随行付数据同步中间件「Porter」开源啦
Posted 京西
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了随行付数据同步中间件「Porter」开源啦相关的知识,希望对你有一定的参考价值。
Porter是一款数据同步中间件,主要用于解决同构/异构数据库之间的表级别数据同步问题。
目前Porter已在随行付内部实现普及,并持续迭代优化,取得显著成果。现在,我们决定开源Porter项目,希望能够帮助更多的团队解决「微服务下的数据库治理」的问题,欢迎社区开发者们与我们一起加强Porter!
项目背景
谈到微服务,不得不提的就是微服务架构下的数据治理,在微服务架构中强调彻底的组件化和服务化,每个微服务都可以独立的部署和投产。应用和数据库之间的关系受到微服务架构模式的影响,与以往传统模式中多个服务共享一个数据库不同,微服务架构下每个服务都要有自己的数据库。
这就意味着,如果你想获得微服务带来的好处,必要条件就是——每个服务独有一个数据库,因为微服务强调的就是松耦合。我们希望数据库和服务一样,要有充分的独立性,可以和服务一起部署、一起扩展、一起重构。
微服务改造过程中,无法避免的一个坎,就是垂直拆库:根据不同的子服务,把过去的「一库多服」拆分成「一库一服」。
一库一服还是一库多服?
系统的整体价值通过应用的各个模块之间的通信、协作、共享数据来体现。单体架构模式中,单体应用通过本地方法调用来完成,相比之下,微服务则是通过远程API调用完成。
而共享数据最“贱”的方式就是采用共享数据库模式,也就是单体应用中最常用的方式,一般只有一个数据库,如图「一库多服」和「一库一服」的方式:
「一库多服」的架构模式通常会被认为是微服务架构下的反范式,它的问题在于:
