我们把它叫做穿透率,一个中间的穿透率是多少,这个意思是中间件往下发的压力 比 发到中间件的压力。

回到之前快慢中间件比较的场景,左边中间件的穿透率是20%,右边中间件的穿透率是60%。通过计算穿透率可以评估一个转发类中间件的性能。如果是分布式类的中间件还不能这样评估,因为穿透率越高,并不代表一个分布式的中间件的处理性能更好,需要其它的指标来评估。
我们在测试的时候,如果要比较两个环境的性能,就一定需要注意: 先让对数据库的压力表现相同,其中就包括连接的属性、SQL、平均延迟等,才能比较两个中间件的性能的好坏。如果不满足这个条件,测出来的是整个系统的表现,而并不是一个中间件的性能表现。
所以中间件的最终的测试对象,我们最终的结论:
测试中间件的观察对象是
中间件+向数据库的实际压力
在这里我可以透露给大家一个小的故事,这个故事是真实发生过的,因为我们是做乙方的,像大型的银行金融机构提供解决方案,然后有一次我的项目经理就来找我,说我们中间件测试跟友商的比QPS差了很多。我说你给用户跪吧,之后我们派了一个资深的工程师到现场去看,把两套环境拿到一起看,我们发现友商的环境上,MySQL的binlog是关掉的。然后我们就把那个项目经理从地上扶起来,向客户去解释其中的道理,我们解释的道理就是刚才这个道理: 一定要观察数据库上的压力表现。
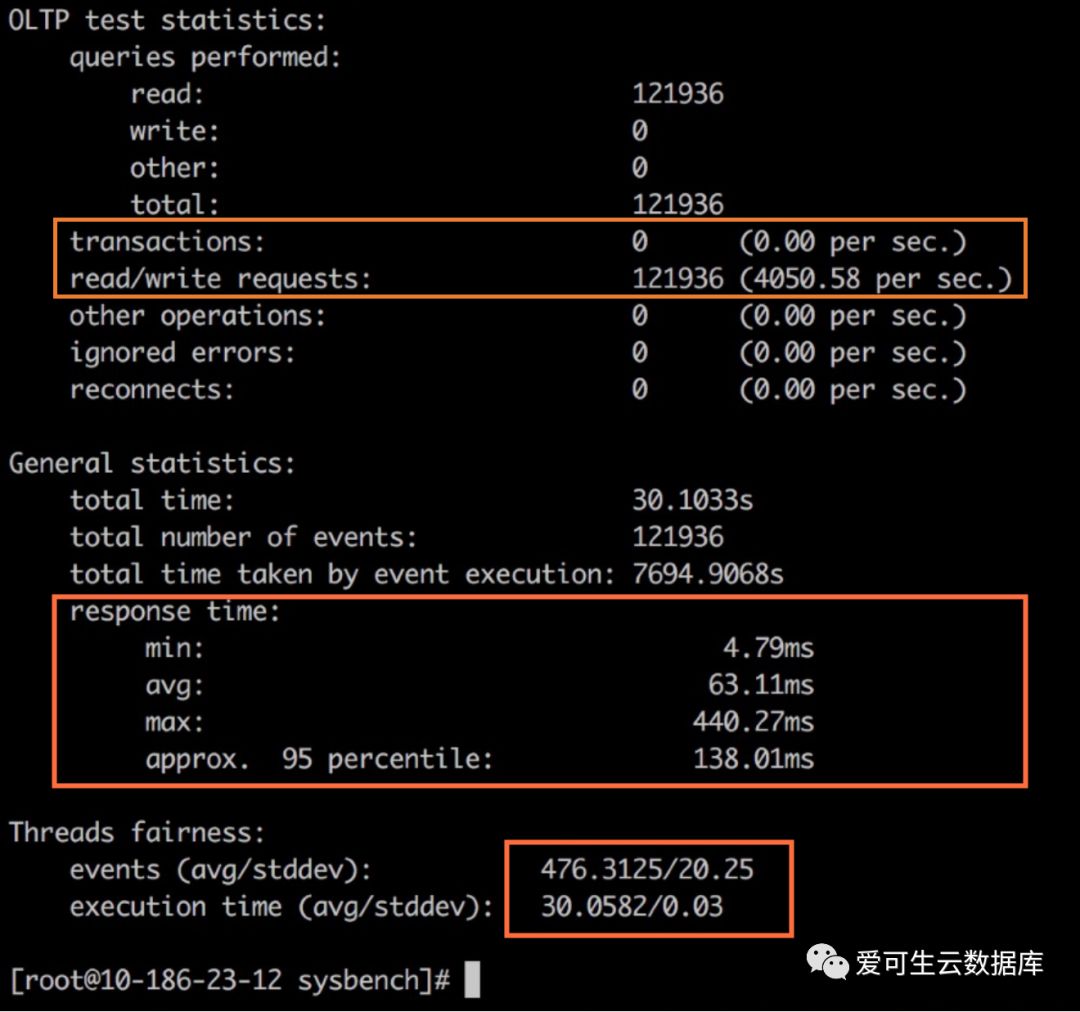
这是一个sysbench的性能报告,大家第一眼看这个报告, 关注的通常是这个位置,4000QPS,纯读的压力。
除了这个部分以外还需要注意其他两个部分:
第一,Response time, 即响应时间,下面的几个数值是最小值,平均值、最大值和95%分位数,这四个值能构造出一个延迟分布的密度曲线大概的形状。举个例子,如果在现在这个情况下,95%分位数接近最大值( 比如把图中的138.01ms改成438ms),那么说明这个测试中的异常值的出现概率超过5%,比如说,能观测的性能点是12万个点,在这12万个点里边有超过高过5%的观测点,是高过438毫秒的,那么我们认为: 在这个压力表现下, 这个中间件的某一些连接的延迟很有可能出现了异常. 响应时间指标的作用,是构造延迟的分布曲线的大概形状。
