来自95后的天池中间件大赛总结
Posted 程序猿DD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了来自95后的天池中间件大赛总结相关的知识,希望对你有一定的参考价值。
来源:kirito的技术分享
第一部分:Dubbo Mesh优化
先说结果,最终榜单排名是第 15 名(除去前排大佬的两个小号,加上作弊的第一名,勉强能算是第 12 名),说实话是挺满意的成绩。这篇文章主要是分享给以下读者:比赛中使用了 netty 却没有达到理想 qps 的朋友,netty 刚入门的朋友,对 dubbo mesh 感兴趣的朋友。
在比赛之前我个人对 netty 的认识也仅仅停留在了解的层面,在之前解读 RPC 原理的系列文章中涉及到 netty 传输时曾了解过一二,基本可以算零基础使用 netty 参赛,所以我会更多地站在一个小白的视角来阐述自己的优化历程,一步步地提高 qps,也不会绕开那些自己踩过的坑以及负优化。另一方面,由于自己对 netty 的理解并不是很深,所以文中如果出现错误,敬请谅解,欢迎指正。
Dubbo Mesh 是什么?
为了照顾那些不太了解这次比赛内容的读者,我先花少量的篇幅介绍下这次阿里举办的天池中间件大赛到底比的是个什么东西,那就不得不先介绍下 Dubbo Mesh 这个概念。
如果你用过 dubbo,并且对 service mesh 有所了解,那么一定可以秒懂 Dubbo Mesh 是为了解决什么问题。说白了,dubbo 原先是为了 java 语言而准备的,没有考虑到跨语言的问题,这意味着 nodejs,python,go 要想无缝使用 dubbo 服务,要么借助于各自语言的 dubbo 客户端,例如:node-dubbo-client,python-dubbo-client,go-dubbo-client;要么就是借助于 service mesh 的解决方案,让 dubbo 自己提供跨语言的解决方案,来屏蔽不同语言的处理细节,于是乎,dubbo 生态的跨语言 service mesh 解决方案就被命名为了 dubbo mesh。
一图胜千言:
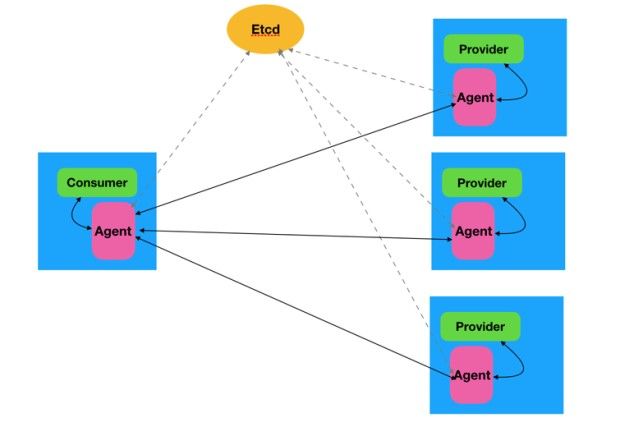
在原先的 dubbo 生态下,只有 consumer,provider,注册中心的概念。dubbo mesh 生态下为每个服务(每个 consumer,provider 实例)启动一个 agent,服务间不再进行直接的通信,而是经由各自的 agent 完成交互,并且服务的注册发现也由 agent 完成。图中红色的 agent 便是这次比赛的核心,选手们可以选择合适的语言来实现 agent,最终比拼高并发下各自 agent 实现的 qps,qps 即最终排名的依据。
赛题剖析
这次比赛的主要考察点在于高并发下网络通信模型的实现,可以涵盖以下几个关键点:reactor 模型,负载均衡,线程,锁,io 通信,阻塞与非阻塞,零拷贝,序列化,http/tcp/udp与自定义协议,批处理,垃圾回收,服务注册发现等。它们对最终程序的 qps 起着或大或小的影响,对它们的理解越深,越能够编写出高性能的 dubbo mesh 方案。
语言的选择,初赛结束后的感受,大家主要还是在 java,c++,go 中进行了抉择。语言的选择考虑到了诸多的因素,通用性,轻量级,性能,代码量和qps的性价比,选手的习惯等等。虽然前几名貌似都是 c++,但总体来说,排名 top 10 之外,绝不会是因为语言特性在从中阻挠。c++ 选手高性能的背后,可能是牺牲了 600 多行代码在自己维护一个 etcd-lib(比赛限制使用 etcd,但据使用 c++ 的选手说,c++ 没有提供 etcd 的 lib);且这次比赛提供了预热环节,java 党也露出了欣慰的笑容。
java 的主流框架还是在 nio,akka,netty 之间的抉择,netty 应该是众多 java 选手中较为青睐的,博主也选择了 netty 作为 dubbo mesh 的实现;go 的协程和网络库也是两把利器,并不比 java 弱,加上其进程轻量级的特性,也作为了一个选择。
官方提供了一个 qps 并不是很高的 demo,来方便选手们理解题意,可以说是非常贴心了,来回顾一下最简易的 dubbo mesh 实现:
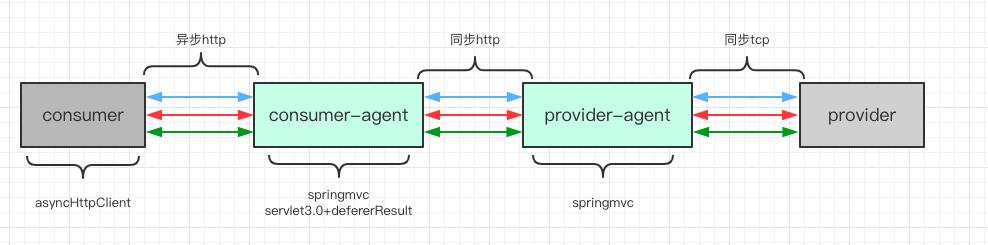
如上图所示,是整个初始 dubbo mesh 的架构图,其中 consumer 和 provider 以灰色表示,因为选手是不能修改其实现的,绿色部分的 agent 是可以由选手们自由发挥的部分。比赛中 consumer,consumer-agent 为 单个实例,provider、provider-agent 分别启动了三个性能不一的实例:small,medium,large,这点我没有在图中表示出来,大家自行脑补。
所以所有选手都需要完成以下几件事:
consumer-agent 需要启动一个 http 服务器,接收来自 consumer 的 http 请求
consumer-agent 需要转发该 http 请求给 provider-agent,并且由于 provider-agent 有多个实例,所以需要做负载均衡。consumer-agent 与 provider-agent 之间如何通信可以自由发挥。
provider-agent 拿到 consumer-agent 的请求之后,需要组装成 dubbo 协议, 使用 tcp 与 provider 完成通信。
这样一个跨语言的简易 dubbo mesh 便呈现在大家面前了,从 consumer 发出的 http 协议,最终成功调用到了使用 java 语言编写的 dubbo 服务。这中间如何优化,如何使用各种黑科技成就了一场非常有趣的比赛。博主所有的优化都不是一蹴而就的,都是一天天的提交试出来的,所以恰好可以使用时间线顺序叙述自己的改造历程。
优化历程
Qps 1000 到 2500 (CA 与 PA 使用异步 http 通信)