稳定性:单点故障,一个数据库挂掉,整批服务全部停止。服务独立性被扼杀;
耦合性:数据在一起,会给贪图方便的开发或者DBA工程师编写很多数据间高度依赖的程序或者工具;
扩展性:无法针对某一个服务进行精准优化或扩展,服务会大体分为两个读多写少、写多读少,数据库优化是根据服务而来的,不是一概而论。
所以随行付内部一般推荐这样的做法:
为每一个微服务准备一个单独的数据库,即「一库一服」模式。这种模式更加适合微服务架构,它符合每一个服务是独立开发、独立部署、独立扩展的特性。
在「一库一服」模式下,当需要对一个服务进行升级或者数据架构改动时,这并不会影响到其他的服务;需要对某个服务进行扩展时,也可以通过手术式对某一个服务进行局部扩容。
一库一服后,带来的明显问题:
业务管理系统对数据完整的查询,比如分页查询、多条件查询等,数据被拆分后如何来整合?
如何对数据的分析挖掘?需要分析全量的数据,并不能影响到当前业务。
各个微服务对数据库的要求出现了分歧,数据库类型多元化自主选择还是统一?多类型数据库的数据聚合数据共享要怎么做?
....
项目介绍
功能
2017年,Porter在随行付内部广泛使用,不仅仅提供数据同步功能,主要还有以下功能:
原生支持Oracle|mysql到Jdbc关系型数据库最终一致同步。
插件友好化,支持自定义源端消费插件、目标端载入插件、告警插件等插件二次开发。
支持自定义源端、目标端表、字段映射。
支持节点基于配置文件的同步任务配置。
支持管理后台同步任务推送,节点、任务管理。
提供任务运行指标监控,节点运行日志、任务异常告警。
支持节点资源限流、分配。
基于Zookeeper集群插件的分布式架构。支持自定义集群插件。
架构设计
