扫盲消息队列 | 消息中间件 | Kafka
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了扫盲消息队列 | 消息中间件 | Kafka相关的知识,希望对你有一定的参考价值。
先吐槽
我真的写技术文章写到怀疑人生,我翻看历史发文记录,只要我一本正经的写的技术文章,都没人看,但是!一发闲扯淡的内容,阅读量肯定是技术文的好几倍(读者爸爸们别这么搞嘛)
这说明啥?说明学习还是太枯燥无趣了,但是你想想,每天就网上看闲扯淡的文章,这咋能进大厂嘛!对吧。
再接受几次这样的打击我都不想写技术文章了。哎!不过我也就嘴上说说,我还是会坚持写下去的。
反正你们有没有认真看我不知道,我写完一遍这个文章,每个知识点细节我都滚瓜乱熟了,因为都是我一个字一个字敲出来的。
开始正文吧!21世纪的流水线工人,消息队列是一定要会的。
我真的不能再贴心了!!!!
背景
分布式微服务系统下,凡是可以“排队”去做的事情,都可以使用消息队列。网上买东西同样也需要“排队付款”,但是有人说,我点确认付款后马上就显示成功了,没感觉到排队呀?其实在后台系统中是排了,只不过排队的时间对于人来说有点短,可能1-2秒就结束了,但是对于计算机来说,这1-2秒的时间很长了。
大型分布式系统建设中,消息队列主要解决应用耦合、异步消息、流量削锋等问题。实现高性能、高可用、可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
Web应用程序毫无疑问有大量的代码执行HTTP请求/响应周期的一部分。这适用于更快的任务耗费数百毫秒内或更少。然而,有些处理,还需要耗时更多甚至最终会是一两秒钟缓慢的同步执行,在如此长时间的调用流转中,肯定有一些调用是可以不同步的,如下单送积分,用户下单是最主要的,送积分的操作可以异步去做,订单支付成功给用户的短信通知,返回支付订单进入下一环节更更好,短信通知可以异步去发送,为了应对诸如此类的异步操作,消息队列这门技术应运而生。
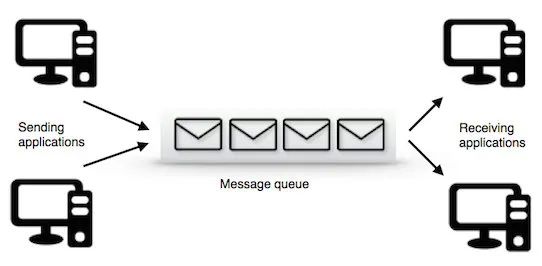
在计算机科学中,消息队列(Message queue)是一种进程间通信或同一进程的不同线程间的通信方式。实际上,消息队列常常保存在链表结构中。[2]拥有权限的进程可以向消息队列中写入或读取消息。
目前,有很多消息队列有很多开源的实现,包括JBoss Messaging、JORAM、Apache ActiveMQ、Sun Open Message Queue、RabbitMQ[3]、IBM MQ[4]、Apache Qpid[5]、Apache RocketMQ[6]和HTTPSQS。[7]
说了这么多没用的,消息队列到底在企业里怎么用的?
我就直接上两段代码吧
发送一条消息demo
public class MqProducer {
private final Logger LOG = LoggerFactory.getLogger(MqProducer.class);
@Resource
private Producer payProducer;
public void sendPayMsg(String msg) {
try {
LOG.debug("send msg:{}", msg);
payProducer.send(msg);//发送出去一条消息。
} catch (MQException e) {
LOG.error("mq消息异常 message:{}", msg, e);
}
}
}
接收一个消息demo
public class DemoConsumer {
/**
* 注意:服务端对单ip创建相同主题相同队列的消费者实例数有限制,超过100个拒绝创建.
* */
private static IConsumerProcessor consumer;
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.setProperty(ConsumerConstants.SubscribeGroup, "dache.risk.log.queue.v2");
// 创建topic对应的consumer对象(注意每次build调用会产生一个新的实例)
consumer = KafkaClient.buildConsumerFactory(properties, "topic.xxx.xxx");
// 调用recvMessageWithParallel设置listener
consumer.recvMessageWithParallel(String.class, new IMessageListener() {
@Override
public ConsumeStatus recvMessage(Message message, MessagetContext context) {
//TODO:业务侧的消费逻辑代码
try {
System.out.println("message=[" + message.getBody() + "] partition=" + message.getParttion());
} catch (Exception e) {
e.printStackTrace();
}
return ConsumeStatus.CONSUME_SUCCESS;
}
});
}
}
消息长什么样子?