官方提供的 demo 直接跑通了整个通信流程,省去了我们大量的时间,初始版本评测可以达到 1000+ 的 qps,所以 1000 可以作为 baseline 给大家提供参考。demo 中 consumer 使用 asyncHttpClient 发送异步的 http 请求, consumer-agent 使用了 springmvc 支持的 servlet3.0 特性;而 consumer-agent 到 provider-agent 之间的通信却使用了同步 http,所以 C 到 CA 这一环节相比 CA 到 PA 这一环节性能是要强很多的。改造起来也很简单,参照 C 到 CA 的设计,直接将 CA 到 PA 也替换成异步 http,qps 可以直接到达 2500。
主要得益于 async-http-client 提供的异步 http-client,以及 servlet3.0 提供的非阻塞 api。
<dependency>
<groupId>org.asynchttpclient</groupId>
<artifactId>async-http-client</artifactId>
<version>2.4.7</version>
</dependency>
// 非阻塞发送 http 请求
ListenableFuture<org.asynchttpclient.Response> responseFuture = asyncHttpClient.executeRequest(request);
// 非阻塞返回 http 响应
@RequestMapping(value = "/invoke")
public DeferredResult<ResponseEntity> invoke(){}
Qps 2500 到 2800 (负载均衡优化为加权轮询)
demo 中提供的负载均衡算法是随机算法,在 small-pa,medium-pa,large-pa 中随机选择一个访问,每个服务的性能不一样,响应时间自然也不同,随机负载均衡算法存在严重的不稳定性,无法按需分配请求,所以成了自然而然的第二个改造点。
large:
-Dlb.weight=3
medium:
-Dlb.weight=2
small:
-Dlb.weight=1
预热赛时最高并发为 256 连接,这样的比例可以充分发挥每个 pa 的性能。
Qps 2800 到 3500 (future->callback)
c 到 ca 以及 ca 到 pa 此时尽管是 http 通信,但已经实现了非阻塞的特性(请求不会阻塞 io 线程),但 dubbo mesh 的 demo 中 pa 到 p 的这一通信环节还是使用的 future.get + countDownLatch 的阻塞方式,一旦整个环节出现了锁和阻塞,qps 必然上不去。
关于几种获取结果的方式,也是老生常谈的话题:
future 方式在调用过程中不会阻塞线程,但获取结果是会阻塞线程,provider 固定 sleep 了 50 ms,所以获取 future 结果依旧是一个耗时的过程,加上这种模型一般会使用锁来等待,性能会造成明显的下降。替换成 callback 的好处是,io 线程专注于 io 事件,降低了线程数,这和 netty 的 io 模型也是非常契合的。
Promise<Integer> agentResponsePromise = new DefaultPromise<>(ctx.executor());
agentResponsePromise.addListener();
netty 为此提供了默认的 Promise 的抽象,以及 DefaultPromise 的默认实现,我们可以 out-of-box 的使用 callback 特性。在 netty 的入站 handler 的 channelRead 事件中创建 promise,拿到 requestId,建立 requestId 和 promise 的映射;在出站 handler 的channelRead 事件中拿到返回的 requestId,查到 promise,调用 done 方法,便完成了非阻塞的请求响应。可参考: 入站 handler ConsumerAgentHttpServerHandler 和 和出站 handlerConsumerAgentClientHandler 的实现。
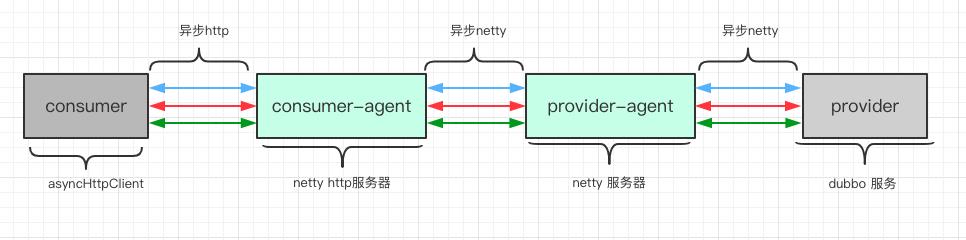
Qps 3500 到 4200 (http通信替换为tcp通信)
ca 到 pa 的通信原本是异步 http 的通信方式,完全可以参考 pa 到 p 的异步 tcp 通信进行改造。自定义 agent 之间的通信协议也非常容易,考虑到 tcp 粘包的问题,使用定长头+字节数组来作为自定义协议是一个较为常用的做法。这里踩过一个坑,原本想使用 protoBuffer 来作为自定义协议,netty 也很友好的提供了基于 protoBuffer 协议的编解码器,只需要编写好 DubboMeshProto.proto 文件即可:
message AgentRequest {
int64 requestId = 1;
string interfaceName = 2;
string method = 3;
string parameterTypesString = 4;
string parameter = 5;
}
message AgentResponse {
int64 requestId = 1;
bytes hash = 2;
}
protoBuffer 在实际使用中的优势是毋庸置疑的,其可以尽可能的压缩字节,减少 io 码流。在正式赛之前一直用的好好的,但后来的 512 并发下通过 jprofile 发现,DubboMeshProto 的 getSerializedSize ,getDescriptorForType 等方法存在不必要的耗时,对于这次比赛中如此简单的数据结构而言 protoBuffer 并不是那么优秀。最终还是采取了定长头+字节数组的自定义协议。
参考: com.alibaba.dubbo.performance.demo.agent.protocol.simple.SimpleDecoder
http 通信既然换了,干脆一换到底,ca 的 springmvc 服务器也可以使用 netty 实现,这样更加有利于实现 ca 整体的 reactive。使用 netty 实现 http 服务器很简单,使用 netty 提供的默认编码解码器即可。
public class ConsumerAgentHttpServerInitializer extends ChannelInitializer<SocketChannel> {
@Override
public void initChannel(SocketChannel ch) {