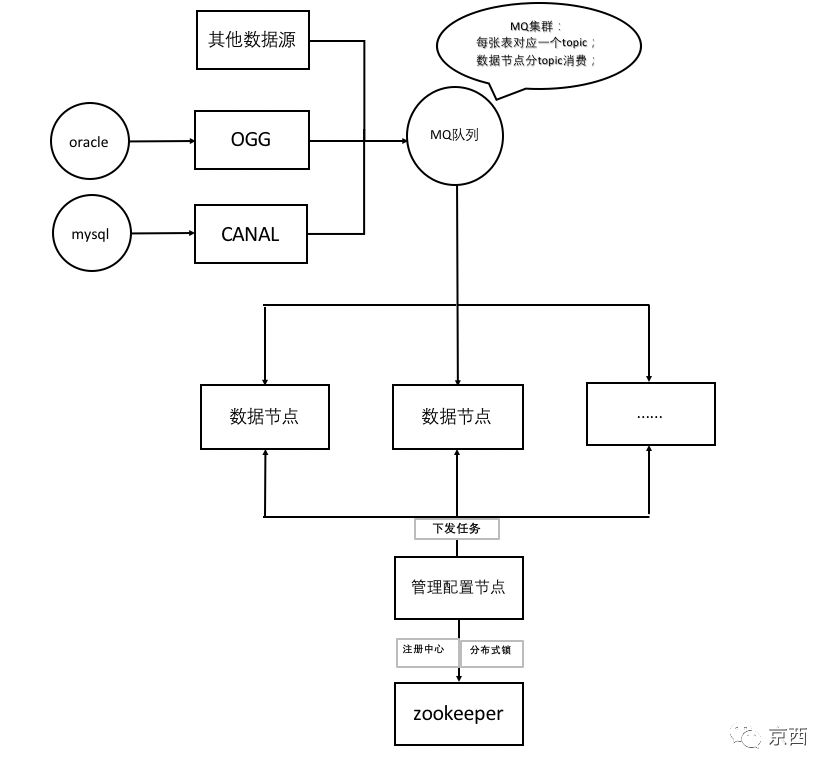
原理介绍:
1、基于Canal开源产品,获取MySql数据库增量日志数据。
2、管理系统架构。管理节点(web manager)管理工作节点任务编排、数据工作节点(TaskWork)汇报工作进度
3、基于Zookeeper集群插件的分布式架构。支持自定义集群插件
4、基于Kafka消息组件,每张表对应一个Topic,数据节点分Topic消费工作
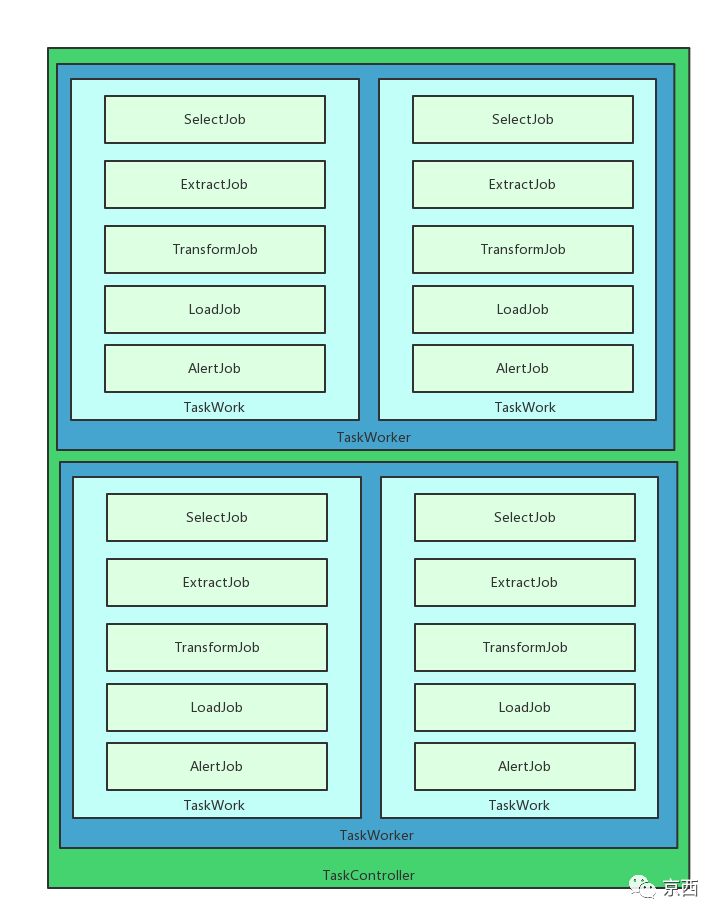
整体是一个管道过滤器风格的架构模式,如下:
1、TaskController与TaskWorker一对多关系,TaskController对应Node进程,进程内只有一个。
2、TaskWorker与TaskWork一对多关系,TaskWorker对应任务,每个任务对应一个Worker;每个任务有多个管道,即TaskWork,对应MQ topic;每个Work有多个阶段性任务。
3、TaskWork与Job一对一关系。
4、SelectJob单线程从数据源消费数据。
5、ExtractJob单线程从Select队列中读取数据,多线程提取数据。
6、TrasnformJob单线程从Extract内存集合中读取数据,多线程映射转换数据
7、LoadJob单线程按照SelectJob消费顺序加载数据到数据库。
8、AlertJob单线程同步Zookeeper数据库检查时间点,对比指定时间段内源数据库和目标数据库的数据条目差异,按照配置文件配置的告警方式进行告警。
结语
随行付在微服务架构落地中,面对的诸多技术难题与解决方案我们将在后续文章中抽丝剥茧,为你细细道来。
