中间件黑科技之鹰眼系统
Posted 匠心独运维妙维效
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中间件黑科技之鹰眼系统相关的知识,希望对你有一定的参考价值。
中国光大银行信息科技部系统运维中心
今年俄罗斯世界杯,多了一项以前没有的内容,即VAR(Video Assistant Referee),视频助理裁判,有争议时,主裁就会跑到场边看视频回放,然后再做出裁决。VAR 首次使用,为比赛的公正性提供了非常有力的协助,避免出现了当年德国vs英格兰的“门线惨案”。
网球、羽毛球、排球、击剑等项目也使用了鹰眼,也被称为即时回放系统。在鹰眼的帮助下,网球比赛中的争议和误判得到最大限度减少。看网球比赛时最有意思也最带感的事情之一就是看球员挑战鹰眼了。球员食指一竖,主裁判立刻就开始对着麦克风说:xxx先生/女士挑战EDF线的呼报,此球被喊IN/OUT(界内/出界)。之后现场观众就开始自觉地集体鼓掌,有些赛事还会在大屏幕上显示动画并且配合音效,气氛那叫一个热烈。而无论这球是界内还是界外,挑战成功与否,观众都要好好喧嚣一番。要是碰到费德勒对小德这种比赛的关键分时出现挑战,那球迷闹得更是火热,全场上万人跟那儿喊“IN”的场景也是颇为壮观。
鹰眼之所以称之为黑科技,是因为它提升了人工解决问题的速度和准精度。记录并回溯问题场景,精准发现问题,迅速改正问题正是“鹰眼”灵魂。

中间件是我行基础技术体系中的重要组成部分,承载着我行绝大部分业务系统的日常运行,其运行稳定性、运行性能的好坏会直接影响我行业务系统的服务能力进而影响用户的整体体验,业内对中间件应用性能管理划分了如下五个阶段:
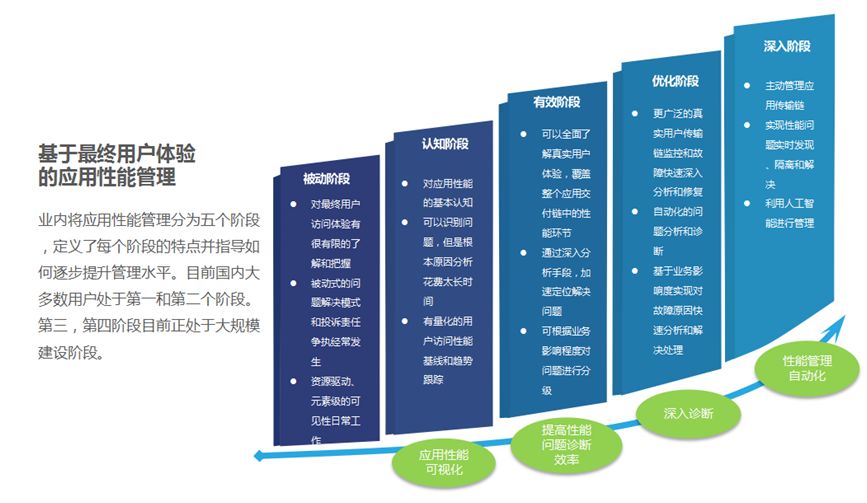