第二,Threads fairness,线程的公平性,举例两款中间件,有一款中间件我们打4个并发下去,其中三根连接是不工作的,只有一根连接效率特别高,它可以达到4000 QPS;另外一款中间件每根连接效率没有那么高,但是每根连接都可以达到1000 QPS。如果大家去买的话,用一万块钱去买中间件,大家会买哪一款. 这就是线程的公平性的度量目的。线程的公平性的两个数值: 前面是它的平均数,后面是它的标准差。这个标准差一定不能太高,如果太高的话就意味着它每根的线程处理的效率不一样,一般意味着这个中间件中间哪个环节错了。
2.性能测试指标选取: 吞吐 or 延迟 ?
高压力下, 高吞吐
低压力下, 低延迟
举例,如果有一款中间件在低并发的情况下延迟很低吞吐还好,随着它的并发越来越高,它的吞吐基本上是一个线性的增长,并发数增长十倍,吞吐量增长了九倍,这个系统已经看起来还不错,但是延迟增长了20倍左右,这一款中间件大家在实际的业务上会不会选呢?
我咨询过业务相关的同行,他们的答案是完全不一样的,有人会用,有的人不会用,完全取决于它的业务类型。 如果是个低并发的业务,会认为这个中间件够用,如果说业务是一个高并发并且对延迟没有太高的要求,150毫秒之内的延迟都能接受,那么这款中间件它的吞吐量线性成长率其实是非常不错的。但如果是延迟敏感型的业务,它的延迟要求很高,比如说它最多只能接受25毫秒的延迟, 那么这款中间件就不应该选。
所以在进行性能测试时,到底选择吞吐还是选择延迟是要跟着业务走的,业务必须要给出底线我们才知道怎么测,否则拿到例子中的数值,第一反映就是一百毫秒这个数很大,就不想用,但其实它的吞吐的线性成长率还是比较好的。
一般的来说,开发在做一个系统的时候很容易低成本的做出高压力下能承受高吞吐、低压力下能做到低延迟的这样一个系统,但是反过来不行。如果在高压力下做低延迟,这个成本在开发上是异常的高,需要用尽各种极端的技术来做,如果在低压力下做高吞吐,这个在现实中没有意义,所以在成本受控的情况下做出来的一般都是这样的效果. 如果大家从事中间件的测试的话,那么对中间件的期待的要求不要太高,贴合业务的性能表现是最合适的。
这是我想讨论的第二件事情,性能指标的选取就是不同的压力下一定要选取不同的指标并且一定要贴着业务走,业务一定要告诉你它的底线在哪里。
3.性能测试报告的结论是得到绝对数值 ?

