秒杀系统番外篇 | 阿里开源MySQL中间件Canal快速入门
Posted 后端技术漫谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了秒杀系统番外篇 | 阿里开源MySQL中间件Canal快速入门相关的知识,希望对你有一定的参考价值。

前言
距离上一篇文章发布又过去了两周,这次先填掉上一篇结尾处开的坑,介绍一下数据库中间件Canal的使用。
「Canal用途很广,并且上手非常简单,小伙伴们在平时完成公司的需求时,很有可能会用到。」
举个例子:
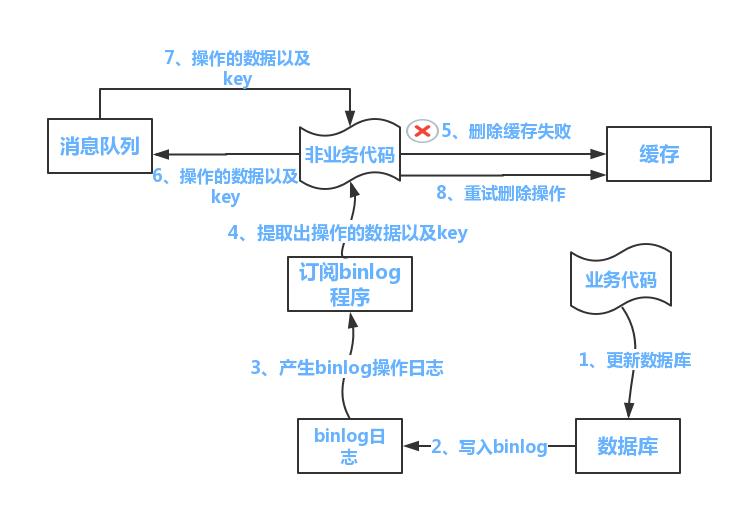
公司目前有多个开发人员正在开发一套服务,为了缩短调用延时,对部分接口数据加入了缓存。一旦这些数据在数据库中进行了更新操作,缓存就成了旧数据,必须及时删除。
删除缓存的代码「理所当然可以写在更新数据的业务代码里」,但有时候者写操作是在别的项目代码里,你可能无权修改,亦或者别人不愿你在他代码里写这种业务之外的代码。(毕竟多人协作中间会产生各种配合问题)。又或者就是单纯的删除缓存的操作失败了,缓存依然是旧数据。
正如上篇文章里面所说,我们可以将缓存更新操作完全独立出来,形成一套单独的系统。「Canal正是这么一个很好的帮手。」 能帮我们实现像下图这样的系统:
「本篇文章的要点如下:」
-
Canal是什么 -
Canal工作原理 -
数据库的读写分离 -
数据库主从同步 -
数据库主从同步一致性问题 -
异步复制 -
全同步复制 -
半同步复制 -
Canal实战 -
开启mysql Binlog -
配置Canal服务 -
运行Canal服务 -
Java客户端Demo
❝ ❞
Canal是什么
众所周知,阿里是国内比较早地大量使用MySQL的互联网企业(去IOE化:去掉IBM的小型机、Oracle数据库、EMC存储设备,代之以自己在开源软件基础上开发的系统),并且基于阿里巴巴/淘宝的业务,从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
Canal应运而生,它通过伪装成数据库的从库,读取主库发来的binlog,用来实现「数据库增量订阅和消费业务需求」。
「Canal用途:」
-
数据库镜像 -
数据库实时备份 -
索引构建和实时维护(拆分异构索引、倒排索引等) -
「业务 cache 缓存刷新」 -
带业务逻辑的增量数据处理
https://github.com/alibaba/canal
在这里就不再摘抄项目简介了,提炼几个值得注意的点:
-
canal 使用 client-server 模式,数据传输协议使用 protobuf 3.0(很多RPC框架也在使用例如gRPC) -
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x -
canal 作为 MySQL binlog 增量获取和解析工具,可将变更记录投递到 MQ 系统中,比如 Kafka/RocketMQ。
Canal工作原理
Canal实际是将自己伪装成数据库的从库,来读取Binlog。我们先补习下关于「MySQL数据库主从数据库」的基础知识,这样就能更快的理解Canal。
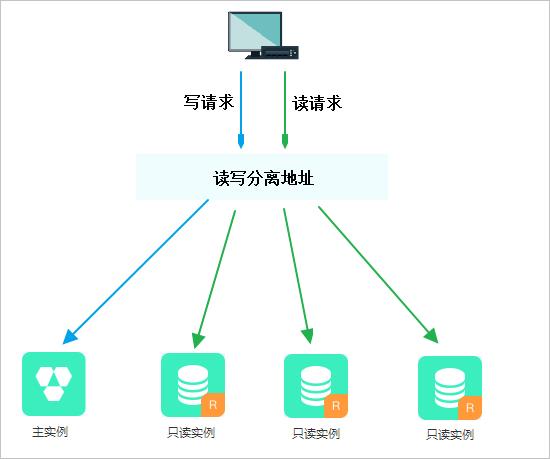
数据库的读写分离
为了应对高并发场景,MySQL支持把一台数据库主机分为单独的一台写主库(主要负责写操作),而把读的数据库压力分配给读的从库,而且读从库可以变为多台,这就是读写分离的典型场景。
数据库主从同步
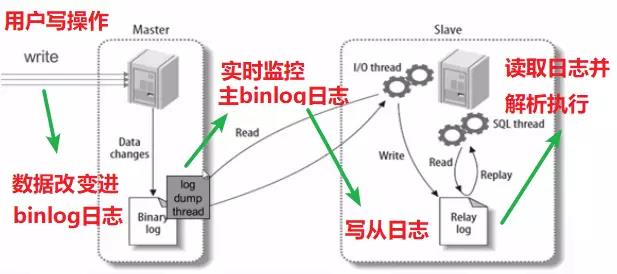
实现数据库的读写分离,是通过数据库主从同步,让从数据库监听主数据库Binlog实现的。大体流程如下图:
❝MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
❞
详细主从同步原理在这里就不展开细说了。
可以看到,这种架构下会有一个问题,「数据库主从同步会存在延迟,那么就会有短暂的时间,主从数据库的数据是不一致的。」
这种不一致大多数情况下非常短暂,很多时候我们可以忽略他。
但一旦要求数据一致,就会引申出如何解决这个问题的思考。
数据库主从同步一致性问题
我们通常使用MySQL主从复制来解决MySQL的单点故障问题,其通过逻辑复制的方式把主库的变更同步到从库,主备之间无法保证严格一致的模式,
于是,MySQL的主从复制带来了主从“数据一致性”的问题。「MySQL的复制分为:异步复制、半同步复制、全同步复制。」
异步复制
MySQL默认的复制即是异步复制,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,「主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。」