目前国内绝大多数企业在中间件运维领域都停留在第一和第二阶段,我们定义为中间件运维1.0阶段,即被动响应事件,按救火队的方式逐个解决中间件事件,这种运维方式依赖故障现场收集,依赖中间件运维工程师专业技能,只能事后分析。一旦故障期间数据收集不全,则故障定位困难,问题解决周期长,效率低,只适合运维实例环境不多的场景,随着业务需求爆发式增长以及生产环境云化带来的中间件实例大量增加,现有运维模式及人力已经无法满足运维需求,现实情况要求我们向第三四阶段转型,我们定义为中间件运维2.0阶段,即从业务视角,打通应用、中间件、数据库、网络、基础环境的关联关系;更快速、更精确、更自动化智能化的实现中间件应用数据分析;更标准化,广范围、低门槛的中间件运维技能供给。
为了实现这个转型,我们尝试了一些方式,如编写一线预案、完善mbean数据采集工具等,但实际效果有限,因受中间件数据采集接口限制,数据采集有短板,难以快速明确系统异常的具体位置,难以对交易执行时间、执行时间分配等更细化的性能项进行采集,也无法进行故障回溯排查。最终我们将方向定位在尝试向生产环境引入APM产品,结合定制化开发,实现我们的需求,中间件分析诊断系统(以下简称鹰眼系统)如此应运而生。
鹰眼系统建设目标:

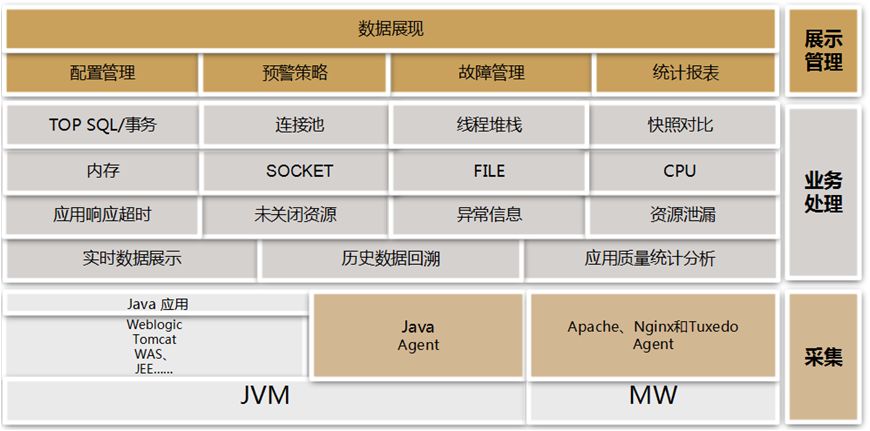
鹰眼系统技术架构:
鹰眼系统由 Agent、Collector、Console 三个主要模块组成,应用系统在其中脚本中加入鹰眼agent的启动参数,重启应用后即可生效,鹰眼系统通过代理采集性能数据,汇总到Collector结点,通过kafka将实时数据送入Spark中处理,将处理结果入库;将历史数据入HBase,Console 是轻量级的和无状态的,用户可以在此总览 Agent 实例的监控信息、实时监控性能指标、分析内存泄露、资源未关闭等问题产生的原因,迅速定位有问题的应用。
