Lua 的速度为什么比 Python 快?
Posted 游戏蛮牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lua 的速度为什么比 Python 快?相关的知识,希望对你有一定的参考价值。
Lua 和 Python 同为虚拟机解释型脚本语言,为什么 Lua 的执行速度比 Python 高?
有几个答案用指令集基于栈还是寄存器来解释,错了。Python主要不是慢在这里。
我们做个实验。最简单的整数循环:
Python 3.5.1 (default, Mar 3 2016, 09:29:07)[GCC 5.3.0] on linuxType "help", "copyright", "credits" or "license" for more information.> def f(n):... i=0... while i<n:... i+=1...> import timeit> timeit.timeit('f(100*1000*1000)', number=1, globals=globals())13.05189818800136> import dis> dis.dis(f)2 0 LOAD_CONST 1 (0)3 STORE_FAST 1 (i)3 6 SETUP_LOOP 26 (to 35)9 LOAD_FAST 1 (i)12 LOAD_FAST 0 (n)15 COMPARE_OP 0 (<)18 POP_JUMP_IF_FALSE 344 21 LOAD_FAST 1 (i)24 LOAD_CONST 2 (1)27 INPLACE_ADD28 STORE_FAST 1 (i)31 JUMP_ABSOLUTE 934 POP_BLOCK35 LOAD_CONST 0 (None)38 RETURN_VALUE
和未优化的C比较一下:
$ cat test.cint main() {int n=100*1000*1000;int i=0;while (i<n)i++;return 0;}$ gcc -O0 test.c$ time ./a.outreal 0m0.445suser 0m0.443ssys 0m0.000s$ gcc -O0 -S test.c$ cat test.s.file "test.c".text.globl main.type main, @functionmain:.LFB0:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl $100000000, -8(%rbp)movl $0, -4(%rbp)jmp .L2.L3:addl $1, -4(%rbp).L2:movl -4(%rbp), %eaxcmpl -8(%rbp), %eaxjl .L3movl $0, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc.LFE0:.size main, .-main.ident "GCC: (GNU) 6.1.1 20160602".section .note.GNU-stack,"",@progbits
首先看到,Python速度真的是相当慢。最简单的整数循环耗时是未优化C程序的近30倍。
然后我们看Python版本的循环体:
9 LOAD_FAST 1 (i)12 LOAD_FAST 0 (n)15 COMPARE_OP 0 (<)18 POP_JUMP_IF_FALSE 344 21 LOAD_FAST 1 (i)24 LOAD_CONST 2 (1)27 INPLACE_ADD28 STORE_FAST 1 (i)31 JUMP_ABSOLUTE 9
Python编译器还真是很少进行优化,比如明显的对i反复LOAD_FAST和STORE_FAST,可以改为一直在栈上操作。然而在Python里尝试做这种优化,和把基于栈的指令集改成基于寄存器一样,是没有关注到重点。
如果是基于寄存器的指令集,那么最好情况下所有LOAD_FAST, LOAD_CONST, STORE_FAST指令可以去掉,指令数由9条减少到4条,看起来是很大的进步。然而“数指令数估计时间”这种思路并不适用于Python VM。
所有指令都没有类型,或者说都是“抽象”操作。这与JVM形成了鲜明对比:JVM内置了多种基本类型,并且指令都指定了类型,比如iload, iadd。为了效率,Java甚至把这些类型在语言层面暴露出来,哪怕基本类型和对象类型语义不一致给初学者带来了困惑。
接下来我们来看Python VM实现这些指令的代码。字节码解释器的主体是ceval.c里一个巨大的switch。先看其中的LOAD_FAST:
我把执行路径上的宏和函数都加进来了。所以图中出现的就是在前面的例子里,LOAD_FAST要经过的全部代码。其中TARGET和FAST_DISPATCH是每条字节码都有的纯解释开销,而中间的代码是实际干活的部分。如果没有开tracing,最后会用computed goto直接跳到下一条指令的处理代码。
希望读者对LOAD_FAST这样一条比较简单的指令的工作量有了感性认识。
接着看STORE_FAST:
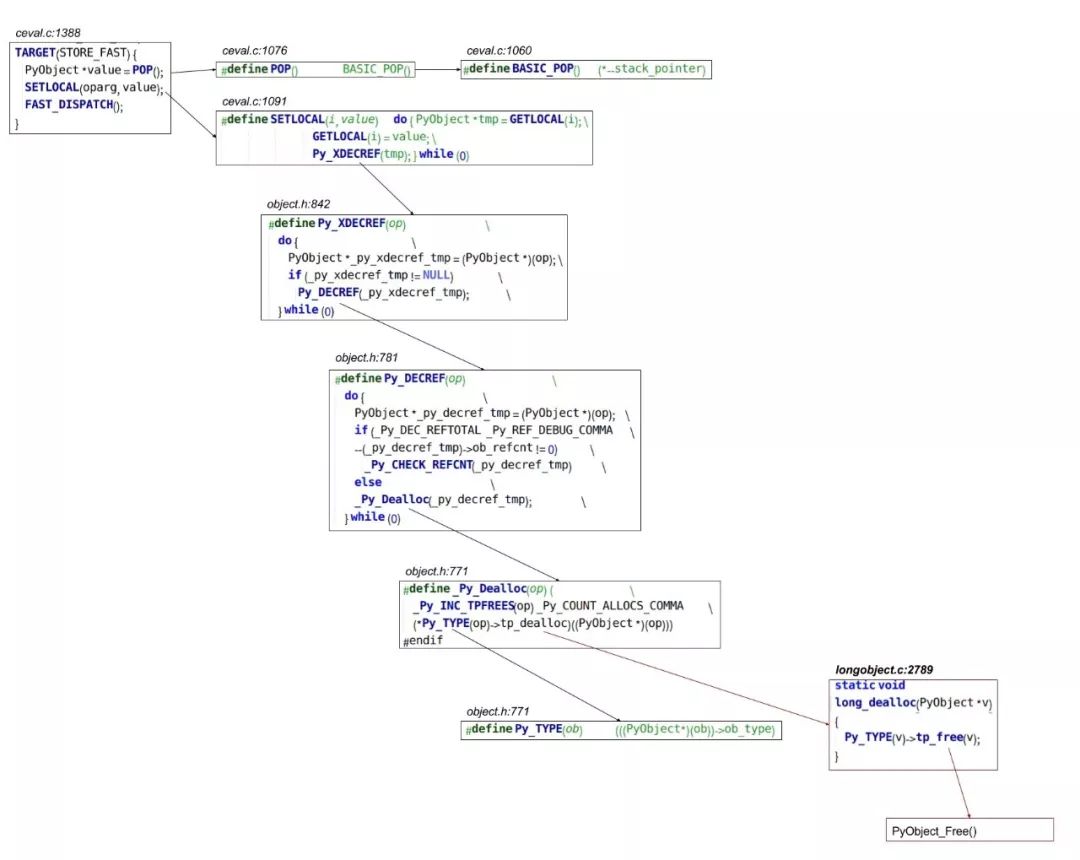
前面出现过的宏/函数我就不再次重复了。STORE_FAST需要把变量原来的值的引用计数减一,所以多出了Py_XDEFREF这一串代码,比LOAD_FAST要复杂些。注意右下角,如果引用计数减到0,就要调用对象的tp_dealloc方法来释放对象。这里具体调用的函数取决于对象的类型,在上面的例子里是int,所以会调用long_dealloc。所以我把这个函数标成红色,表示这条字节码不是一定调用这个函数,而是取决于对象的类型。
接下来是LOAD_CONST:

由于常量没有像局部变量那样用C数组存放,需要调用tuple的方法去拿,稍微比LOAD_FAST复杂一点。
顺便看几个典型的栈操作指令:
实现都相当简单。
如果把基于栈的虚拟机改为基于寄存器,理论上可以节省的就是上面这些代码。但是要注意LOAD/STORE系指令里实际干活的部分(比如Py_XDECREF)很可能省不掉。确定能省掉的是TARGET和FAST_DISPATCH这种纯解释开销和POP_TOP/ROT_THREE这种栈操作指令(但是又要增加寄存器间复制的指令)。
看完了可以省掉的指令,来看看真正干活的,无论如何不可能通过单纯把指令集改成基于寄存器就省掉的指令吧。INPLACE_ADD:
真是一图胜千言...
跟一遍这个执行过程,你还觉得前面那些LOAD_FAST/STORE_FAST省不省的,重要吗?对比LOAD_FAST和INPLACE_ADD的图,你还认同“这个循环指令集A要9条指令,指令集B只要4条,所以B一定比A快很多”这种思路吗?