❝主库将事务 Binlog 事件写入到 Binlog 文件中,此时主库只会通知一下 Dump 线程发送这些新的 Binlog,然后主库就会继续处理提交操作,而此时不会保证这些 Binlog 传到任何一个从库节点上。
❞
全同步复制
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。「因为需要等待所有从库执行完该事务才能返回」,所以全同步复制的性能必然会收到严重的影响。
❝当主库提交事务之后,所有的从库节点必须收到、APPLY并且提交这些事务,然后主库线程才能继续做后续操作。但缺点是,主库完成一个事务的时间会被拉长,性能降低。
❞
半同步复制
是介于全同步复制与全异步复制之间的一种,「主库只需要等待至少一个从库节点收到」并且 Flush Binlog 到 Relay Log 文件即可,主库不需要等待所有从库给主库反馈。同时,「这里只是一个收到的反馈,而不是已经完全完成并且提交的反馈」,如此,节省了很多时间。
❝介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,「同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。」
❞
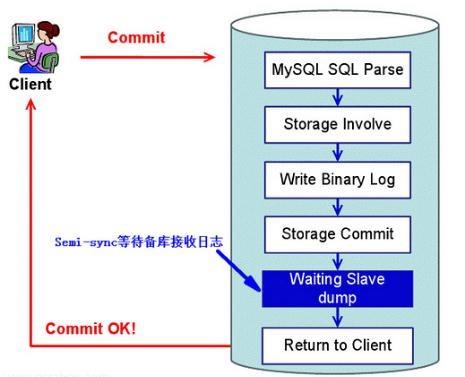
「事实上,半同步复制并不是严格意义上的半同步复制,MySQL半同步复制架构中,主库在等待备库ack时候,如果超时会退化为异步后,也可能导致“数据不一致”。」
❝当半同步复制发生超时时(由rpl_semi_sync_master_timeout参数控制,单位是毫秒,默认为10000,即10s),会暂时关闭半同步复制,转而使用异步复制。当master dump线程发送完一个事务的所有事件之后,如果在rpl_semi_sync_master_timeout内,收到了从库的响应,则主从又重新恢复为半同步复制。
❞
关于半同步复制的详细原理分析可以看这篇引申文章,在此不展开:
https://www.cnblogs.com/ivictor/p/5735580.html
回到Canal的工作原理
回顾了数据库从库的数据同步原理,理解Canal十分简单,直接引用官网原文:
-
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议 -
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) -
canal 解析 binary log 对象(原始为 byte 流)
Canal实战
开启MySQL Binlog
这个步骤我在之前的文章已经提到过,这里完善了一下,再贴一下,方便大家。
首先进入数据库控制台,运行指令:
mysql> show variables like'log_bin%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin | OFF |
| log_bin_basename | |
| log_bin_index | |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
+---------------------------------+-------+
5 rows in set (0.00 sec)
可以看到我们的binlog是关闭的,都是OFF。接下来我们需要修改Mysql配置文件,执行命令:
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
在文件末尾添加:
log-bin=/var/lib/mysql/mysql-bin
binlog-format=ROW
保存文件,重启mysql服务:
sudo service mysql restart
重启完成后,查看下mysql的状态:
systemctl status mysql.service
这时,如果你的mysql版本在5.7或更高版本,就会报错:
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.190791Z 0 [Warning] Changed limits: max_open_files: 1024 (requested 5000)
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.190839Z 0 [Warning] Changed limits: table_open_cache: 431 (requested 2000)
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.359713Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (se