鹰眼系统数据采集借助了java字节码操纵技术,Agent 部署在JavaEE 应用服务器上,负责收集在JavaEE 服务器中运行的JSP/SERVLET、EJB、SQL 语句等的性能信息并将收集到的信息聚合后再上报给Collector。jvm通过配置参数,启动时将javaagent加载到JVM之中,作为JVM的一部分。并且在main方法执行前,执行agent的代码去注册ClassFileTransformer。jvm在加载类文件的时候发出ClassFileLoad的事件,然后交给instrument来调用javaagent里注册的ClassFileTransformer实现字节码的修改。字节码的修改使用了ASM框架,这是一个JAVA字节码分析、创建和修改的应用框架。通过ASM对协议规范的实现类(例如JSP/SERVLET、EJB、jdbc的实现类)进行字节码增强。从而达到动态注入代码的目的,进而动态对JVM的运行数据进行获取。这种注入方法无需修改任何应用代码,可实现无侵入式的动态注入。
鹰眼系统功能列表:
鹰眼系统主要实现了如下功能:
中间件性能深度诊断与自动化分析展示:实现中间件运行性能深度诊断,可对中间件运行情况,应用的运行响应时间,SQL执行情况,内存泄露情况、应用负载情况等方面进行汇总分析并通过定制化视图展示,并可提供日报、周报、月报的巡检功能,实现中间件性能精细化管理,提升中间件事前分析能力。
中间件故障信息回溯:提升中间件事件回溯分析能力,可不局限于故障时采集的异常信息,可对中间件异常之前的线程堆栈、内存镜像、响应时间等指标进行记录,优化中间件故障支持的能力。
中间件性能测试代码级技术支持能力:将中间件性能数据深度采集与分析应用于测试环境,在上线前进行对系统运行情况进行更深入评估,规避更多性能问题,确保系统上线后稳定运行。注:目前暂时仅支持JVMAGENT。

目前我行已基本实现鹰眼系统全覆盖部署,部署点数达到了近1000点,这在业内是目前已知较大规模的APM部署体量,整个实施过程未对生产产生影响,目前我行weblogic中间件生产系统均能享受到应用异常现场快速定位,历史数据对比分析等中间件运维服务。