ChannelPipeline p = ch.pipeline();
p.addLast("encoder", new HttpResponseEncoder());
p.addLast("decoder", new HttpRequestDecoder());
p.addLast("aggregator", new HttpObjectAggregator(10 * 1024 * 1024));
p.addLast(new ConsumerAgentHttpServerHandler());
}
}
http 服务器的实现也踩了一个坑,解码 http request 请求时没注意好 ByteBuf 的释放,导致 qps 跌倒了 2000+,反而不如 springmvc 的实现。在队友@闪电侠的帮助下成功定位到了内存泄露的问题。
public static Map<String, String> parse(FullHttpRequest req) {
Map<String, String> params = new HashMap<>();
// 是POST请求
HttpPostRequestDecoder decoder = new HttpPostRequestDecoder(new DefaultHttpDataFactory(false), req);
List<InterfaceHttpData> postList = decoder.getBodyHttpDatas();
for (InterfaceHttpData data : postList) {
if (data.getHttpDataType() == InterfaceHttpData.HttpDataType.Attribute) {
MemoryAttribute attribute = (MemoryAttribute) data;
params.put(attribute.getName(), attribute.getValue());
}
}
// resolve memory leak
decoder.destroy();
return params;
}
在正式赛后发现还有更快的 decode 方式,不需要借助于上述的 HttpPostRequestDecoder,而是改用 QueryStringDecoder:
public static Map<String, String> fastParse(FullHttpRequest httpRequest) {
String content = httpRequest.content().toString(StandardCharsets.UTF_8);
QueryStringDecoder qs = new QueryStringDecoder(content, StandardCharsets.UTF_8, false);
Map<String, List<String>> parameters = qs.parameters();
String interfaceName = parameters.get("interface").get(0);
String method = parameters.get("method").get(0);
String parameterTypesString = parameters.get("parameterTypesString").get(0);
String parameter = parameters.get("parameter").get(0);
Map<String, String> params = new HashMap<>();
params.put("interface", interfaceName);
params.put("method", method);
params.put("parameterTypesString", parameterTypesString);
params.put("parameter", parameter);
return params;
}
节省篇幅,直接在这儿将之后的优化贴出来,后续不再对这个优化赘述了。
Qps 4200 到 4400 (netty复用eventLoop)
这个优化点来自于比赛认识的一位好友@半杯水,由于没有使用过 netty,比赛期间恶补了一下 netty 的线程模型,得知了 netty 可以从客户端引导 channel,从而复用 eventLoop。不了解 netty 的朋友可以把 eventLoop 理解为 io 线程,如果入站的 io 线程和 出站的 io 线程使用相同的线程,可以减少不必要的上下文切换,这一点在 256 并发下可能还不明显,只有 200 多 qps 的差距,但在 512 下尤为明显。复用 eventLoop 在《netty实战》中是一个专门的章节,篇幅虽然不多,但非常清晰地向读者阐释了如何复用 eventLoop(注意复用同时存在于 ca 和 pa 中)。
// 入站服务端的 eventLoopGroup
private EventLoopGroup workerGroup;
// 为出站客户端预先创建好的 channel
private void initThreadBoundClient(EventLoopGroup workerGroup) {
for (EventExecutor eventExecutor : eventLoopGroup) {
if (eventExecutor instanceof EventLoop) {
ConsumerAgentClient consumerAgentClient = new ConsumerAgentClient((EventLoop) eventExecutor);
consumerAgentClient.init();
ConsumerAgentClient.put(eventExecutor, consumerAgentClient);
}
}
}
使用入站服务端的 eventLoopGroup 为出站客户端预先创建好 channel,这样可以达到复用 eventLoop 的目的。并且此时还有一个伴随的优化点,就是将存储 Map
到了这一步,整体架构已经清晰了,c->ca,ca->pa,pa->p 都实现了异步非阻塞的 reactor 模型,qps 在 256 并发下,也达到了 4400 qps。