假设大家在评估这样一个数据库,这个数据库它的测试参数都列在屏幕上,测试使用sysbench工具,压力类型是OLTP只读方式,读的类型是点选,一共八张表,每张表有一兆行的数据,使用Socket连接,64并发,测试环境是72核超线程. 在这种情况下这台数据库能做到QPS是40万以上,大家觉得这款数据库怎么样?
如果你手里有钱,会不会去买这样一款数据库来支撑你的线上业务,这款数据库是谁?这款数据是MySQL 5.5。
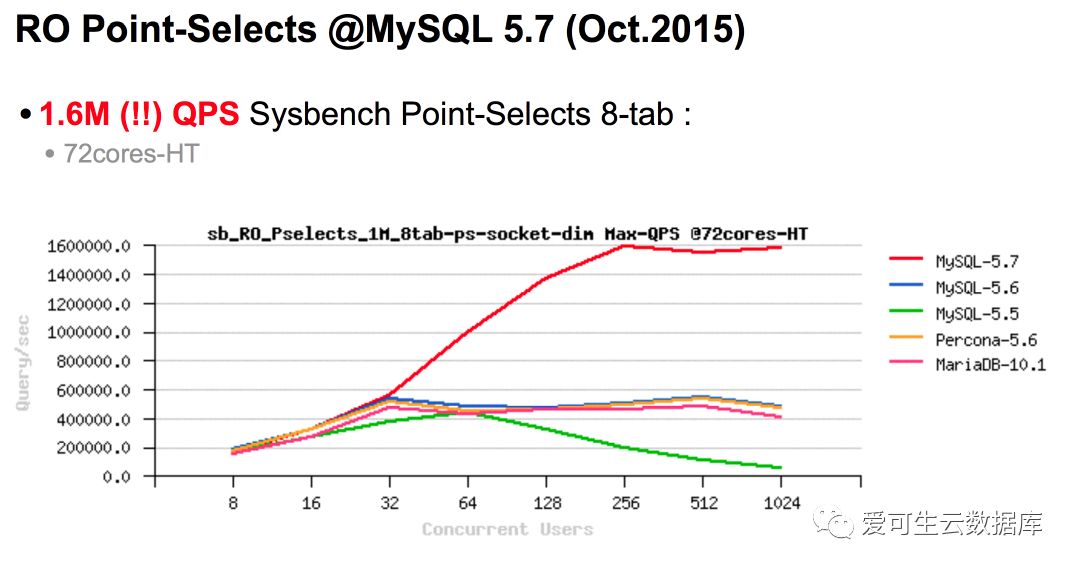
这张图来自于MySQL 5.7的官方报告,其中这个点是MySQL 5.5,它能在64并发下做到40万QPS,看到这个数据时我其实有点惊讶, MySQL 5.5是我刚工作的时候的数据库版本,那款是大家公认的性能比较差的数据库,但是它就能做到40万QPS。

这张图来自于MySQL的一份报告,我强烈推荐这个报告的原因是,首先这个报告里边是有绝对的数值,同时,报告里有对数值的比较,再同时它有对每个场景进行压力分析和瓶颈分析。如果大家一定需要一份带绝对值的测试报告,我强烈推荐这份测试报告,因为它里面带了若干的分析,而且它里边有一句非常有意思的话:
Numbers are just reflecting what is behind。
这份报告有专门的一节来解释为什么应该相信压力分析和瓶颈分析,而不应该相信绝对数值。我们回到刚才这张图,MySQL 5.7在这个压力场景下能做到的是一百万,如果在128并发,按照最高到256的并发这样的场景下能做到1.6兆的QPS,但实际上我们很少有人在线上能跑出这样的值. 按照我们团队的多年测试的实践经验,做性能测试不要以找到值为目的,而要以找到瓶颈为目的,并且要把这个瓶颈解决掉。如此循环直到这个瓶颈无法解决为止。
实践经验:
以找到瓶颈为目的, 直到瓶颈无法解决
更容易找到 可重现的 正确的 性能值
比如说遇到操作系统的瓶颈,万兆网卡已经不够用了,吞吐已经上不去了,在成本内能买到的卡就是这个样子,那这个瓶颈就没有办法再解决了。这样我们能得到一个正确的并且可以重现的性能值.