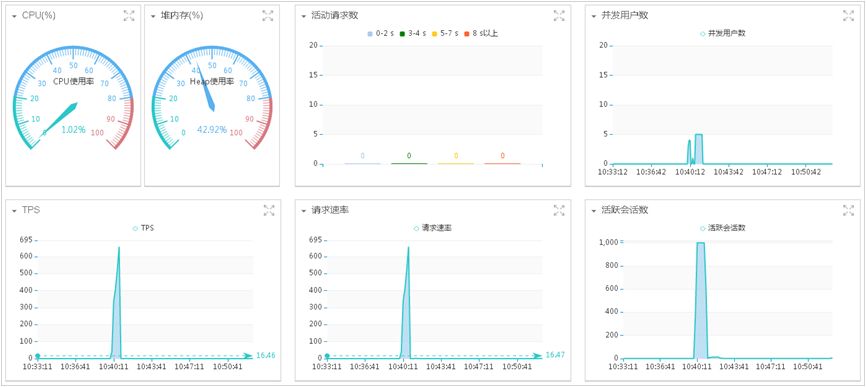
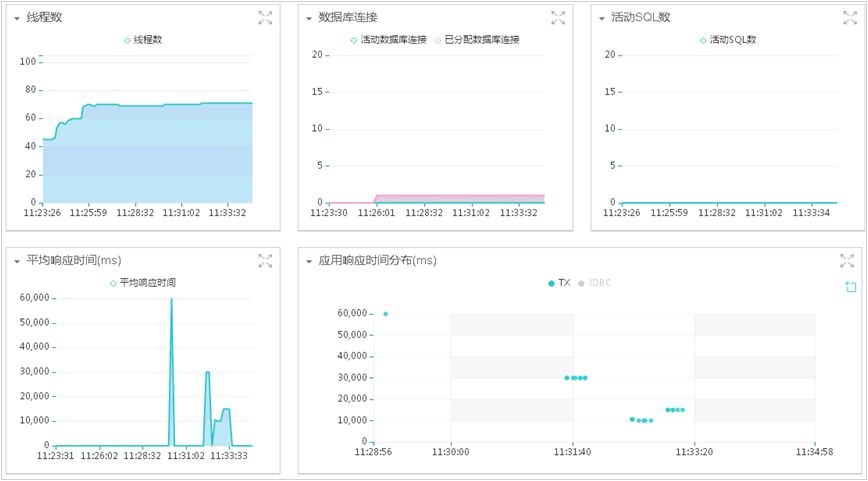
实时数据分析:
实时展示的指标数据包含:CPU使用率(%)、JVM堆内存(%)、活动请求数、并发用户数、TPS、请求速率、活跃会话数、线程数、数据库连接、活动SQL数、平均响应时间和应用响应时间分布。
查看各个指标,如TPS有没有压上去;平均响应时间是否符合预期;应用响应时间分布是否均衡;有没有大量应用访问失败的情况;CPU使用率和堆内存使用率是否可接受,有没有达到瓶颈等等。通过应用请求分布图查看最近应用访问的整体情况。
历史数据分析:
故障发生后,现场运维人员往往想在最短时间内恢复服务,减少故障带来的损失,事后再来追踪故障发生原因,但这样带来的问题是事后分析信息量不足,无法复现场景,使用历史分析功能正能解决此问题,用户可以查看过去任意时间段的原始指标数据,还原历史场景,从而帮助用户定位出导致故障的原因。
查看比较长的时间范围内的指标数据时,展示的是该指标的平均值,可以看出指标在这段时间内的整体趋势表现。
对比多个实例同一指标的历史数据,能看出一些潜在问题。以TPS为例,在正常情况下,多个集群实例的TPS曲线图应该比较接近,如果某些实例高,某些实例低,负载不均衡,则可能负载算法存在问题。
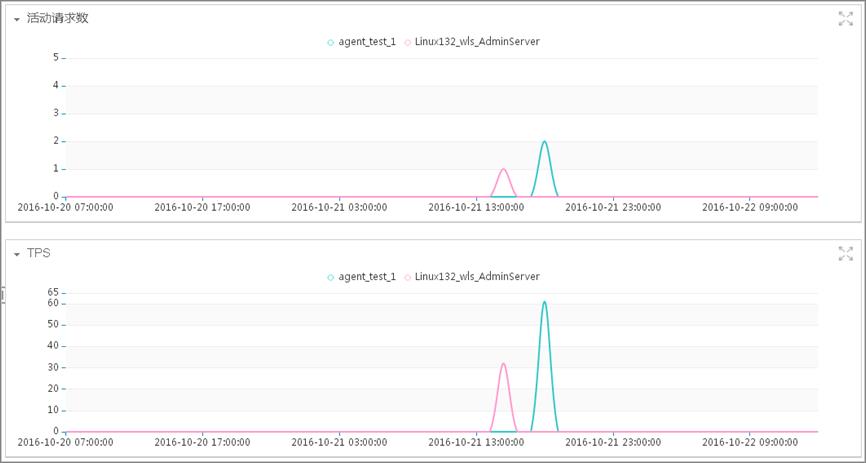
事件一:OOM事件
我行某系统在某次投产之后,webloigcserver频繁异常“死掉”。应用系统启动之后,半小时左右就会触发,并且在触发“死掉”前系统访问速度很慢。由于系统业务模块较多,无法准确定位故障模块,所以使用“鹰眼”系统帮助分析故障原因。