{"businessType":1,"cityId":10,"ctime":1567426767077,"dataKey":20190902,"logType":1,"phone":"13212341234","uid":12345678,"userType":1,"uuid":"32EA02C86D78863"}
代码呢,就是普通的java代码,只不过引入了一个kafka的jar,消息就是json串,使用消息队列真的就这么点代码,剩下的内容都是业务代码了。
新手关注消息队列,主要关注两个最重要的概念就行了,一个是生产者,一个是消费者,两者的关系和我们日常发短信一样,短信是通过手机号发送接收,系统间消息是通过topic,可以理解成手机号。
-
Producer消息的生产方,如支付系统确认用户已经支付,支付系统要通知订单系统和物流系统,支付系统就是生产者。 -
Consumer消费的接收方,Producer 的案例中,物流系统就是消费方,前两个都比较简单,我就不多说了。 -
Topic每条发布到MQ集群的消息都有一个类别,这个类别被称为topic,可以理解成一类消息的名字。所有的消息都以topic作为单位进行归类。
日常开发中需要关心哪些指标
1.生产消息数目
每分钟几百几千个都正常水平吧,业务繁忙的每分钟几万几十万也是有的
2.消息延迟情况
延迟越低越好啦,几百毫秒正常水平。
3.消息积压数
这个当然是要0了,如果遇到消费端服务器上线,可能会有段时间积压正常,这个指标,日常应该都是0才对。
为什么使用消息队列
开头不是说了,排队能解决一个问题,就是削峰,意思就是流量洪峰来了,收银员结账速度依旧是一样的,不会被累死,还有两个重要的概念就是解耦、异步
使用消息队列有什么缺点呢?
这个新手也一定要知道啦,因为面试官会问。
-
消息丢失问题: 任何系统不能保证万无一失,比如 Producer 发出了10000条消息,Consumer 只收到了 9999 个消息,有1个丢了,Consumer 能否接受丢一条?如果是订单成功短信可以接受丢一条,就是有一个顾客没有通知到已经发货,但货还是发出去了,如果是支付系统,用户已经付款却因为消息丢失没有通知到订单或物流系统,那恐怕顾客要找你麻烦了。 -
消息重复问题:如 Producer 发出了10000条消息,Consumer 只收到了 10001 条消息,有一条是重复的,业务能否接受一条重复的消息,这个是作为系统设计者要考虑的问题。 -
消息的顺序问题:如 Producer 发送顺序是123,Consumer 收到的消息是132,要考虑消费端是否对顺序敏感。 -
一致性问题: 如消息丢失问题真的发生且无法找回,会造成两个系统的数据最终不一致,如果消息延迟,会造成短暂不一致。
ActiveMQ vs Kafka vs RabbitMQ
RabbitMQ、Kafka和ActiveMQ都是用于提供异步通信和解耦进程(分离消息的发送方和接收方)的消息传递技术。
它们被称为消息队列、消息代理或消息传递工具。RabbitMQ、Kafka和ActiveMQ都有相同的基本用途,但它们的工作方式不同。Kafka是一个高吞吐量的分布式消息传递系统。
RabbitMQ是一个基于AMQP的可靠消息代理。ActiveMQ和Kafka都是Apache的产品,都是用Java编写的,RabbitMQ是用Erlang编写的。
进BAT你就研究这其中一个就可以了,数量不在多,重点是深度。
ActiveMQ,Kafka和RabbitMQ有哪些替代方案?
这些在国内都不是很常用,新手了解一下就可以了,反正,知识广度&眼界是有了。
-
Apollo:在现有REST API的基础上构建一个通用的GraphQL API,可以快速发布新的应用程序特性,而无需等待后端更改。 -
IBM MQ:它是一个消息传递中间件,可以简化和加速跨多个平台的不同应用程序和业务数据的集成。它提供了经过验证的企业级消息传递功能,能够熟练而安全地移动信息。 -
ZeroMQ:扩展性好,开发比较灵活,采用C语言实现,实际上他只是一个socket库的重新封装,如果我们做为消息队列使用,需要开发大量的代码 -
Amazon SQS
关于消息队列的常见面试题
-
为什么使用消息队列? -
消息队列有什么优点和缺点? -
那为什么Kafka的吞吐量远高于其他同类中间件? -
比较重要的关键字吗?比如 Producer, Consumer,Partition,Broker,你都是怎么理解的?
参考资料
-
Thorough Introduction to Apache Kafka -
推荐一本书《深入理解Kafka:核心设计与实践原理》,微信读书就可以免费阅读。
以上是关于扫盲消息队列 | 消息中间件 | Kafka的主要内容,如果未能解决你的问题,请参考以下文章