以上三点总结:
1.测试中间件的观察对象是:
中间件+向数据库的实际压力
2.性能测试指标选取:
在不同并发下, 选择不同指标
3.性能测试报告的结论应当是:
同等条件下的 性能比较 和 性能瓶颈分析
二.性能测试的一些(我们用的)方法 * 2
下面介绍2种我们用下来比较成熟的方法:
1.观测, 观测, 观测
-eBPF/Systemtap
-中间件自身提供观测
-USE
2.测试工具校准
关于观测:
第一,推荐两种观测工具,eBPF或Systemtap;
第二,我们自己也做中间件,我们中间件自身是提供了一些观测指标的,向大家介绍一下这种方法;
第三,有一种线程是对于资源消耗的观察手段,即USE;
l eBPF 操作系统级的观测
eBPF此处引用我的同事洪斌在今年的phpCON的演讲,他的演讲主题是《MySQL性能诊断与实践》,其中详细的介绍了一下这个工具能给大家带来什么好处,列举其中几个,如:
1. 延迟分布,比如MySQL请求的延迟,VFS延迟,Ext4的延迟,块设备的延迟等;
2. MySQL的文件IO压力分析;
3. 临时表的生命周;
4. 短连接的分析;
详细演讲内容:github.com/actiontech/slides
举一个例子,下图是eBPF的一个脚本,可观察MySQL的延迟,它会给大家列出延迟的分布曲线:
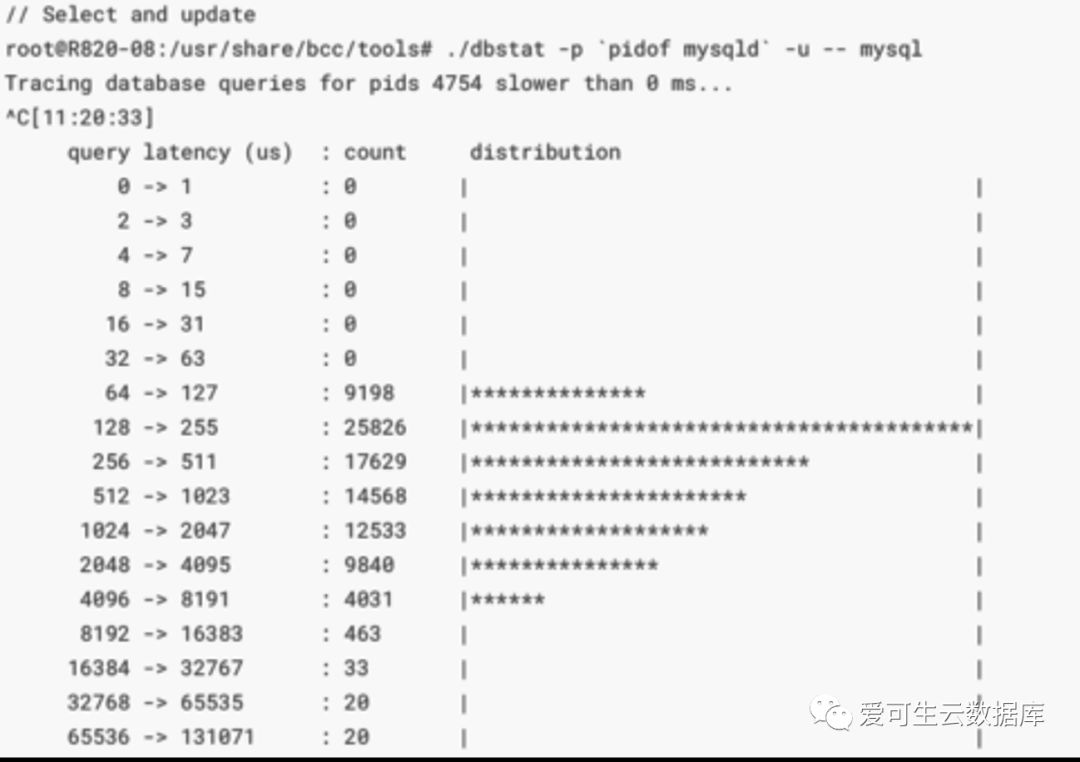
左边这一类是延迟,从零到一,二到三,四到七,它是指数级增长,单位是微秒,可以看到的是 压力打在数据库上的平均延迟,大量的数据压力在128微妙到255微妙之间,这个数据库的整体延迟还是不错的。
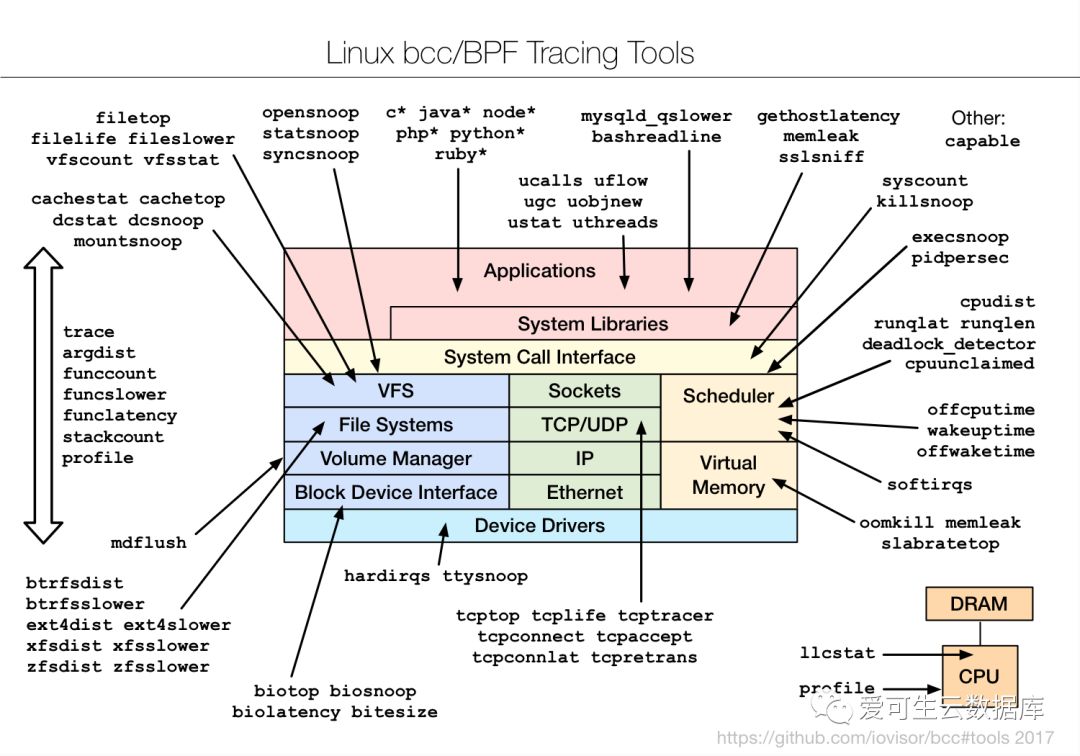
这张材料引用自Breddan Gregg的项目BCC,是eBPF的实用脚本集,它能观测操作系统的方方面面,来帮助大家做压力观测。
l 中间件自身提供观测
操作系统的观测已经很全了,为什么中间件本身也要提供一些观测点,我们自己的中间件DBLE,是一个开源项目,GitHub上可以搜到,在DBLE中我们提供了这样的一种观测方法,如下:

DBLE把一个压力下来分成了六个阶段:
- 开始梳理
- 完成解析
- 完成路由分配
- 从数据库回收结果
- 后置处理
- 反馈处理
每个阶段提供了时间分布,这样我们可知道压力到底在中间件的哪一个阶段变慢。
比如在这个数据下,中间件的性能其实不错,是因为从第三个点到第四个点之间是后端数据库的处理,它占了整个处理时间的70%以上,所以在这种情况下可以判断后端数据库已经慢了,而不是中间件产生了什么太大的问题,所以中间件本身应该提供观测。
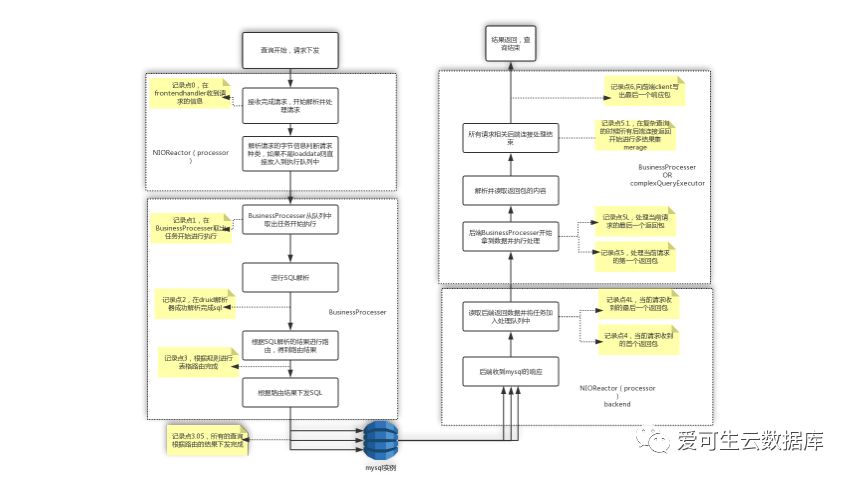