通过系统实时性能监控,可以很清楚地看到系统中存在堆内存异常增高的情况。
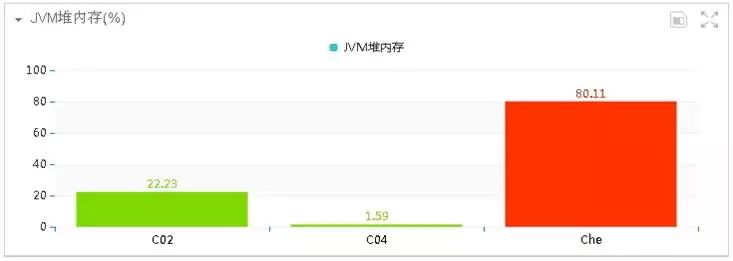
然后到监控 JVM 内存模块查看,堆内存增长曲线图如下:
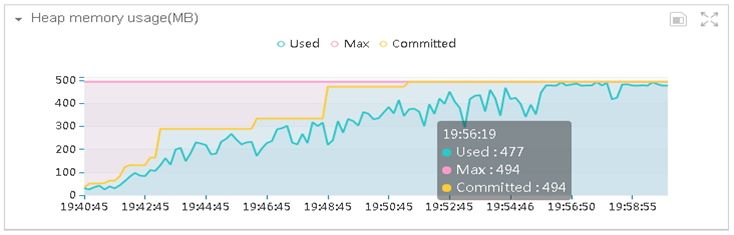
系统的堆内存从不足100M,增加到490M以上,而JVM虚拟机分配的最大堆内存只有494M,并且Full GC后内存没有明显下降,初步怀疑是存在内存泄露的情况。通过内存泄漏监测,如下图所示:
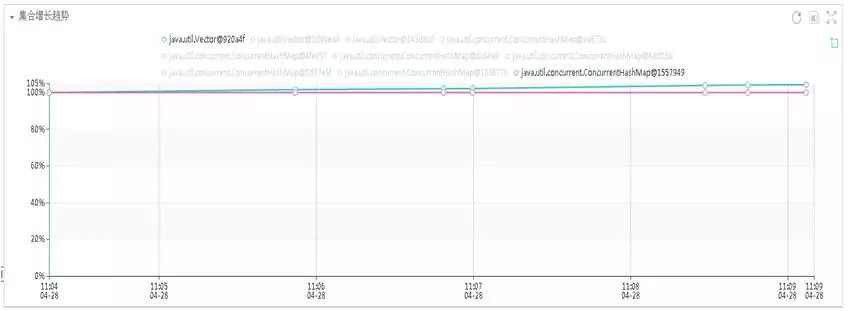
java.util.Vector已经达到450M左右,而且在不断增加,从而导致整个JVM堆内存溢出。根据采集的堆栈信息,如下所示,定位到引起故障的源代码,找到了引起该故障的原因。
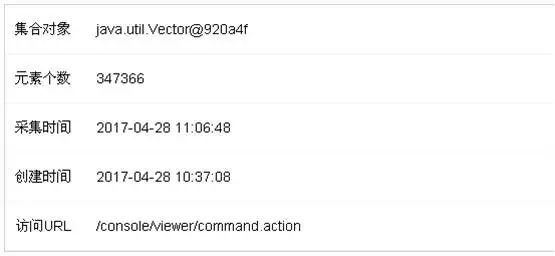

该问题是由于业务模块某源码时处理逻辑不够健壮,导致执行该业务时,不停的向Vector中添加对象,所以只要执行该模块的操作,就会产生内存溢出,从而导致OOM。紧急投产修复bug后,系统问题解决。
事件二:堆内存充裕却频繁FullGC
我行某重要系统一个子模块,频繁触发FULL GC操作,导致整个系统处理能力降低,整体性能严重下降,使用“鹰眼”系统帮助分析故障原因。
通过实时监控-JVM页面,可以很清楚地看到系统运行过程中JVM的运行情况。当系统产生FULL GC时,“鹰眼”记录了FULL的次数和时间。

图1 FULL GC次数图表

图2 FULL GC时间图表
FULL GC引起的原因主要有JVM参数设置原因、应用本身问题、以及应用内部主动调用System.gc()等原因造成。通过观察“鹰眼”系统监控-JVM上的Eden Space、Survivor Space、Tenured Gen图表我们发现,这段时间内Survivor Space、Tenured Gen内存仍旧很充裕,只有Eden Space具有频繁的GC现象。