正式赛 512 连接带来的新格局
上述这份代码在预热赛 256 并发下表现尚可,但正式赛为了体现出大家的差距,将最高并发数直接提升了一倍,但 qps 却并没有得到很好的提升,卡在了 5400 qps。和 256 连接下同样 4400 的朋友交流过后,发现我们之间的差距主要体现在 ca 和 pa 的 io 线程数,以及 pa 到 p 的连接数上。5400 qps 显然低于我的预期,为了降低连接数,我修改了原来 provider-agent 的设计。从以下优化开始,是正式赛 512 连接下的优化,预热赛只有 256 连接。
Qps 5400 到 5800 (降低连接数)
对 netty 中 channel 的优化搜了很多文章,依旧不是很确定连接数到底是不是影响我代码的关键因素,在和小伙伴沟通之后实在找不到 qps 卡在 5400 的原因,于是乎抱着试试的心态修改了下 provider-agent 的设计,采用了和 consumer-agent 一样的设计,预先拿到 provder-agent 入站服务器的 woker 线程组,创建出站请求的 channel,将原来的 4 个线程,4 个 channel 降低到了 1 个线程,一个 channel。其他方面未做任何改动,qps 顺利达到了 5800。
理论上来说,channel 数应该不至于成为性能的瓶颈,可能和 provider dubbo 的线程池策略有关,最终得出的经验就是:在 server 中合理的在 io 事件处理能力的承受范围内,使用尽可能少的连接数和线程数,可以提升 qps,减少不必要的线程切换。顺带一提(此时 ca 的线程数为 4,入站连接为 http 连接,最高为 512 连接,出站连接由于和线程绑定,又需要做负载均衡,所以为 $$ 线程数pa数=43=12 $$ 这个阶段,还存在另一个问题,由于 provider 线程数固定为 200 个线程,如果 large-pa 继续分配 3/1+2+3=0.5 即 50% 的请求,很容易出现 provider 线程池饱满的异常,所以调整了加权值为 1:2:2。限制加权负载均衡的不再仅仅是机器性能,还要考虑到 provider 的连接处理能力。
Qps 5800 到 6100 (Epoll替换Nio)
依旧感谢@半杯水的提醒,由于评测环境使用了 linux 作为评测环境,所以可以使用 netty 自己封装的 EpollSocketChannel 来代替 NiosocketChannel,这个提升远超我的想象,直接帮助我突破了 6000 的关卡。
private EventLoopGroup bossGroup = Epoll.isAvailable() ? new EpollEventLoopGroup(1) : new NioEventLoopGroup(1);
private EventLoopGroup workerGroup = Epoll.isAvailable() ? new EpollEventLoopGroup(2) : new NioEventLoopGroup(2);
bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(Epoll.isAvailable() ? EpollServerSocketChannel.class : NioServerSocketChannel.class)
本地调试由于我是 mac 环境,没法使用 Epoll,所以加了如上的判断。
NioServerSocketChannel 使用了 jdk 的 nio,其会根据操作系统选择使用不同的 io 模型,在 linux 下同样是 epoll,但默认是 level-triggered ,而 netty 自己封装的 EpollSocketChannel 默认是 edge-triggered。 我原先以为是 et 和 lt 的差距导致了 qps 如此大的悬殊,但后续优化 Epoll 参数时发现 EpollSocketChannel 也可以配置为 level-triggered,qps 并没有下降,在比赛的特殊条件下,个人猜想并不是这两种触发方式带来的差距,而仅仅是 netty 自己封装 epoll 带来的优化。
//默认
bootstrap.option(EpollChannelOption.EPOLL_MODE, EpollMode.EDGE_TRIGGERED);
//可修改触发方式
bootstrap.option(EpollChannelOption.EPOLL_MODE, EpollMode.LEVEL_TRIGGERED);
Qps 6100 到 6300 (agent自定义协议优化)
agent 之间的自定义协议我之前已经介绍过了,由于一开始我使用了 protoBuf,发现了性能问题,就是在这儿发现的。在 512 下 protoBuf 的问题尤为明显,最终为了保险起见,以及为了和我后面的一个优化兼容,最终替换为了自定义协议—Simple 协议,这一点优化之前提到了,不在过多介绍。
Qps 6300 到 6500 (参数调优与zero-copy)
这一段优化来自于和 @折袖-许华建 的交流,非常感谢。又是一个对 netty 不太了解而没注意的优化点:
关闭 netty 的内存泄露检测:
-Dio.netty.leakDetectionLevel=disabled
netty 会在运行期定期抽取 1% 的 ByteBuf 进行内存泄露的检测,关闭这个参数后,可以获得性能的提升。
开启 quick_ack:
bootstrap.option(EpollChannelOption.TCP_QUICKACK, java.lang.Boolean.TRUE)
tcp 相比 udp ,一个区别便是为了可靠传输而进行的 ack,netty 为 Epoll 提供了这个参数,可以进行 quick ack,具体原理没来及研究。
开启 TCP_NODELAY
serverBootstrap.childOption(ChannelOption.TCP_NODELAY, true)
这个优化可能大多数人都知道,放在这儿一起罗列出来。网上搜到了一篇阿里毕玄的 rpc 优化文章,提到高并发下 ChannelOption.TCP_NODELAY=false 可能更好,但实测之后发现并不会。