在这个项目的文档中, 我们把画了中间件的压力处理流程,其实对于大部分的中间件都是这样的,这张图在DBLE开源的文档上都可以找到。安利一下我们自己的中间件DBLE,大家有兴趣的话可以去看一下,文档齐全,分析方法也很齐全。
中间件本身的观测与操作系统的区别在于: 中间件提供的视角是站在压力处理的视角来提供的,操作系统视角是站在资源的视角来提供,这两个视角缺一不可。如果只知道操作系统说IO压力大,但是并不知道是哪个环节造成的压力大,那诊断瓶颈的成本会比较高. 这就是为什么中间件要补充一个视角。
l USE
对于资源来说,强烈推荐《性能之巅》这本书,它介绍的分析方法叫USE,就是使用率、饱和度、错误率这三个指标就足以评估一个资源,IO资源也好,网络资源也好,足以评估一个资源现在的使用状况。
举一个例子,为什么使用率和饱和度得分开,如果现在操作系统告诉我们内存占用率是100%,内存能不能再申请出来一块?是可以的,因为内存的使用率100%,其中比如说有50%是分给buffer和cache, 操作系统会自动回收,这种情况下内存的使用率是100%,但饱和度并没有达到饱和,我们可以继续使用内存,直到它的饱和度上升到100%为止,这个内存就再也申请不出来了。
所以这就是为什么这本书将使用率和饱和度一定要拆开的原因。强烈推荐!