而FULL GC的产生主要与Tenured Gen内存有关。我们初步怀疑是应用系统内部手动调用System.gc()而引起了FULL GC ,Eden Space、Survivor Space、Tenured Gen图表如下所示:
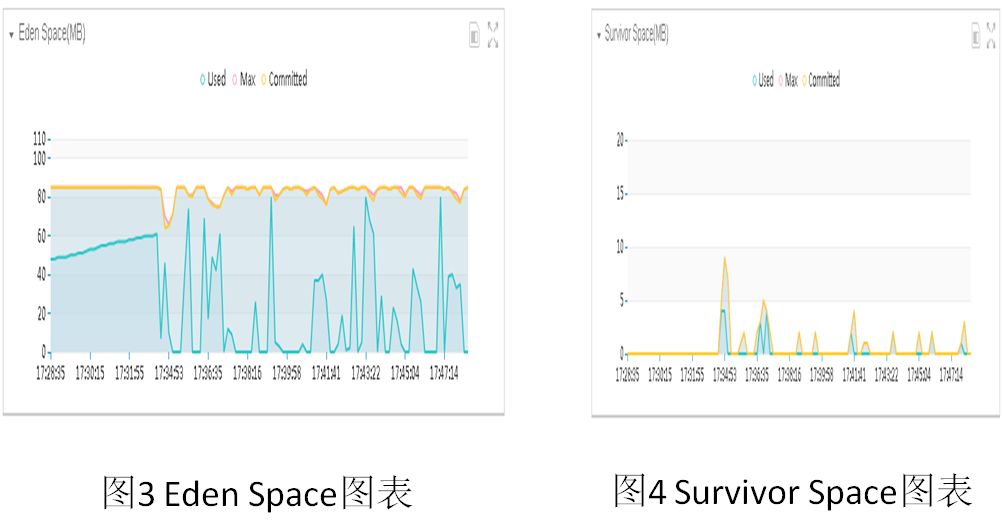
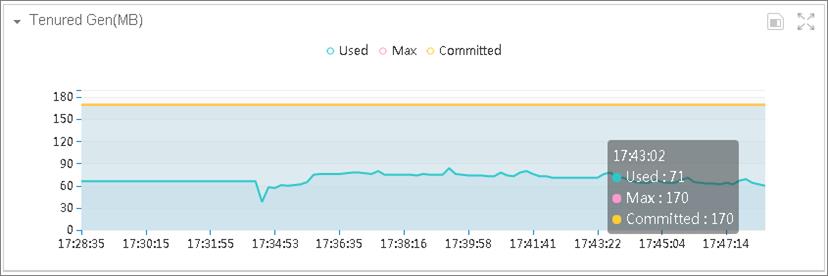
图5 Tenured Gen图表
为了进一步验证,我们在建议JVM的参数中加入参数:-XX:DisableExplicitGC。加入此参数后,FULLGC现象消失。由此,我们确定了是业务系统代码引起的问题。加此参数,可引起应用OOM问题,请谨慎使用。
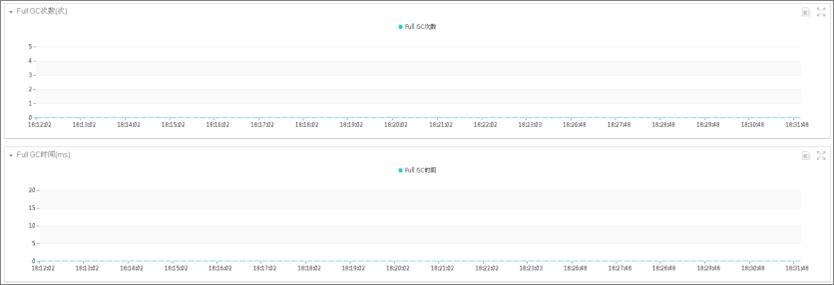
图6 FULL GC图表
由此可见,在系统代码中,最好不要手动进行GC,而让系统主动进行GC操作。
事件三: CPU占用率高
卡中心某系统CPU使用率在业务访问量一般,压力小时也会出现CPU使用率很高的情况。通过“鹰眼”系统实时监控的CPU使用率功能,发现这些在CPU使用率比较高时,有一类业务访问比较频繁,如下图所示:
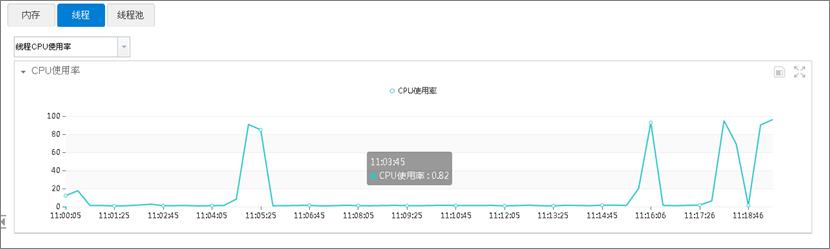
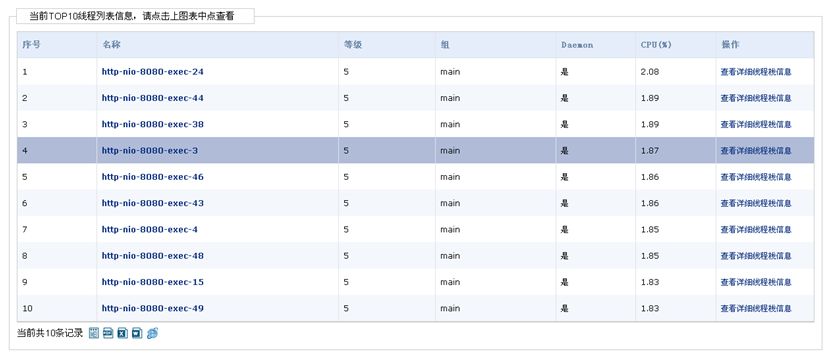
点击“查看详细线程栈信息”,查看线程的调用栈信息,发现占用cpu较高的线程调用栈都是在hashmap的操作上。如图:
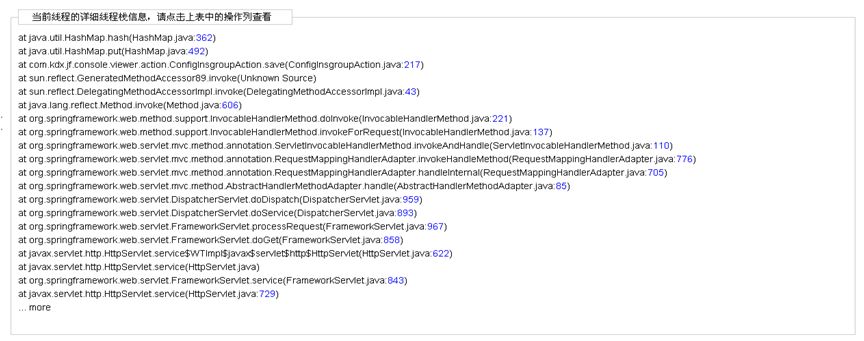
经确认,发现多个线程在对某个Hashmap对象进行并发访问,导致Hashmap的数据结构被破坏,引发死循环,进而大量消耗CPU资源,修复代码逻辑后,问题得以解决。