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.361395Z 0 [Note] /usr/sbin/mysqld (mysqld 5.7.28-0ubuntu0.16.04.2-log) starting as process 5930 ...
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.363017Z 0 [ERROR] You have enabled the binary log, but you haven't provided the mandatory server-id. Please refer to the proper server
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.363747Z 0 [ERROR] Aborting
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.363922Z 0 [Note] Binlog end
Jan 06 15:49:58 VM-0-11-ubuntu mysqld[5930]: 2020-01-06T07:49:58.364108Z 0 [Note] /usr/sbin/mysqld: Shutdown complete
Jan 06 15:49:58 VM-0-11-ubuntu systemd[1]: mysql.service: Main process exited, code=exited, status=1/FAILURE
「You have enabled the binary log, but you haven't provided the mandatory server-id. Please refer to the proper server」
之前我们的配置,对于5.7以下版本应该是可以的。但对于高版本,我们需要指定server-id。
我们给这个MySQL指定为2(只要不与其他库id重复):
server-id=2
创建数据库Canal使用账号
mysql> select user, host from user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| root | % |
| debian-sys-maint | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+-----------+
5 rows in set
CREATE USER canal IDENTIFIED BY 'xxxx'; (填写密码)
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
show grants for 'canal'
配置Canal服务
去Github下载最近的Canal稳定版本包:
-
https://github.com/alibaba/canal/releases
解压缩:
mkdir /tmp/canal
tar zxvf canal.deployer-$version.tar.gz -C /tmp/canal
配置文件设置:
主要有两个文件配置,一个是conf/canal.properties一个是conf/example/instance.properties。
为了快速运行Demo,只修改conf/example/instance.properties里的数据库连接账号密码即可
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=xxxxxxx
canal.instance.connectionCharset = UTF-8
运行Canal服务
请先确保机器上有JDK,接着运行Canal启动脚本:
sh bin/startup.sh
下图即成功运行:
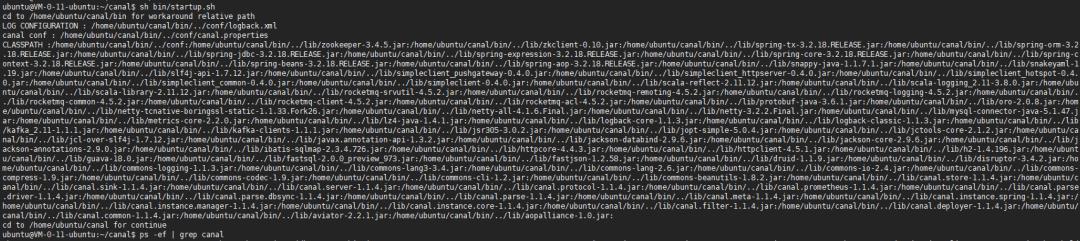
Java客户端代码
我在秒杀系统系列文章的代码仓库里(miaosha-job)编写了如下客户端代码
package job;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
public class CanalClient {
private static final Logger LOGGER = LoggerFactory.getLogger(CanalClient.class);
public static void main(String[] args) {
// 第一步:与canal进行连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111),
"example", "", "");
connector.connect();
// 第二步:开启订阅
connector.subscribe();
// 第三步:循环订阅
while (true) {
try {