还是解释一下:
前面说了,Python字节码都是抽象的,所以INPLACE_ADD并不知道操作数能不能作inplace(不产生新对象)的加法,所以binary_iop1要去判断操作数是否支持。恰好int因为是immutable type,不支持inplace操作(nb_inplace_add=NULL),那么就要用普通的加法(nb_add)。
由于不能inplace,每次n+=1要new一个新的int对象,还要free掉原来的对象。
另外还要处理一大堆情况,比如加法既可以由左操作数定义也可以由右操作数定义;如果两边都定义了,而一个是另一个的子类,还要优先用子类的方法。
和前面一样,最终实际干活的函数是由对象类型动态决定的。在我们的例子里对象是int,所以调用了long_add。由于int支持任意精度整数,long_add实现很长;由于例子里n不会超过32位,我截取了针对这种情况快速处理的代码。
“实际干活”的指令最后会用DISPATCH而不是FAST_DISPATCH,区别是前者会检查是否需要释放GIL给别的线程。这里需要原子地读一个标志,所以比FAST_DISPATCH慢不少。LOAD/STORE等指令用FAST_DISPATCH的原因是 1) 它们总是围绕着实际干活的指令,没必要这么频繁地检查 2) 实际干活的指令由于会调用用户代码,执行时间可以任意长,所以如果每几条指令才检查一次标志,线程切换延迟可能会很大;而LOAD等指令执行时间比较短,不检查标志也不会给线程切换带来很大延迟。
和Lua对比的话,我没看过Lua VM的代码,引用别的答案里的代码:
{TValue *rb = RKB(i);TValue *rc = RKC(i);lua_Number nb; lua_Number nc;if (ttisinteger(rb) && ttisinteger(rc)) {lua_Integer ib = ivalue(rb); lua_Integer ic = ivalue(rc);intop(+, ib, ic));}
和上图对比一下。
所以Python为什么慢?一个整数加法,用C就是一条机器指令,Lua大概十几行C代码,而Python需要经过近百行C代码。这些代码都干啥了?
Lua VM的指令集虽然也是抽象的,但对应的数据类型是确定的几种,因此不像Python对所有指令都要dynamic dispatch。
Python的加法语义设计得非常灵活,可以定义在左操作数/右操作数/两边同时定义... 进一步增加了dynamic dispatch的逻辑。
Python的int没有使用机器native整型,而是自己定义的任意精度整型格式。因此即使数据范围可以被native整型支持,整数运算逻辑仍然较复杂。
我们再做个profile实测一下。Python VM的源代码用configure --enable-profiling配置,就会在编译时加入gprof的测量代码。下面是运行测试代码的结果:
% cumulative self self totaltime seconds seconds calls s/call s/call name43.37 2.68 2.68 2262 0.00 0.00 PyEval_EvalFrameEx10.52 3.33 0.65 100001314 0.00 0.00 PyObject_RichCompare8.90 3.88 0.55 100000589 0.00 0.00 long_richcompare6.15 4.26 0.38 100002461 0.00 0.00 PyLong_FromLong5.99 4.63 0.37 100000052 0.00 0.00 PyNumber_InPlaceAdd5.58 4.98 0.35 100027904 0.00 0.00 _PyObject_Malloc5.58 5.32 0.35 100023539 0.00 0.00 _PyObject_Free5.26 5.65 0.33 100000294 0.00 0.00 long_add2.51 5.80 0.16 100001636 0.00 0.00 long_dealloc1.46 5.89 0.09 100022850 0.00 0.00 PyObject_Free1.21 5.97 0.08 100027904 0.00 0.00 PyObject_Malloc
...
PyEval_EvalFrameEx是字节码解释器循环所在,耗时43%。我们前面分析过,把指令集从基于栈改为基于寄存器,循环体最多能省一半指令,而且由于FAST_DISPATCH和DISPATCH的差别,这一半指令的解释开销较低。因此我们可以粗略地估计这种“优化”改进空间的上限是20%。
而其后10个耗时最多的函数里,PyObject_RichCompare和long_richcompare用来实现COMPARE_OP,其它的都属于INPLACE_ADD(和其后的STORE_FAST里必然发生的long_dealloc)。这两条指令就占用了54%的时间。
实际上不只是整数运算,作为面向对象语言最核心的“调用方法”和“访问对象自身属性”两个操作,Python也是非常慢。这个我有空再补充。
总的来说,Python性能为什么这么差?性能好的语言大体分两类:
被设计成高性能。如C,Java。这类语言在设计之初就把性能放在优先位置,愿意为之作各种牺牲,比如前面提到的,Java作为面向对象语言而为基本类型搞特殊规则;而后面加新功能时,往往首先问的也是这是否会使现有程序变慢。
设计时不重视性能,后期被强烈的性能需求和砸钱搞成高性能。如javascript。
而对Python设计者来说,有太多因素排在性能之前:易学,灵活性(比如加法的各种定义方法),概念简单(比如把int/long合并成一个任意精度整数类型)。即使有人愿意砸钱,设计者也不见得配合你,比如提出各种与性能优化相悖的向后兼容要求...
以上是关于Lua 的速度为什么比 Python 快?的主要内容,如果未能解决你的问题,请参考以下文章