其他调优的参数可能都是玄学了,对最终的 qps 影响微乎其微。参数调优并不能体现太多的技巧,但对结果产生的影响却是很可观的。
在这个阶段还同时进行了一个优化,和参数调优一起进行的,所以不知道哪个影响更大一些。demo 中 dubbo 协议编码没有做到 zero-copy,这无形中增加了一份数据从内核态到用户态的拷贝;自定义协议之间同样存在这个问题,在 dubbo mesh 的实践过程中应该尽可能做到:能用 ByteBuf 的地方就不要用其他对象,ByteBuf 提供的 slice 和 CompositeByteBuf 都可以很方便的实现 zero-copy。
Qps 6500 到 6600 (自定义http协议编解码)
看着榜单上的人 qps 逐渐上升,而自己依旧停留在 6500,于是乎动了歪心思,GTMD 的通用性,自己解析 http 协议得了,不要 netty 提供的 http 编解码器,不需要比 HttpPostRequestDecoder 更快的 QueryStringDecoder,就一个偏向于固定的 http 请求,实现自定义解析非常简单。
POST / HTTP/1.1
content-length: 560
content-type: application/x-www-form-urlencoded
host: 127.0.0.1:20000
interface=com.alibaba.dubbo.performance.demo.provider.IHelloService&method=hash¶meterTypesString=Ljava%32lang%32String;¶meter=xxxxx
http 文本协议本身还是稍微有点复杂的,所以 netty 的实现考虑到通用性,必然不如我们自己解析来得快,具体的粘包过程就不叙述了,有点 hack 的倾向。
同理,response 也自己解析:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Type: text/plain;charset=UTF-8
Content-Length: 6
123456
Qps 6600 到 6700 (去除对象)
继续丧心病狂,不考虑通用性,把之前所有的中间对象都省略,encode 和 decode 尽一切可能压缩到 handler 中去处理,这样的代码看起来非常难受,存在不少地方的 hardcoding。但效果是存在的,ygc 的次数降低了不少,全程使用 ByteBuf 和 byte[] 来进行数据交互。这个优化点同样存在存在 hack 倾向,不过多赘述。
Qps 6700 到 6850 (批量flush,批量decode)
事实上到了 6700 有时候还是需要看运气的,从群里的吐槽现象就可以发现,512 下的网路 io 非常抖,不清楚是机器的问题还是高并发下的固有现象,6700的代码都能抖到 5000 分。所以 6700 升 6850 的过程比较曲折,而且很不稳定,提交 20 次一共就上过两次 6800+。
所做的优化是来自队友@闪电侠的批量flush类,一次传输的字节数可以提升,使得网络 io 次数可以降低,原理可以简单理解为:netty 中 write 10 次,flush 1 次。一共实现了两个版本的批量 flush。一个版本是根据同一个 channel write 的次数积累,最终触发 flush;另一个版本是根据一次 eventLoop 结束才强制flush。经过很多测试,由于环境抖动太厉害,这两者没测出多少差距。
handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
ch.pipeline()
.addLast(new SimpleDecoder())
.addLast(new BatchFlushHandler(false))
.addLast(new ConsumerAgentClientHandler());
}
});
批量 decode 的思想来自于蚂蚁金服的 rpc 框架 sofa-bolt 中提供的一个抽象类:AbstractBatchDecoder
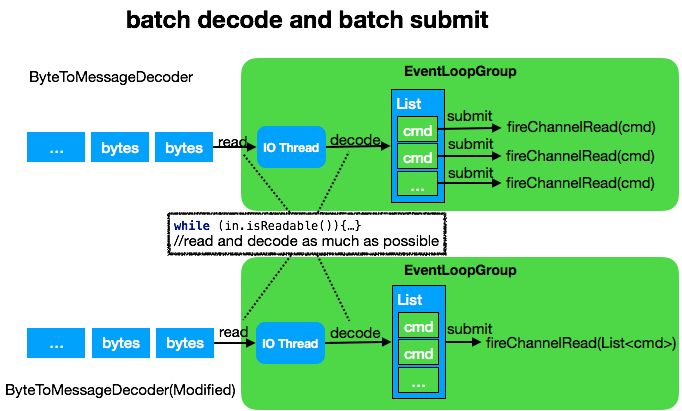
Netty 提供了一个方便的解码工具类 ByteToMessageDecoder ,如图上半部分所示,这个类具备 accumulate 批量解包能力,可以尽可能的从 socket 里读取字节,然后同步调用 decode 方法,解码出业务对象,并组成一个 List 。
最后再循环遍历该 List ,依次提交到 ChannelPipeline 进行处理。此处我们做了一个细小的改动,如图下半部分所示,即将提交的内容从单个 command ,改为整个 List 一起提交,如此能减少 pipeline 的执行次数,同时提升吞吐量。这个模式在低并发场景,并没有什么优势,而在高并发场景下对提升吞吐量有不小的性能提升。
值得指出的一点:这个对于 dubbo mesh 复用 eventLoop 的特殊场景下的优化效果其实是存疑的,但我的最好成绩的确是使用了 AbstractBatchDecoder 之后跑出来的。我曾经单独将 ByteToMessageDecoder 和 AbstractBatchDecoder 拉出跑了一次分,的确是后者 qps 更高。
总结
其实在 qps 6500 时,整体代码还是挺漂亮的,至少感觉能拿的出手给别人看。但最后为了性能,加上时间比较赶,不少地方都进行了 HardCoding,而实际能投入生产使用的代码必然要求通用性和扩展性,赛后有空会整理出两个分支:一个 highest-qps 追求性能,另一个分支保留下通用性。这次比赛从一个 netty 小白,最终学到了不少的知识点,还是收获很大的,最后感谢一下比赛中给过我指导的各位老哥。
最高 qps 分支:highest-qps
考虑通用性的分支(适合 netty 入门):master
https://code.aliyun.com/250577914/agent-demo.git
第二部分:百万队列存储设计
维持了 20 天的复赛终于告一段落了,国际惯例先说结果,复赛结果不太理想,一度从第 10 名掉到了最后的第 36 名,主要是写入的优化卡了 5 天,一直没有进展,最终排名也是定格在了排行榜的第二页。痛定思痛,这篇文章将自己复赛中学习的知识,成功的优化,未成功的优化都罗列一下。
赛题介绍