感谢我们处在技术飞速发展的时代,这个时代赋予我们更高的使命,也要求我们具备更高的能力。
我们既要仰望星空,也要脚踏实地。
随行付开源网站:
https://open.vbill.cn
https://github.com/sxfad/porter
管理员使用手册:
https://github.com/sxfad/porter/blob/master/doc/manager_manual.md
http://github.com/alibaba/canal
团队介绍
项目负责人:张科伟-架构师,主导Porter架构设计与开发
项目后端开发者:郭洪健-高级开发工程师、付紫钲-开发工程师、刘利鹏-高级开发工程师
项目前端开发者:殷玲慧-高级前端开发工程师;王淑彬-高级前端开发工程师
项目测试者:王田-资深测试工程师;张家豪-测试工程师
项目支持者:于浩、郭丽涛、葛杉杉、杨俊峰等DBA
系统截图
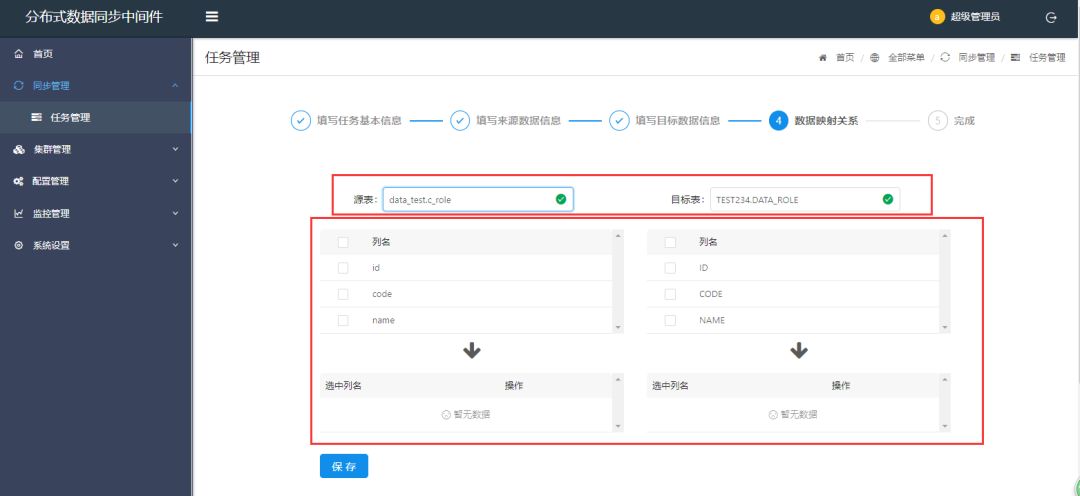
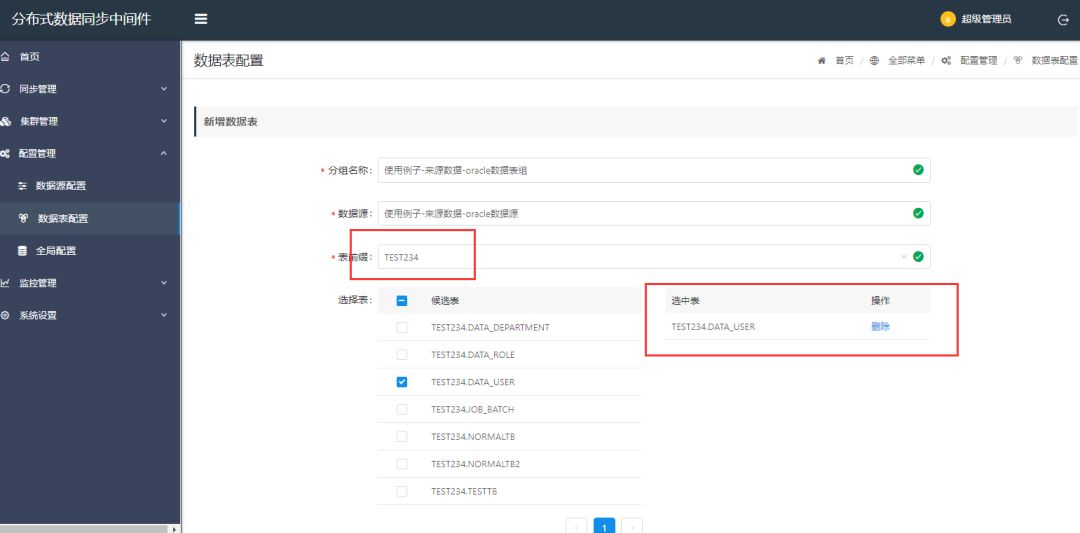
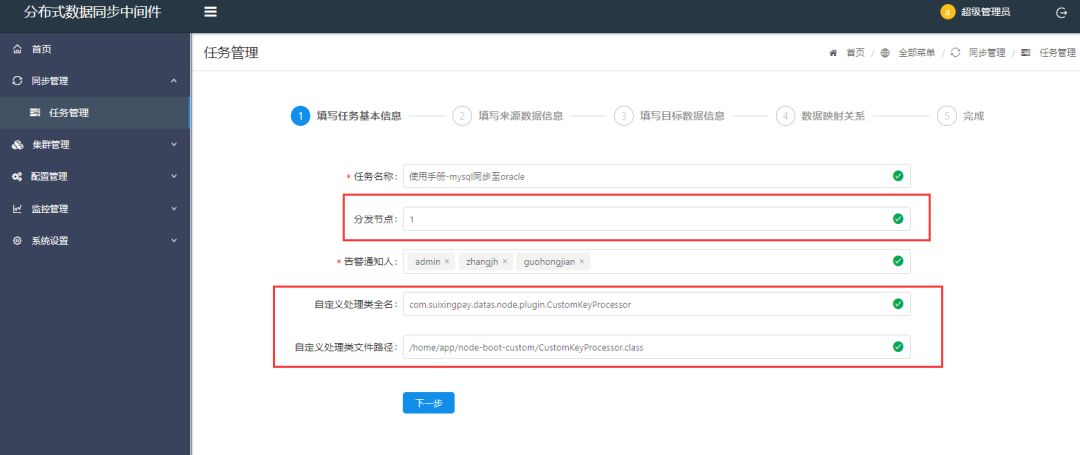
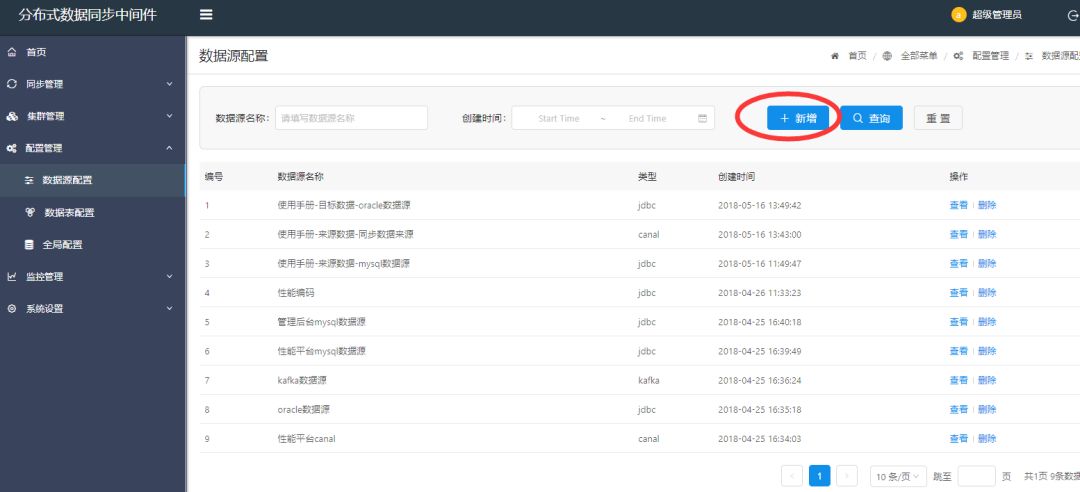
<< 滑动查看下一张图片 >>
写在最后:
欢迎加入Porter开源交流qq群,群号码:835209101
关于随行付的开源Porter项目,你有什么问题或看法,欢迎留言告诉我们,大家一起讨论交流!
更多精彩内容请点击“阅读原文”
以上是关于随行付数据同步中间件「Porter」开源啦的主要内容,如果未能解决你的问题,请参考以下文章
实战!Spring Boot 整合 阿里开源中间件 Canal 实现数据增量同步!