事件四:大量应用访问失败
某系统出现大量业务访问失败的情况,查看CPU和内存的占用情况均正常。通过监控实时线程状态功能,发现存在很多状态为BLOCKED的线程,于是定位到问题是线程死锁导致业务访问失败,如下图所示:
点击状态为BLOCKED状态的线程名称,查看线程的调用栈信息,发现阻塞状态的线程调用栈都显示在一个地方,这样便定位到出现死锁的业务代码了。经与开发人员确认,发现该代码逻辑在并发访问时会出现死锁,修改代码后问题得以解决。
事件五:数据库大查询响应时间慢
我行某系统发现某功能响应时间慢,同时中间件层面有warning,使用鹰眼系统后,查到问题请求。
使用活动请求列表功能:实时展示正在处理的应用请求,存在处理时间比较久的请求,说明系统存在性能瓶颈点,点击应用URL查看正在处理的请求执行逻辑,辅助定位引起问题的原因。故发现存在大查询:返回结果集调用次数 10721,响应时间2910913(ms)。
中间件管理员利用鹰眼系统反馈问题URL 和问题堆栈、执行SQL,帮组项目组精准定位。联合DBA,分析查看SQL 历史性情况和统计信息收集情况结论:
1. 该SQL执行时间过长,因取值情况不同,导致响应时间和执行计划有变化;
2. 该SQL的执行计划存在全表扫描的情况,影响执行效率;
DBA建议:
1. 考虑SQL拆分,增加临时中间表;
2. 根据SQL的实际功能出发,添加合理的条件,如果可以走索引。
鹰眼系统目前在开发测试及生产环境中间件故障分析诊断方面起到了很大作用,但问题分析还是需要投入较多专业人力,距离真正的中间件运维2.0还有不少距离,下一步我们将着眼于如何智能化分析应用数据,尽力将其打造为一个使用门槛低,功能强大的专家系统,更好的服务于开发、测试、生产各阶段,助力我行科技快速发展。
以上是关于中间件黑科技之鹰眼系统的主要内容,如果未能解决你的问题,请参考以下文章