题面描述很简单:使用 Java 或者 C++ 实现一个进程内的队列引擎,单机可支持 100 万队列以上。
public abstract class QueueStore {
abstract void put(String queueName, byte[] message);
abstract Collection<byte[]> get(String queueName, long offset, long num);
}
编写如上接口的实现。
put 方法将一条消息写入一个队列,这个接口需要是线程安全的,评测程序会并发调用该接口进行 put,每个queue 中的内容按发送顺序存储消息(可以理解为 Java 中的 List),同时每个消息会有一个索引,索引从 0 开始,不同 queue 中的内容,相互独立,互不影响,queueName 代表队列的名称,message 代表消息的内容,评测时内容会随机产生,大部分长度在 58 字节左右,会有少量消息在 1k 左右。
get 方法从一个队列中读出一批消息,读出的消息要按照发送顺序来,这个接口需要是线程安全的,也即评测程序会并发调用该接口进行 get,返回的 Collection 会被并发读,但不涉及写,因此只需要是线程读安全就可以了,queueName 代表队列的名字,offset 代表消息的在这个队列中的起始索引,num 代表读取的消息的条数,如果消息足够,则返回 num 条,否则只返回已有的消息即可,若消息不足,则返回一个空的集合。
评测程序介绍
发送阶段:消息大小在 58 字节左右,消息条数在 20 亿条左右,即发送总数据在 100G 左右,总队列数 100w
索引校验阶段:会对所有队列的索引进行随机校验;平均每个队列会校验1~2次;(随机消费)
顺序消费阶段:挑选 20% 的队列进行全部读取和校验; (顺序消费)
发送阶段最大耗时不能超过 1800s;索引校验阶段和顺序消费阶段加在一起,最大耗时也不能超过 1800s;超时会被判断为评测失败。
各个阶段线程数在 20~30 左右
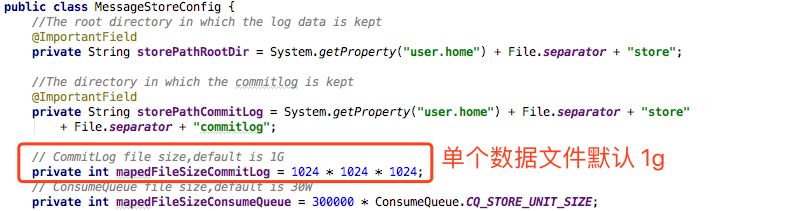
测试环境为 4c8g 的 ECS,限定使用的最大 JVM 大小为 4GB(-Xmx 4g)。带一块 300G 左右大小的 SSD 磁盘。对于 Java 选手而言,可使用的内存可以理解为:堆外 4g 堆内 4g。
赛题剖析
首先解析题面,接口描述是非常简单的,只有一个 put 和一个 get 方法。需要注意特别注意下评测程序,发送阶段需要对 100w 队列,每一次发送的量只有 58 字节,最后总数据量是 100g;索引校验和顺序消费阶段都是调用的 get 接口,不同之处在于前者索引校验是随机消费,后者是对 20% 的队列从 0 号索引开始进行全量的顺序消费,评测程序的特性对最终存储设计的影响是至关重要的。
复赛题目的难点之一在于单机百万队列的设计,据查阅的资料显示
Kafka 单机超过 64 个队列/分区,Kafka 分区数不宜过多
RocketMQ 单机支持最高 5 万个队列
至于百万队列的使用场景,只能想到 IOT 场景有这样的需求。相较于初赛,复赛的设计更加地具有不确定性,排名靠前的选手可能会选择大相径庭的设计方案。
复赛的考察点主要有以下几个方面:磁盘块读写,读写缓冲,顺序读写与随机读写,pageCache,稀疏索引,队列存储设计等。
由于复赛成绩并不是很理想,优化 put 接口的失败是导致失利的罪魁祸首,最终成绩是 126w TPS,而第一梯队的 TPS 则是到达了 200 w+ 的 TPS。鉴于此,不太想像初赛总结那样,按照优化历程罗列,而是将自己做的方案预研,以及设计思路分享给大家,对文件 IO 不甚了解的读者也可以将此文当做一篇科普向的文章来阅读。
思路详解
确定文件读写方式
作为忠实的 Java 粉丝,自然选择使用 Java 来作为参赛语言,虽然最终的排名是被 Cpp 大佬所垄断,但着实无奈,毕业后就把 Cpp 丢到一边去了。Java 中的文件读写接口大致可以分为三类:
标准 IO 读写,位于 java.io 包下,相关类:FileInputStream,FileOuputStream
NIO 读写,位于 java.nio 包下,相关类:FileChannel,ByteBuffer
Mmap 内存映射,位于 java.nio 包下,相关类:FileChannel,MappedByteBuffer
标准 IO 读写不具备调研价值,直接 pass,所以 NIO 和 Mmap 的抉择,成了第一步调研对象。
第一阶段调研了 Mmap。
public void test1() throws Exception {
String dir = "/Users/kirito/data/";
ensureDirOK(dir);
RandomAccessFile memoryMappedFile;
int size = 1 * 1024 * 1024;
try {
memoryMappedFile = new RandomAccessFile(dir + "testMmap.txt", "rw");
MappedByteBuffer mappedByteBuffer = memoryMappedFile.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, size);
for (int i = 0; i < 100000; i++) {
mappedByteBuffer.position(i * 4);
mappedByteBuffer.putInt(i);
}
memoryMappedFile.close();
} catch (Exception e) {
e.printStackTrace();
}
}
如上的代码呈现了一个最简单的 Mmap 使用方式,速度也是没话说,一个字:快!我怀着将信将疑的态度去找了更多的佐证,优秀的源码总是第一参考对象,观察下 RocketMQ 的设计,可以发现 NIO 和 Mmap 都出现在了源码中,但更多的读写操作似乎更加青睐 Mmap。RocketMQ 源码 org.apache.rocketmq.store.MappedFile 中两种写方法同时存在,请教 @匠心零度 后大概得出结论:RocketMQ 主要的写是通过 Mmap 来完成。
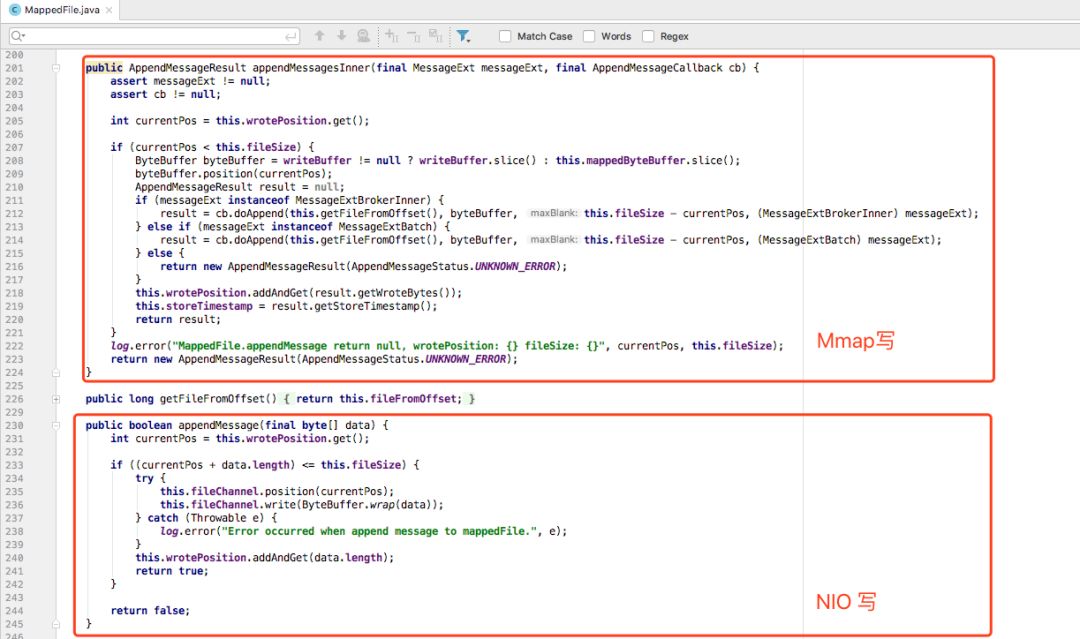