我们在DBLE中间件内部也提供了类似这样的观察机制,有点像Linux的Load average. 我们对于它的每一个线程的使用都提供了一分钟、五分钟或者是十五分钟这三种使用率的评估。通过使用率就可以观察到在并发压力下中间件的运行状况到底是死在了一根线程上,还是每根线程上承载的压力差不多。之前关于线程公平性的问题也可以通过这个指标来诊断。
2.测试工具校准
测试工具校准,举个例子,BenchmarkSQL,是Java版的TPCC,不少银行都在用它检验一个数据库或者是检验一个中间件能不能正常表现,但是我们碰到了这样一个问题:在测试压力中, 测试脚本要删一个记录,如果删不掉我就一直的删,一直删,但是这个工具在RR的隔离级别下造成一个死循环。

这个死循环是这样的:
第一句话它把auto commit设成0;
第二句select就会开启一个事务;
第三句话在这个压力下跑过一段逻辑之后再select看看这行数据还在不在,如果在就去删掉它。如果隔离级别是RR的,在第二三句之间把这行数据删掉,那么此时还能看到这行数据对吧. 但之后的delete回应没有影响数据行,所以BenchmarkSQL就会陷入上面的这条死循环,看到数据, 删除, 没删掉, 然后就一直会去删,但是一直能看到这行数据,所以就会陷入这个死循环。
换句话说BenchmarkSQL,在RR的隔离级别下就会造成这样一个死循环。 很难想象这个工具是在银行客户中被大量使用. 有一天项目经理告诉我,友商的中间件好着啊,然后我们就必须要去研究这款中间件,为什么它没有问题,原因是设置了RR的隔离级别, 它实际下到数据库的压力是RC隔离级别,RC隔离级别错在第三步看不到这条数据,它就不会跑下面这个循环,所以人家的中间件的错误将测试工具的错误抵消了。我们呼吁在测试时保持科学的态度.
在开始演讲之前姜老师的笔记本在这个环境下工作是好的,我说能不能换我的笔记本做这个演讲,我就把线插入我的笔记本然后两边都显示不出来了. 这个时候姜老师最应该说的一句话是什么呢?在我的环境下它是好的啊,但他并没有说,这是一个很科学的态度。
关于性能测试,我们推荐两个方法:
第一个方法,性能测试一定要去观测,观测的目的是什么,看到瓶颈,看到瓶颈的目的是什么?解决掉它以获得一个完全可以重复的正确的性能测试值来获得正确的结论。
第二个方法,测试工具一定要校准,业界常用的测试工具有很多,不要相信一些小众的测试工具,每一种测试工具都一定要校准。校准的话可以用多种测试工具同时去跑,去校准,或者是去分析测试工具的压力类型,刚才的观测过程就足以分析一个测试工具实际下发到后端的压力到底是什么,足以看到它的压力类型是什么,分析它的压力模式是不是正确的,以做测试工具校准。
所以在我们的公司ISO流程里边有一个规定是半年用这个测试工具做一次校准,因为测试工具也在面临着升级,我们面临的测试工具很多,这是我想讨论的第二个部分。
三.分布式事务相关*1
分布式事务相关,其实跟性能没有什么太大的关系,它来自于一个故事。我们做数据库的服务提供商,面试过很多人,大家都会在分布式事务上企图寻找亮点,然后我们就经常问如何证明分布式事务是有效的,比如说MySQL有XA,之前也有公司推出了快照隔离级别的分布式事务中间件,如何测试分布式事务中间件是有效的,我们得到最多的一句话就是你可以随便的拔电源一百次,然后那边就说可以拔两百次,那边又说可以拔三百次,都是这样的一个情况。
1. 事务性