// 每次读取 1000 条
Message message = connector.getWithoutAck(1000);
long batchID = message.getId();
int size = message.getEntries().size();
if (batchID == -1 || size == 0) {
LOGGER.info("当前暂时没有数据,休眠1秒");
Thread.sleep(1000);
} else {
LOGGER.info("-------------------------- 有数据啦 -----------------------");
printEntry(message.getEntries());
}
connector.ack(batchID);
} catch (Exception e) {
LOGGER.error("处理出错");
} finally {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* 获取每条打印的记录
*/
public static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
// 第一步:拆解entry 实体
Header header = entry.getHeader();
EntryType entryType = entry.getEntryType();
// 第二步:如果当前是RowData,那就是我需要的数据
if (entryType == EntryType.ROWDATA) {
String tableName = header.getTableName();
String schemaName = header.getSchemaName();
RowChange rowChange = null;
try {
rowChange = RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
EventType eventType = rowChange.getEventType();
LOGGER.info(String.format("当前正在操作表 %s.%s, 执行操作= %s", schemaName, tableName, eventType));
// 如果是‘查询’ 或者 是 ‘DDL’ 操作,那么sql直接打出来
if (eventType == EventType.QUERY || rowChange.getIsDdl()) {
LOGGER.info("执行了查询语句:[{}]", rowChange.getSql());
return;
}
// 第三步:追踪到 columns 级别
rowChange.getRowDatasList().forEach((rowData) -> {
// 获取更新之前的column情况
List<Column> beforeColumns = rowData.getBeforeColumnsList();
// 获取更新之后的 column 情况
List<Column> afterColumns = rowData.getAfterColumnsList();
// 当前执行的是 删除操作
if (eventType == EventType.DELETE) {
printColumn(beforeColumns);
}
// 当前执行的是 插入操作
if (eventType == EventType.INSERT) {
printColumn(afterColumns);
}
// 当前执行的是 更新操作
if (eventType == EventType.UPDATE) {
printColumn(afterColumns);
// 进行删除缓存操作
deleteCache(afterColumns, tableName, schemaName);
}
});
}
}
}
/**
* 每个row上面的每一个column 的更改情况
* @param columns
*/
public static void printColumn(List<Column> columns) {
columns.forEach((column) -> {
String columnName = column.getName();
String columnValue = column.getValue();
String columnType = column.getMysqlType();
// 判断 该字段是否更新
boolean isUpdated = column.getUpdated();
LOGGER.info(String.format("数据列:columnName=%s, columnValue=%s, columnType=%s, isUpdated=%s", columnName, columnValue, columnType, isUpdated));