但是在实际使用 Mmap 来作为写方案时遇到了两大难题,单纯从使用角度来看,暴露出了 Mmap 的局限性:
Mmap 在 Java 中一次只能映射 1.5~2G 的文件内存,但实际上我们的数据文件大于 100g,这带来了第一个问题:要么需要对文件做物理拆分,切分成多文件;要么需要对文件映射做逻辑拆分,大文件分段映射。
RocketMQ 中限制了单文件大小来避免这个问题。
Mmap 之所以快,是因为借助了内存来加速,mappedByteBuffer 的 put 行为实际是对内存进行的操作,实际的刷盘行为依赖于操作系统的定时刷盘或者手动调用 mappedByteBuffer.force() 接口来刷盘,否则将会导致机器卡死(实测后的结论)。
由于复赛的环境下内存十分有限,所以使用 Mmap 存在较难的控制问题。
经过这么一折腾,再加上资料的搜集,最终确定,Mmap 在内存较为富足并且数据量小的场景下存在优势(大多数文章的结论认为 Mmap 适合大文件的读写,私以为是不严谨的结论)。
第二阶段调研 Nio 的 FileChannel,这也是我最终确定的读写方案。
由于每个消息只有 58 字节左右,直接通过 FileChannel 写入一定会遇到瓶颈,事实上,如果你这么做,复赛连成绩估计都跑不出来。另一个说法是 ssd 最小的写入单位是 4k,如果一次写入低于 4k,实际上耗时和 4k 一样。这里涉及到了赛题的一个重要考点:块读写。
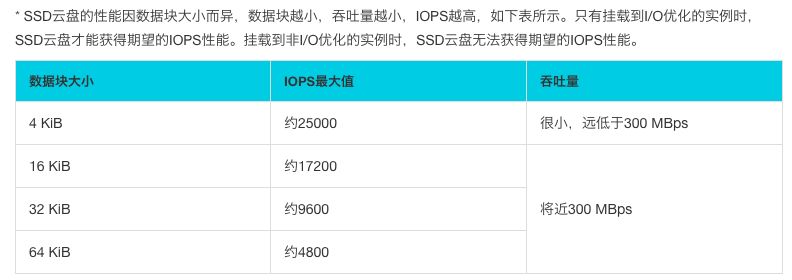
根据阿里云的 ssd 云盘介绍,只有一次写入 16kb ~ 64kb 才能获得理想的 IOPS。文件系统块存储的特性,启发我们需要设置一个内存的写入缓冲区,单个消息写入内存缓冲区,缓冲区满,使用 FileChannel 进行刷盘。经过实践,使用 FileChannel 搭配缓冲区发挥的写入性能和内存充足情况下的 Mmap 并无区别,并且 FileChannel 对文件大小并无限制,控制也相对简单,所以最终确定使用 FileChannel 进行读写。
确定存储结构和索引结构
由于赛题的背景是消息队列,评测 2 阶段的随机检测以及 3 阶段的顺序消费一次会读取多条连续的消息,并且 3 阶段的顺序消费是从队列的 0 号索引一直消费到最后一条消息,这些因素都启发我们:应当将同一个队列的消息尽可能的存到一起。前面一节提到了写缓冲区,便和这里的设计非常契合,例如我们可以一个队列设置一个写缓冲区(比赛中 Java 拥有 4g 的堆外内存,100w 队列,一个队列使用 DirectByteBuffer 分配 4k 堆外内存 ,可以保证缓冲区不会爆内存),这样同一个缓冲区的消息一起落盘,就保证了块内消息的顺序性,即做到了”同一个队列的消息尽可能的存到一起“。
按块存取消息目前看来有两个优势:
按条读取消息=>按块读取消息,发挥块读的优势,减少了 IO 次数
全量索引=>稀疏索引。块内数据是连续的,所以只需要记录块的物理文件偏移量+块内消息数即可计算出某一条消息的物理位置。这样大大降低了索引的数量,稍微计算一下可以发现,完全可以使用一个 Map 数据结构,Key 为 queueName,Value 为 List
在内存维护队列块的索引。如果按照传统的设计方案:一个 queue 一个索引文件,百万文件必然会超过默认的系统文件句柄上限。索引存储在内存中既规避了文件句柄数的问题,速度也不必多数,文件 IO 和 内存 IO 不是一个量级。
由于赛题规定消息体是非定长的,大多数消息 58 字节,少量消息 1k 字节的数据特性,所以存储消息体时使用 short+byte[] 的结构即可,short 记录消息的实际长度,byte[] 记录完整的消息体。short 比 int 少了 2 个字节,2*20亿消息,可以减少 4g 的数据量。
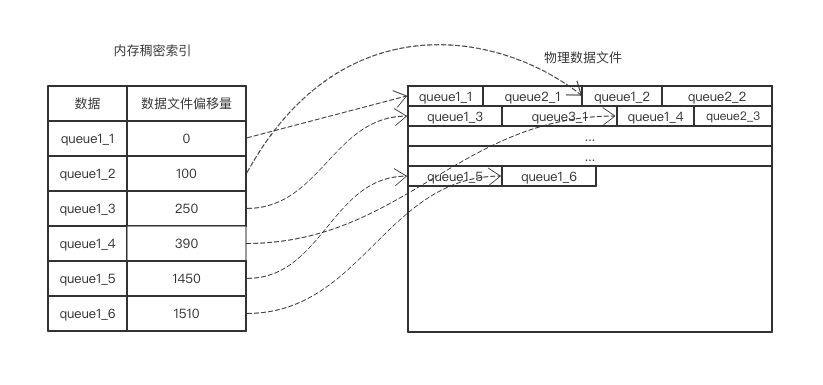
稠密索引是对全量的消息进行索引,适用于无序消息,索引量大,数据可以按条存取。
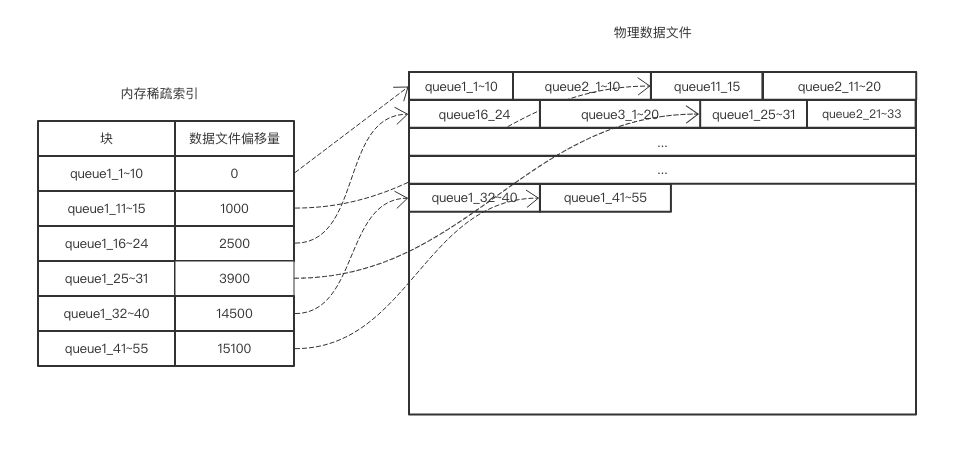
稀疏索引适用于按块存储的消息,块内有序,适用于有序消息,索引量小,数据按照块进行存取。
由于消息队列顺序存储,顺序消费的特性,加上 ssd 云盘最小存取单位为 4k(远大于单条消息)的限制,所以稀疏索引非常适用于这种场景。至于数据文件,可以做成参数,根据实际测试来判断到底是多文件效果好,还是单文件,此方案支持 100g 的单文件。
内存读写缓冲区
在稀疏索引的设计中,我们提到了写入缓冲区的概念,根据计算可以发现,100w 队列如果一个队列分配一个写入缓冲区,最多只能分配 4k,这恰好是最小的 ssd 写入块大小(但根据之前 ssd 云盘给出的数据来看,一次写入 64k 才能打满 io)。
一次写入 4k,这导致物理文件中的块大小是 4k,在读取时一次同样读取出 4k。
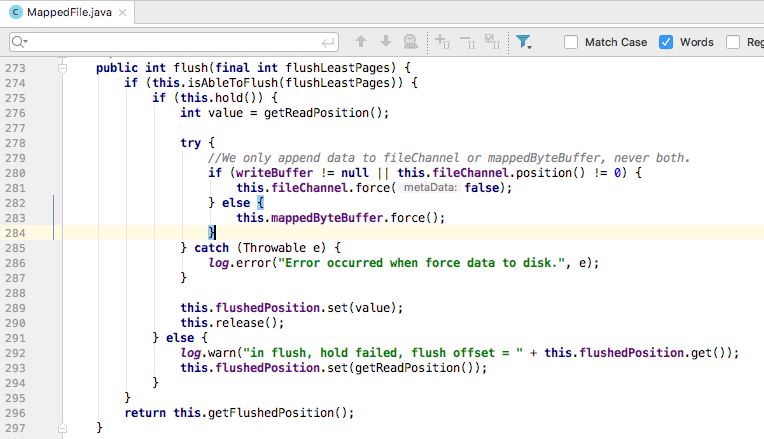
// 写缓冲区
private ByteBuffer writeBuffer = ByteBuffer.allocateDirect(4 * 1024);
// 用 short 记录消息长度
private final static int SINGLE_MESSAGE_SIZE = 2;
public void put(String queueName,byte[] message){
// 缓冲区满,先落盘
if (SINGLE_MESSAGE_SIZE + message.length > writeBuffer.remaining()) {
// 落盘
flush();
}
writeBuffer.putInt(SINGLE_MESSAGE_SIZE);
writeBuffer.put(message);
this.blockLength++;
}
不足 4k 的部分可以选择补 0,也可以跳过。评测程序保证了在 queue 级别的写入是同步的,所以对于同一个队列,我们无法担心同步问题。写入搞定之后,同样的逻辑搞定读取,由于 get 操作是并发的,2阶段和3阶段会有 10~30 个线程并发消费同一个队列,所以 get 操作的读缓冲区可以设计成 ThreadLocal<ByteBuffer> ,每次使用时 clear 即可,保证了缓冲区每次读取时都是崭新的,同时减少了读缓冲区的创建,否则会导致频繁的 full gc。读取的伪代码暂时不贴,因为这样的 get 方案不是最终方案。