对于分布式事务相关来说,不管是正确性也好还是性能也好,首先是要去验证ACID数据的异常,因为大家做数据库都会妥协,说这个数据库比那个数据库性能好一定是做了什么妥协的,这些技术一定是关系到这些数据异常。
l ACID相关的数据异常
数据库异常的分类:
脏读/不可重复读/幻读/脏写/更新丢失/写偏序/读偏序/…
测试分布式事务时, 至少应该知道这些数据异常的场景. 一个分布式事务实现,如果脱离MySQL在中间件上做一个分布式事务实现的话,一定是从头开始做东西,就一定要从最原始的理论基础来去证明每个异常场景都能被正确处理。
l 针对锁机制的弱点: S2PL/SS2PL
大量的分布式事务实践在使用锁机制,那么在锁机制里边就两种锁一种是S级别的2PL和SS级别的2PL两种,每一种实现都有它的弱点,建议针对这些弱点进行相关的正确性和性能测试。
2.可靠性和性能
- CPU
- 内存 (perf - NUMA)
- 磁盘 (systemtap - 延迟/错误)
- 网络 (tc - 延迟/乱序/篡改/丢失)
- 进程 (kill / hang / 线程乱序执行)
…
关于破坏性测试,拔电源到底够不够?可靠性能的测试一定要从这几个方面,一定先从资源的角度去考虑。
第一,内存, NUMA到底该不该关闭,把它打开对性能到底有什么影响,都可以通过perf来观察到,或者是通过perf来注入一些错误点让它产生一些错误,内存或CPU都可以注入错误。
第二, 磁盘很早的时候淘宝的团队就在用systemtap在IO上做延迟和错误的注入,比如模拟一个IO是失败的,或者是模拟一个IO无限的等待下去,Pingcap也有相关的文章介绍,这也是我们的日常使用的技术。
第三, 网络,用TC可以做出四种网络故障,延迟,乱序,丢失,篡改. 网络故障不单纯是开启iptables, tc可以做出这四种,并且按概率来安排这四种故障。
第四,进程,关掉电源很多时候模拟的都是进程kill. 除了这个以外还有进程hang,以及很多人都会忽略掉的线程乱序执行。在某些机器中,程序的线程是按照某种顺序执行的,但是换一个CPU或者换一个环境,或者是打个干扰压力上去, 程序的线程就会乱序执行。
我们看一个分布式事务测试报告说测试对象是正确的,一定要考虑这些方面. 下面是我们同事写的一句话:
怀着敬畏之心
怀疑每一行代码都会
- 出错
或者
- 不返回结果
一定要怀着一个敬畏的心怀疑每一行代码都会出错或者是不返回,我写这个slide的时候应该是三四周之前,后来第二周阿里就挂了,然后阿里的故障分析报告上也是同样的一句话,就是你一定要怀着一个敬畏之心. 大家通过这么多钱买下来的经验都是这样的,对于一个系统一定要怀着敬畏之心去看待它,不要没事儿去拔电源, 我又不是卖电源的对吧!
以上是我今天的分享,谢谢大家!
PPT下载链接:
https://github.com/actiontech/slides

爱可生(证券代码:832768)依托于融合、开放、创新的数据处理技术和服务能力,为大型行业用户的特定场景提供深度挖掘数据价值的解决方案。公司持续积累的核心关键技术,覆盖到分布式数据库集群、云数据库平台、数据库大体量运管平台、海量数据集成与存储、清洗与治理、人工智能分析挖掘、可视化展现、安全与隐私保护等多个领域。
公司已与多个行业内的专业公司建立了长期伙伴关系,不断促进新技术与行业知识相结合,为用户寻求新的数据驱动的价值增长点。公司已在金融、能源电力、电信、广电、政府等行业取得了多个大型用户典型成功案例,获得了市场的广泛认可和业务持续的增长。
以上是关于MySQL中间件性能测试 I的主要内容,如果未能解决你的问题,请参考以下文章