});
}
/**
* 秒杀下单接口删除库存缓存
*/
public static void deleteCache(List<Column> columns, String tableName, String schemaName) {
if ("stock".equals(tableName) && "m4a_miaosha".equals(schemaName)) {
AtomicInteger id = new AtomicInteger();
columns.forEach((column) -> {
String columnName = column.getName();
String columnValue = column.getValue();
if ("id".equals(columnName)) {
id.set(Integer.parseInt(columnValue));
}
});
// TODO: 删除缓存
LOGGER.info("Canal删除stock表id:[{}] 的库存缓存", id);
}
}
}
代码中有详细的注释,就不做解释了。
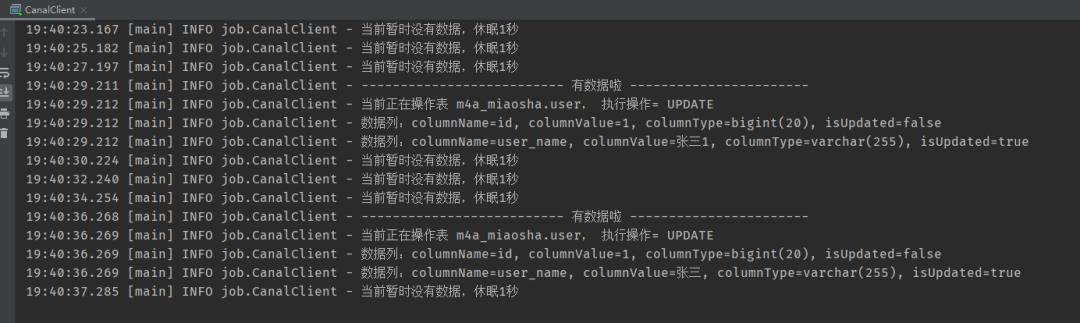
我们跑起代码,紧接着我们在数据库中进行更改UPDATE操作,把法外狂徒张三改成张三1,然后再改回张三,见下图。
Canal成功收到了两条更新操作:
紧接着我们模拟一个删除Cache缓存的业务,在代码中有:
/**
* 秒杀下单接口删除库存缓存
*/
public static void deleteCache(List<Column> columns, String tableName, String schemaName) {
if ("stock".equals(tableName) && "m4a_miaosha".equals(schemaName)) {
AtomicInteger id = new AtomicInteger();
columns.forEach((column) -> {
String columnName = column.getName();
String columnValue = column.getValue();
if ("id".equals(columnName)) {
id.set(Integer.parseInt(columnValue));
}
});
// TODO: 删除缓存
LOGGER.info("Canal删除stock表id:[{}] 的库存缓存", id);
}
}
「在上面的代码中,在收到m4a_miaosha.stock表的更新操作后,我们刷新库存缓存。效果如下:」
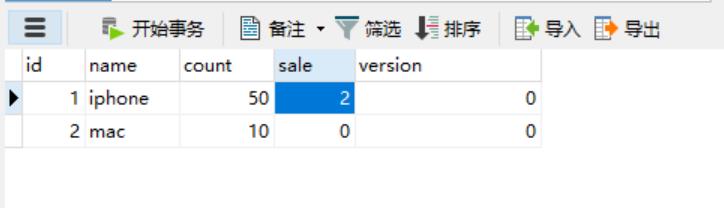
简单的Canal使用就介绍到这里,剩下的发挥空间留给各位读者大大们。
总结
本文总结了Canal的基本原理和简单的使用。
「总结如下几点:」
-
Canal实际是将自己伪装成数据库的从库,来读取主数据库发来的Binlog。 -
Canal用途很广,比如数据库实时备份、索引构建和实时维护(拆分异构索引、倒排索引等)、业务 cache 缓存刷新。 -
Canal可以推送至非常多数据源,并支持推送到消息队列,方便多语言使用。
参考
-
https://blog.csdn.net/l1028386804/article/details/81208362 -
https://github.com/alibaba/canal/wiki/QuickStart -
https://youzhixueyuan.com/database-master-slave-synchronization.html -
https://www.jianshu.com/p/790a158d9eb3 -
https://blog.csdn.net/xihuanyuye/article/details/81220524 -
https://www.cnblogs.com/ivictor/p/5735580.html
往期推荐
关注我
我是一名后端开发工程师。主要关注后端开发,数据安全,爬虫,物联网,边缘计算等方向,欢迎交流。
各大平台都可以找到我
-
「微信公众号:后端技术漫谈」 -
「Github:@qqxx6661」 -
CSDN:@Rude3knife -
知乎:@后端技术漫谈 -
简书:@蛮三刀把刀 -
掘金:@蛮三刀把刀
原创文章主要内容
-
后端开发相关技术文章 -
Java面试复习手册 -
设计模式/数据结构/LeetCode算法题解 -
爬虫/边缘计算相关技术文章 -
逸闻趣事/好书分享/个人生活
个人公众号:后端技术漫谈
「如果文章对你有帮助,不妨收藏,转发,在看起来~」
以上是关于秒杀系统番外篇 | 阿里开源MySQL中间件Canal快速入门的主要内容,如果未能解决你的问题,请参考以下文章