到这里整体的设计架构已经出来了,写入流程和读取流程的主要逻辑如下:
写入流程:
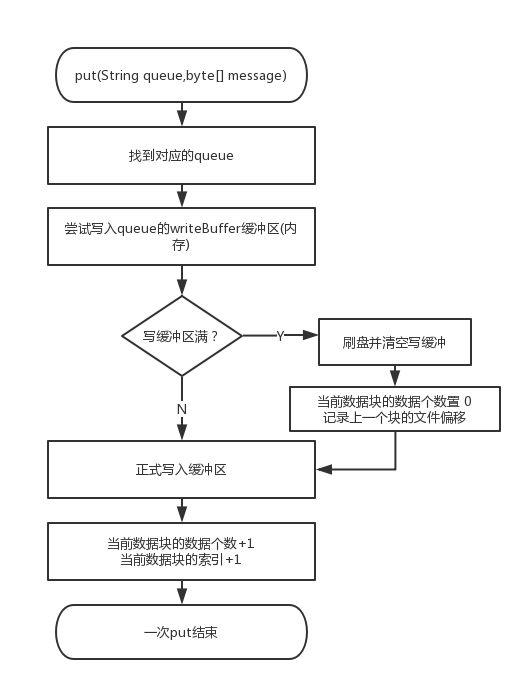
读取流程:
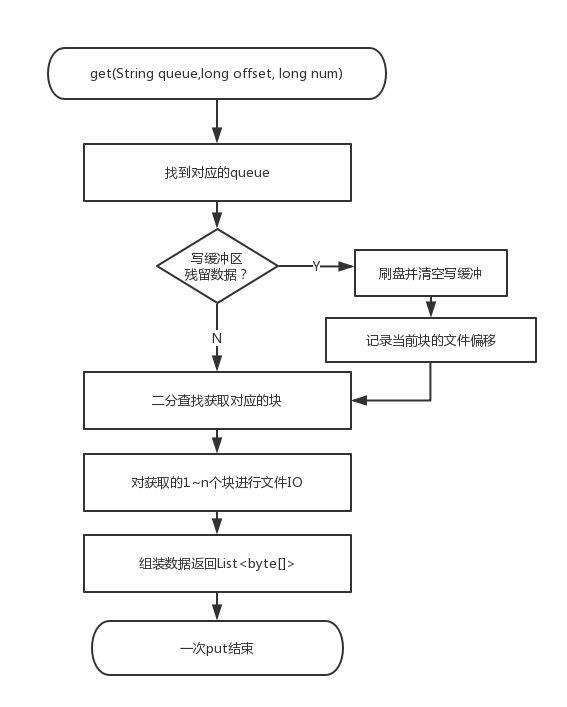
内存读缓存优化
方案设计经过好几次的推翻重来,才算是确定了上述的架构,这样的架构优势在于非常简单明了,实际上我的第一版设计方案的代码量是上述方案代码量的 2~3 倍,但实际效果却不理想。上述架构的跑分成绩大概可以达到 70~80w TPS,只能算作是第三梯队的成绩,在此基础上,进行了读取缓存的优化才达到了 126w 的 TPS。在介绍读取缓存优化之前,先容我介绍下 PageCache 的概念。
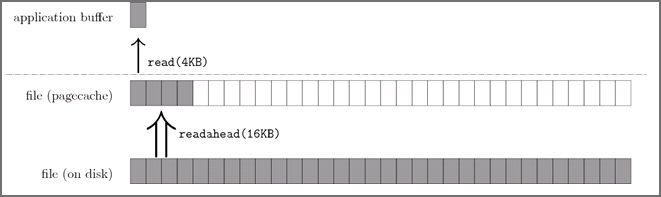
Linux 内核会将它最近访问过的文件页面缓存在内存中一段时间,这个文件缓存被称为 PageCache。如上图所示。一般的 read() 操作发生在应用程序提供的缓冲区与 PageCache 之间。而预读算法则负责填充这个PageCache。应用程序的读缓存一般都比较小,比如文件拷贝命令 cp 的读写粒度就是 4KB;内核的预读算法则会以它认为更合适的大小进行预读 I/O,比如 16-128KB。
所以一般情况下我们认为顺序读比随机读是要快的,PageCache 便是最大的功臣。
回到题目,这简直 nice 啊,因为在磁盘中同一个队列的数据是部分连续(同一个块则连续),实际上一个 4KB 块中大概可以存储 70 多个数据,而在顺序消费阶段,一次的 offset 一般为 10,有了 PageCache 的预读机制,7 次文件 IO 可以减少为 1 次!这可是不得了的优化,但是上述的架构仅仅只有 70~80w 的 TPS,这让我产生了疑惑,经过多番查找资料,最终在 @江学磊 的提醒下,才定位到了问题。
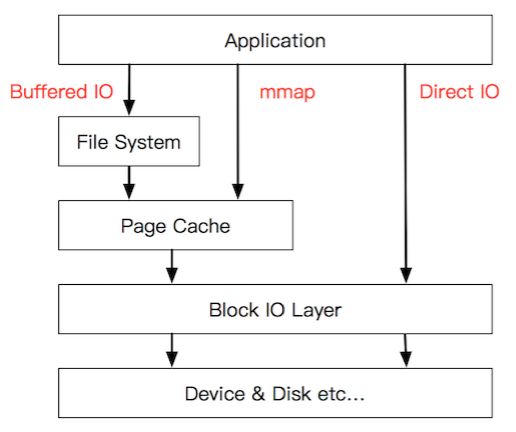
两种可能导致比赛中无法使用 pageCache 来做缓存
由于我使用 FIleChannel 进行读写,NIO 的读写可能走的正是 Direct IO,所以根本不会经过 PageCache 层。
测评环境中内存有限,在 IO 密集的情况下 PageCache 效果微乎其微。
虽然说不确定到底是何种原因导致 PageCache 无法使用,但是我的存储方案仍然满足顺序读取的特性,完全可以自己使用堆外内存自己模拟一个“PageCache”,这样在 3 阶段顺序消费时,TPS 会有非常高的提升。
一个队列一个读缓冲区用于顺序读,又要使得 get 阶段不存在并发问题,所以我选择了复用读缓冲区,并且给 get 操作加上了队列级别的锁,这算是一个小的牺牲,因为 2 阶段不会发生冲突,3 阶段冲突概率也并不大。
改造后的读取缓存方案如下:
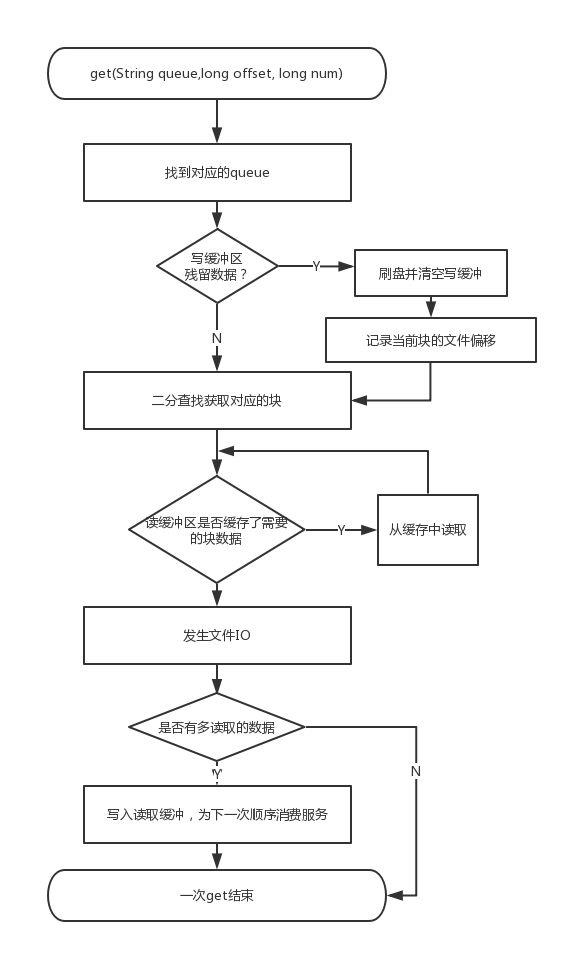
经过缓存改造之后,使用 Direct IO 也可以实现类似于 PageCache 的优化,并且会更加的可控,不至于造成频繁的缺页中断。经过这个优化,加上一些 gc 的优化,可以达到 126w TPS。整体方案算是介绍完毕。
其他优化
还有一些优化对整体流程影响不大,拎出来单独介绍。
2 阶段的随机索引检测和 3 阶段的顺序消费可以采取不同的策略,2 阶段可以直接读取所需要的数据,而不需要进行缓存(因为是随机检测,所以读缓存肯定不会命中)。
将文件数做成参数,调整参数来判断到底是多文件 TPS 高还是单文件,实际上测试后发现,差距并不是很大,单文件效果略好,由于是 ssd 云盘,又不存在磁头,所以真的不太懂原理。
gc 优化,能用数组的地方不要用 List。尽量减少小对象的出现,可以用数组管理基本数据类型,小对象对 gc 非常不友好,无论是初赛还是复赛,Java 比 Cpp 始终差距一个垃圾回收机制。必须保证全程不出现 full gc。
失败的优化与反思
本次比赛算是留下了不小的遗憾,因为写入的优化一直没有做好,读取缓存做好之后我 2 阶段和 3阶段的总耗时相加是 400+s,算是不错的成绩,但是写入耗时在 1300+s。我上述的方案采用的是多线程同步刷盘,但也尝试过如下的写入方案:
异步提交写缓冲区,单线程直接刷盘
异步提交写缓冲区,设置二级缓冲区 64k~64M,单线程使用二级缓冲区刷盘
同步将写缓冲区的数据拷贝至一个 LockFreeQueue,单线程平滑消费,以打满 IOPS
每 16 个队列共享一个写入缓冲区,这样控制写入缓冲区可以达到 64k,在刷盘时进行排序,将同一个 queue 的数据放置在一起。
但都以失败告终,没有 get 到写入优化的要领,算是本次比赛最大的遗憾了。
还有一个失误在于,评测环境使用的云盘 ssd 和我的本地 Mac 下的 ssd 存储结构差距太大,加上 mac os 和 Linux 的一些差距,导致本地成功的优化在线上完全体现不出来,还是租个阿里云环境比较靠谱。
另一方面的反思,则是对存储和 MQ 架构设计的不熟悉,对于 Kafka 和 RocketMQ 所做的一些优化也都是现学现用,不太确定用的对不对,导致走了一些弯路,而比赛中认识的一个 96 年的小伙子王亚普,相比之下对中间件知识理解的深度和广度实在令我钦佩,实在还有很多知识需要学习。
参赛感悟
第一感受是累,第二感受是爽。
相信很多选手和我一样是工作党,白天工作,只能腾出晚上的时间去搞比赛,对于966 的我真是太不友好了,初赛时间延长了一次还算给缓了一口气,复赛一眨眼就过去了,想翻盘都没机会,实在是遗憾。爽在于这次比赛真的是汗快淋漓地实践了不少中间件相关的技术,初赛的 Netty,复赛的存储设计,都是难以忘怀的回忆,比赛中也认识了不少朋友,有学生党,有工作党,感谢你们不厌其烦的教导与发人深省的讨论,从不同的人身上是真的可以学到很多自己缺失的知识。
据消息说,阿里中间件大赛很有可能是最后一届,无论是因为什么原因,作为参赛者,我都感到深深的惋惜,希望还能有机会参加下一届的中间件大赛,也期待能看到更多的相同类型的赛事被各大互联网公司举办,和大佬们同台竞技,一边认识更多新朋友的感觉真棒。
- END -
近期热文:
……
深入交流、更多福利
扫码加入我的知识星球
点击“阅读原文”,看本号其他精彩内容
以上是关于来自95后的天池中间件大赛总结的主要内容,如果未能解决你的问题,请参考以下文章
天池中间件大赛dubboMesh优化总结(qps从1000到6850)